
이제 CNN에 대해서 공부할 차례!
합성곱 신경망이라고도 한다 ㅎㅎ
내가 가장 관심있어하는 영상인식분야에서 두드러진 성능을 보여주는 모델이므로 꼼꼼히 살펴보자!
1. 컨벌루션 신경망 소개🙋♀️
지금까지 다루었던 신경망에서는 하위 Layer의 유닛들과 상위 Layer의 유닛들이 완전히 연결되어 있었다. 이전에 분석한 대로 신경망에 매개변수(가중치)가 너무 많으면 과잉 적합에 빠질 수도 있고 학습이 늦어진다.
Convolution Neural Network(CNN)에서는 아래와 같이 하위 Layer의 유닛들이 부분적으로만 연결되어 있다. 따라서 복잡도가 낮아지고 과잉적합에 빠지지 않는다.
CNN에서 하나의 유닛은 제한된 영역만을 본다.
즉 부분적으로만 연결되어 있다고 볼 수 있다.
CNN은 2차원 형태의 입력을 처리하기 때문에, 이미지 처리에 특히 적합하다.
신경망의 각 레이어에서 일련의 필터가 이미지에 적용된다.
따라서 이미지의 종류를 판별하거나 이미지 안의 물체를 추적하거나, 숫자나 얼굴 인식, 이미지의 내용을 이해하여 이미지를 분류하거나 주석을 붙이는 작업에도 성공하고 있다.
2. 컨벌루션 연산➕➖➗🟰
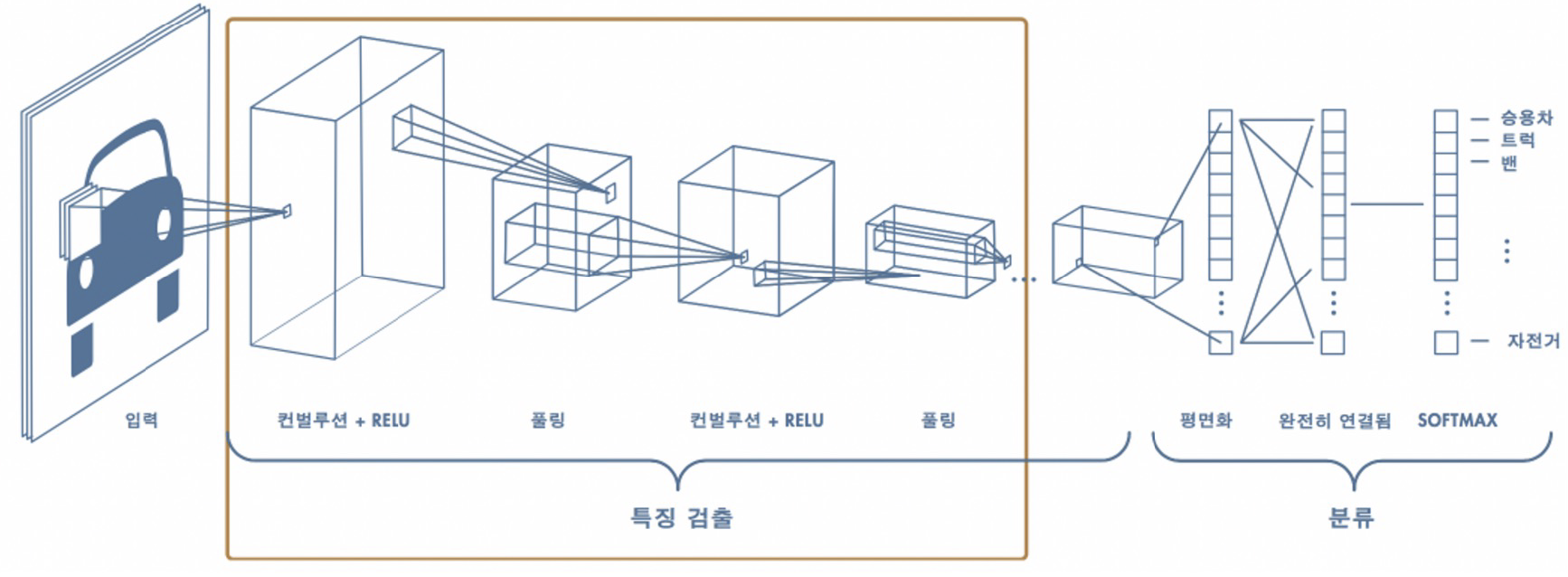
CNN의 구조⭐⭐⭐
- 맨 앞에 2차원의 입력값을 나타내는 입력층이 있다.
Convolution연산을 통해서 특징을 뽑아내는특징맵(feature map)이 존재한다.- 특징맵의 출력에는
ReLU 활성화 함수가 적용된다. - 풀링
Pooling 연산을 적용한다. (서브 샘플링이라고도 한다.) - 2~4 단계가
반복된다. - 신경망의 끝에서
완전 연결된 신경망이 있어 추출된 특징을 바탕으로 물체를 인식한다. - 이 과정에서 2차원 배열을 1차원 배열로 변경하고 출력 레이어의 유닛들은
Softmax 활성화 함수를 통해 출력된다.
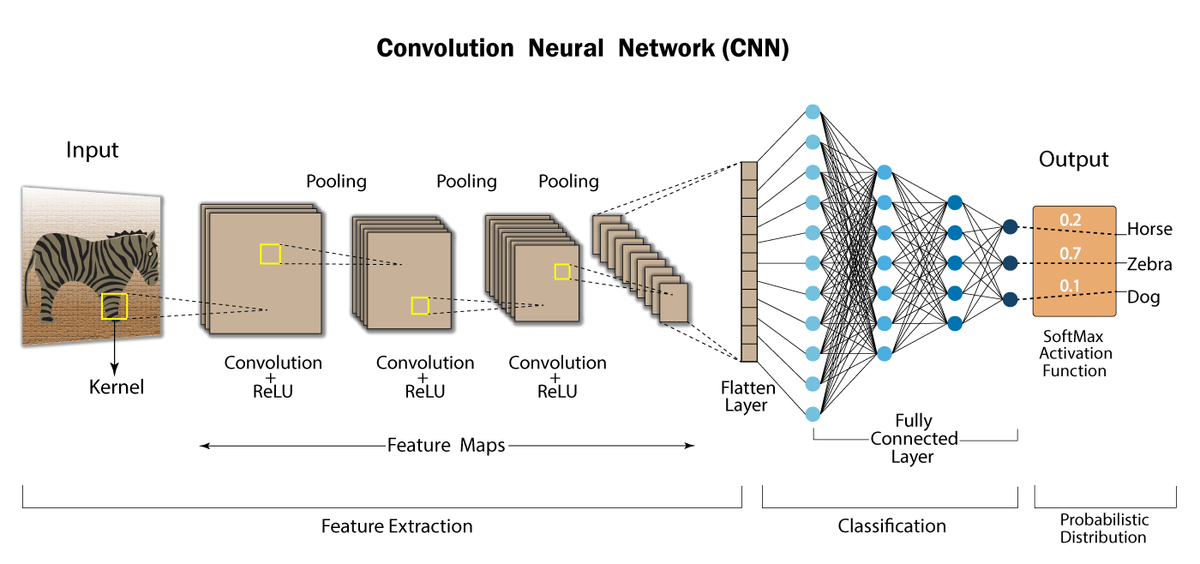
컨벌루션 연산은 필터링 연산이라고도 하며, 이미지로부터 어떤 특징값을 얻어낼 때 사용한다. 주변 화소값들에 가중치를 곱해서 모두 더한 후에, 이것을 새로운 화소값으로 하는 연산이다.
그럼 각 단계에 대해서 살펴보기전에 자주 나올 단어들에 대해 정의해보자😊
보폭(Stride)⭐
Filter를 몇 칸씩 움직이게할지 결정
예를 들어 보폭이 1이면 한 번에 1픽셀씩 이동하면서 커널을 적용한다.
보폭이 2라면 컨벌루션을 출력하면 출력의 크기가 입력의 절반으로 줄어들 것이라는 것을 예측해볼 수 있다.
그림으로 간단히 표현하면 아래와 같다.
만약 아래의 상황에서 stride가 1이었다면, 출력값은 3x3형태였을 것이다.
패딩(Padding)⭐
이미지의 가장자리를 처리하기 위한 기법
주로 출력 데이터의 크기를 조정할 목적으로 사용한다.
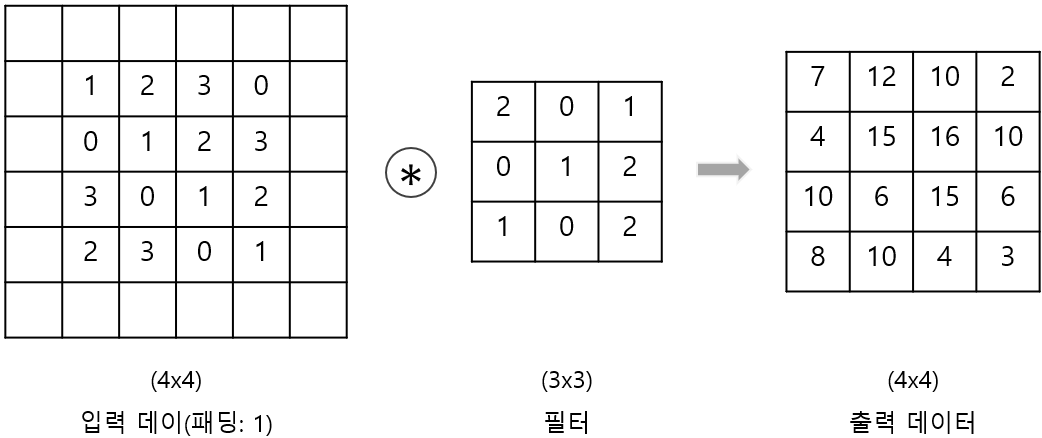
아래는 대표적으로 zero-padding 기법을 적용한 사례이다.
4x4크기의 입력 데이터에 3x3크기의 필터를 적용하면, 2x2크기의 출력데이터를 얻게 될 것이다.
근데 뭐가 문제지? 라고 생각할 수 있다!
이를 반복하게되면 마지막에 출력 크기가 1이 되어서 합성곱 연산을 할 수 없어지는 문제 가 발생한다🤔❗
따라서 아래와 같이 패딩값을 지정해주어 입력 크기를 유지해줄 수 있다.
아래에서 사용한 방법(zero-padding)외에도 여러 기법이 존재하니 필요한 경우에 찾아보면 좋을 듯 하다.
필터(Filter)/커널(Kernel)⭐
Feature를 찾기 위한 Detector
위에서 커널을 1개만 사용하여 예를 들었었다.
하나의 커널은 하나의 특징만을 추출한다.
실제로 모델을 구축할 때는 여러 개의 커널을 동시에 학습하는 경우가 대다수이다. 128개나 256개의 커널도 흔히 사용한다.
여기서 학습되는 것은 커널의 가중치이다.
각 커널(필터)마다 가중치를 가지고 있으므로 동시에 여러 개 커널의 가중치들이 학습된다.
커널이 많아지면 자연스럽게 특징맵의 개수도 많아질 것이다.
아래에서 예시를 살펴보자.
예를 들어 필터의 개수가 4이면, 특징맵의 개수도 4이 될 것이다.
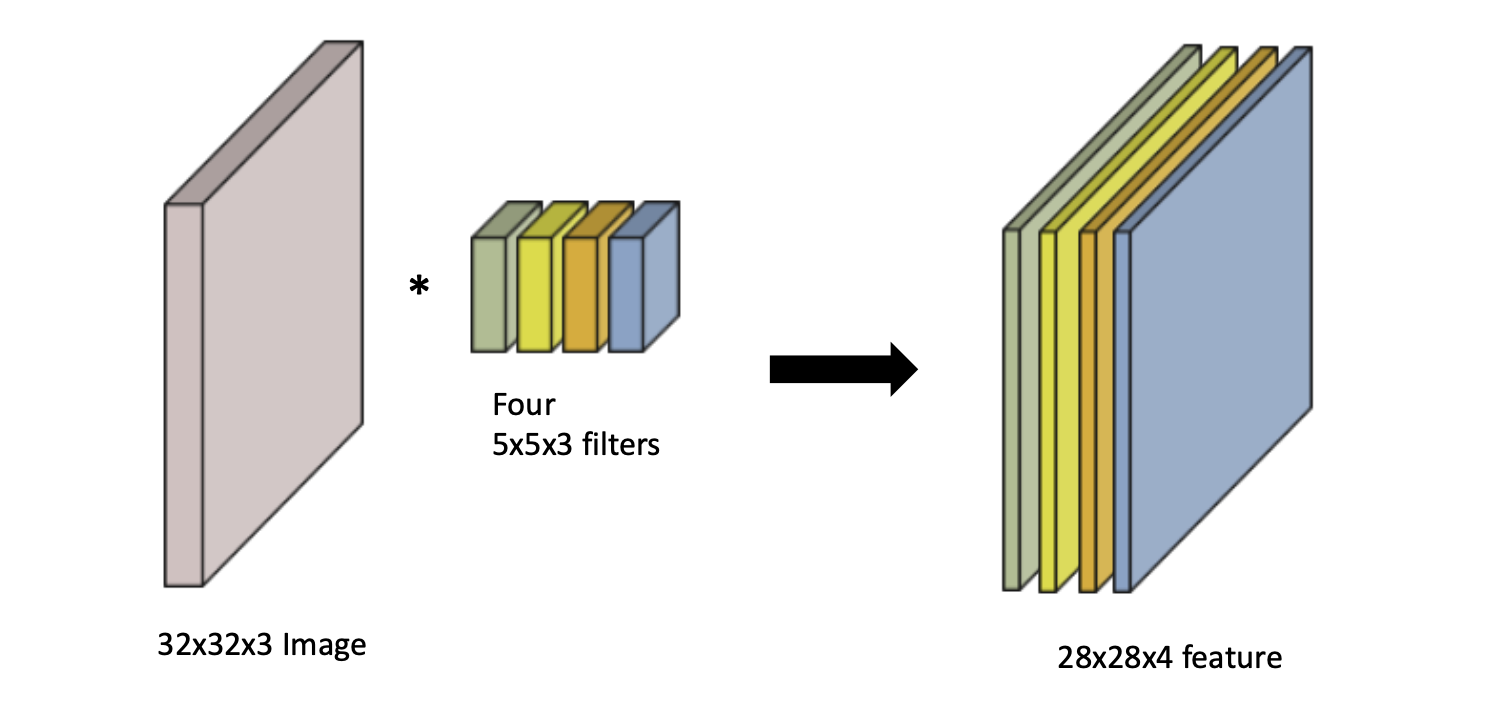
구체적으로 보면 입력으로 32x32 크기의 컬러 이미지가 들어왔다고 가정하자.
4개의 5x5크기의 필터를 사용하고, stride=1, padding='valid'라는 가정하에 1개의 필터는 28x28 크기의 출력을 보일 것이다.
이러한 필터가 4개 존재하므로 전체 출력은 28x28x4이다.
3. 풀링(서브 샘플링)
CNN에서는 Convolution 연산을 수행한 후에 Pooling을 수행한다고 하였다.
Pooling의 역할은 아래와 같다.
입력 데이터를 요약하는 연산
Convolution Layer의 출력 데이터를 입력으로 받아서 출력 데이터의 크기를 줄이거나, 특정 데이터를 강조한다.
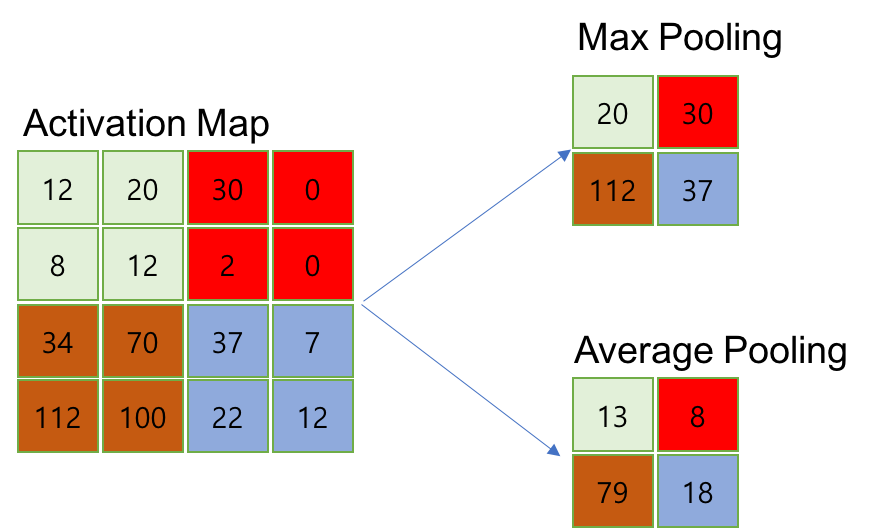
주로 사용되는 Pooling의 종류는 아래와 같다.
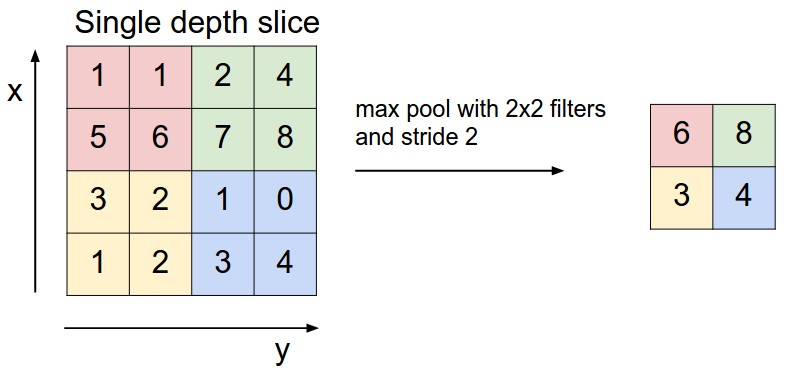
- Max Pooling👍
- Average Pooling👍
- Min Pooling
Pooling의 장점은 아래와 같다.
- 레이어의 크기가 작아지므로 계산이 빨라진다.
- 레이어의 크기가 작아진다는 것은 신경망의 매개변수가 작아진다는 것을 의미한다. 따라서 과잉적합이 나올 가능성이 줄어든다.
- 물체의 공간 이동에 대해서 둔감해지게 된다.😯⭐
아래의 세 번째 이유가 가장 중요하고, Pooling을 사용하는 이유이다.
예를 들어 보자.
추출하고 싶은 고양이가 이미지의 왼쪽 위에 있다.
그럼 Pooling 했을 때 왼쪽 위에 수치가 높게 나타날 것이다.
그런데 고양이가 오른쪽 아래로 평행이동한다면, Pooling했을 때 수치에 의해 오른쪽 아래에 있다는 것을 동일하게 인식할 수 있을 것이다.
이것을 영상처리에서 평행이동-불변(Translation-invariant)라고 한다.
CNN의 중요한 기본 개념(Filter/Kernel, Stride, Padding, Pooling)과 구조에 대해서 살펴보았다.
다음부터는 CNN에 대해 조금 더 구체적으로 살펴볼 것이다!
참고 자료
https://velog.io/@sdubee10/%EB%94%A5%EB%9F%AC%EB%8B%9D-CNN-Convolutional-Neural-Network
https://amber-chaeeunk.tistory.com/24
https://lemidia.github.io/development/boostcamp-week3-day13/
http://taewan.kim/post/cnn/
