
문제
타이타닉의 생존자 예측
Kaggle의 타이타닉 데이터
데이터셋 확인📚
import numpy as np
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
train = pd.read_csv("./titanic/train.csv", sep=",")
test = pd.read_csv("./titanic/test.csv", sep=",")
print("데이터 feature값:",train.columns)
print("훈련 데이터 길이:",len(train))
시각화
성별('Sex')에 따라 그룹화 하고, 생존여부('Survived')의 평균을 낸 것이다.
여성의 생존률이 높은 것을 확인할 수 있다.
df = train.groupby("Sex").mean()['Survived']
df.plot(kind='bar')
plt.show()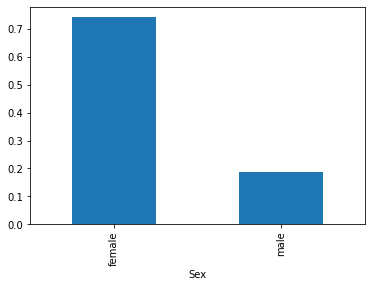
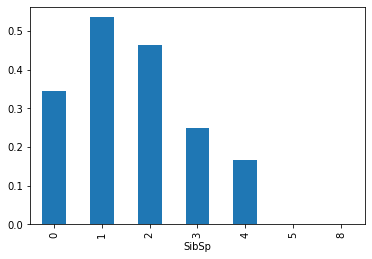
다른 Feature들에 대해서도 평균을 내보았다.
Pclass(티켓 등급)
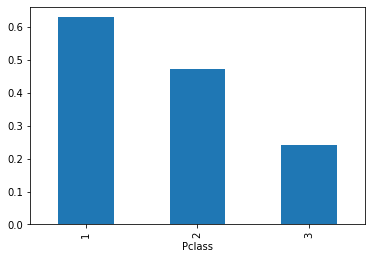
Age(나이)
SibSp(타이타닉호에 탑승한 형제자매/배우자 수)
Parch(타이타닉호에 탑승한 부모/자녀 수)
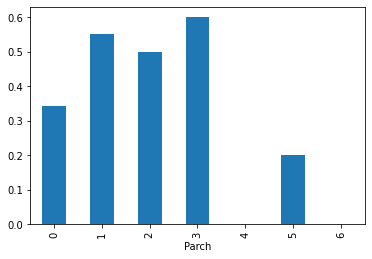
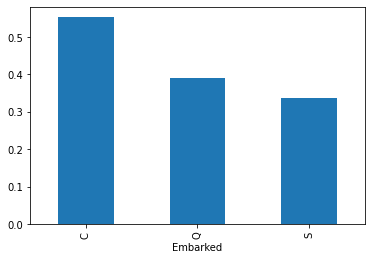
Embarked(승선항)
시각적으로
Sex(성별),Pclass(티켓 등급),Embarked(승선항)이 생존률과 상관관계가 있어보인다. 따라서 해당 Feature에 대해서만 모델을 구현해보자.
학습 데이터 정제🧽
Feature Select, 결측값 제거
위의 3개의 Feature와 Survived(생존여부)를 제외한 나머지 컬럼값들 그리고 결측값이 있는 데이터(NaN) 행들을 제거해주었다.
train.drop(['PassengerId','Name','Age','SibSp','Parch','Ticket','Fare','Cabin'],
inplace=True,
axis = 1)
train.dropna(inplace=True)
print("정제된 훈련 데이터 길이:",len(train))
print(train.head())inplace는 기존의 데이터 프레인을 변경하라는 의미이고,
axis=1은 축번호 1번 즉 Column을 삭제하라는 의미이다.

범주형 자료형 데이터 처리
# 범주형 데이터 처리('Sex', 'Embarked')
for ix in train.index:
# 성별
if train.loc[ix, 'Sex'] =='male':
train.loc[ix, 'Sex']=1
else:
train.loc[ix, 'Sex']=0
# 승선항
if train.loc[ix, 'Embarked'] =='C':
train.loc[ix, 'Embarked'] =0
elif train.loc[ix, 'Embarked']=='Q':
train.loc[ix, 'Embarked']=1
else:
train.loc[ix, 'Embarked']=2
print(train.head())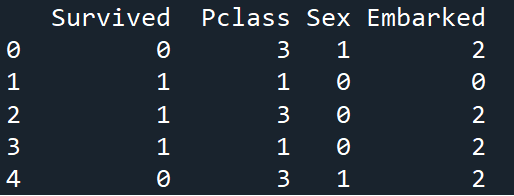
Label(Survived)값 추출
우리의 목표 출력값은 생존률 즉 Survived이므로 이를 추출하여 np.ravel()을 이용하여 1차원 배열로 만들어준다.
# Label값 추출
target= np.ravel(train.Survived)
train.drop(['Survived'], inplace = True, axis = 1)
train = train.astype(float)모델 구축하기🍱
해당 문제는 생존 혹은 생존하지 못함으로 분류하는 이진 분류 문제이다.
따라서 Sigmoid 출력층을 사용하였고, 입력층과 출력층 사이의 은닉층은 모두 Relu 활성화 함수를 사용하였으며, 가운데에 Dropout()을 호출하여 과잉적합을 방지하였다.
## 모델 구축하기
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(32, activation='relu',input_shape=(3,)))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'],
)전체 코드😊
import numpy as np
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
train = pd.read_csv("./titanic/train.csv", sep=",")
test = pd.read_csv("./titanic/test.csv", sep=",")
print("데이터 feature값:",train.columns)
print("훈련 데이터 길이:",len(train))
# 사용하지 않는 컬럼 제거
train.drop(['PassengerId','Name','Age','SibSp','Parch','Ticket','Fare','Cabin'],
inplace=True,
axis = 1)
test.drop(['PassengerId','Name','Age','SibSp','Parch','Ticket','Fare','Cabin'],
inplace=True,
axis = 1)
# 결측값 제거
train.dropna(inplace=True)
print("정제된 훈련 데이터 길이:",len(train))
print(train.head())
# 범주형 데이터 처리('Sex', 'Embarked')
for ix in train.index:
# 성별
if train.loc[ix, 'Sex'] =='male':
train.loc[ix, 'Sex']=1
else:
train.loc[ix, 'Sex']=0
# 승선항
if train.loc[ix, 'Embarked'] =='C':
train.loc[ix, 'Embarked'] =0
elif train.loc[ix, 'Embarked']=='Q':
train.loc[ix, 'Embarked']=1
else:
train.loc[ix, 'Embarked']=2
# 검증 데이터와 훈련 데이터 분리 약 10:1
tr = train.loc[:800]
ts = train.loc[800:]
# Label값 추출
tr_label= np.ravel(tr.Survived)
tr.drop(['Survived'], inplace = True, axis = 1)
tr = tr.astype(float)
ts_label = np.ravel(ts.Survived)
ts.drop(['Survived'], inplace = True, axis = 1)
ts = ts.astype(float)
## 모델 구축하기
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(32, activation='relu',input_shape=(3,)))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'],
)
history = model.fit(tr,
tr_label,
validation_data = (ts, ts_label),
epochs = 30,
batch_size = 32,
verbose = 2)
# 훈련 데이터의 손실값과 검증 데이터의 손실값을 그래프에 출력
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
acc = history_dict['accuracy']
epochs = range(1, len(acc)+1)
plt.plot(loss_values)
plt.plot(val_loss_values)
plt.xlabel("epoch")
plt.ylabel('loss')
plt.legend(['train error','test error'], loc='upper left')
plt.show()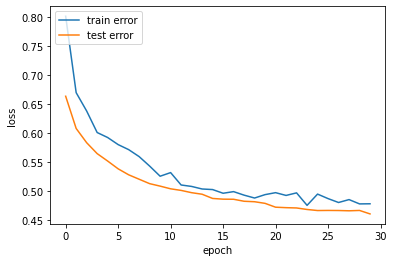
Kaggle 제출✏️
모델 만들어본 김에 제출해보고 싶어졌다.
이전에 머신러닝으로 선형 회귀 모델(knn), RandomForest모델, xgBoost 등을 사용하여 이런 곳에 제출한 적은 있지만, 딥러닝 모델로는 제출해본 적이 없다. 따라서 이번에 첫 도전!ㅎㅎ
제출한 코드는 아래와 같고
import numpy as np
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
train = pd.read_csv("./titanic/train.csv", sep=",")
test = pd.read_csv("./titanic/test.csv", sep=",")
print("데이터 feature값:",train.columns)
print("훈련 데이터 길이:",len(train))
# 사용하지 않는 컬럼 제거
train.drop(['PassengerId','Name','Age','SibSp','Parch','Ticket','Fare','Cabin'],
inplace=True,
axis = 1)
passengerId = test[['PassengerId']]
test.drop(['PassengerId','Name','Age','SibSp','Parch','Ticket','Fare','Cabin'],
inplace=True,
axis = 1)
# 결측값 제거
train.dropna(inplace=True)
print("정제된 훈련 데이터 길이:",len(train))
print(train.head())
# 범주형 데이터 처리('Sex', 'Embarked')
for ix in train.index:
# 성별
if train.loc[ix, 'Sex'] =='male':
train.loc[ix, 'Sex']=1
else:
train.loc[ix, 'Sex']=0
# 승선항
if train.loc[ix, 'Embarked'] =='C':
train.loc[ix, 'Embarked'] =0
elif train.loc[ix, 'Embarked']=='Q':
train.loc[ix, 'Embarked']=1
else:
train.loc[ix, 'Embarked']=2
for ix in test.index:
# 성별
if test.loc[ix, 'Sex'] =='male':
test.loc[ix, 'Sex']=1
else:
test.loc[ix, 'Sex']=0
# 승선항
if test.loc[ix, 'Embarked'] =='C':
test.loc[ix, 'Embarked'] =0
elif test.loc[ix, 'Embarked']=='Q':
test.loc[ix, 'Embarked']=1
else:
test.loc[ix, 'Embarked']=2
# 검증 데이터와 훈련 데이터 분리 약 10:1
tr = train.loc[:800]
ts = train.loc[800:]
# Label값 추출
tr_label= np.ravel(tr.Survived)
tr.drop(['Survived'], inplace = True, axis = 1)
tr = tr.astype(float)
ts_label = np.ravel(ts.Survived)
ts.drop(['Survived'], inplace = True, axis = 1)
ts = ts.astype(float)
## 모델 구축하기
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(32, activation='relu',input_shape=(3,)))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy'],
)
history = model.fit(tr,
tr_label,
validation_data = (ts, ts_label),
epochs = 30,
batch_size = 32,
verbose = 2)
# 훈련 데이터의 손실값과 검증 데이터의 손실값을 그래프에 출력
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
acc = history_dict['accuracy']
epochs = range(1, len(acc)+1)
plt.plot(loss_values)
plt.plot(val_loss_values)
plt.xlabel("epoch")
plt.ylabel('loss')
plt.legend(['train error','test error'], loc='upper left')
plt.show()
## 제출물 생성
test = test.astype(float)
result = model.predict(test)
threshold = 0.5
result_binary = (result>threshold).astype(int)
result_df = pd.DataFrame(result_binary, columns = ['Survived'])
result = pd.concat([passengerId, result_df], axis =1)
result.to_csv('submission.csv', index = False)
.
.
.
결과는 아래와 같다.😊
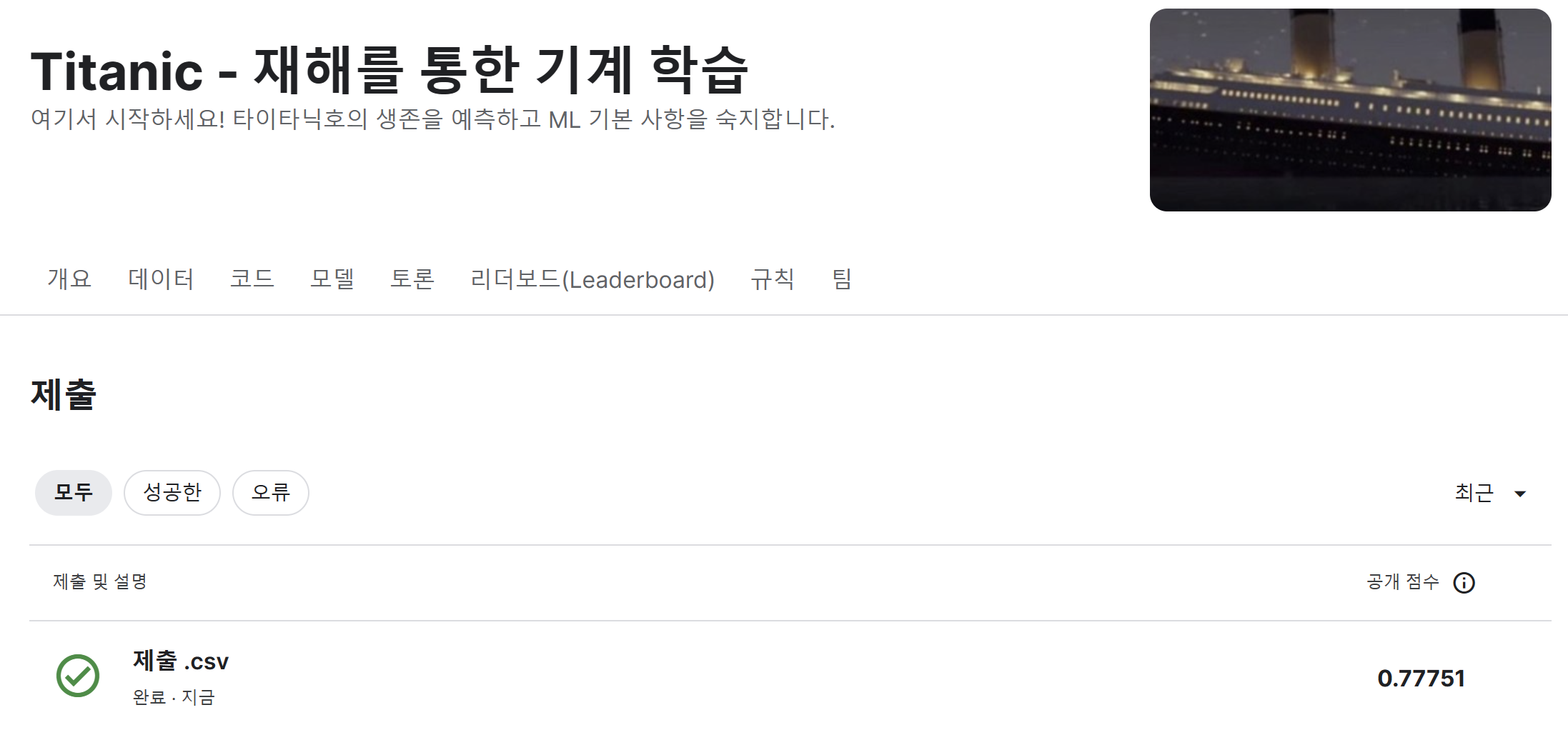
ㅎ..ㅎ 정확도는 낮지만 그래도 오랜만에 csv파일도 만들어보고 데이터 프레임 연결도 해보고..!
의미있었다! 이제 9장으로 넘어가자~
