- ✅ 만 정리가 완벽하게 끝난 부분, 논문을 조금 발췌독함..
- 시간날 때마다 틈틈이 추가할 예정!
- Citation: Minaee, S., Mikolov, T., Nikzad, N., Chenaghlu, M., Socher, R., Amatriain, X., & Gao, J. (2024). Large language models: A survey. arXiv preprint arXiv:2402.06196.
✅ Abstract
- 여기서는 3가지 가장 인기있는 LLM Families (GPT, LLaMA, PaLM)을 포함하여 가장 눈에 띄는 LLM을 review하고, 그 특징과 기여도, 한계에 대해 논의하고 있음
- LLM을 구축하고 보강하기 위해 개발된 기술도 제공하고 있음
- How LLMs are built
- How LLMs are used and augmented
- LLM Training과 Fine-tuning, Evaluation을 위해 준비된 인기있는 데이터셋에 대한 조사
- Popular Dataset for LLMs
- 널리 사용되는 LLM 평가지표 검토
- ✅ 6-A. Popular Metrics for Evaluating LLMs - 대표적인 벤치마크 세트에서 여러 인기 있는 LLM의 성능 비교
- Prominent LLMs’ Performance on benchmarks
- 미해결 과제와 향후 연구 방향 논의함
- 7. Challenges and Future Directions
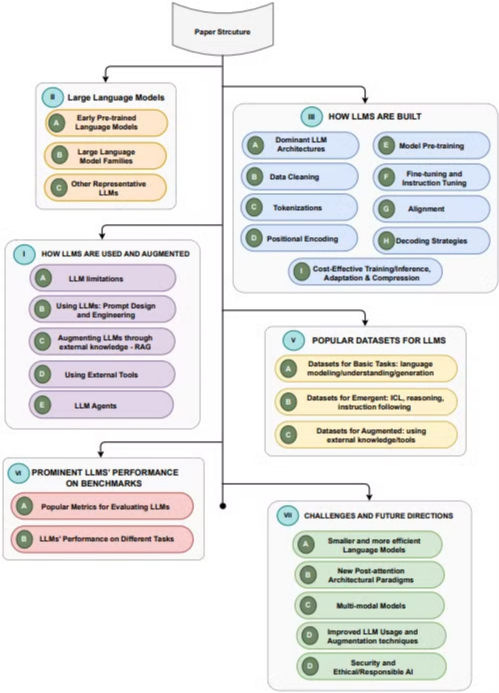
✅ 1. Introduction

- Language Modeling이란:
- 1950년대에 섀넌이 정보 이론을 인간의 언어에 적용하여 간단한 n-그램 언어 모델이 자연어 텍스트를 얼마나 잘 예측하거나 압축하는지 측정한 것에서 시작된 오랜 연구 주제
- Statistical Language Models (SLMs):
- 텍스트를 하나의 Sequence of words로 간주
- 단어의 확률을 곱한 값으로 텍스트의 확률을 추정하는 것
- SLM의 지배적인 형태: -gram (a.k.a Markov Chain Models)
- n-1 단어의 바로 다음에 오는 단어에 대한 확률을 계산하는 것
- 단어 확률 계산하는 방법: 텍스트 말뭉치(text corpora) 에서 수집된 단어와 n-gram 수를 사용하여 추정
- 데이터 희소성을 처리해야 함
- e.g., 일부 보이지 않는 단어나 n-gram에 0 확률을 할당해준다거나, …
- 많은 NLP 시스템에서 널리 사용되지만, 데이터 희소성 문제 때문에 자연어의 다양성과 가변성을 완전히 포착할 수 없어 불완전함이 존재함
- n-1 단어의 바로 다음에 오는 단어에 대한 확률을 계산하는 것
- Neural Language Models (NLMs):
- 단어를 저차원 연속 벡터(embedding vector)에 매핑하여 데이터 희소성 처리
- 신경망을 사용해 다음 단어의 Embedding Vector의 합계를 기반으로 다음 단어를 예측
- 임베딩 벡터: 벡터간 의미적 유사성을 거리로 쉽게 계산할 수 있는 hidden space 정의
- 딱히 형태(forms)나 modality에 관계없이, 두 입력의 의미적 유사성을 계산할 수 있음!
- e.g., 웹 검색에서의 쿼리와 문서라던지, machine translation에서 서로 다른 언어로 된 문장, 이미지 캡셔닝에서의 이미지와 텍스트, …
- 초기 NLM: task-specific (그런 데이터에 학습된 hidden space, 결국 task-specific model)
- Pre-trained Language Models (PLMs):
- vs. 초기 NLM: task-agnostic (task에 구애받지 않음)
- 이런 generality는 학습된 hidden embedding space에도 적용됨
- Pre-training & Fine-tuning Paradigm
- RNN이나 Transformer가 포함된 Langugage Model을 단어 예측과 같은 일반 작업을 위해 웹 규모의 레이블 없는 text corpora로 pretrain한 다음, 소량의 레이블이 있는 task-specific 데이터를 사용하여 특정 작업에 맞게 finetune하는 것
- Large Language Models(LLMs):
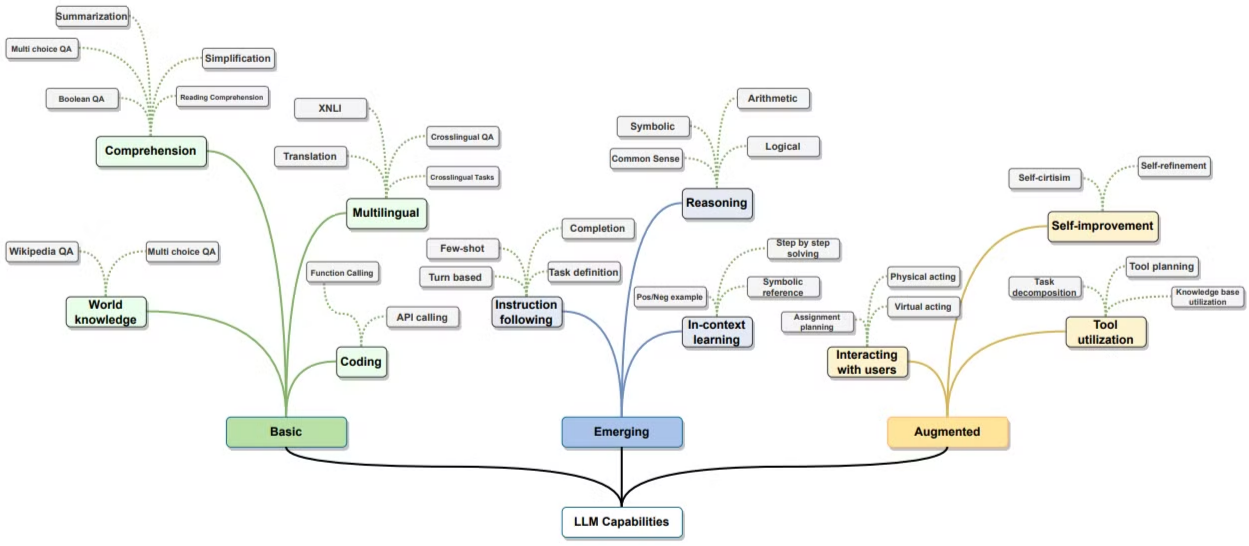
Fig 1. LLM Capabilities.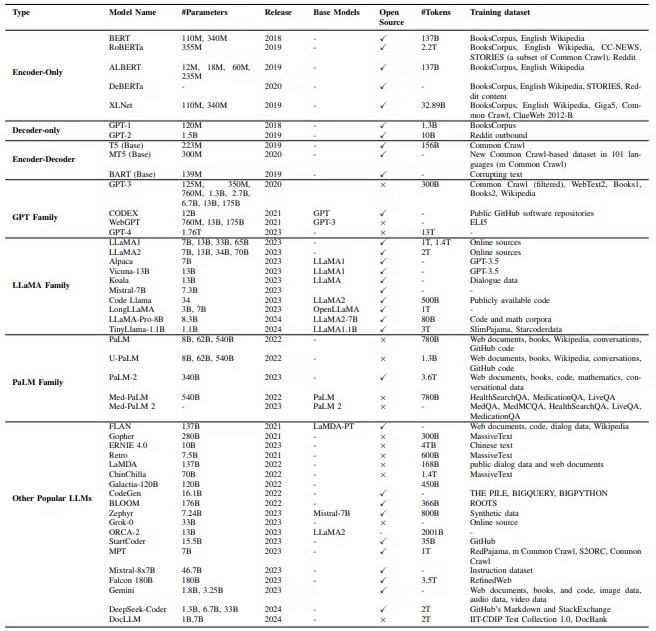
Table 1: High-level Overview of Popular Language Models- Neural Network 기반의 Pre-trained한 대규모 Statistical Language Model ..
(앞선 내용을 모두 합치고 대규모로 학습된 것을 의미) - 주로 transformer-based neural language model임
- 대규모 텍스트 데이터로 pretrain된 수백 억에서 수천 억개의 parameters 포함하고 있음
- (vs. PLMs): 모델 크기 훨씬 크고, 언어 이해 및 생성 능력이 더 뛰어남, emergent 능력을 새롭게 발휘함
- In-Context Learning: 추론 시, prompt에 제시된 작은 예제 세트에서 새로운 과제를 학습하는 상황 내 학습
- Instruction Following: Instruction Tuning 이후, 명시적인 예제를 사용하지 않고 새로운 유형의 작업에 대한 지시를 따름
- Multi-step Reasoning: LLM이 복잡한 과제를 Chain-of-thought prompt에서 보여준 것처럼 중간 추론 단계로 분해하여 해결할 수 있는 단계를 포함
- Augment Method:
- External Knowledge와 Tool을 사용하여 사용자 및 환경과 효과적으로 상호작용하고, 상효작용을 통해 수집된 피드백 데이터를 사용하여 (e.g., via reinforcement learning w/ human feedback (RLHF))
- AI Agent로의 배포 가능: advanced usage & augmentation기술 사용해서 환경 감지 및 의사결정할 수 있기 때문 (Section IV에서 자세히 설명)
- Neural Network 기반의 Pre-trained한 대규모 Statistical Language Model ..
2. Large Language Models

- 집중 논의: GPT, LLaMA, PaLM
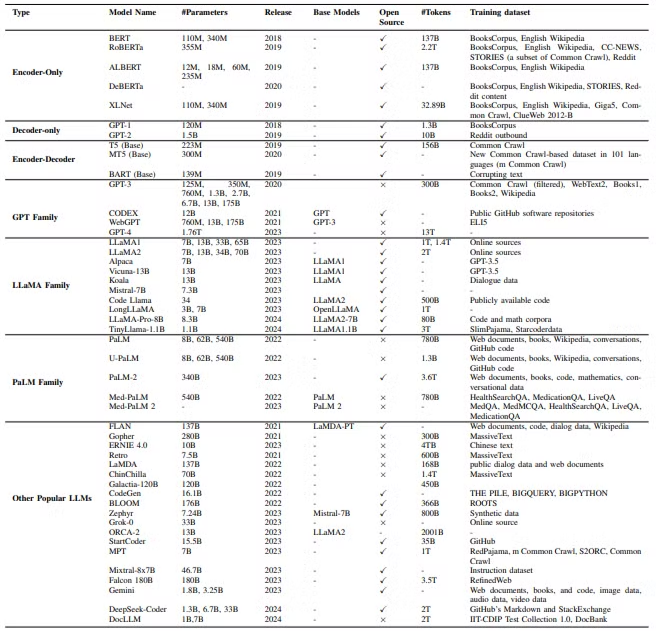
Table 1: High-level Overview of Popular Language Models
2-A. Early Pre-trained Neural Language Models
2-A1. Encoder-only PLMs
- encoder 네트워크로만 구성
- text classification과 같이 입력ㄹ 텍스트의 클래스 레이블을 예측해야하는 언어 이해 작업을 위해 주로 개발됨
- 대표적인 인코더 전용 모델: BERT, RoBERTa, ALBERT, DeBERTa, XLM, XLNet, UNILM
- BERT(Birectional Encoder Representations from Transformers):
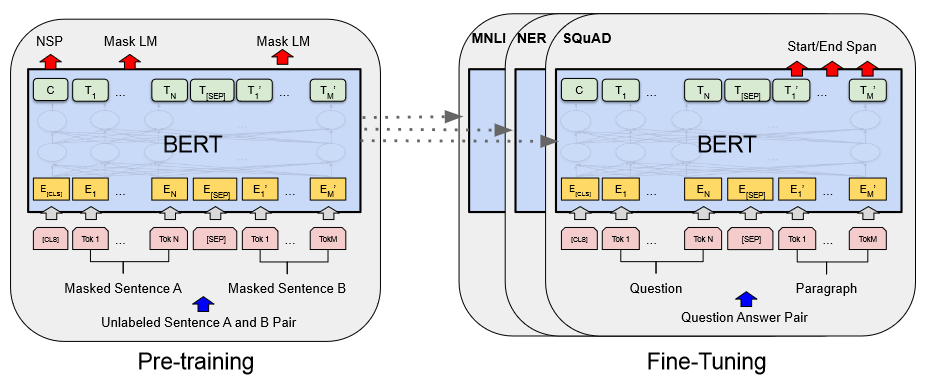
Figure 3:Overall pre-training and fine-tuning procedures for BERT. Courtesy of- 3가지 모듈로 구성
- Embedding Module: 입력 텍스트 → 일련의 임베딩 벡터(sequence of embedding vector)
- a stack of Transformer encoders: 임베딩 벡터 → 문맥 표현 벡터(contextual representation vectors)
- Fully Conncected layer: 표현 벡터 → 원핫 벡터로 변환 (at final layer)
- 2가지 목표를 사용해 사전 학습
- Masked Language Model(MLM)
- 다음 문장 예측
- pre-trained BERT can be fine-tuned:
- classifier layer 추가 시, text classfication, question answering 등 다양한 언어 이해 작업 O
- BERT 기반 다른 모델들이 이후 등장
- RoBERTa
- ALBERT
- DeBERTa
- ELECTRA
- XLMs
- 3가지 모듈로 구성
- Auto-regressive (decoder) model의 장점을 활용하는 모델 존재
- XLNet
- UNILM
2-A2. Decoder-only PLMs
- decoder-only PLMs 중 가장 널리 사용되는 것은 GPT-1과 GPT-2
- 이후 더 강력해진 GPT-3, GPT-4의 토대가 됨
- GPT-1: 다양한 라벨이 없는 text corpora에 대한 decoder-only transformer 모델의 생성적 자기 훈련(Generative Pre-Training)을 통해 광범위한 자연어 작업에서 우수한 성능을 얻을 수 있음을 처음으로 입증
- GPT-1
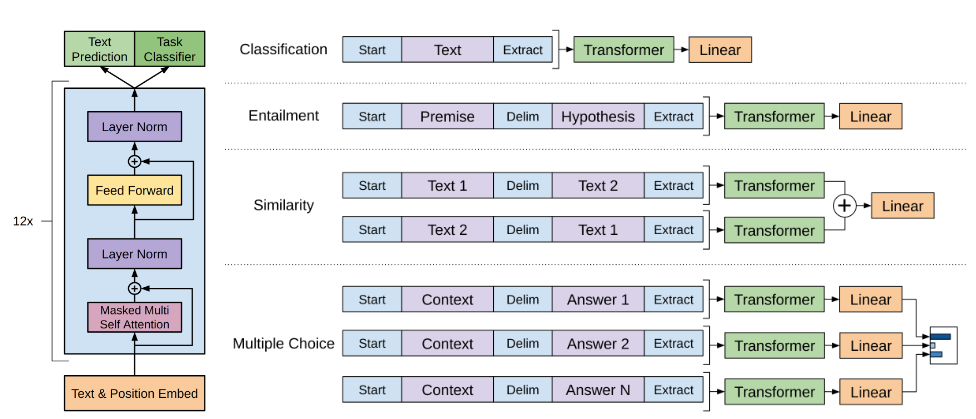
Figure 7:High-level overview of GPT pretraining, and fine-tuning steps. Courtesy of OpenAI.
2-B. Large Language Model Families
- LLM: 주로 수백억에서 수천억 개의 파라미터를 포함하는 트랜스포머 기반 PLM
- 위에서 검토한 PLM에 비해 LLM은 모델 크기가 훨씬 클 뿐만 아니라, 소규모 모델에서는 볼 수 없는 강력한 언어 이해 및 생성 능력과 emergent ability를 제공합니다.
✅ 2-B1 The GPT Family
- OpenAI에서 개발한 디코더 전용 트랜스포머 기반 언어 모델 제품군
- GPT-1, GPT-2, GPT-3, InstrucGPT, ChatGPT, GPT-4, CODEX 및 WebGPT로 구성
- Open Source: (초기모델) GPT-1 및 GPT-2
- Closed Source: (최신모델) GPT-3 및 GPT-4와 같은 최신 모델, API를 통해서만 액세스 가능
- GPT-1, GPT-2, GPT-3, InstrucGPT, ChatGPT, GPT-4, CODEX 및 WebGPT로 구성
- GPT-3: 사전 학습된 자동 회귀 언어 모델, 1,750억 개의 파라미터
- GPT-3는 이전 PLM보다 훨씬 클 뿐만 아니라 이전의 소규모 PLM에서는 볼 수 없었던 새로운 능력을 처음으로 보여줬다는 점, 최초의 LLM
- In-Context Learning의 새로운 능력을 보여주며, 이는 모델과의 텍스트 상호 작용만으로 지정된 작업과 few-shot demonstrations를 통해 gradient 업데이트나 fine-tuning 없이 모든 downstream task에 적용할 수 있음을 의미
- 번역, QA, Cloze 작업 등 많은 NLP 작업은 물론 단어 스크램블링, 문장의 새로운 단어 사용, 3자리 산술 등 즉각적인 추론이나 domain-adaptation이 필요한 여러 작업에서 강력한 성능을 달성함
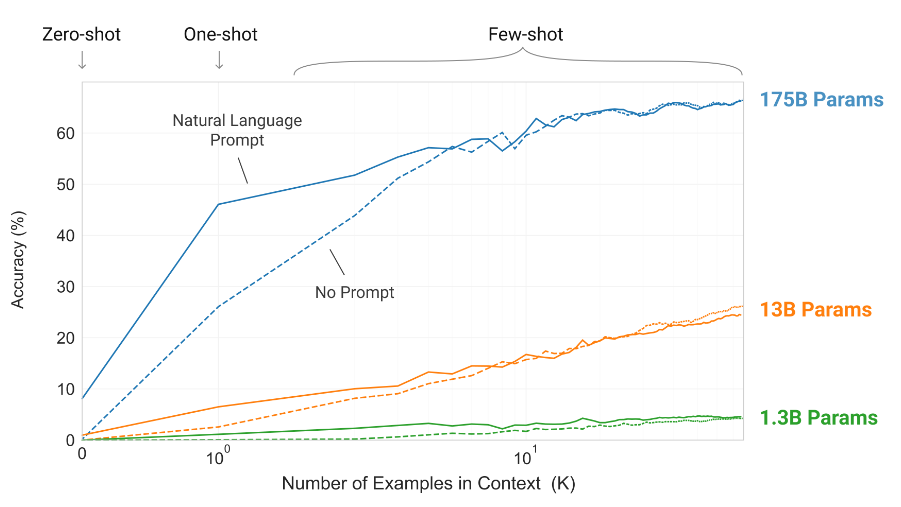
Figure 9: 문맥 내 프롬프트의 예제 수에 따른 GPT-3의 성능을 그래프로 나타낸 것
- WebGPT: 텍스트 기반 웹 브라우저를 사용하여 개방형(open-ended) 질문에 답하도록 Fine-tuned되어 사용자가 웹을 쉽게 검색하고 탐색할 수 있도록 하는 GPT-3의 또 다른 후손
- 3가지 학습 단계:
- 사람의 데모 데이터를 사용하여 WebGPT가 사람의 브라우징 행동을 모방하는 방법을 학습하는 것
- 그런 다음 사람의 선호도를 예측하기 위해 보상 함수를 학습
- 마지막으로 강화 학습과 거부 샘플링을 통해 보상 함수를 최적화하도록 WebGPT를 개선
- 3가지 학습 단계:
- InstructGPT: LLM이 예상되는 사람의 지시를 따르도록 하기 위해 사람의 피드백으로 Fine-tune하여 광범위한 작업에 대한 사용자 의도에 맞게 언어 모델을 조정
- 라벨러가 작성한 프롬프트와 OpenAI API를 통해 제출된 프롬프트 세트부터 시작하여 원하는 모델 동작의 라벨러 데모 데이터 세트가 수집
- 그런 다음 이 데이터 세트에 대해 GPT-3를 Fine-tune
- 그런 다음 강화 학습을 사용하여 모델을 더욱 Fine-tune하기 위해 사람이 평가한 모델 출력의 데이터 세트를 수집
- 인간 피드백을 통한 강화 학습(RLHF)으로 알려져 있음
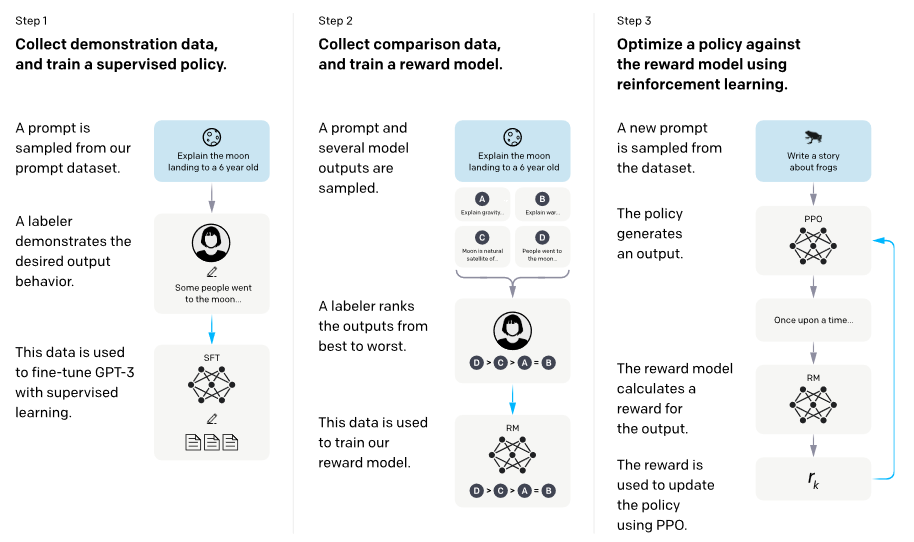
Figure 10: The high-level overview of RLHF.
- 인간 피드백을 통한 강화 학습(RLHF)으로 알려져 있음
- 공개 NLP 데이터 세트에서 성능 퇴행을 최소화하면서 진실성이 향상되고 유독성 출력 발생이 감소한 것으로 나타남
- ChatGPT
- GPT-4: GPT 제품군 중 가장 최신의 가장 강력한 LLM
-
2023년 3월에 출시된 GPT-4는 이미지와 텍스트를 입력으로 받아 텍스트 출력을 생성할 수 있다는 점에서 멀티모달 LLM
-
가장 까다로운 실제 시나리오에서는 아직 인간보다 성능이 떨어지지만, 그림 11과 같이 모의 변호사 시험에서 응시자 중 상위 10% 정도의 점수로 합격하는 등 다양한 직업 및 학업 벤치마크에서 인간 수준의 성능을 보여줌
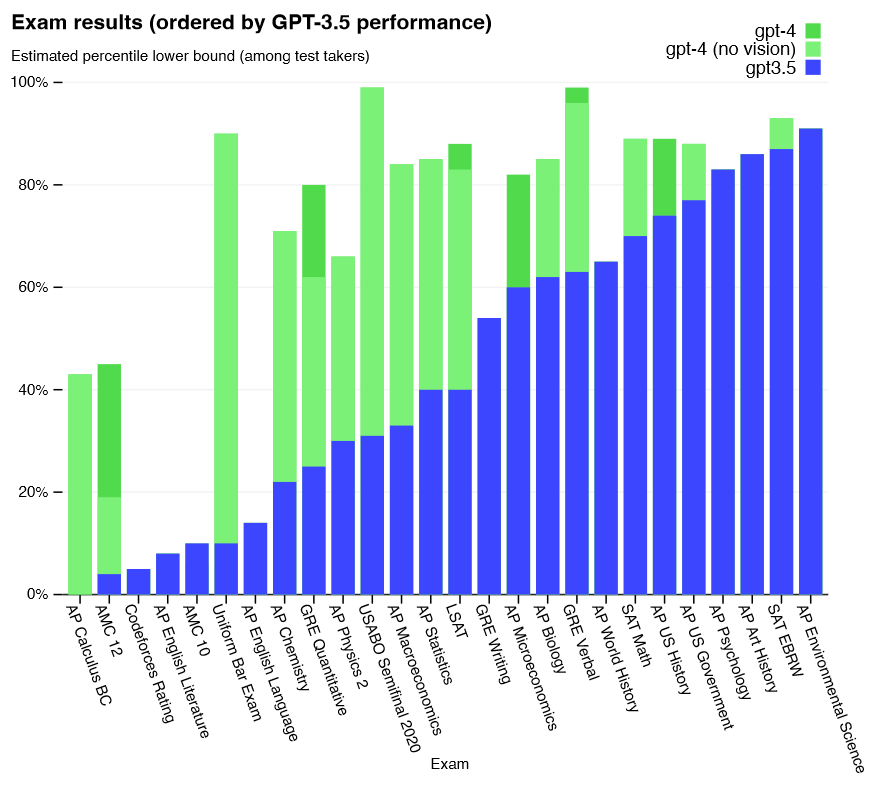
Figure 11:GPT-4 performance on academic and professional exams, compared with GPT 3.5.
-
초기 GPT 모델과 마찬가지로 GPT-4는 먼저 대규모 텍스트 말뭉치에서 다음 토큰을 예측하도록 사전 학습한 다음, RLHF로 미세 조정하여 모델 행동을 사람이 원하는 행동에 맞춤
-
✅ 2-B2 The LLaMA Family
- From Meta, Open Source, 기초 언어 모델 모음(a collection of foundation language models)
- Code LLaMA, Gorilla, Giraffe, Vigogne, Tulu 65B, Long LLaMA, Stable Beluga2 등 LLaMA 또는 LLaMA-2에 구축된 instruction-following 모델이 늘어나면서, LLaMA Family도 빠르게 성장하는 중
- LLaMA: 2023년 2월에 출시, 7B~65B 매개변수 범위로 구성
- 공개적으로 사용 가능한 데이터 세트에서 수집된 수조 개의 토큰에 대해 pre-trained
- GPT-3의 트랜스포머 아키텍처를 사용, 다른 점이 있다면?
- ReLU 대신 SwiGLU 활성화 함수 사용
- 절대 위치 임베딩 대신 회전 위치 임베딩 사용
- 표준 계층 정규화 대신 루트 평균 제곱 계층 정규화 사용 등
- 몇 가지 아키텍처를 약간 수정한 것이 특징!
- 오픈 소스 LLaMA-13B 모델은 대부분의 벤치마크에서 독점적인 GPT-3(175B) 모델보다 성능이 뛰어남
- LLaMA-2 Collections: 2023년 7월 Meta는 Microsoft와 협력 출시, 여기에는 기초 언어 모델과 대화용으로 미세 조정된 채팅 모델인 LLaMA-2 Chat이 모두 포함되어 있음
- LLaMA-2 Chat 모델은 여러 공개 벤치마크에서 다른 오픈 소스 모델을 능가
- LLaMA-2 Chat의 훈련 과정
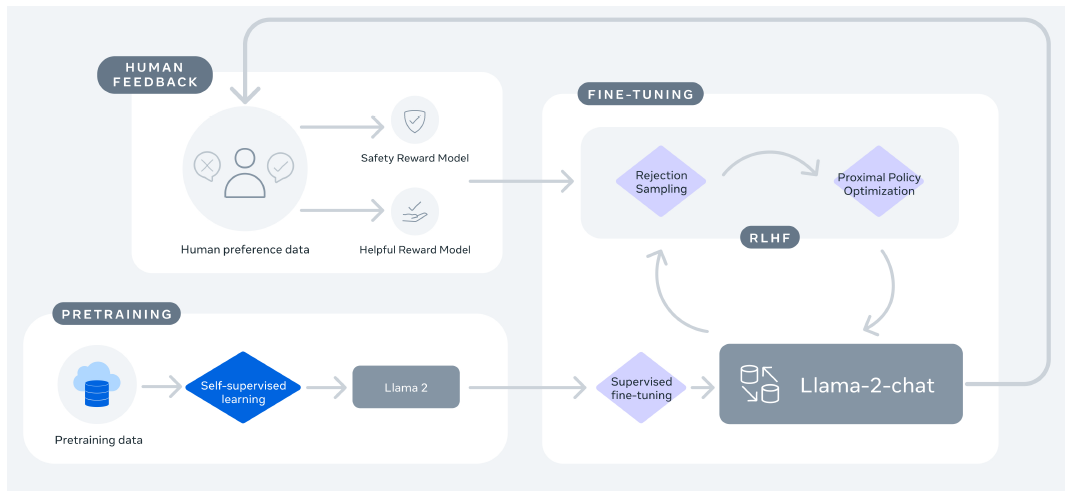
Figure 12:Training of LLaMA-2 Chat.
- 공개적으로 사용 가능한 온라인 데이터를 사용하여 LLaMA-2를 pre-train하는 것으로 시작
- 그런 다음 supervised fine-tuning을 통해 초기 버전의 LLaMA-2 채팅을 구축
- 그 후 RLHF, 거부 샘플링(rejection sampling) 및 근거리 정책 최적화(proximal policy optimization)를 사용하여 모델을 반복적으로 개선
- RLHF 단계에서는, 보상 모델을 수정하기 위한 사람의 피드백을 축적하여 보상 모델이 너무 많이 변경되어 LLaMA 모델 학습의 안정성을 해칠 수 있는 것을 방지하는 것이 중요!
- RLHF 단계에서는, 보상 모델을 수정하기 위한 사람의 피드백을 축적하여 보상 모델이 너무 많이 변경되어 LLaMA 모델 학습의 안정성을 해칠 수 있는 것을 방지하는 것이 중요!
- Alpaca: GPT-3.5(text-davinci-003)를 사용하여 자가 교육(self-instruct) 스타일로 생성된 52K instruction-following 데모를 사용하여 LLaMA-7B 모델에서 fine-tuned 됨
- 교육, 특히 학술 연구에 매우 비용 효율적
- self-instruct evaluation set에서 Alpaca는 훨씬 더 작음에도 불구하고 GPT-3.5와 비슷한 성능을 보임
- Vicuna: ShareGPT에서 수집한 사용자 공유 대화에 대해 LLaMA를 fine-tuning하여 13B 채팅 모델인 Vicuna-13B를 개발
- GPT-4를 평가자로 사용한 예비 평가(Preliminary Evaluation)에 따르면, Vicuna-13B는 OpenAI의 ChatGPT와 Google의 Bard의 품질을 90% 이상 달성하는 동시에 LLaMA와 Stanford Alpaca 같은 다른 모델보다 90% 이상의 경우에서 더 우수한 성능을 발휘하는 것으로 나타남
- 13은 Vicuna와 다른 잘 알려진 모델들의 상대적인 응답 품질을 GPT-4로 비교한 것
- Vicuna-13B의 또 다른 장점은 모델 훈련에 필요한 컴퓨팅 수요가 상대적으로 제한적이라는 점입니다. Vicuna-13B의 훈련 비용은 300달러에 불과하다고 함!
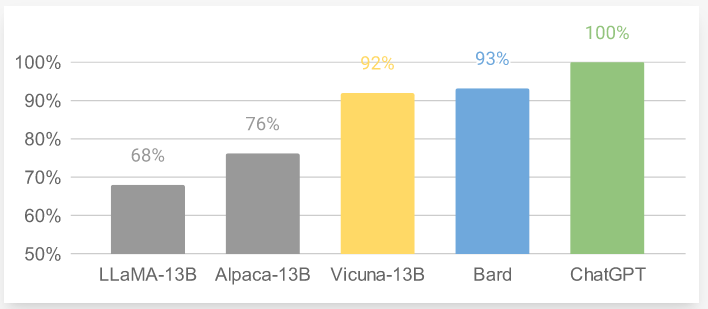
Figure 13:Relative Response Quality of Vicuna and a few other well-known models by GPT-4. Courtesy of Vicuna Team.
- Guanaco: 알파카 및 비쿠나와 마찬가지로 instructions-following 데이터를 사용하여 LLaMA 모델을 fine-tune
- Fine-tune Method: QLoRA를 사용
- QLoRA는 고정된 4비트 양자화된 pre-trained된 언어 모델을 통해 gradient를 Low Rank Adapter(LoRA)로 역전파함
- 매우 효율적으로 이루어지므로 단일 48GB GPU에서 65B 파라미터 모델을 Fine-tuning할 수 있음.
- 최고의 Guanaco 모델은 Vicuna 벤치마크에서 이전에 출시된 모든 모델보다 성능이 뛰어나며, 단일 GPU에서 24시간의 fine-tuning만 거치면 ChatGPT의 99.3% 성능 수준에 도달할 수 있음
- Fine-tune Method: QLoRA를 사용
- Koala: LLaMA를 기반으로 구축된 또 다른 명령어 추종 언어 모델이지만 ChatGPT와 같은 고성능 비공개 소스 채팅 모델에서 생성된 사용자 입력 및 응답을 포함하는 상호작용 데이터에 특히 중점을 두고 있음.
- Koala-13B 모델 - 실제 사용자 프롬프트에 기반한 사람의 평가에 따라 최첨단 채팅 모델과 경쟁적으로 성능을 발휘함 Mistral-7B[65]는
- Mistral-7B: 뛰어난 성능과 효율성을 위해 설계된 7B 매개변수 언어 모델
-
평가된 모든 벤치마크에서 최고의 오픈 소스 13B 모델(LLaMA-2-13B)과 추론, 수학, 코드 생성에서 최고의 오픈 소스 34B 모델(LLaMA-34B)을 능가하는 성능을 보임
-
grouped-query attention을 활용하여 추론 속도를 높이고, sliding window attention과 결합하여 추론 비용을 줄이면서 임의의 길이의 시퀀스를 효과적으로 처리함
-
2-B3 The PaLM Family
3. How LLMs are built

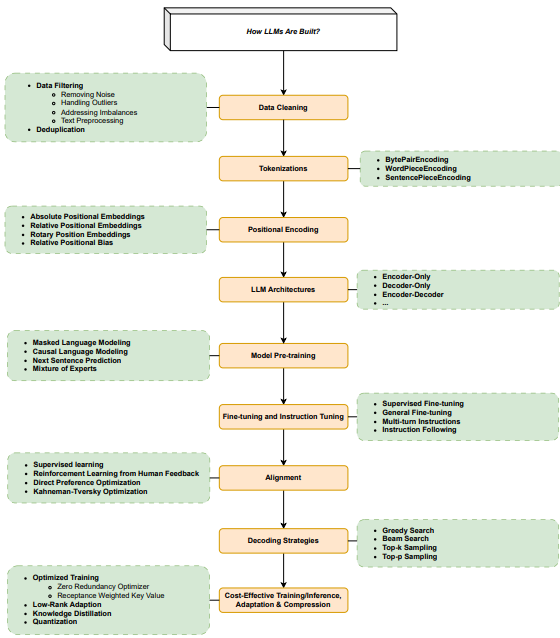
Fig. 25: This figure shows different components of LLMs.
3-A. Dominant LLM Architectures
- 가장 널리 사용되는 LLM 아키텍처: encoder-only, decoder-only, & encoder-decoder
- 대부분 (building block으로서) Transformer를 기반으로 함
- 따라서, 여기서도 Transformer Archietecture 검토
3-A1 Transformer
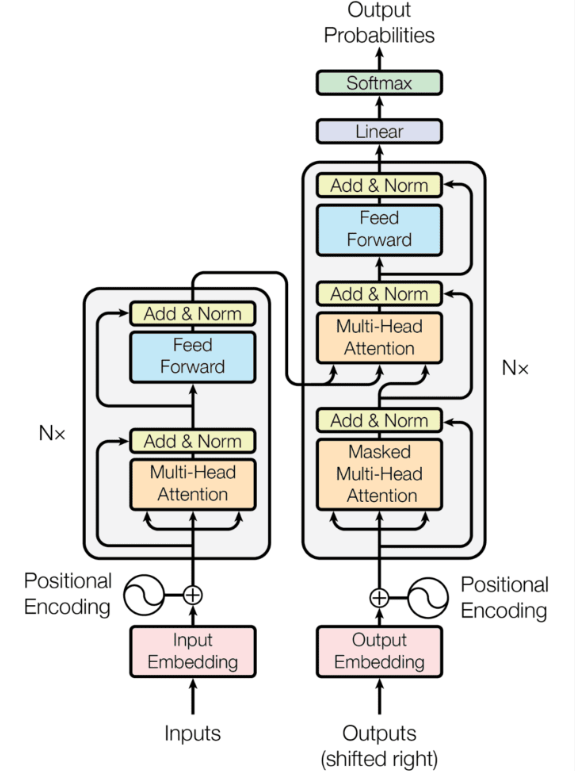
Figure 26:High-level overview of transformer work.
- (Self-)Attention Mechanism:
- (vs. Recurrence & Convolution Mechanism) → GPU 사용하여 훨씬 효과적으로 장기적인 contextual info를 capture 할 수 있음
- (vs. Recurrence & Convolution Mechanism) → GPU 사용하여 훨씬 효과적으로 장기적인 contextual info를 capture 할 수 있음
✅ 3-B. Data Cleaning
- 데이터 품질은 학습된 언어 모델의 성능에 매우 중요함
- 필터링, 중복 제거와 같은 데이터 정리 기술은 모델 성능에 큰 영향을 미침
3-B1 Data Filtering
- 목표: 학습 데이터의 품질과 학습된 LLM의 효율성을 향상시키는 것
- 일반적인 데이터 필터링 기법:
- 노이즈 제거: 모델의 일반화 능력에 영향을 미칠 수 있는 관련성이 없거나 노이즈가 있는 데이터를 제거
- 예를 들어, 학습 데이터에서 잘못된 정보를 제거하여 모델이 잘못된 응답을 생성할 가능성을 낮추는 것
- 품질 필터링을 위한 두 가지 주요 접근 방식: classifier-based과 heuristic-based frameworks
- 이상값 처리: 데이터에서 이상값 또는 이상 징후를 식별하고 처리하여 모델에 불균형적인 영향을 미치지 않도록 함
- 불균형 해결: 편견을 피하고 공정한 대표성을 보장하기 위해 데이터 세트의 클래스 또는 카테고리 분포의 균형을 맞추는 작업
- 텍스트 전처리: Stopwords, 구두점 또는 모델의 학습에 크게 기여하지 않을 수 있는 기타 요소를 제거하여 텍스트 데이터를 정리하고 표준화하는 작업
- 모호성 처리: 학습 중에 모델을 혼란스럽게 할 수 있는 모호하거나 모순되는 데이터를 해결하거나 제외함
- 노이즈 제거: 모델의 일반화 능력에 영향을 미칠 수 있는 관련성이 없거나 노이즈가 있는 데이터를 제거
3-B2 Deduplication
- 데이터 세트에서 중복된 인스턴스 또는 동일한 데이터가 반복적으로 발생하는 것을 제거하는 프로세스
- 중복된 데이터 포인트는 모델 학습 과정에서 편견을 유발하고 다양성을 감소시킴
- 이는 모델이 동일한 사례를 여러 번 학습하여 특정 사례에 대한 과적합을 초래함
- 중복 제거는 보이지 않는 새로운 데이터에 대한 모델의 일반화 능력을 향상시킴
- 중복은 특정 패턴이나 특성의 중요성을 의도치 않게 부풀릴 수 있기 때문에, 중복 제거 프로세스는 대규모 데이터 세트를 다룰 때 특히 중요!
- 구체적인 중복 제거 방법: 데이터의 특성과 학습 중인 특정 언어 모델의 요구 사항에 따라 달라질 수 있음
- 전체 데이터 포인트 또는 특정 기능을 비교하여 중복을 식별하고 제거하는 방법이 포함될 수 있음
- 문서 수준에서 기존 작업은 주로 문서 간 상위 수준의 특징(예: n-그램 중복)의 중복 비율에 의존하여 중복 샘플을 탐지함
✅ 3-C. Tokenizations
- 토큰화: 일련의 텍스트를 토큰이라고 하는 작은 부분으로 변환하는 과정
- 단순히 공백을 기준으로 텍스트를 토큰으로 자르기도 하지만, 대부분의 토큰화 도구는 단어 사전에 의존함
- 그러나 이 경우 토큰화 도구는 사전의 단어만 알고 있기 때문에 어휘 부족(OOV)이 문제!
- 사전의 Coverage를 늘리기 위해 LLM에 사용되는 인기 있는 토큰화기는 훈련 데이터에 없는 단어나 다른 언어의 단어를 포함하여 많은 수의 단어를 조합하여 형성할 수 있는 하위 단어를 기반으로 함
- 아래 세 개가 popular tokenizers!
3-C1 BytePairEncoding
- 원래 바이트 수준에서 빈번한 패턴을 사용하여 데이터를 압축하는 데이터 압축 알고리즘의 일종
- 주로 빈번한 단어는 원래의 형태로 유지하고 흔하지 않은 단어는 분해하려고 함
- 어휘를 그다지 크지 않게 유지하면서도 동시에 일반적인 단어를 표현하기에 충분!
- 또한 접미사나 접두사가 알고리즘의 학습 데이터에 일반적으로 제시되는 경우 빈번한 단어의 형태적 형태도 매우 잘 표현할 수 있음
3-C2 WordPieceEncoding
- 주로 BERT 및 Electra와 같이 매우 잘 알려진 모델에 사용됨
- 학습을 시작할 때 알고리즘은 학습 데이터에서 모든 알파벳을 가져와 학습 데이터 세트에서 UNK 또는 unknown으로 남는 것이 없는지 확인
- 이 경우는 토큰화 도구로 토큰화할 수 없는 입력이 모델에 주어질 때 발생
- 주로 일부 문자가 토큰화할 수 없는 경우에 발생
- 바이트쌍 인코딩과 마찬가지로, 빈도에 따라 모든 토큰을 어휘에 넣을 가능성을 최대화하려고 시도함
3-C3 SentencePieceEncoding
- 앞서 설명한 두 토큰화 방식은 모두 강력하고 공백 토큰화에 비해 많은 장점 O
- but, 단어가 항상 공백으로 구분된다는 가정을 당연하게 받아들임
- 하지만, 실제로 일부 언어에서는 원치 않는 공백이나 심지어는 만들어진 단어와 같은 많은 노이즈 요소로 인해 단어가 손상될 수 있기 때문에, 이 가정이 항상 옳은 것은 아님!
- SentencePieceEncoding은 이 문제를 해결하려고 시도
3-D. Positional Encoding
3-E. Model Pre-training
3-F. Fine-tuning & Instruction Tuning
3-G. Alignment
3-H. Decoding Strategies
3-I. Cost-Effective Training/Inference/Adaptation/Compression
3-I1 Optimized Training
3-I2 Low-Rank Adaption (LoRA)
-
LoRA (낮은 순위 적용): 훈련 가능한 파라미터의 수를 크게 줄이는 대중적이고 가벼운 훈련 기법
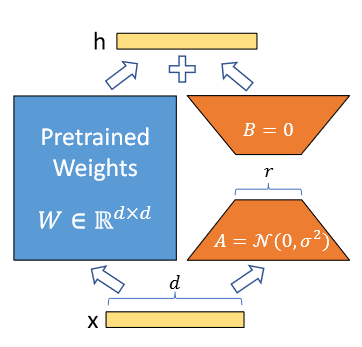
Figure 34:An illustration of LoRA reparametrizan.
- specialize task에 대해 fine-tuned weights와 initial pre-triained weights의 차이가 종종 "low intrinsic rank(낮은 내재 순위)", 즉 낮은 순위 행렬로 잘 근사화될 수 있다는 중요한 통찰에 기반
- 낮은 순위 행렬의 한 가지 특성은 두 개의 작은 행렬의 곱으로 표현할 수 있다는 것
- 이러한 사실은 fine-tuned weights와 initial pre-triained weights 사이의 델타가 훨씬 작은 두 행렬의 행렬 곱으로 표현될 수 있다는 가설로 이어짐
- 원래 가중치 행렬 전체가 아닌 이 두 개의 작은 행렬을 업데이트하는 데 집중함으로써 계산 효율을 크게 향상시킬 수 있음
- 낮은 순위 행렬의 한 가지 특성은 두 개의 작은 행렬의 곱으로 표현할 수 있다는 것
- 훨씬 빠르고 메모리 효율적이며 모델 가중치를 더 작게(수백 MB) 생성하여 저장 및 공유하기가 더 쉬움
- specialize task에 대해 fine-tuned weights와 initial pre-triained weights의 차이가 종종 "low intrinsic rank(낮은 내재 순위)", 즉 낮은 순위 행렬로 잘 근사화될 수 있다는 중요한 통찰에 기반
✅ 3-I3 Knowledge Distillation
-
더 큰 모델에서 학습하는 과정
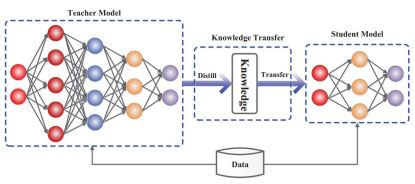
Figure 35: A generic knowledge distillation framework with student and teacher
-
초기에 가장 성능이 우수한 모델이 출시 되면서, API 증류 방식에 사용되더라도 매우 유용하다는 것이 입증됨
-
여러 모델의 지식을 더 작은 모델로 증류하는 접근방식이라고도 함
- 이 접근 방식으로 더 작은 모델을 만들면 엣지 디바이스에서도 사용할 수 있는 더 작은 모델 크기를 얻을 수 있음
-
Knowledge Transfer Forms:
- Response Distillation (반응 증류)
- Teacher 모델의 출력에만 관심을 가지며 Student 모델에게 Teacher과 정확히 또는 최소한 유사하게 수행하는 방법(예측의 의미에서)을 가르치려고 시도
- Feature Distillation (특징 증류)
- 마지막 레이어뿐만 아니라 중간 레이어도 사용하여 Student 모델에 대한 더 나은 내부 표현을 생성함
- 이렇게 하면 Student 모델이 Teacher 모델과 비슷한 표현을 할 수 있음!
- API Distillation (API 증류)
- API(일반적으로 OpenAI와 같은 LLM 제공업체에서 제공하는)를 사용하여 더 작은 모델을 훈련하는 프로세스
- LLM의 경우 더 큰 모델의 직접 출력으로부터 모델을 훈련하는 데 사용되므로 응답 증류와 매우 유사함
- 이러한 유형의 증류는 모델 자체가 공개적으로 사용 가능하지 않은 경우, 최종 사용자에게 (일반적으로) 유료 API가 노출되기 때문에 많은 우려가 제기됨
- 반면에 사용자가 각 호출에 대해 비용을 지불하는 동안 예측을 사용하는 방법은 제한적임
- e.g., OpenAI는 나중에 경쟁에 사용될 LLM을 만드는 데 API를 사용하는 것을 금지함!
- Response Distillation (반응 증류)
✅ 3-I4 Quantization
- 딥러닝의 핵심은 행렬에 적용되는 수학 함수 집합으로, 모델 가중치에 대한 특정 정밀도를 가지고 있음.
- 가중치의 정밀도를 낮추면 모델의 크기를 줄이고 속도를 높일 수 있음
- 예를 들어, Int-8 연산에 비해 Float-32 연산은 느림.
- 양자화라고 하는 이 프로세스는 여러 단계에 걸쳐 적용될 수 있음
- Model Quantization Main Apporach:
- 훈련 후 양자화와 quantization-aware 훈련
- 훈련 후 양자화: 잘 알려진 두 가지 방법, 즉 동적 및 정적 방식으로 훈련된 모델을 양자화하는 것과 관련이 있습니다.
- 동적 학습 후 양자화는 런타임에 양자화 범위를 계산하며 정적에 비해 속도가 느림
- quantization-aware 훈련은 훈련에 양자화 기준을 추가하고, 훈련 과정에서 양자화된 모델을 훈련하고 최적화함
- 이 접근 방식은 최종 모델의 성능이 우수하고 훈련 후에도 정량화할 필요가 없도록 보장함
- 이 접근 방식은 최종 모델의 성능이 우수하고 훈련 후에도 정량화할 필요가 없도록 보장함
- 가중치의 정밀도를 낮추면 모델의 크기를 줄이고 속도를 높일 수 있음
4. How LLMs are used and augmented

- LLM이 학습되면 이를 사용하여 다양한 작업에 대해 원하는 출력을 생성할 수 있음
- LLM은 basic prompting을 통해 바로 사용할 수 있음
- 잠재력을 최대한 활용하거나 몇 가지 단점을 해결하려면 외부 수단을 통해 모델을 보강해야!
## 4-A. LLM Limitations
4-B. Using LLMs: Prompt Design and Engineering
- Prompt: 모델의 출력을 안내하기 위해 사용자가 제공하는 텍스트 입력
- 간단한 질문부터 자세한 설명이나 특정 작업에 이르기까지 다양함
- 일반적으로 지침, 질문, 입력 데이터 및 예제로 구성됨
- 실제로 AI 모델로부터 원하는 응답을 이끌어내기 위해서는, 프롬프트에 지시 사항(Instructions)이나 질문이 포함되어야 하며, 다른 요소는 선택 사항임
- Advanced에는 모델이 논리적 추론 과정을 따라 답변에 도달하도록 유도하는 'Chain-of-thought' 프롬프트와 같은 더 복잡한 구조가 포함됨
- Prompt Engineering: 빠르게 진화하는 분야로, LLM 및 기타 생성형 AI 모델의 상호작용과 결과물을 형성하는 데 사용
- 핵심: 생성 모델을 통해 특정 목표를 달성하기 위한 최적의 프롬프트를 만드는 데 있음
- 이 프로세스에는 모델에 지시를 내리는 것뿐만 아니라 모델의 기능과 한계, 모델이 작동하는 맥락에 대한 이해도 포함됨
- 단순한 프롬프트의 구축을 넘어, 도메인 지식, AI 모델에 대한 이해, 다양한 맥락에 맞게 프롬프트를 조정하는 체계적인 접근 방식이 필요함!
- 주어진 데이터 세트나 상황에 따라 프로그래밍 방식으로 수정할 수 있는 템플릿을 만드는 것이 포함될 수 있음
- e.g., 사용자 데이터를 기반으로 개인화된 응답을 생성하려면 관련 사용자 정보로 동적으로 채워지는 템플릿을 사용할 수 있음.
- 또한 모델 평가나 하이퍼파라미터 튜닝과 같은 전통적인 머신러닝 관행과 유사한 반복적이고 탐색적인 프로세스임
✅ 4-B1 Chain of Thought (CoT)
- Approaches: LLM이 토큰 예측에는 능숙하지만, 본질적으로 명시적 추론을 위해 설계되지 않았다는 점을 이해하는 데 기반 둠!
- CoT는 필수 추론 단계(Essential Reasoning Step)를 통해 모델을 안내함으로써 이 문제를 해결함
- LLM의 암묵적 추론 과정을 명시적으로 만드는 것
- 추론에 필요한 단계를 설명함으로써 모델은 특히 단순한 정보 검색이나 패턴 인식 이상의 것을 요구하는 시나리오에서 논리적이고 합리적인 결과물에 더 가깝게 유도됨
- CoT Prompting
- 2 Primary Forms:
- Zero Shot CoT: 이 형식은 LLM에게 "단계별로 생각하라"고 지시하여 문제를 해체하고, 각 추론 단계를 명확하게 설명하도록 유도하는 것
- Manual CoT: 보다 복잡한 변형으로, 모델의 템플릿으로 단계별 추론 예제를 제공해야 함. 더 효과적인 결과를 얻을 수 있지만 확장성 및 유지 관리에 어려움이 있음.
- Manual CoT는 Zero Shot보다 더 효과적!
- 그러나 example-based CoT의 효과는 다양한 예제의 선택에 달려 있으며, 이러한 단계별 추론 예제로 프롬프트를 수작업으로 구성하는 것은 어렵고 오류가 발생하기 쉬움
- 바로 이 점이 automatic CoT이 필요한 이유
- 그러나 example-based CoT의 효과는 다양한 예제의 선택에 달려 있으며, 이러한 단계별 추론 예제로 프롬프트를 수작업으로 구성하는 것은 어렵고 오류가 발생하기 쉬움
- 2 Primary Forms:
✅ 4-B2 Tree of Thought (ToT)
- The Tree of Thought (ToT) prompting technique:
- Approaches: 다양한 대안 또는 사고 과정을 고려한 후, 가장 그럴듯한 것으로 수렴하는 개념에서 영감
- 각 가지가 서로 다른 추론 과정을 나타내는 여러 개의 '생각의 나무'로 분기하는 아이디어를 기반!
- 이 방법을 사용하면 가장 가능성이 높은 시나리오를 결정하기 전에 여러 시나리오를 고려하는 인간의 인지 과정과 마찬가지로 LLM이 다양한 가능성과 가설을 탐색할 수 있음
- ToT의 중요한 측면은 이러한 추론 경로를 평가하는 것
- LLM은 다양한 사고의 분기를 생성하기 때문에 각 분기의 타당성과 쿼리와의 관련성을 평가함
- 이 과정에는 각 가지를 실시간으로 분석하고 비교하여 가장 일관성 있고 논리적인 결과를 선택하는 과정이 포함됨
- ToT는 한 줄의 추론으로는 충분하지 않을 수 있는 복잡한 문제 해결 시나리오에서 특히 유용!
- 이를 통해 LLM은 결론에 도달하기 전에 다양한 가능성을 고려하여 보다 인간과 유사한 문제 해결 방식을 모방할 수 있음
- Approaches: 다양한 대안 또는 사고 과정을 고려한 후, 가장 그럴듯한 것으로 수렴하는 개념에서 영감
4-B3 Self-Consistency
4-B4 Reflection
4-B5 Expert Prompting
4-B6 Chains
4-B7 Rails
4-B8 Automatic Prompt Engineering (APE)
✅ 4-C. Augmenting LLMs through external knowledge - RAG
- Pre-trained LLM의 주요 한계 중 하나: 최신 지식이 부족하거나 개인 정보 및 사용 사례별 정보에 access를 할 수 없다는 것!
- RAG(Retrieval Augmented Generation, 검색 증강 생성)의 등장!
- RAG System의 Important Components:
- Retrieval, Generation, Augmentation
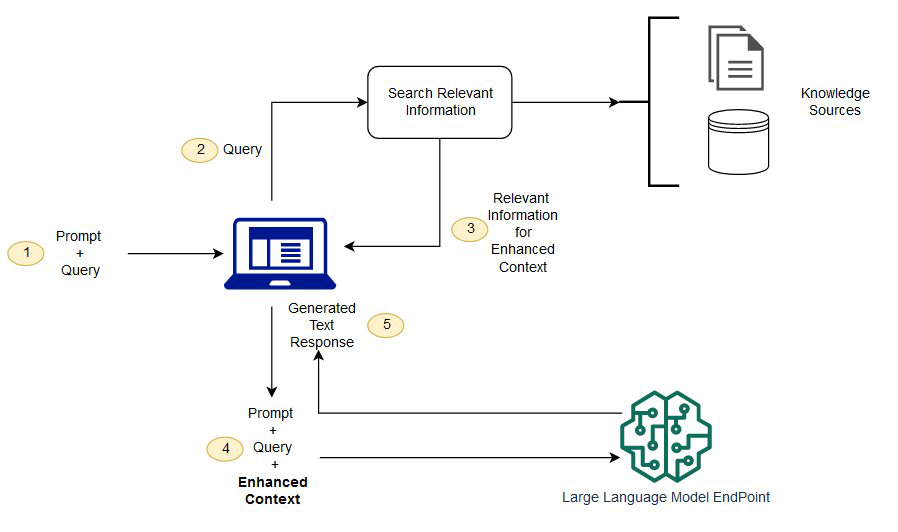
Figure 37:An example of synthesizing RAG with LLMs for question answering application
- 그림 속 RAG는 입력 프롬프트에서 쿼리를 추출하고, 해당 쿼리를 사용하여 외부 지식 소스(e.g., 검색 엔진, Knowledge Graph)에서 관련 정보 검색하는 것을 포함
- KG 예시
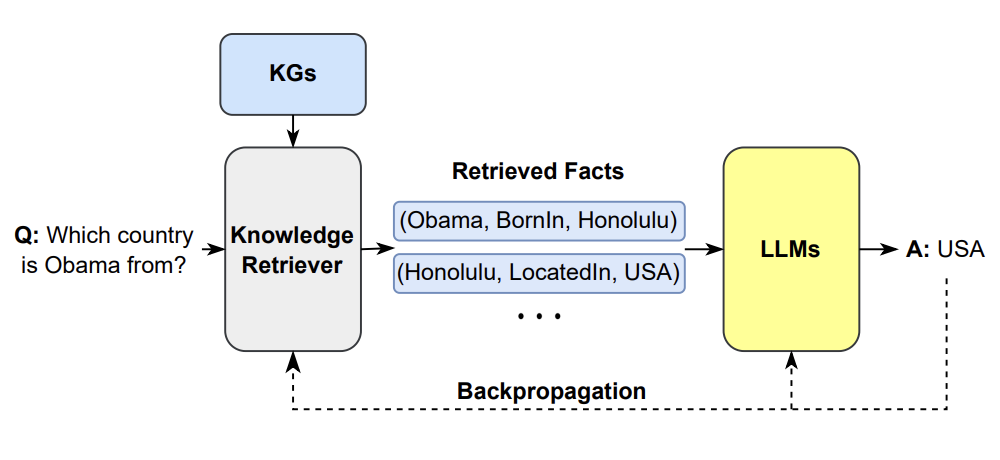
Figure 38: This is one example of synthesizing the KG as a retriever with LLMs
- KG 예시
- 그 다음 관련 정보가 원래 프롬프트에 추가되고, 모델이 최종 응답을 생성할 수 있도록 LLM에 공급함
- RAG-aware prompting techniques
- 하나의 예시: FLARE(Forward-looking Active Retrieval Augmented Generation)
- 예측과 정보 검색을 반복적으로 결합하여 대규모 언어 모델(LLM)의 기능을 향상시킴
- ↔ (기존 RAG) 일반적으로 정보를 한 번 검색한 다음 생성을 진행하는 기존의 검색 증강 모델과 대조적
- LLM 응답의 정확성과 관련성을 개선하기 위한 검색 증강 생성의 진화를 나타냄
- LLM이 향후 콘텐츠를 적극적으로 예측하고 이러한 예측을 쿼리로 사용하여 관련 정보를 검색하는 반복적인 프로세스를 포함
- 이 프로세스가 생성 단계 내내 동적으로 진행됨
- LLM에 의해 생성된 각 문장 또는 세그먼트의 신뢰도를 평가함
- 신뢰 수준이 특정 임계값 미만이면, 모델은 생성된 콘텐츠를 쿼리로 사용하여 관련 정보를 검색한 다음 문장을 다시 생성하거나 구체화하는 데 사용함
- 이러한 반복적인 프로세스를 통해 응답의 각 부분에 가장 관련성이 높고 최신의 정보가 제공되도록!
- 예측과 정보 검색을 반복적으로 결합하여 대규모 언어 모델(LLM)의 기능을 향상시킴
- 하나의 예시: FLARE(Forward-looking Active Retrieval Augmented Generation)
4-D. Using External Tools
4-E. LLM Agents
5. Popular Dataset for LLMs

6. Prominent LLMs’ Performance on benchmarks

- 다양한 시나리오에서 LLM의 성능을 평가하는 데 사용되는 몇 가지 인기 있는 메트릭에 대한 개요
- 몇 가지 인기 있는 데이터 세트와 벤치마크에서 대표적인 대규모 언어 모델의 성능
✅ 6-A. Popular Metrics for Evaluating LLMs
- 생성 언어 모델의 성능을 평가하는 것은 모델이 사용될 기본 작업에 따라 달라짐
- 감정 분석과 같이 주어진 선택지 중에서 하나를 선택하는 작업은 분류와 같이 간단하게 볼 수 있음
- 분류 메트릭을 사용하여 성능을 평가할 수 있음, 이 경우 Acc, Precision, Recall, F1 등과 같은 메트릭이 적용될 수 있음
- 또한 객관식 문제 답변과 같은 특정 작업에 대해 모델에서 생성된 답변은 항상 참 또는 거짓이라는 점에 유의해야 함
- 답변이 옵션 세트에 속하지 않는 경우에는 거짓으로도 볼 수 있음
- 감정 분석과 같이 주어진 선택지 중에서 하나를 선택하는 작업은 분류와 같이 간단하게 볼 수 있음
- 순수하게 개방형 텍스트 생성인 일부 작업은 분류와 같은 방식으로 평가할 수 없음
- 평가의 특정 목적에 따라 다른 메트릭이 필요함
- Code Generation은 개방형 생성 평가에서 매우 다른 경우
- 생성된 코드는 test suite를 통과해야 하지만, 다른 한편으로는 모델이 다양한 솔루션을 코드로 생성할 수 있는지, 그 중 올바른 솔루션을 선택할 확률이 얼마나 되는지 이해하는 것도 중요함
- 이 경우 Pass@k는 매우 좋은 지표임
- 이 경우 Pass@k는 매우 좋은 지표임
- 문제가 주어지면 다양한 코드 솔루션이 생성되는 방식으로 작동함
- 이러한 솔루션은 다양한 기능 테스트를 통해 정확성을 테스트함
- 그 후, 생성된 n개의 솔루션에서 각각의 솔루션이 방정식 4가 맞는지 확인하여 최종 값을 구함
- 생성된 코드는 test suite를 통과해야 하지만, 다른 한편으로는 모델이 다양한 솔루션을 코드로 생성할 수 있는지, 그 중 올바른 솔루션을 선택할 확률이 얼마나 되는지 이해하는 것도 중요함
- Exact Match는 주로 (사전 정의된) 답변과 정확히 일치하는 것과 관련된 또 다른 측정 항목
- 예측이 하나 이상의 원하는 참조 텍스트 중 하나에 토큰 단위로 정확히 일치하면, 올바른 것으로 간주
- 경우에 따라 정확도와 동일할 수 있고, 여기서 M은 총 정답 수이고 N은 총 문제 수
- 예측이 하나 이상의 원하는 참조 텍스트 중 하나에 토큰 단위로 정확히 일치하면, 올바른 것으로 간주
- Human Equivalence Score(HEQ)는 F1 점수의 대안
- HEQ-Q는 개별 질문의 정확도를 나타내며, 모델의 F1 점수가 인간의 평균 F1 점수를 초과하면 정답으로 간주
- 마찬가지로 HEQ-D는 각 대화의 정확도를 나타내며, 대화 내의 모든 질문이 HEQ의 기준을 충족할 때 정확한 것으로 간주
- 기계 번역(Machine Translation)과 같은 다른 생성 작업의 평가:
- Rouge 및 BLEU와 같은 메트릭을 기반
- 이러한 점수는 참조 텍스트(예: 번역)와 생성 모델에 의해 생성된 가설(이 경우 LLM)이 있을 때 잘 작동함
- 이 점수는 주로 계산 방식으로 답변과 기준 진실의 유사성을 감지하는 것이 목표인 경우에 사용됨
- 계산 방식에서는 N-Gram만 사용된다는 뜻! 그러나 BERT-Score와 같은 지표도 이러한 경우에 유용하지만, 다른 모델을 사용하여 판단하기 때문에 오류가 많이 발생함.
- 오늘날에도 순수하게 생성된 콘텐츠를 평가하는 것은 매우 어렵고 완벽하게 맞는 지표가 없으며, 지표는 N-Gram, SkipGram 등과 같은 단순한 특징을 찾거나 정확도와 정밀도를 알 수 없는 모델들임.
- Code Generation은 개방형 생성 평가에서 매우 다른 경우
- 평가의 특정 목적에 따라 다른 메트릭이 필요함
- 생성 평가 지표는 다른 LLM을 사용하여 답을 평가하는 LLM의 또 다른 유형의 평가 지표이기도 함
- 그러나 작업 자체에 따라 이러한 방식으로 평가가 가능할 수도 있고 불가능할 수도 있음
- 생성 평가에서 오류가 발생하기 쉬운 또 다른 종속성은 프롬프트 자체에 대한 의존성
- RAGAS는 생성 평가의 사용법을 통합한 좋은 예 중 하나
- LLM에서 가장 어려운 문제를 해결하기 위해 다양한 벤치마크와 리더보드가 제안됨:
- 어느 것이 더 나은가?
- 하지만 이 질문에 대한 간단한 답은 없음.
- 답은 대규모 언어 모델의 다양한 측면에 따라 달라짐
- 다양한 작업과 각 범주에서 가장 중요한 데이터 집합을 범주별로 제시
- Popular Dataset for LLMs ← 여기서 제시 중
- 동일한 분류를 따르며 각 카테고리를 기준으로 비교를 제공
- 각 카테고리에 대한 비교를 제공한 후에는 다양한 작업에 대해 보고된 성과 지표를 평균화하여, 집계된 성과에 대한 광범위한 개요를 제공함
- 다양한 작업과 각 범주에서 가장 중요한 데이터 집합을 범주별로 제시
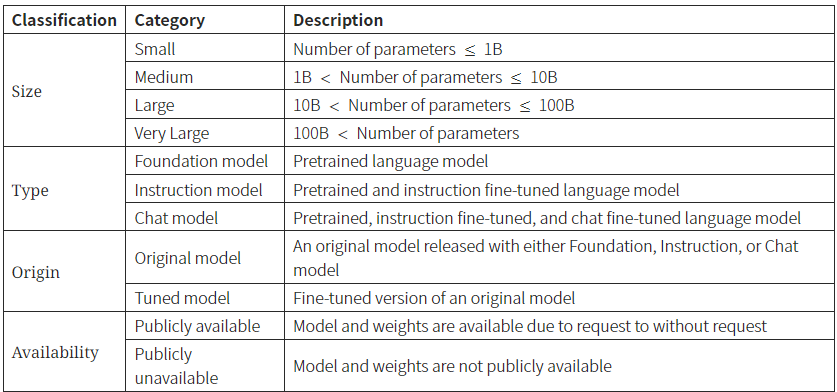
TABLE III:LLM categories and respective definitions.
- 서로 다른 LLM을 평가하는 것은 다른 관점에서도 볼 수 있음
- e.g., 매개변수 수가 현저히 적은 LLM은 매개변수 수가 많은 LLM과 완전히 비교할 수 없음
- 모델의 크기: 이러한 관점에서 LLM을 소형(10억 개 이하의 파라미터), 중형(10억~100억 개), 대형(100억~1000억 개), 초대형(1000억 개 이상)의 네 가지 카테고리로 분류할 것
- 사용하는 LLM의 또 다른 분류: 주요 사용 사례
- Foundation 모델(Pretrained O, Instructions & Chatting Fine-tuning X)
- Instruction 모델(Pretrained O, Instructions Fine-tuning O, & Chatting Fine-tuning X),
- Chatting 모델(Pretrained O, Instructions & Chatting Fine-tuning O)
- 별도로 원래 모델과 튜닝된 모델을 구분하기 위해 또 다른 분류가 필요:
- Original 모델은 Foundation 모델 또는 Fine-tuned 모델로 출시된 모델
- 또한 Original 모델은 일반적으로 특정 데이터 세트 또는 다른 접근 방식으로 Fine-tuned Foundation 모델이라는 점에 유의하는 것이 좋습니다.
- Tuned 모델은 Original 모델을 파악하고 다른 데이터 세트 또는 다른 학습 접근 방식으로 튜닝한 모델
- Original 모델은 Foundation 모델 또는 Fine-tuned 모델로 출시된 모델
- 분류: Availability of the model weights
- 요청을 통해서라도 가중치를 공개적으로 사용할 수 있는 모델은 Public 모델로 표시하고,
- 그렇지 않은 모델은 Private 모델로 표시
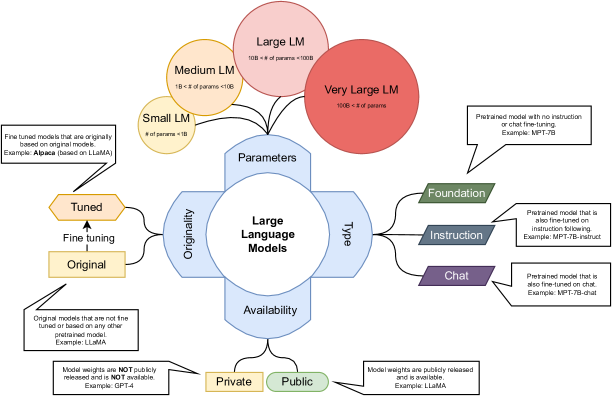
Figure 43:LLM categorizations.
6-B LLMs’ Performance on Different Tasks
- 상식적 추론은 각 모델이 얻을 수 있는 중요한 능력 중 하나
- 이 기능은 추론 능력과 함께 사전 지식을 사용하는 모델의 능력을 나타냄
- 예를 들어 HellaSwag의 경우, 주어진 텍스트는 이야기의 일부분을 포함하고 있는 반면 연속으로 주어진 선택지는 선택하기 까다롭고 세계에 대한 사전 지식이 없으면 텍스트의 연속을 찾는 것이 어려움
- 이러한 유형의 추론은 텍스트가 설명하는 장면이나 사실에 대한 사전 지식을 활용하는 것과 관련이 있기 때문에 높은 관심을 기울일 필요가 있음
7. Challenges and Future Directions

