https://aclanthology.org/2025.emnlp-industry.28.pdf
1. 논문 개요
제목: SELECT-THEN-ROUTE: Taxonomy guided Routing for LLMs
핵심 아이디어:
- 여러 LLM 풀(F)을 가지고 있을 때,
- 먼저 taxonomy 기반 분류기로 “어떤 유형의 질의인가?”를 판단해서 그 태스크에 강한 모델 소수만 뽑고(Select),
- 그 작은 풀 안에서 싼 모델 → 비싼 모델로 올라가는 confidence 기반 cascade를 돌려 최종 모델을 선택(Route)하는 2단계 구조.
실험적으로:
- 6개 공개 벤치마크에서 베스트 단일 모델(O3 Mini) 91.7% → StR 94.3%까지 올리면서,
- 비용은 약 4배 감소(예: 1000 샘플당 $16.29 → $5.21 수준).
2. 서론(Introduction) 요약
2.1 문제 설정
- 최신 LLM들은 QA, 번역, 코드, 추론 등 다양한 도메인에서 강력하지만, 하나의 모델이 모든 도메인에서 최강은 아니다.
- 어떤 모델은 수학적 추론·형식 추론에 강하지만, 코드 생성이나 요약에 약할 수 있음.
- 매 질의마다 모든 LLM들을 다 호출해보고 가장 좋은 모델을 고르는 것은
- 비용/레이턴시 측면에서 비현실적이고,
- noisy한 평가 때문에 오히려 정확도가 떨어질 수도 있다.
2.2 기존 Routing 연구의 한계
- 기존 다수 연구는 라우팅을 “질의 → 모델” 분류/랭킹 문제로 본다.
- 예: Eagle Router, GraphRouter, 기타 classification·ranking 기반 라우터들.
- 하지만:
- 전체 모델 공간에서 바로 고르기 → decision space가 커서 노이즈·오분류에 취약.
- 라우터 자체가 noisy한데, 그 위에 더 복잡한 학습(가중치 최적화 등)을 얹으면
- 튜닝/데이터 요구가 커지고,
- 실제론 best 모델보다 잘 못하는 경우도 많음.
2.3 두 단계(Select-Then-Route)의 직관
저자들이 가져오는 직관:
- decision-space reduction(결정 공간 축소) 아이디어:
- extreme multi-label classification, entity linking 등에서는
- 먼저 후보들을 high-recall로 좁히고,
- 그 안에서만 정교하게 랭킹하는 구조가
- 정확도 향상,
- 레이턴시 감소 모두에 효과적이었다.
- extreme multi-label classification, entity linking 등에서는
이를 LLM 라우팅에 적용:
- Taxonomy-guided selection
- 질의를 “reasoning / code / summarization / …” 같은 semantic class로 분류하고,
- 그 class에서 역사적으로 잘했던 LLM들만 소수 추려서 pool 생성.
- Confidence-based cascade
- 이 작은 풀 안에서 싼 모델부터 실행.
- 답이 신뢰할 만한지 multi-judge 기반 평가(CASCADE)로 확인.
- 신뢰도 낮으면 다음(더 강력/비싼) 모델로 escalte.
2.4 기여 정리
논문이 주장하는 기여:
- Taxonomy-guided two-stage routing(StR) 제안
- “모델 선택 공간 축소(Select)” + “cascade-based routing(Route)”를 명확히 분리.
- Taxonomy router
- 미리 정의한 다차원 taxonomy(태스크 그룹, reasoning 타입, 도메인, I/O 포맷, 복잡도 등)에 따라 질의를 분류하고, 각 class별로 “어떤 모델이 잘하는지”라는 메타 정보를 활용.
- 미리 정의한 다차원 taxonomy(태스크 그룹, reasoning 타입, 도메인, I/O 포맷, 복잡도 등)에 따라 질의를 분류하고, 각 class별로 “어떤 모델이 잘하는지”라는 메타 정보를 활용.
- CASCADE: multi-signal judge 기반 confidence 평가
- logit, reward model, domain-specific verifier, LLM-judge 네 가지 신호를 결합해 “이 답을 믿을 수 있는가?”를 평가.
- logit, reward model, domain-specific verifier, LLM-judge 네 가지 신호를 결합해 “이 답을 믿을 수 있는가?”를 평가.
- 실험적으로
- 6개 벤치마크에서 best single model보다 2.6%p 높은 정확도,
- 평균 모델 대비 10.6%p 향상, 비용은 1/3 이하.
3. 방법론(Method) — 수식 포함 상세 정리
3.1 기본 설정
- 모델 풀 [ ]
- 각각은 API 기반 closed-source나, self-hosted open-source LLM일 수 있음.
- 입력/출력
- (x): 질의/입력 (텍스트, 이미지, 기타)
- (Y): 출력 공간 (텍스트, label, embedding 등).
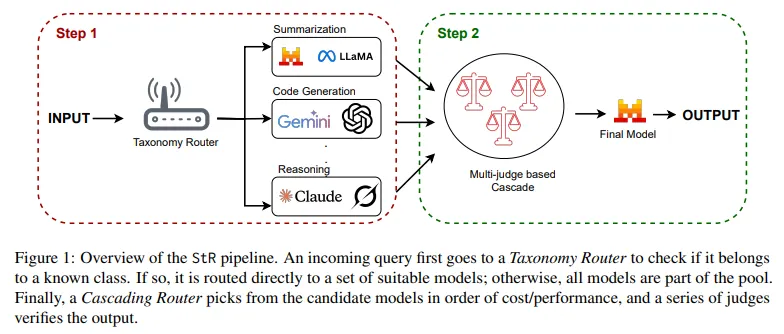
전체 파이프라인은 다음 두 단계로 구성:
- Step 1 – Taxonomy-based selection
- Step 2 – Cascading routing (CASCADE judge)
3.2 Step 1: Taxonomy-based Classification (선택 단계)
3.2.1 Taxonomy 정의
- D개의 독립된 taxonomy 차원을 정의: [ ]
- 각 (C_d)는 dimension d의 label 집합. 예:
- Task Group: instruction_following, knowledge_retrieval, analytical_reasoning, …
- Reasoning Type: single_step, multi_hop, chain_of_thought
- I/O Format: plain_text, json, program_code
- Domain: medical, legal, finance, …
- Complexity: low, medium, high
- 각 (C_d)는 dimension d의 label 집합. 예:
- 주어진 질의 (x_j)에 대해, 각 차원 d에서 (멀티라벨 가능) 확률 벡터를 예측: [ ]
3.2.2 두 종류의 taxonomy 분류기: Slow vs Fast
(1) Slow classifier – LLM 기반
- LLM을 직접 호출해, taxonomy label에 대한 확률을 예측: [ ]
- 장점: 정확도가 높음
- 단점: 비용·레이턴시가 큼.
(2) Fast classifier – embedding 기반
- Sentence-Transformer 등으로 질의를 한 번 임베딩: [ ]
- 각 taxonomy label (c)마다 prototype 벡터 ()를 미리 준비(평균 embedding 등).
- 차원 d에 대해, 다음과 같이 RBF류 softmax로 확률 정의:
- (\alpha > 0): 스케일 하이퍼파라미터.
3.2.3 Slow & Fast의 결합
두 분류기의 출력을 선형 결합:
- (): 사용자 혹은 비용 조건에 따라 결정.
- 예: 비용이 민감하면 fast 비중↑,
- 정확도가 중요하면 slow 비중↑.
3.2.4 최종 taxonomy 라벨 선택
최종 label 집합 (T(x_j))는 두 가지 방식 중 하나로 선택:
- thresholding 방식: [ ]
- 혹은 top-k 방식: 각 차원 d에서 확률 상위 k개의 label 선택.
3.2.5 Candidate model pool (S_j(x_j)) 선택
각 모델 ()에 대해,
어떤 taxonomy label에 대해 이 모델이 강한지를 나타내는 suitability 함수 ()를 정의:
- 논문에서는 단순한 binary check를 사용:
- 예: “모델 (F_i)가 해당 태스크 그룹/도메인에서 strong이라고 미리 설정되어 있는가?”
이때 candidate pool:
- 만약 () (어떤 모델도 taxonomy 기준에서 confident하지 않음) 이라면,
- 보수적으로 (S_j = F) (모든 모델) 로 설정.
3.3 Step 2: Cascading Routing (라우팅 단계)
이제 Step 1에서 얻은 candidate pool () 위에서 cascade를 돌린다.
3.3.1 Candidate pool 정렬
- ()에 포함된 모델들을 사용자 기준으로 정렬:
- 대표적으로 “cheap → expensive” 순서(비용 기준),
- 또는 “cost/성능 비율” 기준 등.
정렬된 리스트를 () 라고 하자.
3.3.2 Cascade 루프
각 모델을 순서대로 시도하면서 confidence가 충분한 지점에서 멈춘다:
- 각 모델 (F_{k})에 대해:
-
응답 생성:
[
]
-
CASCADE judge를 사용해 confidence score () 계산.
-
() 이면,
- 이 응답 (y_k)를 최종 답으로 채택하고 종료.
-
아니면,
- 다음(더 강력/비싼) 모델로 escalate.
-
- 모든 모델을 시도했는데도 ()가 없으면:
- fallback 정책 사용:
- 예: 마지막 모델의 답 반환,
- 혹은 특정 “big model”로 강제 라우팅,
- 또는 “confident하지 않음” 같은 메시지.
- fallback 정책 사용:
3.4 CASCADE: Multi-signal Confidence Scoring
CASCADE는 deferral(다음 모델로 넘길지) 판단 기준으로 사용되는 deterministic 알고리즘.
3.4.1 네 가지 원시 신호
질문 (x), 답변 (y)에 대해 다음 4가지 raw signal을 계산:
[
]
- (): Logit-based confidence
- 모델의 마지막 토큰(probability 등)에 기반한 confidence.
- (): Reward model score
- Skywork-Reward-Llama-3.1-8B 등을 사용, 응답의 품질을 score.
- (): Domain-specific verifier
- 예: 코드/SQL이면 syntax checker, schema validator 등 rule-based verifier.
- (): LLM-judge score
- Prometheus 2 스타일 LLM-as-a-judge: 질의(x)에 맞게 rubric을 생성 → 응답(y)을 rubric에 따라 평가해 score.
(세부 구현은 Appendix A.2에서: rubric 생성 모델 (J{\text{rubric}}), 평가 모델 (J{\text{eval}}) 등.)
- s_r 도 모델 상요한 llm 저지 이고 s_j 도 llm 저지 해서 score 내는건데 정확히 무슨 차이?
조금 풀어서 차이만 정리해줄게.둘 다 “LLM을 써서 점수 내는 것”은 맞는데,
S_R은 “미리 학습된 리워드 모델”이 내는 점수고,
S_J는 “프롬프트로 심판 역할을 시킨 일반 LLM”이 내는 점수야.
즉, 훈련 방식 / 입력·출력 포맷 / 역할이 다르다고 보면 됨.
1. S_R: Reward Model Score
-
정체
- Skywork-Reward-Llama-3.1-8B 같은 별도로 학습된 리워드 모델.
- 입력: (질문 x, 답변 y)
- 출력: 스칼라 점수 하나 (예: [-1, 1] 또는 [0, 1] 범위).
-
어떻게 학습됐냐?
- 보통 preference 데이터(여러 답 중 사람/teacher가 선호한 것)로 RLHF/Reward Modeling처럼 “좋은 답 vs 나쁜 답”을 구분하도록 학습됨.
- 모델 입장에서는
concat(x, y)같은 입력에서 바로score(x,y)를 뽑아내는 회귀/분류기 역할.
- 보통 preference 데이터(여러 답 중 사람/teacher가 선호한 것)로 RLHF/Reward Modeling처럼 “좋은 답 vs 나쁜 답”을 구분하도록 학습됨.
-
특징
- 이미 고정된(프리트레인된) 모델이고,
- 프롬프트로 rubric을 만들고 reasoning하는 게 아니라**“한 방에 점수만 퉁 치는 전용 스코어러”**에 가까움. - 내부적으로는 LLM 구조지만, **인터페이스는 “함수 f(x,y) → 점수”**인 모델이라고 이해하는 게 제일 편함.
2. S_J: LLM-Judge Score
-
정체
- Prometheus 2 같은 일반 LLM을 “판사 역할” 하도록 프롬프트해서 쓰는 것.
- 입력:
- 질문 x
- 또는 x 기반으로 만든 rubric(평가 기준)
- 답변 y
- 출력:
- 자연어 설명 + 최종 numeric 점수 (예: 1~5 점, 0~10 점 등)
-
동작 방식 (두 단계인 경우가 많음)
- Rubric 생성 단계
- LLM에 “이 문제를 평가할 기준(rubric)을 만들어줘”라고 시킴.
- 예:
- “정답 일치”,
- “추론 과정의 논리성”,
- “형식/포맷 준수” 같은 체크 리스트.
- 평가 단계
- 다시 LLM에 (
x,rubric,y)를 주고 “rubric 기준으로 평가하고 점수를 내라”라고 시킴.
- LLM이 자기 reasoning을 하면서 점수 + 설명을 줌.
- 다시 LLM에 (
- Rubric 생성 단계
-
특징
- 이쪽은 정확한 supervised reward 모델이 아니라,**프롬프트 기반 즉석 심판**에 더 가까움. - 상황/도메인에 따라 rubric을 바꿀 수 있고, **설명 가능한 피드백(“어디가 부족했다”)**도 얻을 수 있음. - 대신 - 더 비싸고, - LLM의 프롬프트 민감도/노이즈에도 영향을 받음.
3. 둘 다 “LLM 저지” 맞지 않나? → 정확히는 이런 차이
당신 말대로, S_R도 LLM 구조고, S_J도 LLM이라 “둘 다 LLM-judge 아냐?” 라고 느낄 수 있는데,
논문에서 구분하는 역할은 이런 식이라고 보면 돼:
항목 S_R (Reward Model) S_J (LLM-Judge) 모델 타입 특화된 리워드 모델 (학습된 스칼라 스코어러) 범용 LLM(Prometheus 2 스타일) 입력 (x, y) (x, y) + (선택적으로 rubric) 출력 바로 실수 스코어 자연어 평가 + 점수 학습 방식 preference 기반으로 사전에 supervised 학습 별도 학습 없이 프롬프트로 평가자 역할 시킴 장점 빠르고 일관적, 비용 상대적으로 적음 도메인·문제 특성 반영 쉬움, 설명 가능성 단점 특정 도메인/태스크에 과특화될 수 있음, 해석 어려움 느리고 비싸고, 프롬프트/LLM 노이즈 영향 큼 그래서 논문은 CASCADE 점수를 만들 때:
-
S_L: 답을 낸 모델 자신이 가진 내적 confidence
-
S_R: 사전에 학습된 품질 평가기가 보는 점수
-
S_D: 규칙 기반 검증기(코드/SQL validator 등)
-
S_J: 사람 심사자처럼 판단하라고 시킨 LLM-judge
이 네 가지를 정적 가중치로 섞어서 조금이라도 더 안정적인 “신뢰도 스코어”를 만들겠다는 구조야.
4. 감각적으로 한 줄로 다시 말하면
-
S_R:
“이미 RLHF처럼 학습된 품질 점수 회귀 모델한테 한 번 물어본 점수”
-
S_J:
> “프롬프트로 ‘심사위원 역할’을 맡긴 일반 LLM이 > > > rubric을 보고 생각해서 매긴 점수” >이 정도 차이로 정리하면 헷갈림이 많이 줄어들 거야.
-
3.4.2 Domain-specific 정적 가중치
- 각 신호는 domain(태스크 유형)에 따라 신뢰성이 다르다고 가정.
- 예: 수학/코드에서는 domain-specific verifier (S_D)가 더 중요,
- open QA에서는 LLM-judge (S_J)가 더 신뢰 가능, 등.
따라서:
- 각 domain별로 고정된 가중치 벡터를 설정하고,
- 4개 신호를 적절히 normalize한 뒤,
- 가중합 → 다시 4로 나누어 최종 score를 ([0,1]) 범위로 맞춘다:
여기서:
- S_c(y,x): CASCADE의 최종 confidence score
- ℓ ∈ {L,R,D,J}: 네 가지 신호 (Logit, Reward, Domain-verifier, Judge)
- w_ℓ^(domain): 각 도메인별로 고정된 가중치
- S̃_ℓ: 정규화된 각 신호의 점수
(논문은 수식을 상세히 쓰진 않고, “정규화 후 4로 나눠서 Sc∈[0,1]이 되도록 한다” 정도로 설명.)
중요한 점:
- 학습 기반 가중치 최적화 X
- 기존 연구는 이 신호들의 가중치를 학습/튜닝해야 했지만,
- 이 논문은 정적(domain-specific) 설정으로,
- 추가 학습이 필요 없고,
- 유지보수 비용이 적으며,
- 실제 성능도 comparable하다고 주장.
3.5 전체 알고리즘 요약 (Algorithm 1 StR)

알고리즘 1은 위 내용을 pseudocode로 정리한 것:
- 입력: 질의 x, 모델 집합 F, taxonomy 차원 {C_d}, 파라미터 λ, τ_label, τ_c, δ.
- Taxonomy 단계
- 각 차원 d에 대해:
- slow / fast 확률 분포 () 계산.
- Eq.(2)로 fuse → .
- threshold 혹은 top-k로 T(x) 선택.
- suitability 함수 Φ로 candidate pool S 구성.
- 비어 있으면 S ← F.
- S를 user criterion(cost 등)에 따라 정렬.
- 각 차원 d에 대해:
- Cascade 단계
- 정렬된 S를 순회하면서:
- 생성.
- CASCADE 계산.
- 면 반환.
- 끝까지 threshold를 통과 못하면 마지막 y 또는 fallback.
- 정렬된 S를 순회하면서:
4. 결과(아주 짧게)
- Figure 2 기준:
- 평균 정확도: 83.7%
- Best single model(O3 Mini): 91.7%
- StR: 94.3% (약 2.6%p ↑)
- 비용 측면:
- 평균 비용: $16.29
- 최고가 모델들(GPT-4, Claude 3 Opus 등)은 $70~100 이상
- StR: 약 $5.2 정도로, 평균 대비 1/3 수준, 고가 모델 대비 10배 이상 저렴.
5. 요약 한 줄
SELECT-THEN-ROUTE는 “LLM 라우팅을 바로 하는 것이 아니라,
(1) taxonomy 기반으로 모델 후보 pool을 먼저 줄이고,
(2) 그 안에서 multi-signal judge(CASCADE) 기반 confidence cascade로 최종 모델을 고르는
2단계 구조로, decision space를 줄여 정확도·비용 면에서 Pareto 개선을 달성한 프레임워크”이다.
