input - x1,x2.. (features)
output - y (Target) : 범주형

파이썬 (scikit-learn)
⭐

70% (Training set 70%, Validation set 30%), Test set 30%
그러나 실제의 데이터는 충분하지 않음
- 초매개변수(Hyperparmeter)
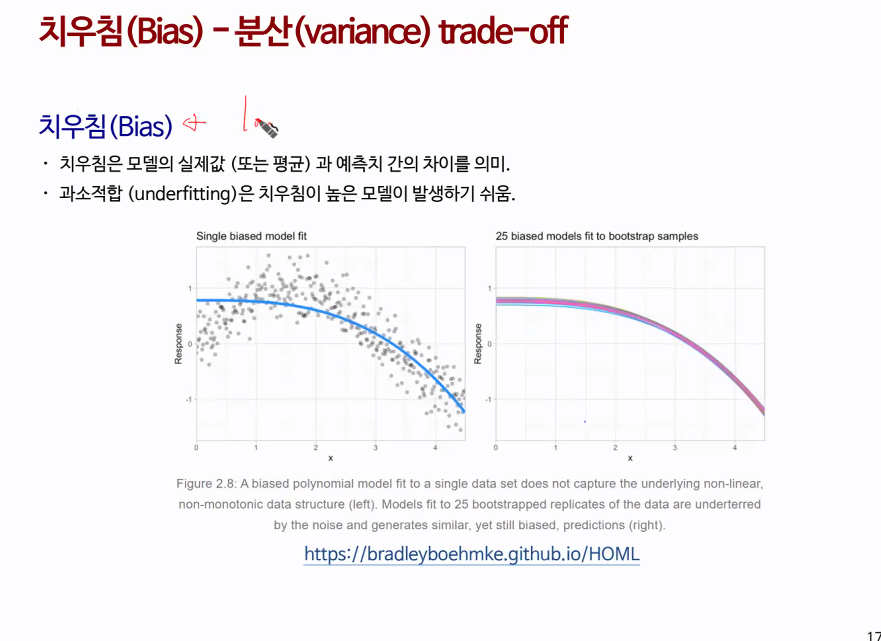
치우침과 분산
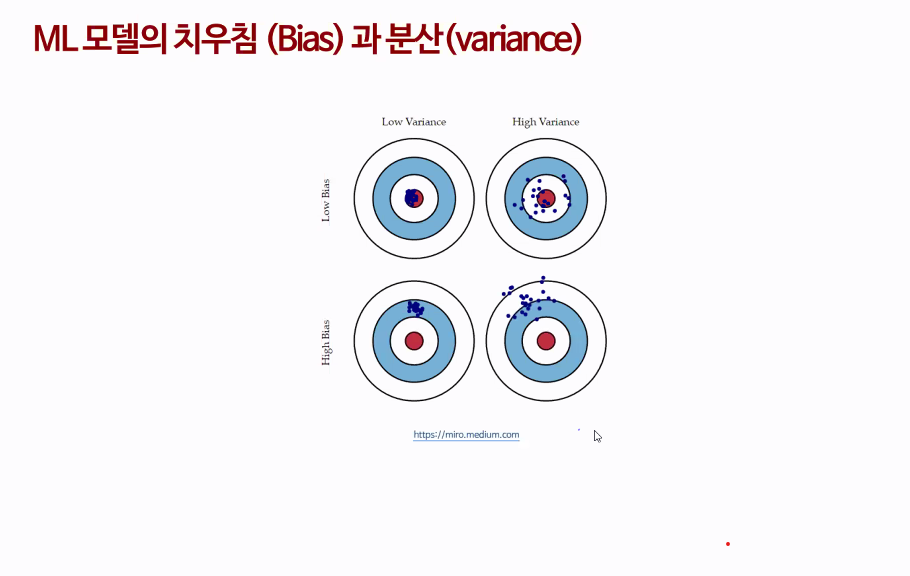
치우침(Bias) : 위 사진에서 중심점(참 값)에서 치우침을 말함
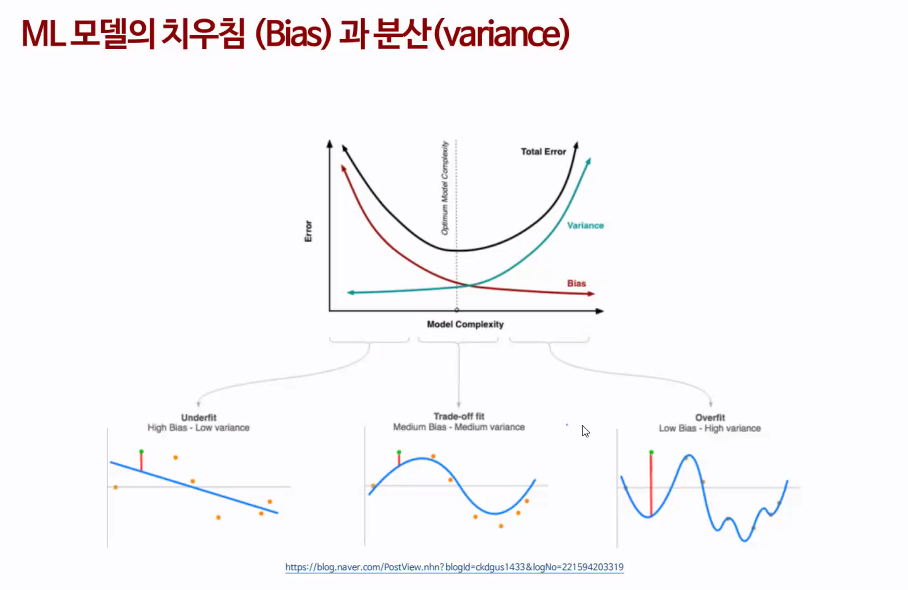
high bias - low variance
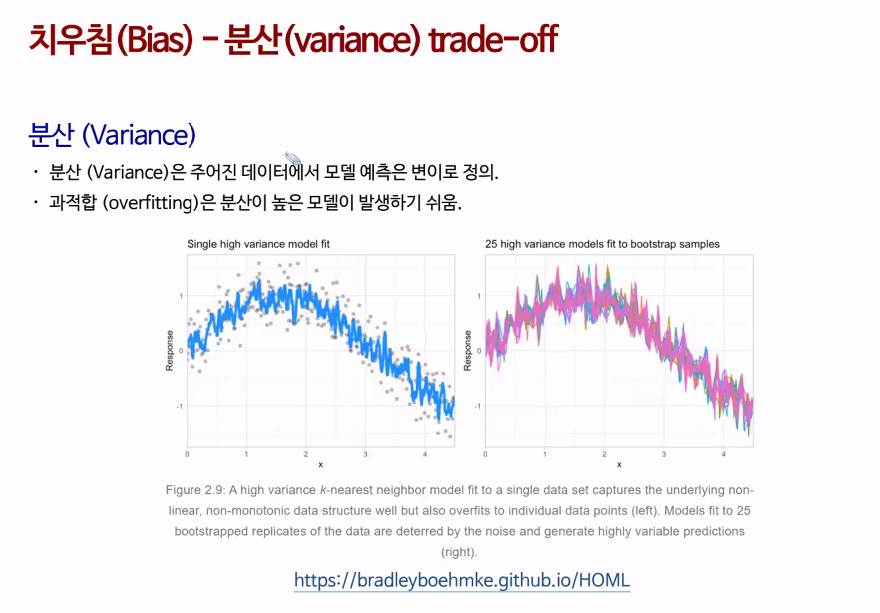
오른쪽 사진 : 과적합
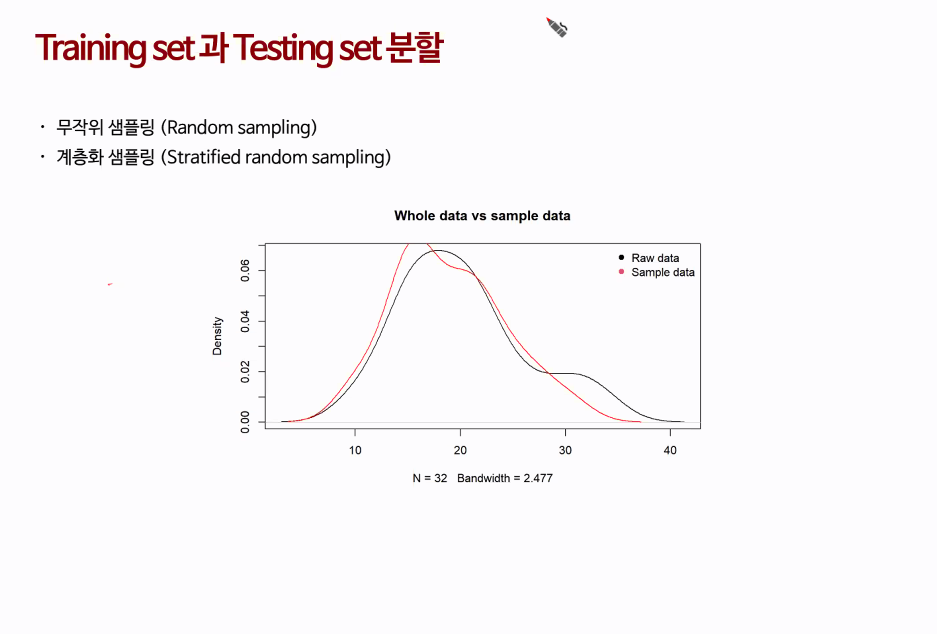
계층화샘플이 더 좋음
-
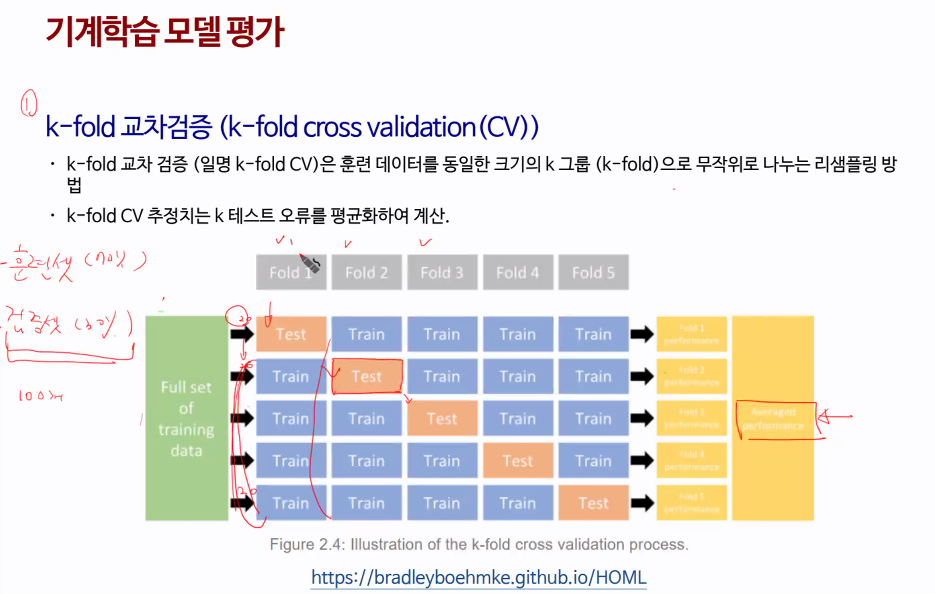
각각test를 각각의train(컬럼)에 진행함. -
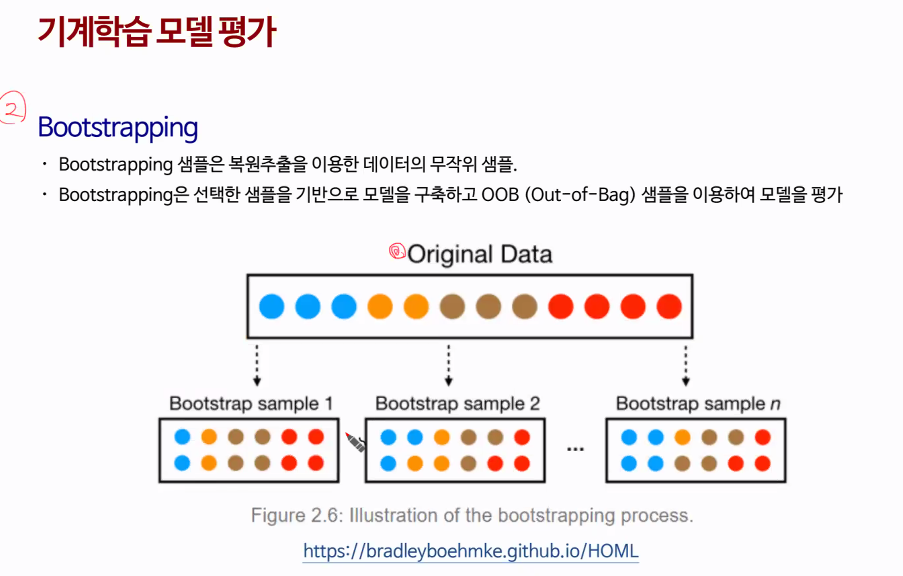
복원추출 : 샘플 추출 후 다시 데이터셋에 넣음

초매개변수 조절
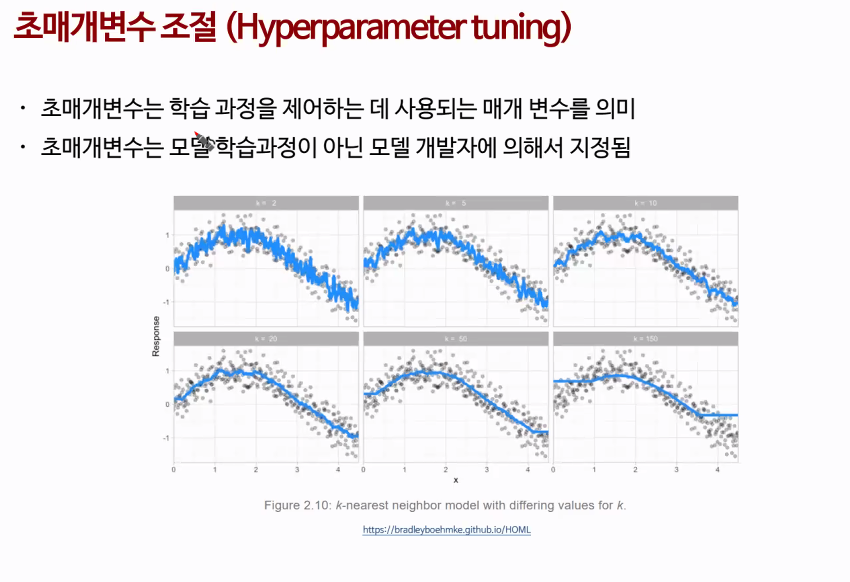
때문에 머신러닝은 모델 개발자의 영향을 많이 받음
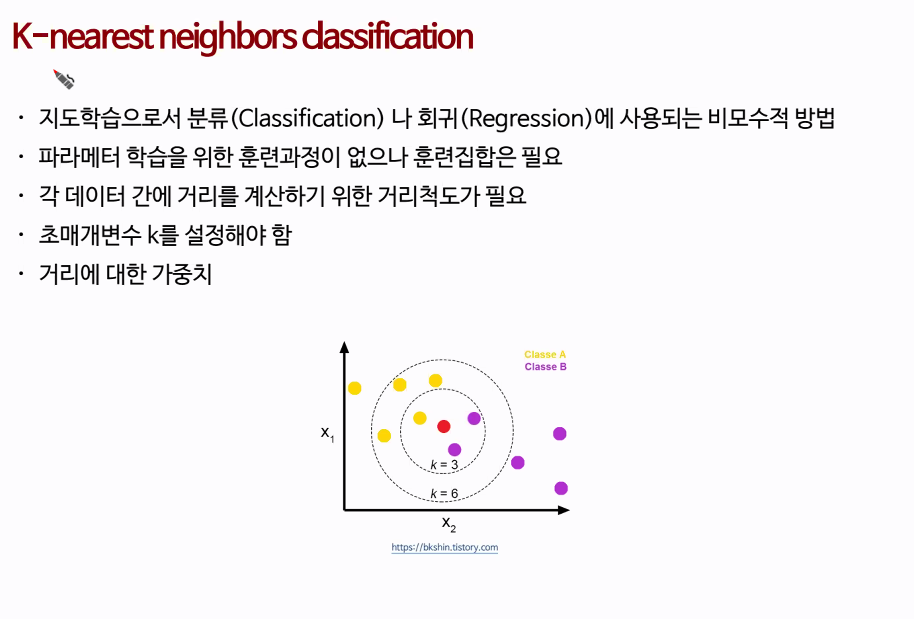
=> K - 최근접 이웃 분류(KNN classfication)
기하학적 거리 (Geometric distance measures)

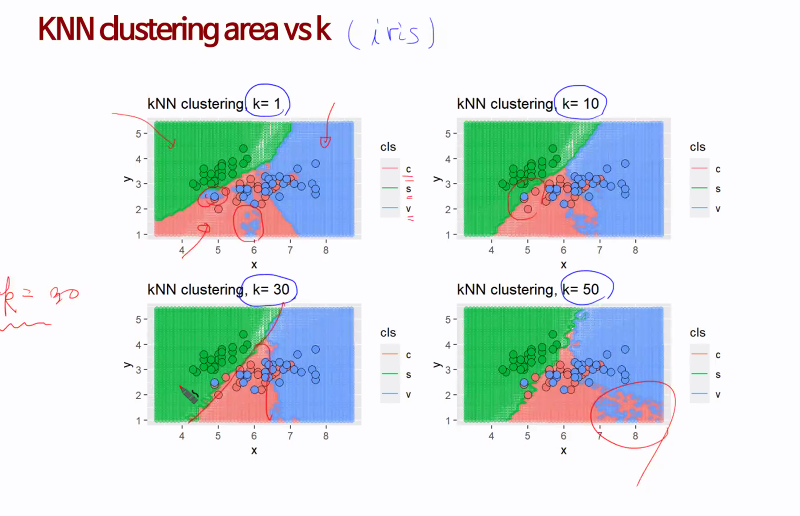
k의 적정값은 10과 30 사이에 존재함
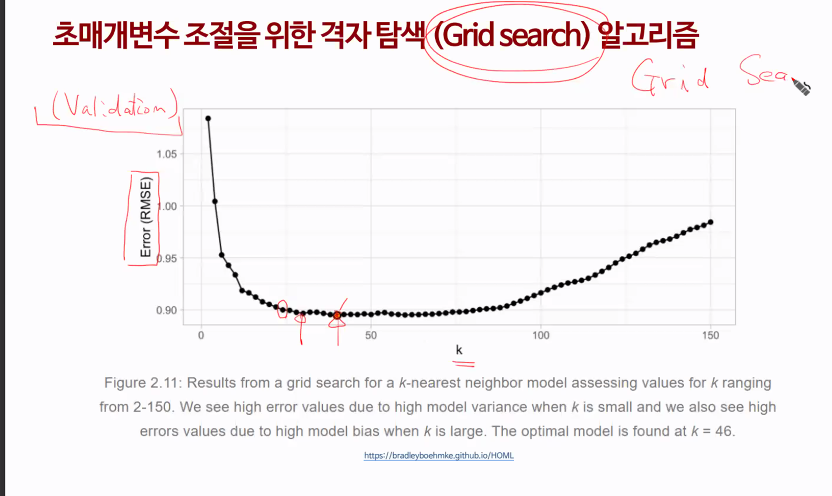
Grid Search

Feature 표준화 (Standardization)

변수의 단위에 대한 영향을 제거할 수 있음
(각각의 값 - 평균)/분산
그러나 해석상의 오류가 발생할 수 있음
Feature 표준화 결과
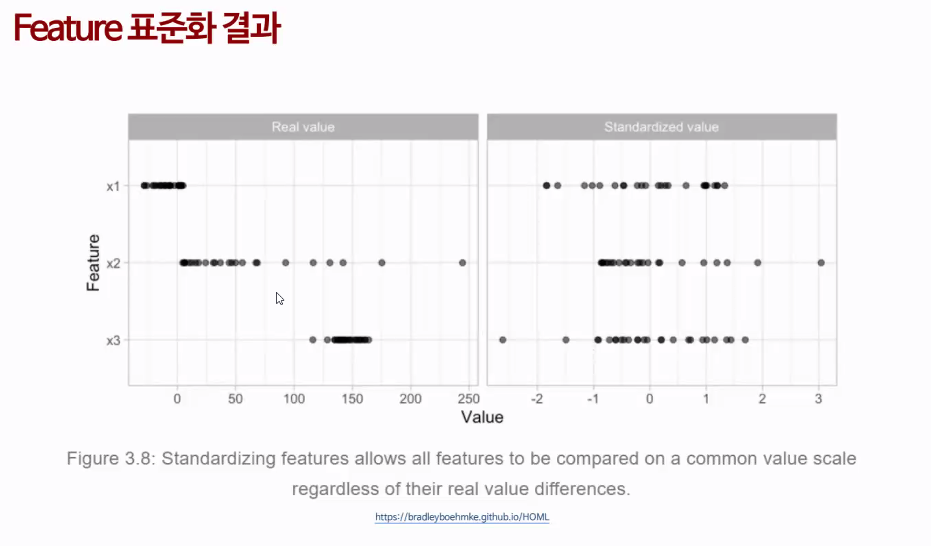
왼쪽 : 단위가 다름
오른쪽 : 표준화 후 대부분이 0으로 수렴
모델평가 지표

- MSE
- R Square

서현이의 코드 생활 ദ്ദി ( ᵔ ᗜ ᵔ )