
Introduction
- 2014년 ILSVRC Competition 우승. 2014년 당시만 해도 모델이 쌓인 정보가 깊은 편이었음.
- 22 Layers of Deep Neural Network. VGG는 Layers가 이보다 작은 19개였는데, GoogleNet에 사용된 Parameter 수가 VGG보다 훨씬 줄어들었다.
- 다만, 성능은 좋으나 널리 활용되지 못했다. 오히려 같은 해에 VGG가 Image의 Feature을 더 많이 뽑아내는 걸로 알려지면서 더 널리 쓰임.
Main Problem
Layer을 쌓으면서 연산량을 어떻게 해결할 것인지가 과제였음. 이를 Inception Module의 구조를 짤 때 해결함.
Solution
Inception Module
- Receptive Field가 3 x 3으로 고정되는 대신에, 1x1, 3x3과 5x5가 공존하면, 최종 입력단에서 입력 이미지에서 취합된 정보가 다양하게 된다. 예를 들어서 물체의 크기가 작을 때도 있고, 클 때도 있는데 이에 대해서 대응할 수 있게 된다.
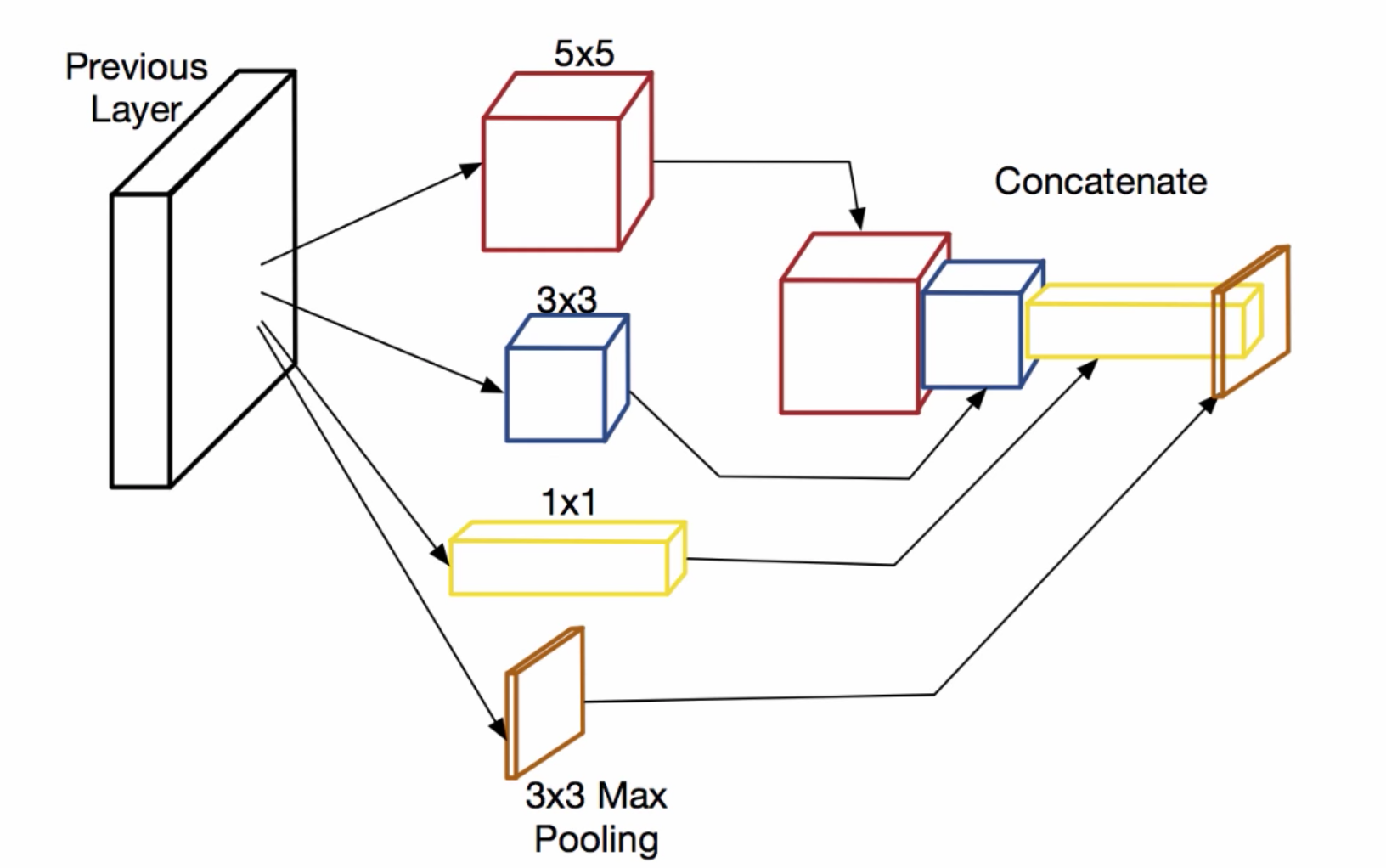
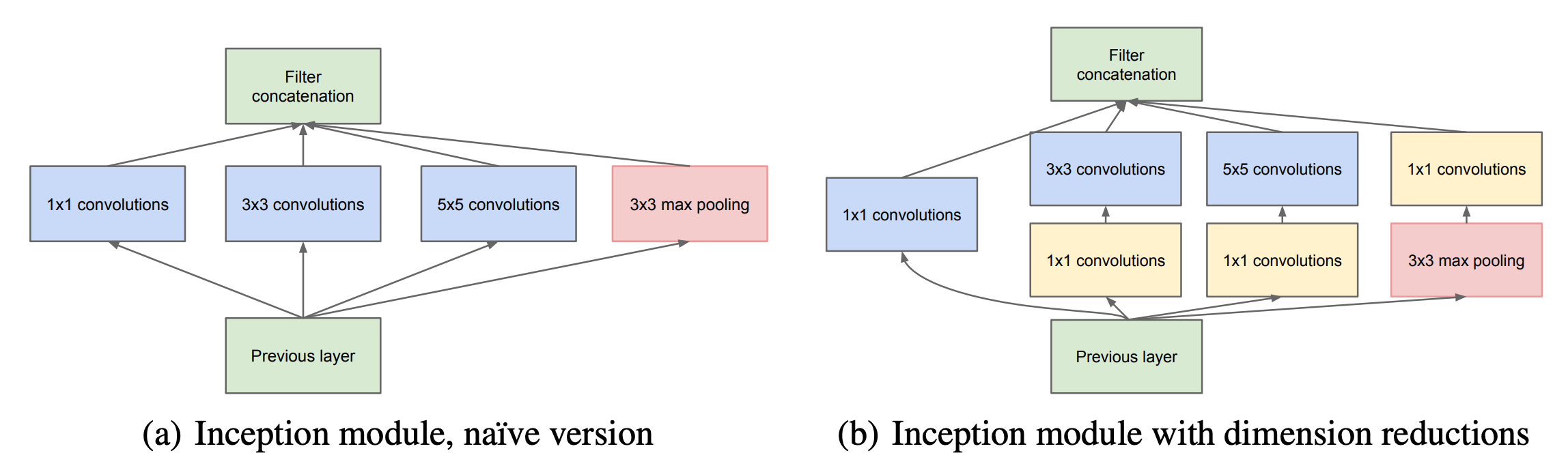
- Naive Inception Module: 기존에는 세로로 Conv Layer과 Pooling Layer을 쌓았는데, 이와는 다르게 가로로 병렬적으로 놓고, feature을 다 뽑은 다음에 concat을 하면 모델 성능에 기여할 것이라고 믿었음. 문제는 이러면 3 x 3이랑 5 x 5를 병렬적으로 놓으면서 연산량이 너무 많아진다는 것.
- 이름은 Inception 모듈인데, 같은 이름을 가진 영화처럼 깊이 들어가는 게 아니라 오히려 Wide하게 배치한다는 점이... 좀 아이러니컬하다.
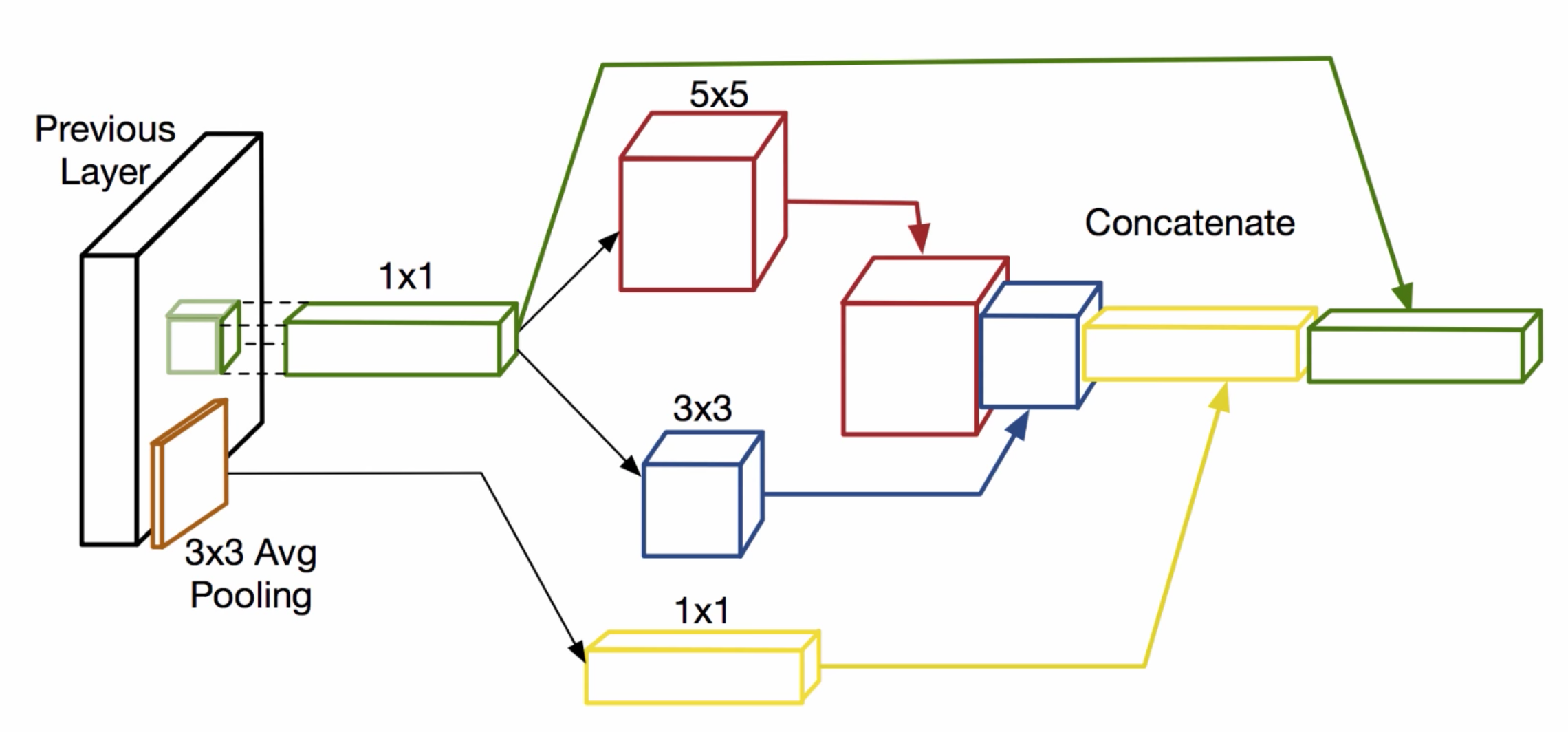
- Inception Module with Dimension Reductions: Parameter 개수와 연산량을 줄이기 위해서, 실제로 Network에 사용한 Inception Module에서는 Dimention Reduction을 위하여 1 x 1 convolution을 넣었다.
Dimensionality Reduction with 1x1 convolution
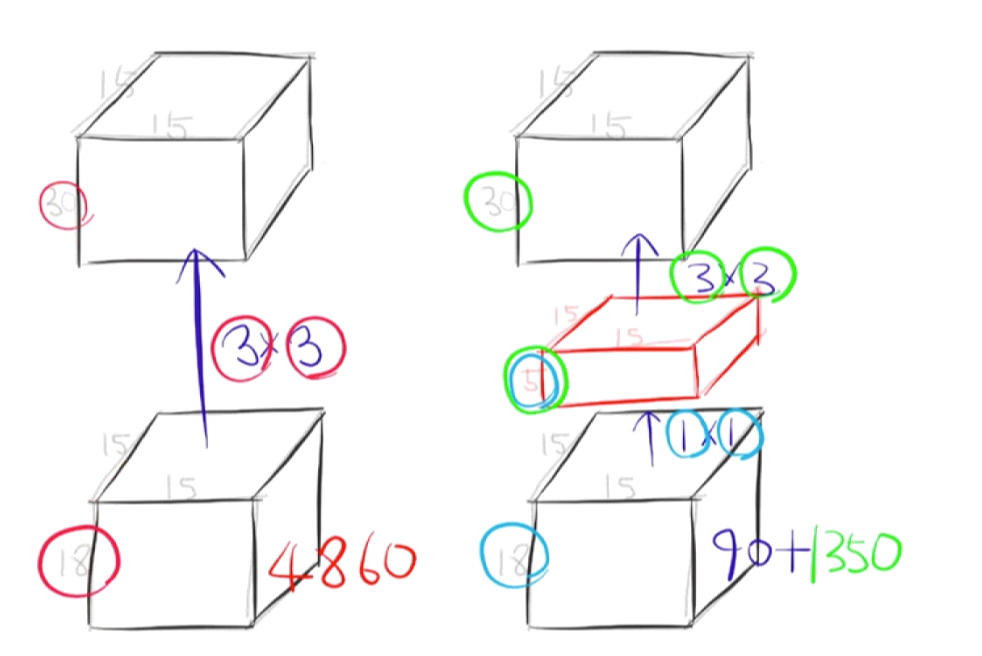
- 15 x 15가 input image size이고, 18이 채널 수이다. 이 Feature Map(15 x 15 x 18)이 3 x 3으로 필터링이 된다. 그렇다면 필터링 과정에서 3 x 3 x 18짜리 필터가 30개가 사용이 된다. 그렇게 해서 parameter 개수는 30개 x (3 x 3) 필터 x 18 채널 = 4860이 되는 것.
- 반면 (1 x 1) 필터 x 18채널 x 5를 거치면 Parameter가 90개 밖에 되지 않는다. 1 x 1 convolution으로 Channel을 줄인 것이다. 이게 Dimension Reduction인 것.
- GoogleNet은 이런 Inception 모듈의 연속이다.
GoogleNet Specifics
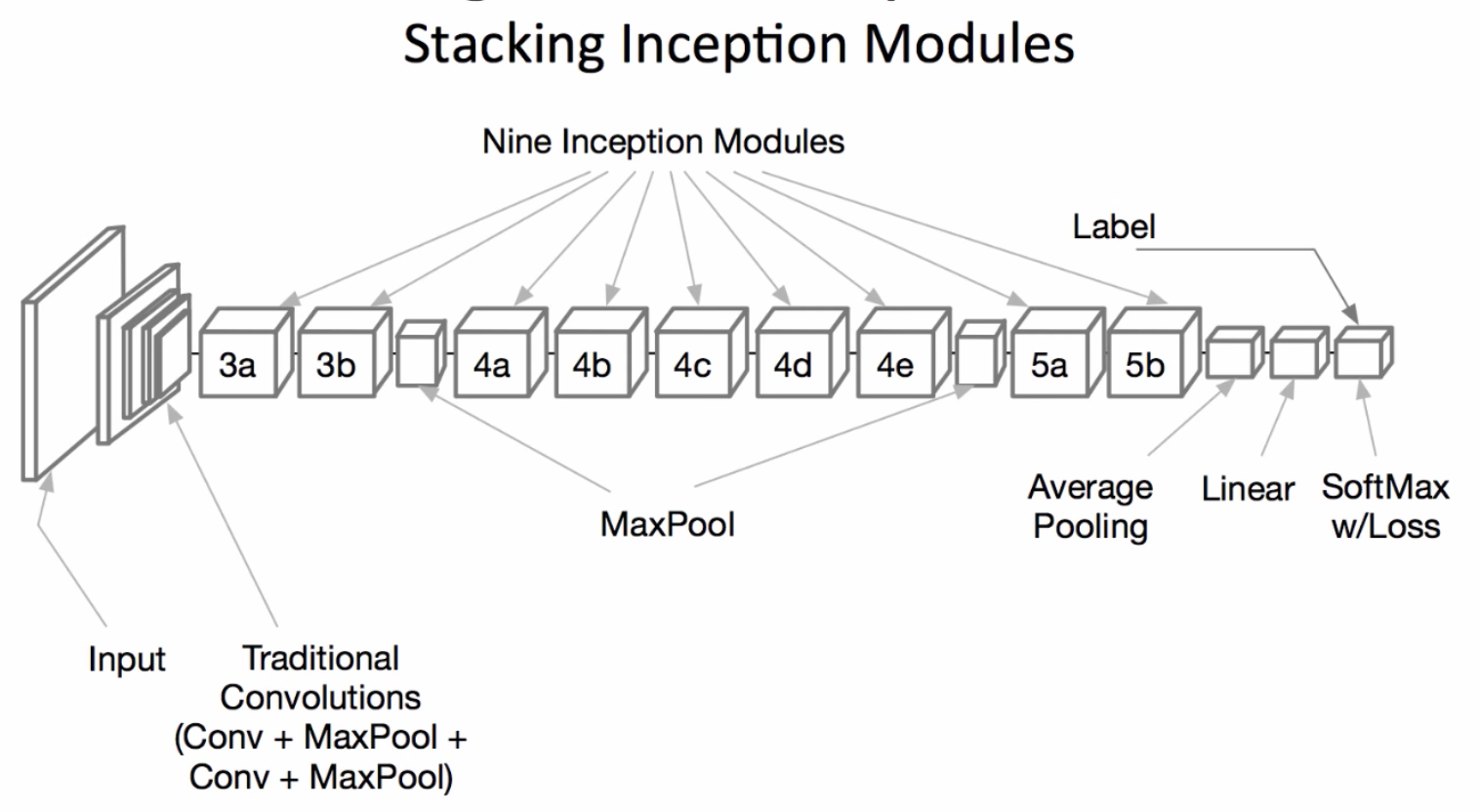
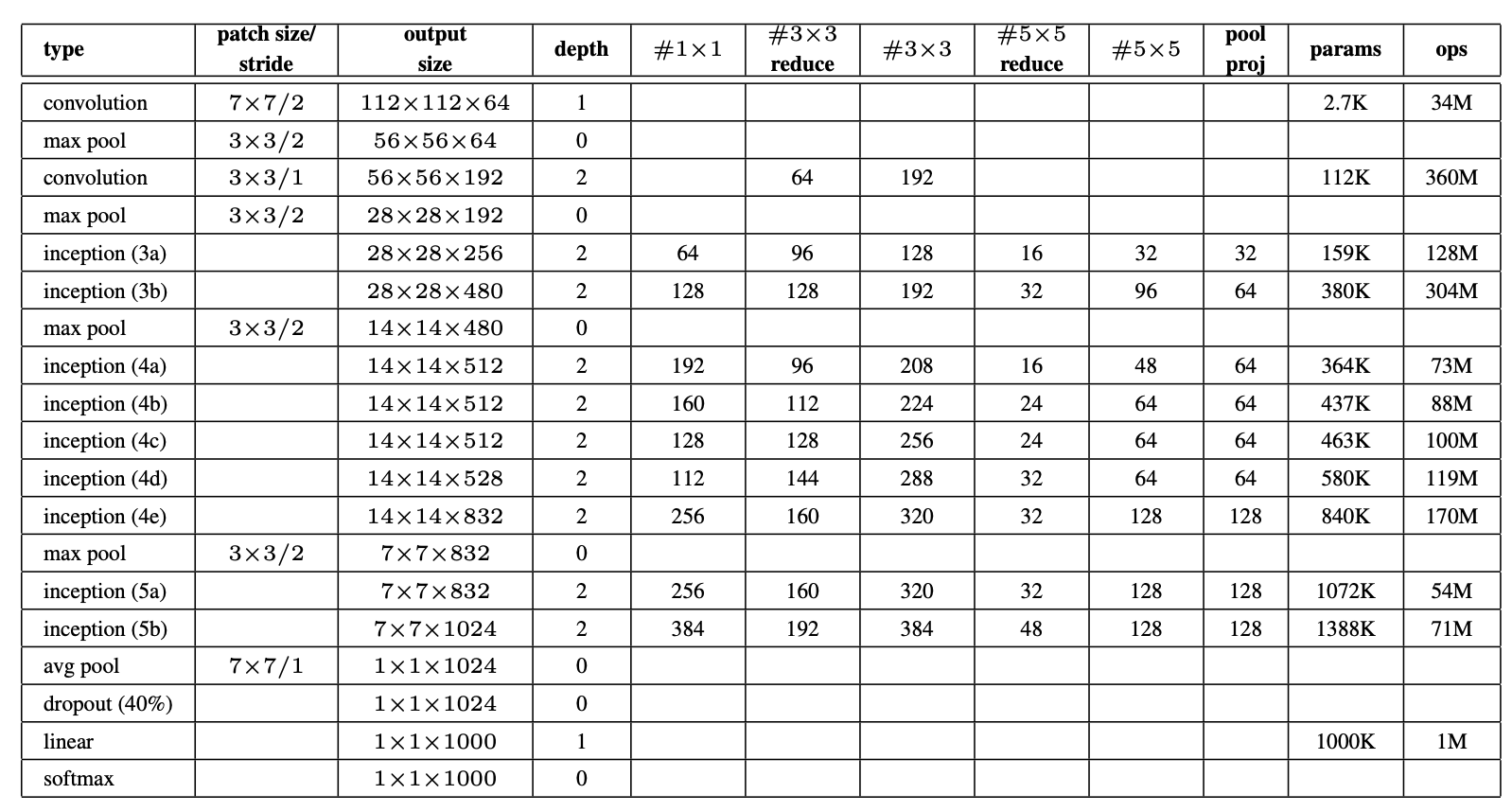
- GoogleNet에서 각 Inception 블럭 마다 convolution layer에 대해서 정리한 도표임.
- patch size/stride: Kernal size & stride
- output size: output feature map size
- depth: convolution layer을 몇 개나 연속해서 썼냐
- ops: 연산량
이해가 부족한 부분
- 사실 아직도 1 x 1 convolution이 어떻게 Parameter 개수를 줄였는지 이해하기 힘들다.
- Convolution을 거치면 Filter 개수가 늘어난다는 건 무슨 의미일까?
- GoogleNet에서 "reduce"가 붙어 있는 건… 뭐지?
출처

break, compose, display