- Problem with MapReduce
: MapReduce는 데이터 복제, 디스크 I/O, 직렬화로 인해 상당한 오버헤드가 발생함
-> Mapper M의 출력은 디스크에 저장되고 정렬된 후, 다시 Reducer R가 이를 읽음 (HDFS read, HDFS write)
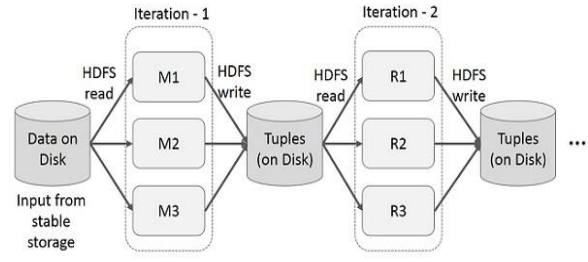
<MapReduce의 주요 제한사항>
- MapReduce로 직접 프로그래밍하기 어려움
-> 많은 문제들이 Map-Reduce로 쉽게 표현되지 X - 성능 병목 현상이나 배치 작업이 사용 사례에 맞지 않는 경우가 있음
-> 디스크에 데이터를 저장하는 것은 메모리 내 작업보다 일반적으로 느림
=> MapReduce는 대규모 어플리케이션에 적합하게 잘 구성되지 않음. 여러 번의 map-reduce 단계를 연결해야 하는 경우가 많음
- Data-Flow Systems
- 데이터는 첫번째 단계 -> 두번째 단계로 흐름
- tasks(작업)/ranks(단계)의 수를 제한 없이 허용
- Map과 Reduce 외의 함수도 허용
-> 데이터 흐름이 한 방향으로만 이루어진다면(DAG=Directed Acyclic Graph, 유향 비순환 그래프), 작업 단위로의 복구를 허용하여 전체 작업 대신 특정 작업을 복구할 수 O
- Data Analytics Software Stack
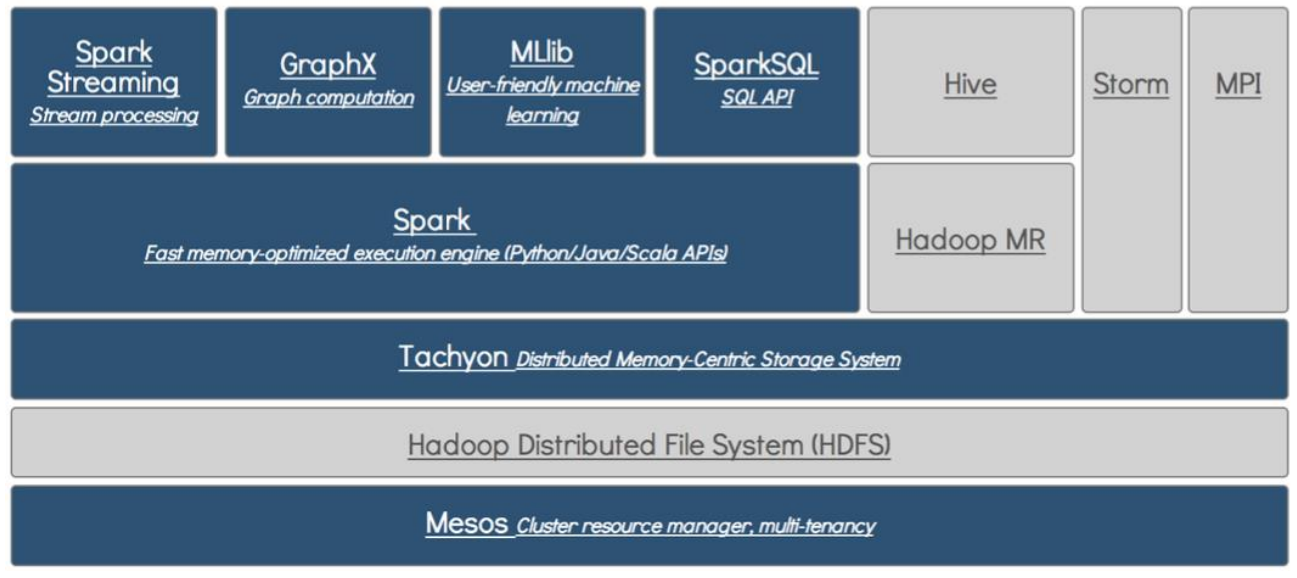
- Spark: 가장 인기있는 Data-Flow System
: 표현력이 풍부한 컴퓨팅 시스템으로, MapReduce 모델에 국한되지 않음
<MapReduce모델에 대한 추가 사항>
- 빠른 데이터 공유
-> 중간 결과를 디스크에 저장하는 것을 피함
-> 반복 쿼리 시 데이터를 캐시함 - General execution graphs (DAGs)사용
- 단순한 Map과 Reduce보다 더 풍부한 함수 지원
- Hadoop과 호환됨
- General DAG
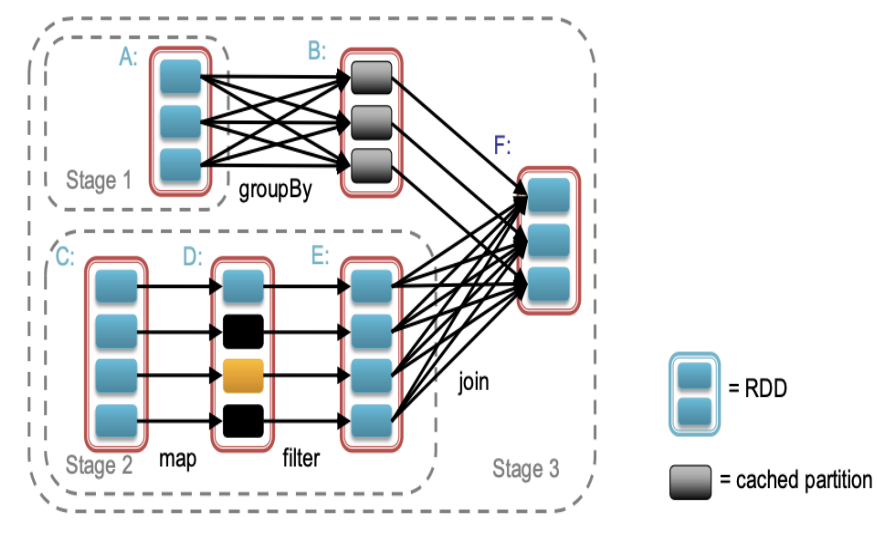
-> General task graphs를 지원
-> 한 방향으로만 갈 수 있음(돌아갈 수 없음)
-> 단순한 순차적 작업만이 아니라, 더 복잡한 작업 흐름(병렬 수행 등) 구성 가능
-> Spark 같은 시스템에서는 단순한 Map-Reduce 형태가 아닌, 필터링, 집계, 조인 등 다양한 작업들이 여러 단계로 연결된 작업 그래프로 표현되며, 이를 통해 복잡한 데이터 처리 흐름을 쉽게 구현할 수 있음
- What is Apache Spark?
: 오픈 소스 소프트웨어 (Apache Foundation에서 개발)
: Java, Scala, Python을 지원
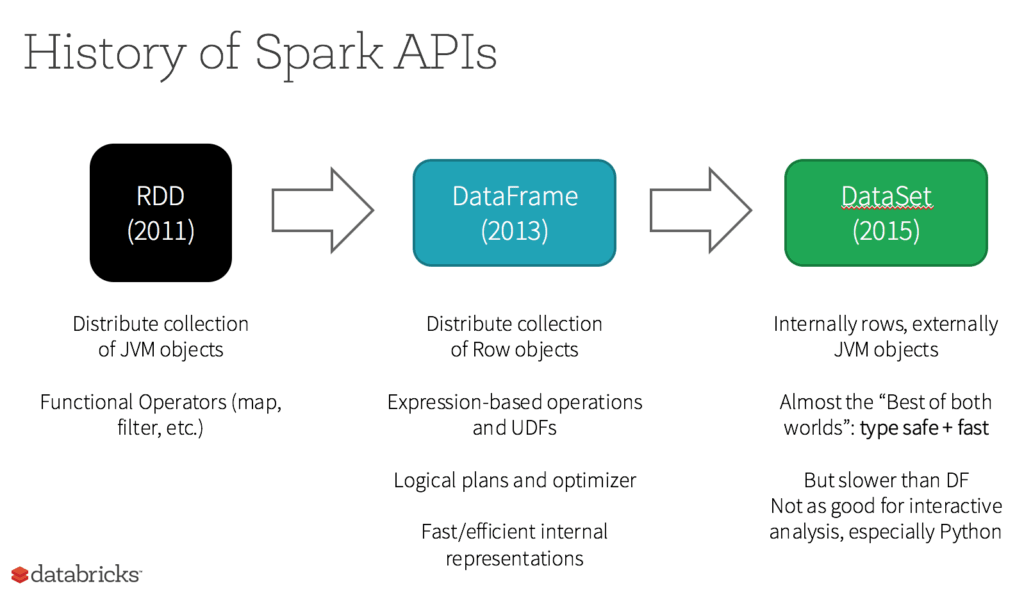
- 핵심 개념/아이디어: Resilient Distributed Dataset (RDD)
- 상위 수준의 API: DataFrames 및 DataSets
-> Spark의 최신 버전에서 도입
-> 집계 데이터를 위한 다양한 API를 제공, 이를 통해 SQL 지원도 도입됨
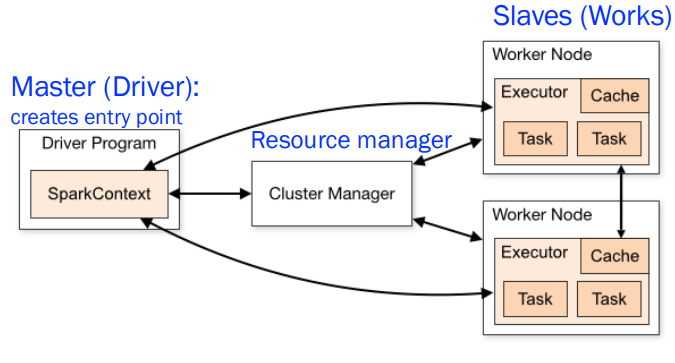
- Spark Architecture : master-slave architecture
- Resilient Distributed Datasets (RDD), 탄력적인 분산 데이터셋
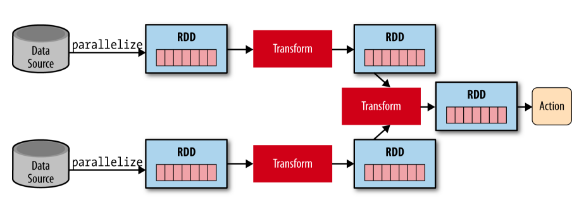
- RDD는 Spark의 기본 데이터 구조 (예전 기본 API)
-> 파티션된 읽기 전용 레코드 모음
-> key-value pairs를 일반화한 구조
- cluster전반에 분산되고, Read-only!!!
- 데이터를 메모리에 캐싱할 수 있음
-> 필요 시 디스크로 Fallback(대체) 가능 - RDD는 Hadoop에서 생성하거나 다른 RDD를 변환하여 생성 가능 (RDD를 중첩할 수 있음)
- RDD는 데이터셋의 모든 요소에 동일한 작업을 적용하는 어플리케이션에 가장 적합함
-> RDD는 변경할 수 없음. Read-Only
-> 변경 대신 이전 RDD를 기반으로 새로운 RDD를 만들 수 있음
-> 그 이전 RDD에 대한 정보와 연산을 기록함(lineage)
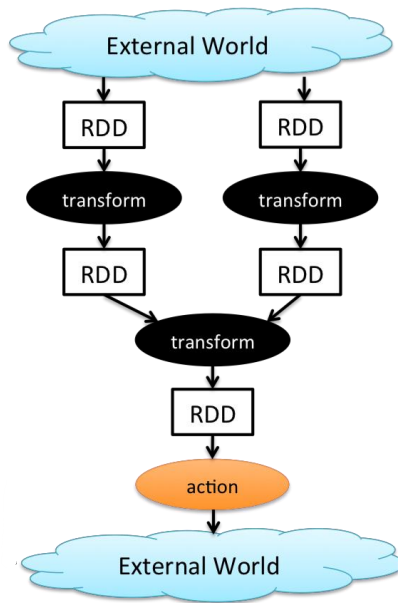
< Spark RDD Operations > **** 둘의 차이
1) 변환(Transformations)
: 다른 RDD에 대한 결정론적 연산(동일입력에 대해 항상 동일결과 생성)을 통해 새로운 RDD를 생성하는 연산
-> Transformations의 예시: map, filter, join, union, intersection, distinct
-> Lazy evaluation: 변환은 즉시 실행되지 않고, 나중에 액션이 호출될 때까지 계산을 미룸. 성능을 최적화하고 불필요한 계산을 방지하기 위한 기법2) 액션(Action)
: 변환된 RDD의 데이터를 실제로 계산하고, 그 결과를 반환하거나 외부 시스템으로 내보냄(return, export data)
-> 즉시 평가, force calculation: 액션이 호출되면 Spark는 모든 지연된 반환들을 실행하여 최종 결과를 계산함
-> 액션의 예시: count, collect, reduce, save
-> 액션은 RDD에 적용될 수 있으며, 액션은 계산을 강제하고 값을 반환함
- Task Scheduler: General DAG
- general task graphs를 지원
- 가능한 경우 pipeline functions 사용
- Cache-aware data reuse & Locality(데이터 지역성) 지원
- Partitioning-aware(파티셔닝 인식)을 통해 셔플 작업을 방지
- Higher-Level API: DataFrame and Dataset
*DataFrame
: RDD와 달리, 데이터가 이름이 지정된 열로 구성됨, 예를 들어 관계형 데이터베이스의 테이블과 유사
: 분산된 데이터 컬렉션에 구조를 부여하여 상위 수준 추상화를 제공
*Dataset
: DataFrame API의 확장판으로, 타입 안전(type-safe)하고 객체 지향적인 프로그래밍 인터페이스(object-oriented programming interface)를 제공(컴파일 시 오류 감지)
-> 두 API 모두 Spark SQL 엔진 위에서 구축되었으며, 둘 다 RDD로 변환 가능
- Useful Libraries for Spark
- Spark SQL: 구조화된 데이터 및 반구조화된 데이터를 처리하기 위한 프로그래밍 인터페이스 제공
- Spark Streaming: 실시간 데이터 스트림의 스트림 처리
- MLlib: 확장 가능한 머신러닝 라이브러리(scalable machine learning)
- GraphX: 그래프 조작을 위한 라이브러리(graph manipulation)
-> Spark RDD를 확장하여 그래프 추상화를 제공: 각 vertex와 edge에 속성을 부여한 directed multigraph
- Spark vs. Hadoop MapReduce
-
성능 : Spark가 일반적으로 더 빠르지만 몇가지 제한 있음
-> Spark는 데이터를 메모리에서 처리할 수 O, but Hadoop MapReduce는 Map이나 Reduce 작업 후 데이터를 디스크에 저장함
-> Spark는 일반적으로 MapReduce보다 성능이 우수, but 좋은 성능을 위해서 많은 메모리 필요. 다른 리소스 요구 서비스가 있거나 메모리에 데이터를 모두 저장할 수 없는 경우 Spark의 성능이 저하됨
-> MapReduce는 다른 서비스들과 쉽게 함께 실행할 수 O, 설계된 1회성 작업에서는 성능 차이가 적음 -
사용 용이성: Spark는 더 높은 수준의 API를 제공하여 프로그래밍이 더 쉬움
-
데이터 처리: Spark는 더 일반적인 데이터 처리를 지원

- Problems Suited for MapReduce
- Example: Host size
- 대규모 웹 코퍼스(웹에서 수집된 대규모 데이터)에서 주어진 메타데이터(URL, 크기, 날짜 ...형식의 줄로 구성)를 기반으로 각 호스트에서 총 전송된 데이터의 양을 계산하는 작업
-> 특정 호스트에서 온 모든 URL의 페이지 크기를 합산하는 문제
<다른 예시>
- 링크 분석 및 그래프 처리
- 머신러닝 알고리즘
- Example: Language Model
- 통계적 기계 번역(Statistical machine translation):
대규모 문서 코퍼스에서 모든 5-단어 시퀀스가 등장하는 횟수 카운트하기
-> MapReduce로 매우 쉽게 처리 가능
- Map: 문서에서 (5-단어 시퀀스, 등장 횟수) 추출
- Reduce: 등장 횟수를 합산
- Example: Join By Map-Reduce
- natural join R(A,B) ⋈ S(B,C) 를 계산
- R과 S는 각각 파일에 저장되어 있음
- 튜플은 (a,b) 또는 (b,c) 쌍으로 구성됨
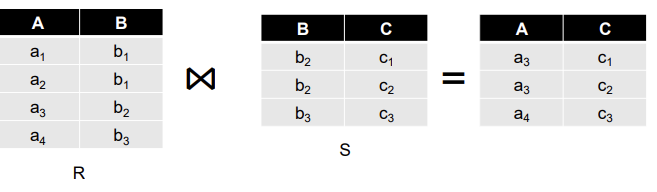
-> 두 개의 관계형 테이블 R(A, B)와 S(B, C)가 각각 지정된 파일에 있음
-> 이 두 테이블에서 공통된 열 B를 기준으로 natural join을 해야함
-> 결과는 새로운 튜플 (A, B, C)를 생성하는 것
- Map-Reduce Join
- B-values에서 1...k로 매핑하는 해시 함수 h 사용
-> 해시 함수의 역할은 각 키를 기반으로 데이터를 적절한 Reduce 작업으로 보내는 것
-
Map 프로세스:
-> 입력 튜플 R(a,b)를 key-value pairs (b, (a, R))으로 변환
-> 입력 튜플 S(b,c)를 (b, (c, S))로 변환 -
Map 프로세스는 key b와 함께 각 key-value pairs를 Reduce 프로세스 h(b)로 전송
-> Hadoop은 이를 자동으로 처리하므로, k값만 지정하면 됨.
- 각 Reduce 프로세스는 모든 (b, (a, R)) 쌍과 (b, (c, S))쌍을 매칭하고 (a, b, c)를 출력
- Problems NOT Suitable for MapReduce
- MapReduce가 적합한 경우:
-> 순차적인 데이터 접근이 필요한 문제
-> 대규모 배치 작업(인터랙티브 or 실시간 아님)
- MapReduce가 비효율적인 경우: 데이터에 대한 랜덤(불규칙한) 접근이 필요한 문제
-> 그래프, 상호 의존적인 데이터( 머신러닝, 여러 항목 쌍을 비교하는 작업)
