
1. 머신러닝이란?
머신러닝은 전통적인 프로그래밍과 비교할 수 있다.
- 전통적인 프로그래밍 🤷♀️
- 입력 데이터와 프로그램 코드를 컴퓨터에 전달
출력 데이터생성
- 머신러닝 🤖
- 입력데이터와 출력 데이터를 컴퓨터에 전달
프로그램 코드생성
머신러닝의 종류는 아래와 같다.
- 지도 학습
- 회귀
- 판단트리
- 랜덤 포레스트
- 분류
- 비지도 학습
- 클러스터링
- 강화 학습
2. 지도 학습
정답을 알려주는 교사가 존재하는 학습 방법
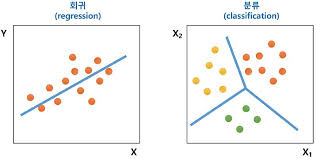
지도 학습에는 회귀(regression)과 분류(classification)이 존재한다.
회귀(Regression)
회귀는 주어진 입력-출력 쌍을 학습한 후에 새로운 입력값이 들어왔을 때, 합리적인 출력값을 예측하는 것이다.
회귀(regression): 입력(x)와 출력(y)이 주어질 때, 입력에서 출력으로의 매핑 함수를 학습하는 것
분류(Classification)
분류는 앞에 나왔던 식에서 출력 y가 이산적(discrete)인 경우에 이것을 분류 문제라고 부른다.
예를 들어 고양이와 강아지를 분류하는 것/스팸 메일인지 아닌지 분류하는 것/종양이 악성인지 아닌지 분류하는 상황에 사용된다.
분류를 수행하기 위한 알고리즘에는 신경망, kNN(K-Nearest Neighbor, SVM(Support Vector Machine)이 있다.
3. 머신러닝의 과정
머신러닝의 과정을 살펴보자!
크게 아래와 같은 순서로 진행될 것이다.
-
데이터 수집
수집되는 데이터의 품질과 양이 예측 모델의 성능을 결정하기 때문에 근본이 되는 중요한 단계!
Train 데이터를 수집한 뒤에 순서를 무작위로 설정해야 한다.
-> 데이터의 순서가 학습하는 것에 영향을 미치지 않기를 원하기 때문에 -
훈련 데이터와 테스트 데이터
훈련 데이터: 모델 학습에 사용되는 데이터
테스트 데이터: 모델의 성능을 평가하는데 사용되는 데이터 -
모델 선택
예를 들어 색상과 산성도라는 feature를 가지고 음료수가 콜라인지 주스인지 분류하는 문제라면선형 모델을 선정할 수 있다.
- 학습
위에서선형 모델을 선택하였으므로 직선의 식은
y=m*x+b
로 표현될 수 있다.
- x: 첫 번째 feature값
- m: 해당 직선의 기울기(가중치 - weight)
- b: y 절편(바이어스 - bias)
- y: 출력값
훈련을 통해 바뀌는 값은 m과 b이다.
-
평가
2번에서 설정해두었던 테스트 데이터를 활용하여 모델의 성능을 평가한다. -
예측
특정 음료의 산성도와 색상(Feature)을 입력해주어 머신러닝 시스템에게 예측하도록 시켜본다!
4. 붓꽃을 머신러닝으로 분류해보자.
아래의 라이브러리를 추가 설치해주어 붓꽃 데이터를 가져온다.
pip install scikit-learn붓꽃 데이터셋은 3가지 종류의 label(0: 'setosa', 1: 'versicolor', 2: 'virginica')과 4가지 종류의 feature이 존재하며 150개의 sample이 존재한다.
데이터셋 확인
그럼 데이터셋을 가져와서 확인해보자.
from sklearn import datasets
iris = datasets.load_iris()
print(iris.data[:5])
print(iris.target)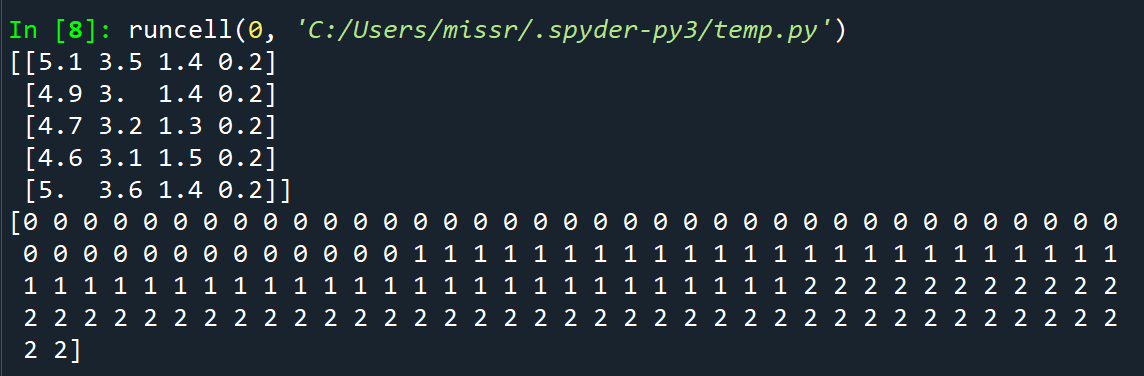
data는 샘플들의 특징에 대한 데이터를 모두 가지고 있는 변수로 n_samples x n_features 형식의 2차원 numpy 배열이다.
- n_samples: 샘플의 개수
- n_features: 샘플 당 특징의 개수
훈련 데이터와 테스트 데이터 분류
from sklearn.model_selection import train_test_split
X = iris.data
Y = iris.target
# Train: Test 데이터 셋 비율을 8:2로 분할한다.
X_train, X_test, y_train, y_test = train_test_split(X,Y, test_size = 0.2, random_state=4)
print(X_train.shape)
print(X_test.shape)
모델 선택 및 학습
knn 알고리즘: 근접한 k개의 이웃을 조사하여 개수가 많은 쪽에 속한다.
knn 모델을 통해 학습하고 평가하는 과정에 대한 전체 코드는 아래와 같다.
from sklearn import datasets
iris = datasets.load_iris()
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
X = iris.data
Y = iris.target
# 훈련 데이터, 테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X,Y, test_size = 0.2, random_state=4)
knn = KNeighborsClassifier(n_neighbors=6)
knn.fit(X_train, y_train)
# 예측
y_pred = knn.predict(X_test)
# 평가
from sklearn import metrics
scores = metrics.accuracy_score(y_test, y_pred)
print(scores)
오늘은 knn 모델 실습을 진행해보았다!
예전에 해보고 한동안 안했다가 하니까 추억 새록새록...어서 여기도 지나쳐서 빨리 딥러닝 쪽 공부하구싶다 ㅎ_ㅎ
그치만 잘하는거 아니니까 복습 꼼꼼하게 하기..!!😊
