- Large-scale Computing
- 대규모 컴퓨팅을 일반 하드웨어로 데이터 마이닝 문제에 어떻게 적용할까?
- 계산을 어떻게 분산시킬까
: 하나의 서버는 약 3년동안 정상 작동
: 1000개의 서버가 있다면, 하루에 1대가 고장남
- Solution Approach
- 문제 : 네트워크를 통해 데이터를 복사하는 데 시간이 소요됨 (노드의 지속성 및 가용성 문제)
- 아이디어
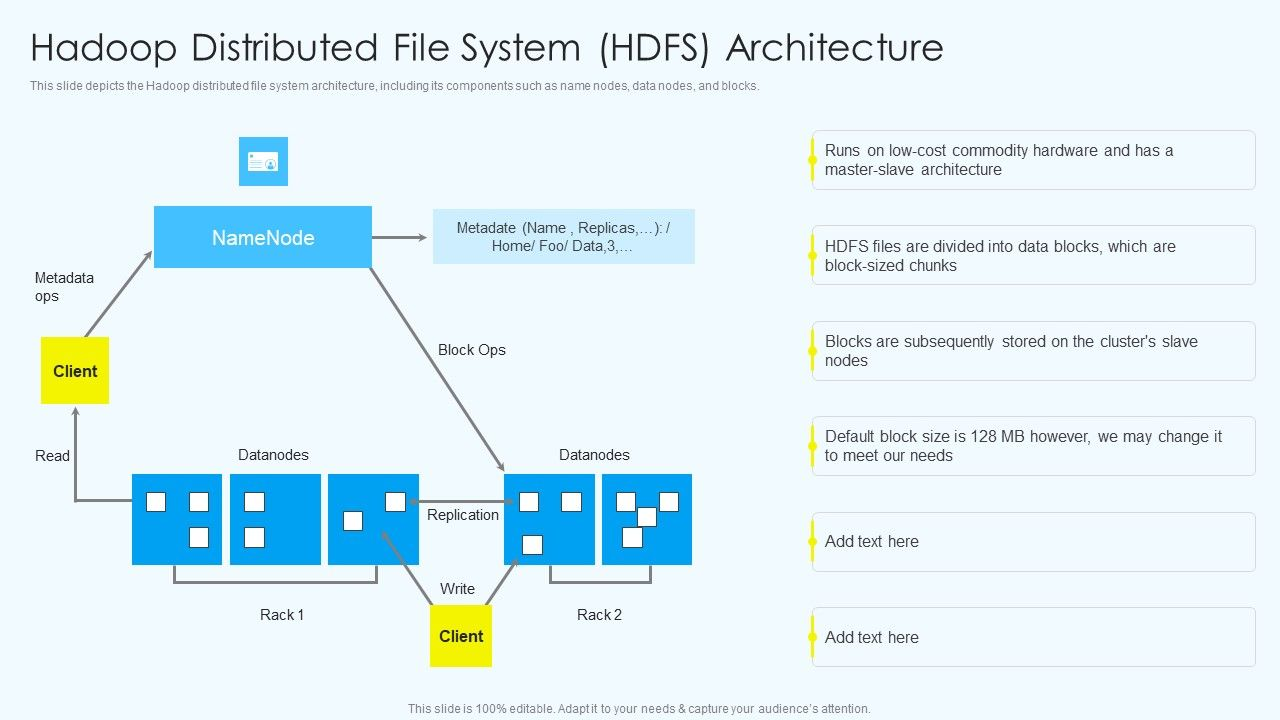
: 데이터를 이동시키는 대신 계산을 데이터가 있는 곳으로 이동하여 데이터 이동을 최소화
: 데이터를 여러번 저장하여 신뢰성을 확보
-> Spark / Hadoop (MapReduce)이 이러한 문제를 해결함
- 저장 인프라 - File System
*Google: GFS, Hadoop: HDFS - 프로그래밍 모델
*MapReduce, Spark
- Storage Infrastructure
-
일반적인 사용 패턴
: 거대한 파일들 (수백 GB에서 TB크기)
: 데이터를 제자리에 업데이트하는 경우는 드묾
: 읽기와 추가 작업이 일반적임 -
문제 : 노드가 실패할 경우, 데이터를 어떻게 지속적으로 저장할 것인가?
-
답
: Distributed File System
-> 전역 파일 네임스페이스 제공 (Google GFS, Hadoop HDFS)
- Distributed File System
- Chunk Servers (청크 서버)
: 파일은 연속된 청크로 분할됨
: 일반적으로 각 청크는 16-64MB
: 각 청크는 여러 대의 머신에 복제됨 (일반적으로 2~3번 복제)
: 복제본은 다른 rack에 저장하려고 함
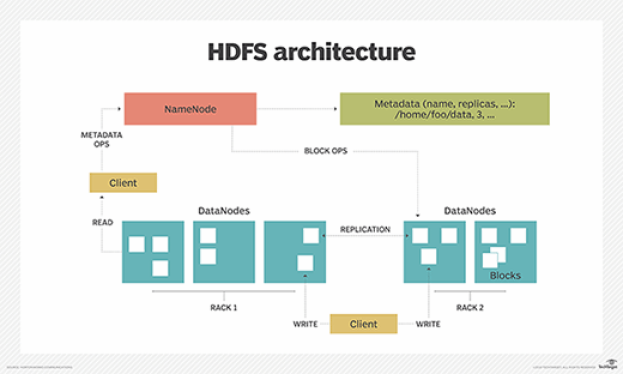
- Master Node (마스터 노드)
: Hadoop의 HDFS에서는 Name Node라고도 불림
: 파일이 저장된 위치에 대한 메타데이터를 저장
: 마스터 노드는 하드웨어 고장에 강하며, 중요한 클러스터 서비스를 관리함
- 파일 접근을 위한 Client Library
: 클라이언트는 먼저 마스터 노드와 통신하여 필요한 데이터를 포함하는 청크 서버를 찾음
: 이후 클라이언트는 청크 서버에 직접 연결해 데이터를 읽음
- 신뢰할 수 있는 분산 파일 시스템
: 데이터는 여러 머신에 걸쳐 분산된 청크로 저장됨
: 각 청크는 다른 머신에 복제됨
: 디스크나 머신 고장 시 원활한 복구 가능
- Programming Model: MapReduce
: Parallel Programming을 쉽게 할 수 있게함
: 하드웨어 및 소프트웨어 장애를 관리하는 것을 보이지 않게 처리
: 매우 대규모 데이터를 쉽게 관리
- 구현체: Hadoop, Spark, Flink, 구글의 원래 구현인 "MapReduce"
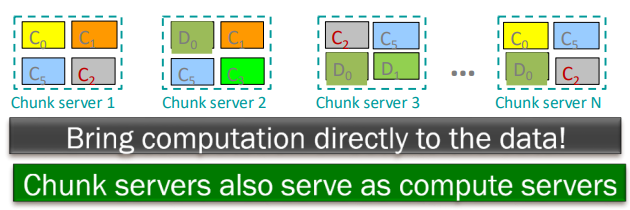
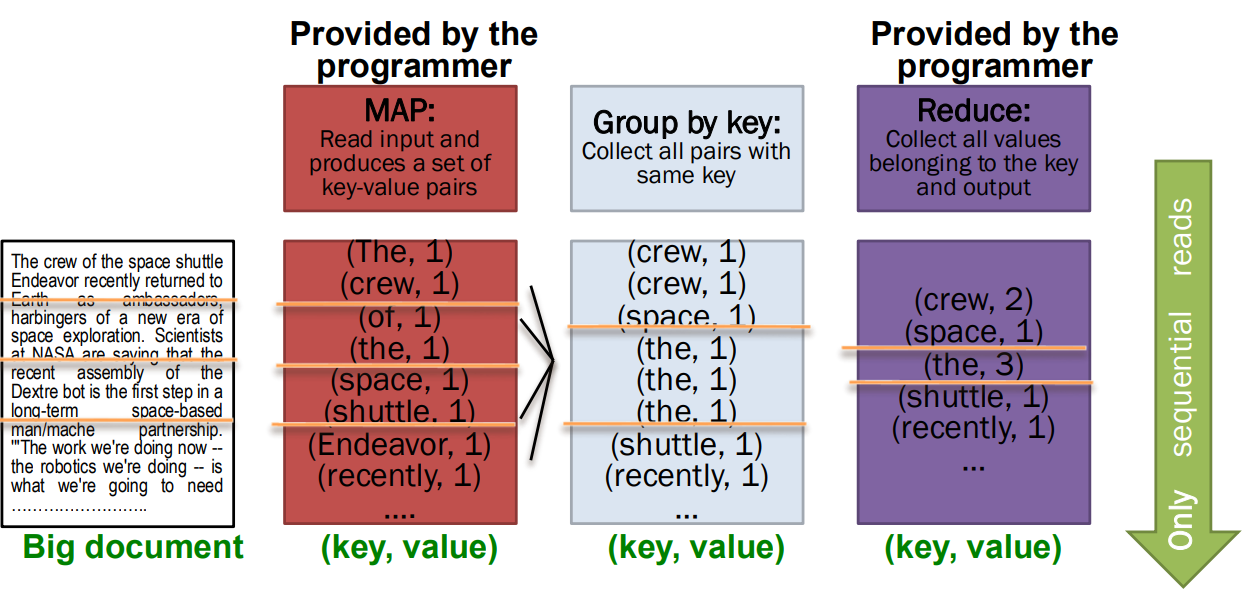
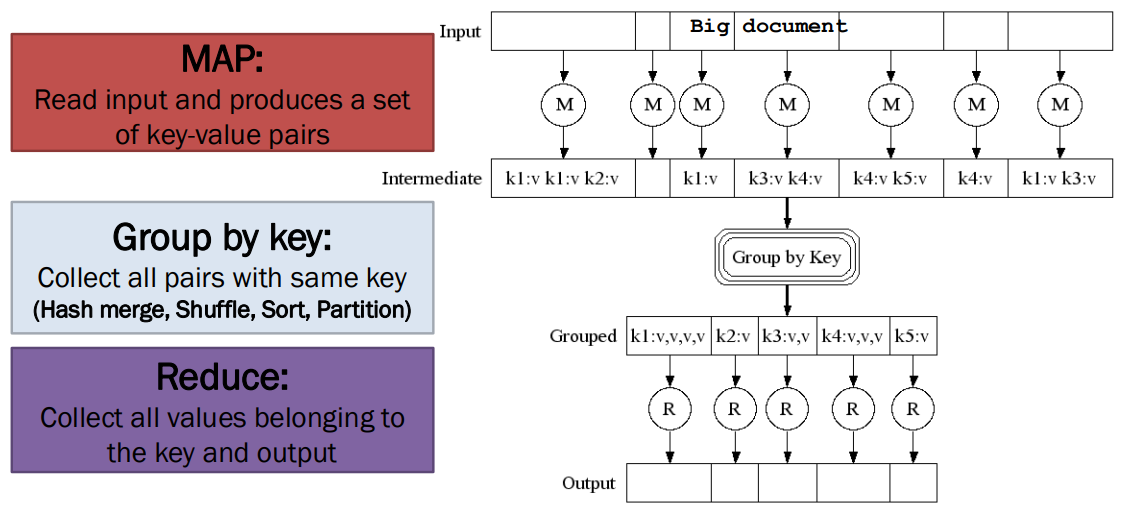
- MapReduce: Overview of 3 steps of MapReduce
* Map
: 각 입력 요소에 사용자 정의 Map 함수를 적용
: Mapper는 단일 요소에 Map 함수를 적용
: 여러 개의 Mapper가 모여 Map 작업을 구성함 (병렬 처리 단위)
: Map함수의 출력은 0, 1, or 그 이상의 key-value pairs
* Group by key : sort and shuffle
: 시스템이 모든 key-value pairs를 key로 정렬하고, key-(list of values) pairs로 출력
* Reduce
: 사용자 정의 Reduce 함수는 각 key-(list of values)에 적용
-> 개요는 동일하게 유지됨, Map과 Reduce 단계를 문제에 맞게 변경함
프로그래머가 지정하는 것
: Map함수, Reduce함수, 입력 파일
< Workflow >
- 입력을 key-value pairs 집합으로 읽음
- Map은 입력된 key-value pairs를 새로운 k'v'-pairs로 변환
- 변환된 k'v'-pairs를 정렬 및 셔플하여 출력 노드로 전달
- 동일한 키 k'를 가진 모든 값은 동일한 Reduce로 전송됨
- Reduce는 키로 그룹화된 모든 k'<v'>* pairs 를 처리하여 새로운 k'v''-pairs로 변환
- 그 결과 쌍을 파일에 작성
-> 모든 단계는 분산되어, 여러 작업이 병렬로 작업을 수행함
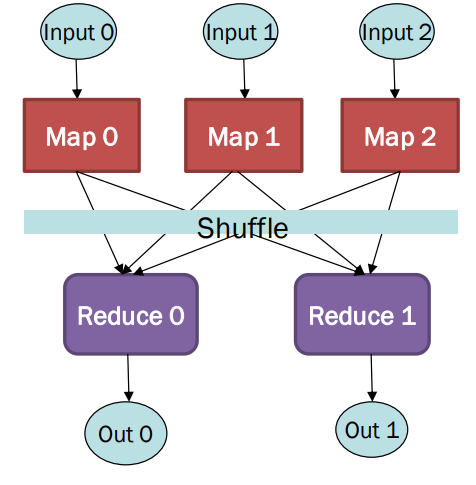
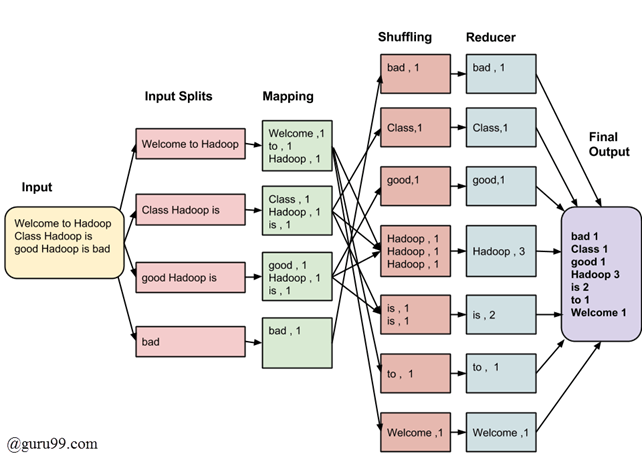
- EX) Word Counting
-
예시 MapReduce 작업
-> input: 거대한 텍스트 문서
-> output: 파일에서 각 고유한 단어가 등장한 횟수를 셈 -
응용 예시
: 웹 서버 로그를 분석하여 인기있는 URL찾기
: 통계적 기계 번역 - 대규모 문서 코퍼스에서 모든 5단어 시퀀스가 등장한 횟수를 셈 -
Input : key-value 쌍의 집합
-
프로그래머는 Map 함수와 Reduce 함수를 지정함
- Map(k, v) → <k’, v’>*
-> 키-값 쌍을 받아 키-값 쌍 집합을 출력
-> 예: 키는 파일 이름, 값은 파일의 한 줄
-> 각 (k, v) 쌍마다 한 번의 Map 호출이 이루어짐- Reduce(k’, <v’>) → <k’, v’’>
-> 동일한 키 k’를 가진 모든 값 v'을 함께 처리하고, v'의 순서대로 처리
-> 고유한 키 k’마다 한 번의 Reduce 함수 호출이 이루어짐

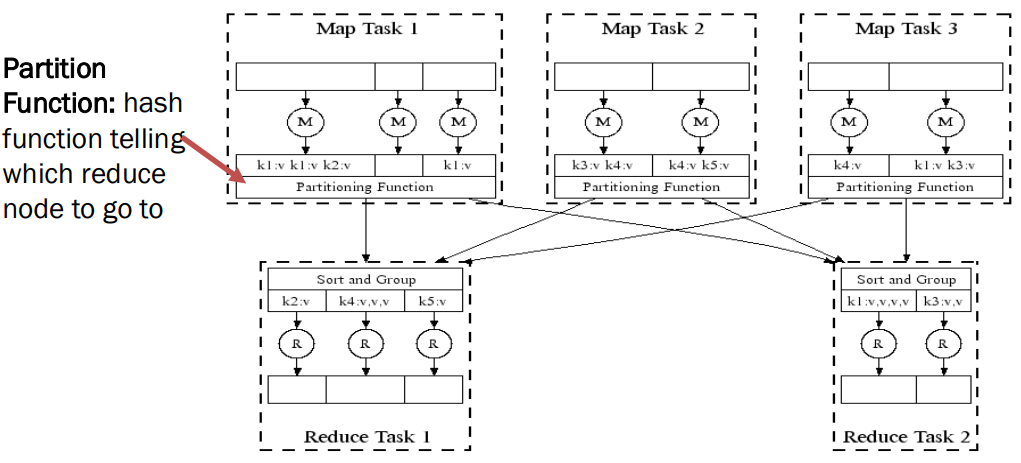
* Partition Function
: 해시 함수로, 어느 Reduce node로 데이터를 보낼지 결정함
-> Map-Reduce 단계는 여러 작업이 병렬로 작업을 수행하면서 분산됨
- Map-Reduce: Environment
<Map-Reduce 환경이 처리하는 것>
- 입력 데이터를 Partitioning
- 프로그램 실행을 여러 머신에 걸쳐 Scheduling
- Group by key 단계 수행 (실제로 이 단계가 bottleneck, 병목현상이 발생하는 부분)
- 기계 고장(failure) 처리
- 필요한 기계 간 통신 관리
*bottleneck: 시스템에서 가장 느린 부분 or 처리 속도를 제한하는 요소(전체 프로세스의 성능을 저하시킬 수 있는 부분)
- Dealing with Failures (장애 처리)
* Map worker failure
: 해당 작업자가 완료했거나 진행 중(in-progress)이던 Map 작업은 초기화되어 대기 상태(idle)로 설정되고 다른 작업자에게 재할당됨
: Reduce worker는 작업이 다른 작업자로 재할당(rescheduled)될 때 통보받음
* Reduce worker failure
: 진행중인 작업만 초기화되어 대기 상태로 설정되고, Reduce 작업이 재시작됨
: 완료된 작업은 이미 끝났고 결과는 파일 시스템에 기록되어 있으므로 영향을 받지 X
* Master failure
: 전체 MapReduce 작업을 관리하고 조정하는 중요한 노드
: MapReduce 작업(전체 작업)이 중단(aborted)되며 클라이언트에게 알림이 전송됨
