
이번 시간에는 케라스에 대해서 함께 알아볼 것이다!
이전에 공부했던 기억이 있는데 가물가물하니까 꼼꼼하게 해봐야지!😊
1. 미니 배치
우리는 이전에 XOR 예제에서 총 4개의 샘플 데이터([0,0], [1,0], [0,1], [1,1])로부터 출력값을 도출해냈었다.
그러나 실제로는 수많은 샘플 데이터가 주어진다.
그렇다면 이 때 우리는 몇 개의 샘플을 처리한 후에 가중치를 변경해야 할까?
아래와 같이 2가지 방법이 있다고 한다.
온라인 학습(Online Learning)또는확률적 경사 하강법(Stochastic Gradient Descent)풀 배치 학습(Full batch learning)
그럼 이러한 방법에 대해 간단히만 살펴보자!
풀 배치 학습
- 모든 훈련 샘플을 처리한 후에 가중치를 변경하는 방법이다.
- 시간과 자원을 많이 소모한다.
- 일반적으로 오프라인 환경에서도 수행되므로, 오프라인 학습(Offline Learning)이라고도 한다.
온라인 학습
- 훈련 샘플 중에서 무작위로 하나를 골라서 학습을 수행하는 방식이다.
- 계산하기 쉽지만 샘플에 따라서 우왕좌왕하기 쉽다.
각각의 방법에 따라 장단점이 존재하는 것을 확인할 수 있다.
그래서 이 두 가지 방법의 중간 방법으로 제안된 것이 미니 배치 학습인 것이다.
미니 배치 학습⭐
- 훈련 샘플을 작은 배치들로 분리시킨 후에, 하나의 배치가 끝날 때마다 학습을 수행하는 방법이다.
- 예를 들어 10000개의 샘플이 있다면 여기서 100개 정도의 샘플을 랜덤하게 뽑아서 학습하는 것이다.
- 온라인 학습의 장점인
빠른 모델 업데이트와 메모리 효율성, 풀 배치 학습의 장점인정확한 모델 업데이트와 계산 효율성의 적절한 타협점이다.⭐
2. 행렬로 미니 배치 구현하기
지금까지 우리는 한 번에 하나의 샘플을 처리하였다.
그런데 위에서 말한 미니 배치 학습 등 여러 개의 샘플을 병렬로 같이 처리하여야할텐데 어떻게 할까?
입력층의 행렬에 추가해줄 수 있다!⭐
이러한 과정을 배치 학습이라고 한다.
계산은 간단하다.
그런데 여러 개의 샘플을 동시에 처리할 때 오차는 어떻게 역전파되는지 알 수 있을까?
체인룰에 의해 또 분해될 것이다.
여기에 구체적인 계산 과정을 포함할 수 없어 글로 열심히 적어보겠다..!
여러 개의 샘플을 동시에 처리할 때, 오차의 역전파 구하기
- E(오차)를 Y(라벨값)에 대해 미분한 값 구하기
- Y(라벨값)을 Z2(출력)에 대해 미분한 값 구하기
- 여기서
하마다드 연산이 사용될 것!
- 여기서
- E(오차)를 W2(가중치)에 대해 미분한 값 구하기
그러나 이 값은 사실 정해져 있다.
A!
왜냐면 Z2 = A1 X W2 + B2인데 미분하면 A라서!
그러나 여기서 지금 역방향으로 전파되고 있으므로 A의 전치 행렬을 곱해주어야 한다. - 위에서 구한 1과 2의 결과값을 곱해 E(오차)를 Z(출력)에 대해 미분한 값 구하기
- 여기서도..!
- 이제 위의 식을 풀어서 W2에 들어있는 가중치인 w5에 대한 그래디언트를 정리해보면 모든 샘플의 그래디언트들이 합쳐지는 것을 알 수 있다.
아래의 참고자료가 진짜 도움이 많이 됐다.
https://wikidocs.net/37406
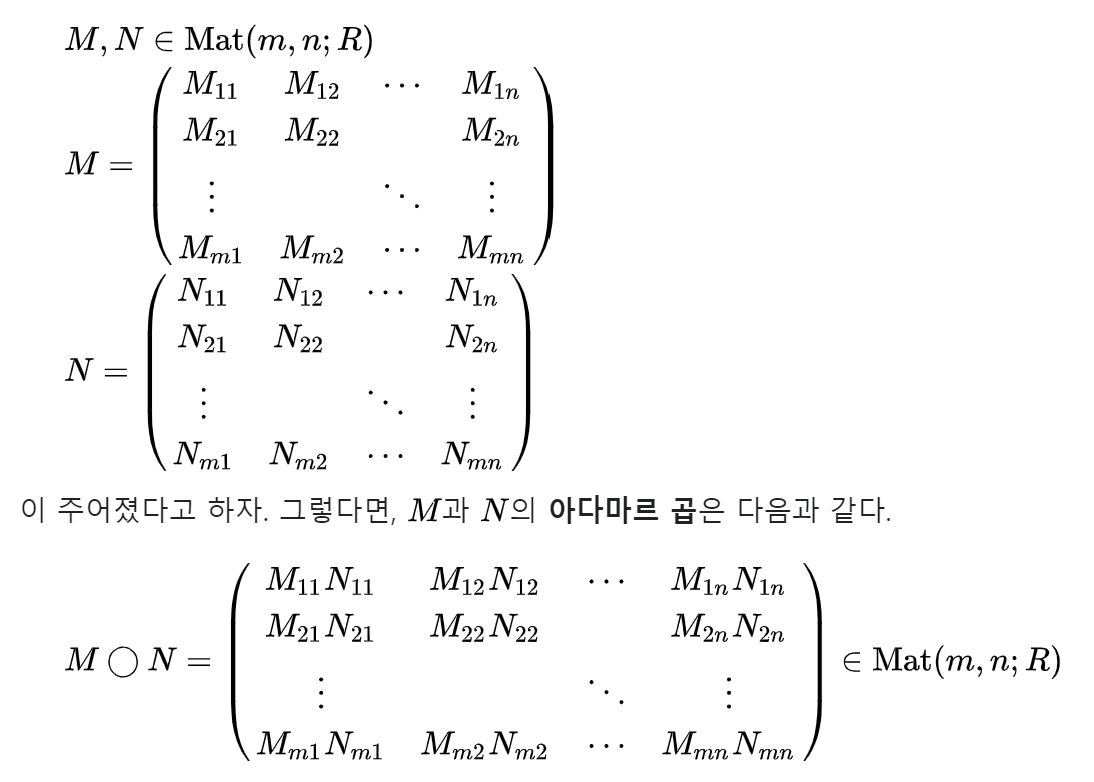
하마다드 연산이란?
같은 크기의 두 행렬의 각 성분을 곱하는 연산이다.
일반적으로 M X N과 N X P 꼴의 두 행렬을 곱하는데 여기서는 M X N와 M X N 꼴의 두 행렬을 곱한다.
미니 배치 구현
한 번 직접 구현해보면서 이해해보겠다!
import numpy as np
# 시그모이드 함수
def actf(x):
return 1/(1+np.exp(-x))
# 시그모이드 함수의 미분치
def actf_deriv(x):
return x*(1-x)
# 입력 유닛의 개수, 은닉 유닛의 개수, 출력 유닛의 개수
inputs, hiddens, outputs = 2, 2, 1
learning_rate = 0.5
# 훈련 입력과 출력 -> XOR 연산
X = np.array([[0,0],[0,1],[1,0],[1,1]])
T = np.array([[0],[1],[1],[0]])
# 가중치를 -1.0에서 1.0 사이의 난수로 초기화한다.
w1 = 2*np.random.random((inputs, hiddens))-1
w2 = 2*np.random.random((hiddens, outputs))-1
B1 = np.zeros(hiddens)
B2 = np.zeros(outputs)
# 순방향 전파 계산
def predict(x):
layer0 = x # 활성화 함수 적용
z1 = np.dot(layer0, w1) + B1 # 행렬 곱 연산
layer1 = actf(z1) # 활성화 함수 적용
z2 = np.dot(layer1, w2) + B2 # 행렬 곱 연산
layer2 = actf(z2)
return layer0, layer1, layer2
# 역방향 전파 계산
def fit():
global w1, w2, B1, B2
for i in range(60000):
layer0, layer1, layer2 = predict(X)
layer2_error = layer2 - T # 오차 계산
layer2_delta = layer2_error*actf_deriv(layer2)
layer1_error = np.dot(layer2_delta, w2.T)
layer1_delta = layer1_error*actf_deriv(layer1)
w2 += -learning_rate*np.dot(layer1.T, layer2_delta)/4.0
w1 += -learning_rate*np.dot(layer0.T, layer1_delta)/4.0
B2 += -learning_rate*np.sum(layer2_delta, axis = 0)/4.0
B1 += -learning_rate*np.sum(layer1_delta, axis = 0)/4.0
def test():
for x, y in zip(X, T):
x = np.reshape(x, (1, -1))
layer0, layer1, layer2 = predict(x)
print(x, y, layer2)
fit()
test() 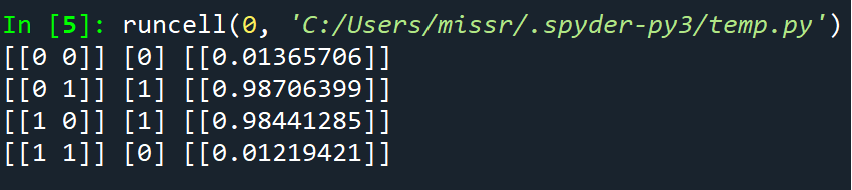
ㅎㅎ 교재를 열심히 따라쳤다^^
순방향 전파까지는 쉽게 이해가 된다.
입력값에 대해 가중치를 곱하고 바이어스값을 더해주는 과정이다.
역전파 과정에 대해 GPT와 함께 다시 다루어보자^_^
순뱡향 전파 과정을 통해 예측값을 도출한다.
layer0, layer1, layer2 = predict(X)실제값과의 오차(E)를 계산한다.
layer2_error = layer2 - T # 오차 계산오차(E)에 대해 Z2로 미분한 값을 구하는 과정이다.
layer2_error는 위에서 말한 것처럼 출력층 노드의 오차이고,
acrf_deriv(layer2)는 활성화함수(시그모이드 함수)를 미분한 값의 결과물이다.
위에서 배웠던 역전파 과정의 4번을 수행하는 과정이다.
layer2_delta = layer2_error*actf_deriv(layer2)은닉층의 오차를 계산하는 과정으로 출력층의 델타와 가중치의 전치(transpose)를 곱한 값이다.
layer1_error = np.dot(layer2_delta, w2.T)은닉층의 델타를 계산하는 과정이다.
layer1_delta = layer1_error * actf_deriv(layer1)ㅎㅎ이해 완료..🥹
이와 같이 계산한 뒤 마지막에 그래디언트를 계산해주어서 배치안헤 포함된 샘플의 개수인 4로 나누 어준 것을 확인할 수 있다.
근데 이전에 바이어스에 대한 공식을 다루지 않았었는데 위에서는 사용되고 있다.
바이어스는 모든 예제의 델타를 합쳐야 한다.
따라서np.sum()을 호출하여 열 방향으로 모든 델타를 합쳤다.
3. 학습률
학습률에 대해 이전에 간단히 언급한 바 있다.
너무 높으면 over shooting이 일어나고, 불안정해지면 발산하기도 한다.
반면에 너무 낮으면 아주 느리게 학습이 이루어지며, 그만큼 수렴하는 시간도 늦어진다.
또한 지역 최소화에 빠질 위험도 존재한다.
우리는 적절한 학습률을 찾아내기 위해 모멘텀이라는 개념에 대해 알아볼 것이다.
모멘텀(Momentum)
경사 하강법(Gradient Descent) 최적화 알고리즘의 한 종류이다.
기존의 기울기 업데이트에 관성의 개념을 도입하여 학습을 가속화시키는 방법이다.
모멘텀은 아래와 같은 특징이 존재한다.
- 현재 시점에서의 그래디언트에 학습률(Learning rate)을 곱한 값을 가중치에서 빼주는 표준적인 경사 하강법 업데이트를 수행한다.
- 역할: 현재의 업데이트에 이전 시점의 업데이트 방향 및 크기를 일정 비율만큼 고려한다.
- 이전에 이동한 방향으로 게속해서 이동하려는 경향이 있기 때문에 지역 최소값에서 빠르게 벗어나 전역 최소값에 수렴한다.
- 모멘텀 상수는 0~1 사이의 값으로 설정된다.
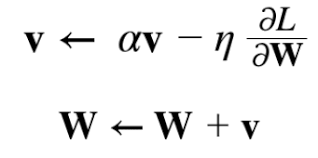
W: 갱신할 가중치 매개변수
ŋ: 학습률 (실제로는 0.01이나 0.001과 같은 값을 미리 정해서 사용)
əL/əW: W에 대한 손실 함수의 기울기
➡️ SGD는 기울어진 방향으로 일정 거리만 가겠다는 단순한 방법
적절한 학습률 설정하기
그렇다면 어떻게 학습률을 설정해야할까?
손실함수의 모양에 따라서 적응적으로 학습률을 변경하는 것이다!
즉 학습률을 고정시키지 말고, 현재 그래디언트 값이나 가중치의 크기, 학습의 정도 등을 고려하여 적응형 학습률로 하는 것이다.
아래와 같은 방법들이 존재한다.
- Adagrad
- RMSprop
- Adam
정리한게 많지는 않은거같은데 시간이 정말 오래걸린다,,
이해하는데 시간을 추가적으로 쓰다보니까..!
경사 하강법의 문제점을 해결하기 위한 다양한 기법들이 존재한다는 것을 보니까 뭔가 마음이 편안하다..
이전에 배웠었는데 구체적으로 다루어보니까 AI 연구가 잘 진행되고 있구나(?)싶었다ㅎㅎㅋㅋ
내일은 이 단원을 꼭 마무리 하고 싶다..!🥺
화이팅~!😊😊😊
참고 자료
https://gooopy.tistory.com/123
https://ko.wikipedia.org/wiki/%EC%95%84%EB%8B%A4%EB%A7%88%EB%A5%B4_%EA%B3%B1
https://heytech.tistory.com/382
https://velog.io/@bbirong/%EB%B0%91%EB%94%A5-6%EC%9E%A5.-%ED%95%99%EC%8A%B5-%EA%B4%80%EB%A0%A8-%EA%B8%B0%EC%88%A0%EB%93%A4
