- Recurrent Neural Networks, 순환 신경망
- 언어의 sequential nature(순차적 특성)를 직접 처리하는 매커니즘을 갖고 있어, 임의의 고정된 크기의 윈도우를 사용하지 않고도 언어의 temporal nature(시간적 특성)를 다룰 수 있음
- 이전 문맥을 recurrent connections(순환 연결)을 통해 새로운 방식으로 표현할 수 있게 하여, 모델의 결정이 수백 개의 이전 단어에 대한 정보에 의존할 수 있도록 함

-
MLP
-> One-to-One -
RNN
-> One-to-Many
-> Many-to-One
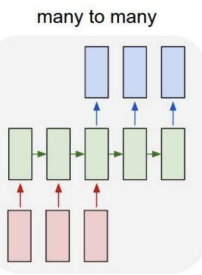
-> Many-to-Many
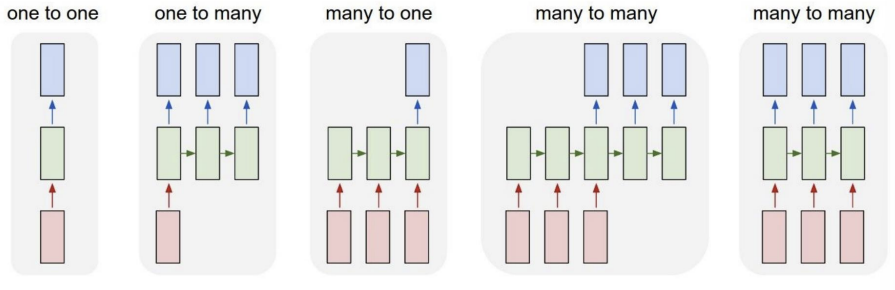
- One-to-Many Task
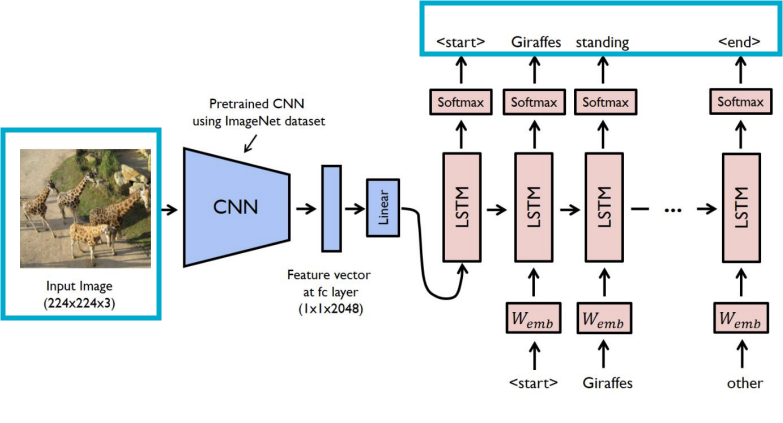
- Image Captioning
: 고정된 크기의 이미지를 입력받아, 그 이미지의 내용을 설명하는 단어 시퀀스(캡션)를 RNN을 통해 생성하는 작업
-> Input: 이미지
-> Output: 캡션
- Many-to-One Task
-
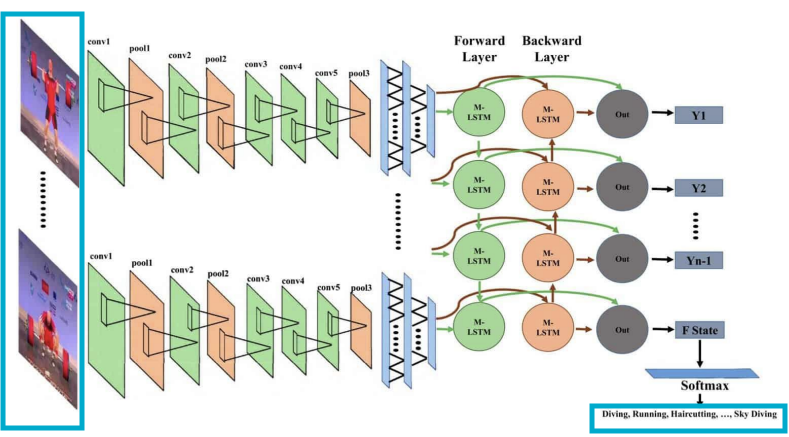
Action prediction(행동 예측)
: 단일 이미지 대신 일련의 비디오 프레임을 보고, 그 비디오에서 어떤 행동이 일어났는지를 나타내는 라벨을 생성하는 작업 -
Sentiment classification(감정 분류)
: 문장의 일련의 단어를 입력받아 그 문장의 감정을 분류
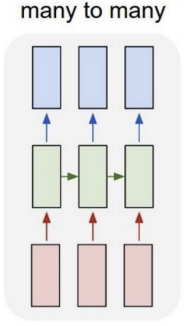
- Many-to-Many Task
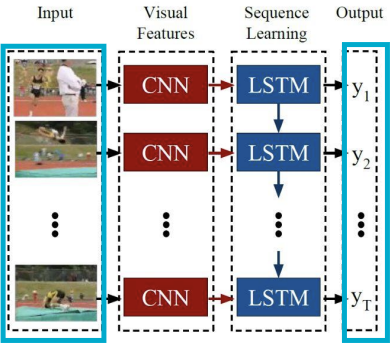
- Video-captioning
: 입력-일련의 비디오 프레임, 출력-그 비디오에 무엇이 있었는지를 설명하는 캡션을 생성하는 작업 - Machine translation(기계 번역)
: 영어 문장의 단어 시퀀스를 입력받아, 프랑스어 문장의 단어 시퀀스를 생성하도록 요청받음
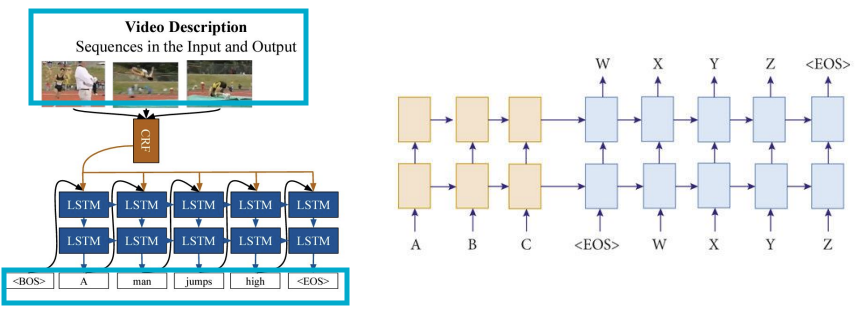
- Many-to-Many Task2
: 매 시간마다 실시간으로 출력을 생성함
- 프레임 단위에서 비디오 분류
: 비디오의 각 프레임을 여러 클래스 중 하나로 분류
- RNN: Hidden State and Output
- RNN
: 매 시간 단계마다 recurrence formula(순환 공식)을 적용하여 벡터 시퀀스 X를 처리할 수 있음
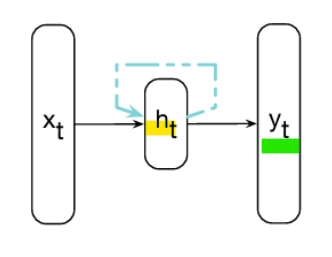
- Hidden State

- Output

-> 동일한 function과 동일한 parameter가 모든 step에 사용됨!
- Hidden State of Vanilla RNN(가장 기본 RNN)
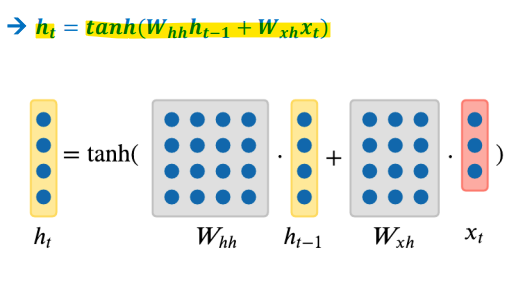
- output
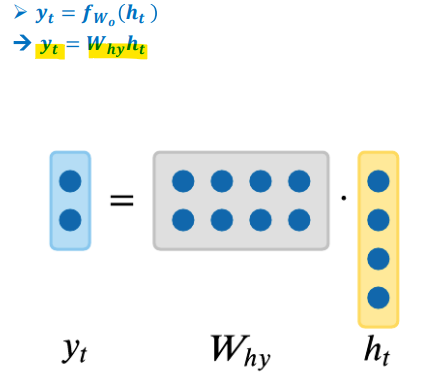
- RNN example as Character-level language model
- Character-level language model
- 작동 방식: 문자들의 시퀀스를 RNN에 입력하면, 매 시점마다 RNN이 다음 문자(sequence에서 다음에 올 문자를) 예측하게 하는 것
- RNN의 예측은 RNN이 지금까지 본 시퀀스에서 다음에 와야 한다고 생각하는 문자의 분포를 점수 형태로 나타낸 것 (이 분포는 어휘 내의 모든 문자의 점수로 표현됨)
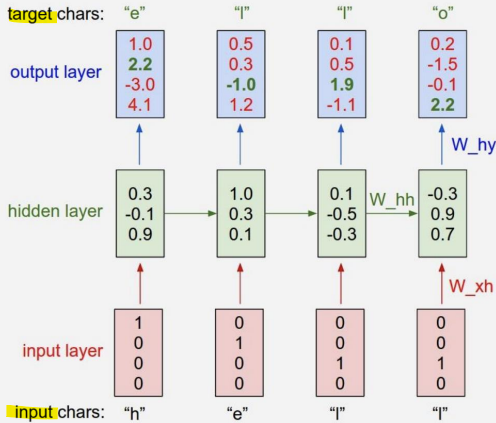
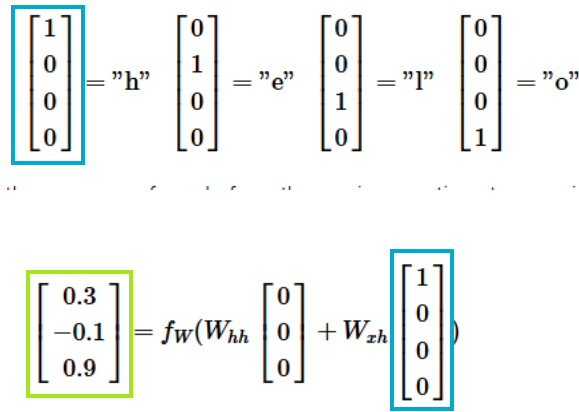
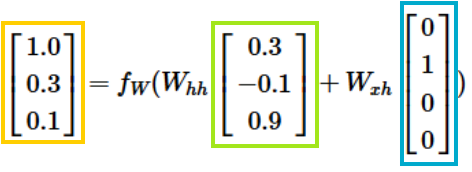
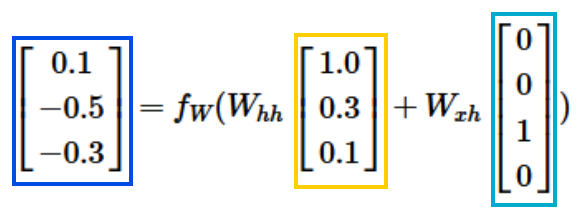
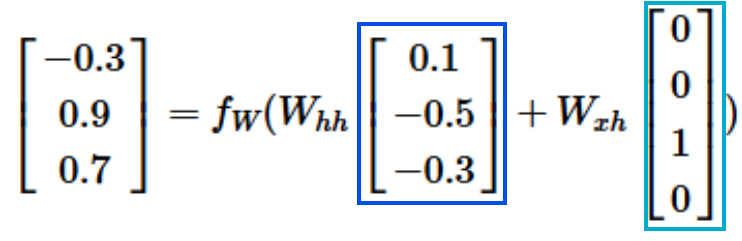
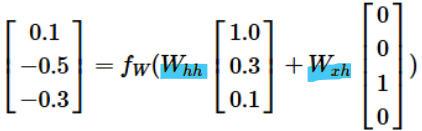
-> 2개의 weight 값은 계속 동일한 값을 사용함!
- Backpropagation
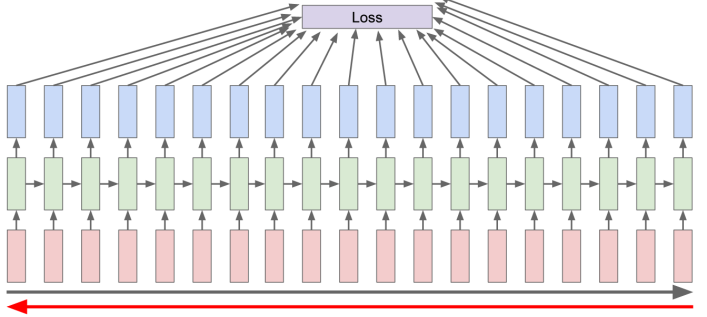
- Forward: Loss를 계산
- Backward: Gradient를 계산
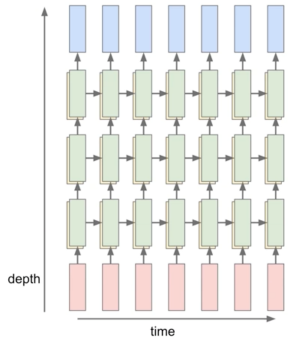
- Multi-layer RNNs
- RNN은 여러 층으로 쌓을 수 있음(더 깊은 모델)
-> 깊을수록 성능이 더 좋음
- RNN Trade-off
<장점>
- 어떤 길이의 입력도 처리할 수 있음
- 이론적으로는 시점 t의 계산이 여러 이전 시점의 정보를 사용할 수 있음
- 입력이 길어져도 모델 크기는 증가하지 않음
- 매 시점에 동일한 가중치가 적용되므로 입력을 처리하는 방식에서 대칭성이 있음
<단점>- Recurrent computation(순환 계산)이 느림
- 실제로는 여러 이전 시점의 정보를 접근하는 것이 어려움
-> 이러한 문제를 해결해주는 모델: LSTM
- Vanilla RNN Gradient Flow

- RNN 구조
: RNN은 순차적인 데이터를 처리하는데, 각 시점 t에서 은닉 상태 ht는 이전 시점의 은닉 상태 ht-1와 현재 입력 xt를 이용해 계산됨
이때 가중치 행렬 W는 모든 시점에서 동일하게 사용됨
<Vanishing gradients 문제>
- 아래쪽의 수식은 손실(Loss)의 기울기(Gradient)가 시간이 지나면서 어떻게 변화하는지를 보여줌 -> 다수의 시점을 거치면서 기울기가 거의 항상 1보다 작아지는 현상이 발생함
- 이러한 현상은 역전파(backpropagation) 과정에서 기울기가 점점 작아지면서, 기울기 소실(Vanishing Gradient) 문제가 발생함
- 그 결과, 네트워크가 과거 시점의 정보를 제대로 학습하지 못하게 됨
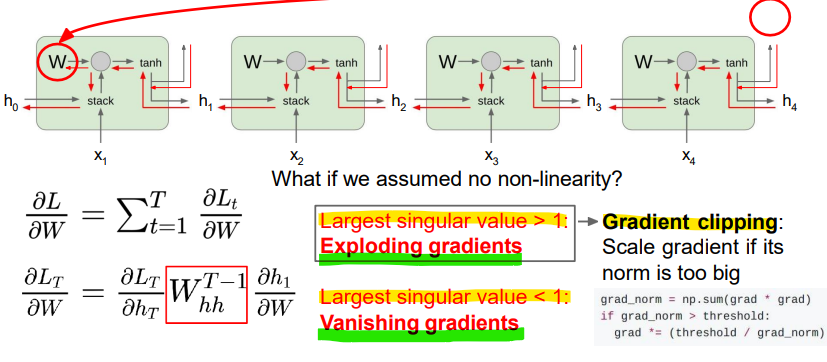
- 기울기 폭발(Exploding Gradients) 문제
: 만약 가중치 행렬 W의 가장 큰 특이값(Singular Value)이 1보다 크다면, 기울기가 지속적으로 커져서 폭발하게 됨
: 기울기 폭발은 학습 과정을 불안정하게 만들고, 가중치가 비정상적으로 큰 값을 갖게 될 수 있음-> 해결법: Gradient Clipping: 일정한 임계값(threshold)으로 제한함(스케일링)
- 기울기 소실(Vanishing Gradients) 문제
: 가중치 행렬 W의 가장 큰 특이값이 1보다 작으면, 기울기가 점점 작아져서 사라지는 기울기 소실 문제가 발생함
: 이는 모델이 긴 시퀀스에 걸쳐 정보를 학습하는 데 어려움을 줌-> 해결법: RNN 구조를 변경
- Long Short Term Memory(LSTM)
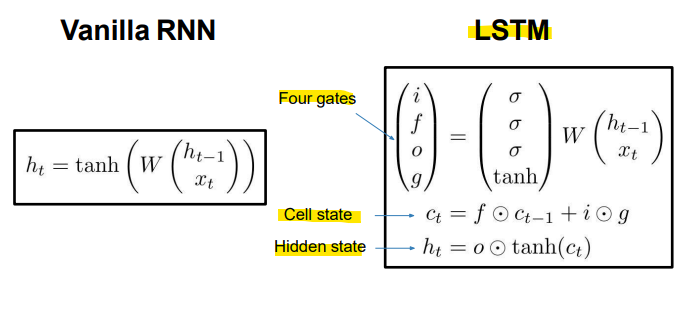
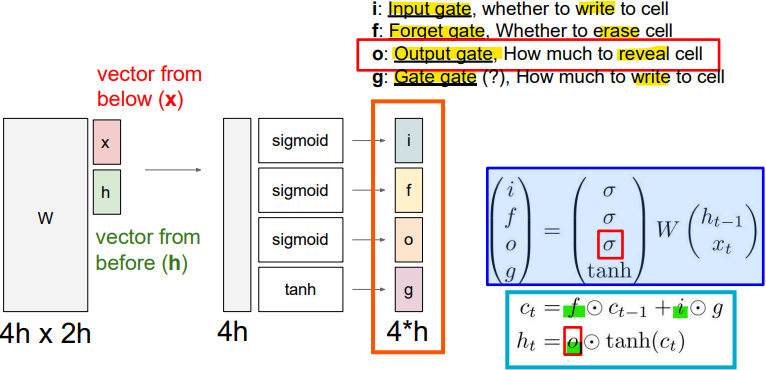
- 입력 게이트(Input Gate, i)
: 셀에 새로운 정보를 얼마나 추가할지를 결정하는 게이트- 망각 게이트(Forget Gate, f)
: 이전 셀 상태에서 어떤 정보를 지울지 결정. 이를 통해 불필요한 정보가 제거됨- 출력 게이트(Output Gate, o)
: 셀의 상태 중에서 얼마나 많은 정보를 출력할지를 결정- 게이트 게이트(Gate Gate, g)
: 셀에 쓰여질 정보를 조절하는 역할- ct
: 현재 시점의 셀 상태를 나타내며, 망각 게이트의 결과와 입력 게이트의 결과를 조합하여 업데이트됨- ht
: 현재 시점의 은닉 상태로, 셀 상태에서 tanh 함수를 거친 값과 출력 게이트의 조합으로 계산됨=> 이 구조를 통해 LSTM은 기억해야 할 정보와 잊어야 할 정보를 명확하게 구분하여 학습할 수 있으며, 긴 시퀀스에서도 중요한 정보를 효과적으로 유지
-
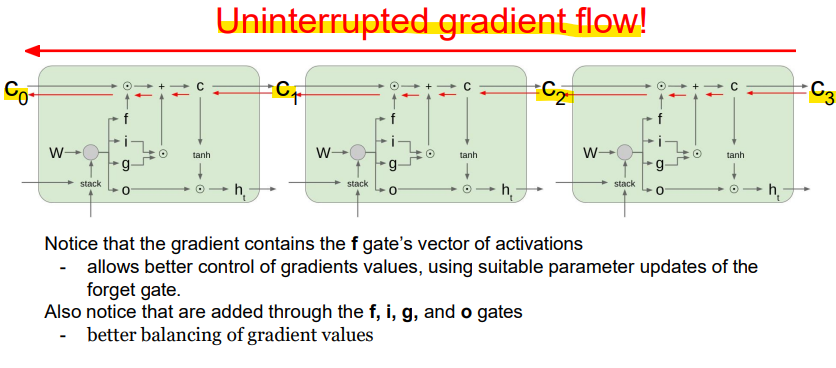
셀 상태 C
: C는 여러 시점에 걸쳐 전달되는 정보. 셀 상태는 망각 게이트, 입력 게이트, 게이트 게이트를 통해 조절되며, 기울기 소실 없이 정보를 전달할 수 있음 -
기울기의 연속적인 흐름
: LSTM에서 기울기가 중단 없이 흐를 수 있음. 이로 인해 역전파(backpropagation)를 할 때, 긴 시퀀스에서도 중요한 정보를 학습할 수 있게 됨 -
게이트의 역할
: 망각 게이트(Forget Gate)의 활성화 벡터가 기울기에 포함되어 있어, 망각 게이트의 매개변수 업데이트를 통해 기울기의 값을 더 잘 조절할 수 있음
: 또한, 입력 게이트, 망각 게이트, 게이트 게이트, 출력 게이트를 통해 기울기의 균형이 더 잘 맞춰져 기울기 폭발이나 소실 문제를 방지할 수 있음
- LSTM이 기울기 소실 문제를 해결하는가?
: LSTM 아키텍처는 RNN이 여러 시점에 걸쳐 정보를 더 쉽게 보존할 수 있도록 만들어줌
-> 예를 들어, 망각 게이트 f=1이고 입력 게이트 i=0일 경우, 해당 셀의 정보는 무기한으로 보존됨
-> 반면, 기본 RNN(Vanilla RNN)은 은닉 상태에서 정보를 보존하기 위해 순환 가중치 행렬 Wh를 학습하는 것이 더 어려움=> LSTM은 기울기 소실 또는 기울기 폭발이 발생하지 않음을 보장하지는 않지만, 장기 의존성(Long-distance dependencies)을 학습하는 것을 더 쉽게 만들어줌(Vanilla RNN에 비해서)
- Gated Recurrent Unit (GRU)
: GRU는 LSTM 네트워크를 단순화하여 두 개의 게이트만 사용함(Update gate z, Reset gate r)
- Update Gate, z
: 이전 은닉 상태를 얼마나 유지할지를 제어
- Reset gate, r
: 과거 정보를 얼마나 잊을지를 결정

<Parameter의 수 비교>
- LSTM
: 추가적인 망각 게이트가 있기 때문에 GRU보다 일반적으로 더 많은 매개변수를 가짐
: 이는 LSTM을 더 강력하게 만들 수 있지만, 특히 작은 데이터셋에서는 과적합에 더 취약할 수 있음- GRU
: GRU는 망각 게이트가 없기 때문에 더 적은 매개변수를 가짐
: 이는 GRU를 계산적으로 더 효율적이고 과적합에 덜 취약하게 만들어, 특히 작은 데이터셋에서 좋은 선택이 될 수 있음
<학습 능력 비교>
- LSTM
: 더 복잡한 아키텍처 덕분에, LSTM은 데이터에서 더 복잡한 패턴과 관계를 학습할 수 있는 잠재력이 있음
: 장기 의존성(Long-distance dependency)을 포착하는 것이 중요한 작업에 매우 적합- GRU
: 더 단순하지만, GRU도 여전히 장기 의존성을 효과적으로 학습할 수 있음
: GRU는 많은 자연어 처리 작업에서 좋은 성능을 보이며, 다양한 시퀀스 모델링 작업에서 인기 있는 선택
<Training 속도 비교>
- LSTM
: 더 많은 매개변수를 가지고 있어, 특히 큰 데이터셋에서 GRU에 비해 훈련 시간이 약간 더 느릴 수 있음- GRU
: GRU는 매개변수가 적기 때문에 훈련 시간이 더 빠를 수 있으며, 더 큰 데이터셋에서도 더 효율적으로 훈련할 수 있음
-> 두 층 모두 다양한 자연어 처리 작업에서 널리 사용되었으며, 인상적인 성과를 보여줌
-> 두 가지를 모두 실험해 보고, 특정 문제에서 더 좋은 성능을 보이는 것을 선택하는 것을 권장
-> 많은 경우, LSTM과 GRU 간의 성능 차이는 크지 않으며, GRU는 단순성과 효율성 덕분에 자주 선호됨
- Neural Machine Translation
- Basic Neural Machine Translation Model (NMT)
- Encoder-Decoder structure (RNN 기반 모델)
- Encoder: 소스 문장의 벡터 표현을 인코딩하는 역할
- Decoder: 조건부 언어 모델로, 타겟 문장을 생성하는 역할
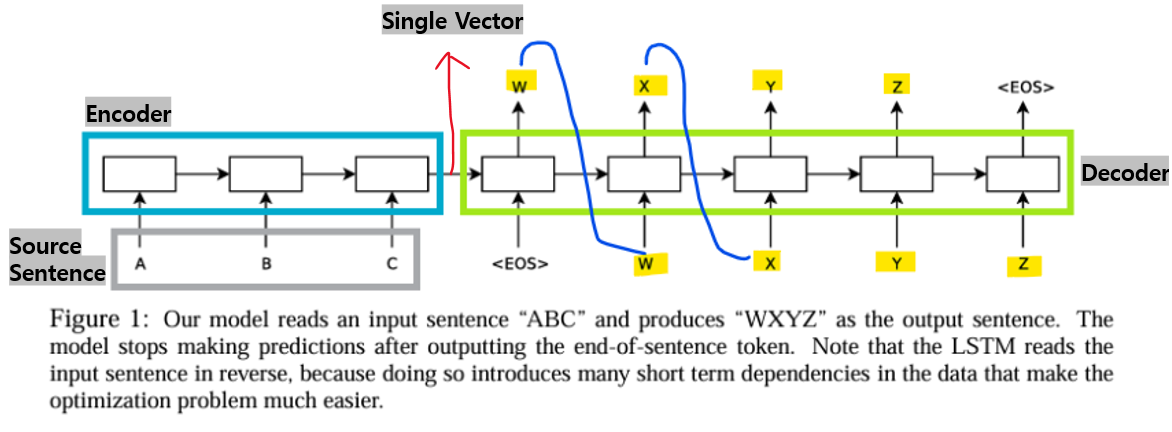
<한계점>
- Encoder
-> 긴 문장의 표현을 충분히 인코딩할 수 X (LSTM/GRU를 사용하더라도)
-> 고정된 크기의 벡터는 제한적임(restrictive)
-> 인코딩된 표현이 편향될 수 있음
- 소스 문장의 각 단어에 'attend(집중)'할 필요가 있음
- Attention-based models
-
개별 단어 벡터의 가중합(weighted sum)을 적응적으로(adaptive) 사용
-
encoder에 양방향(Bidirectional) RNN(BiRNN) 도입
-
적응형(adaptive) 소스 임베딩
-> 가중치는 타겟 은닉 상태에 따라 결정됨 -
정렬(Alignments)은 end-to-end 방식으로 학습됨
-> 데이터(source 문장과 target 문장)로부터
1) Encoder -> Decoder (기존 구조의 문제)
: 가변 길이의 소스 시퀀스를 고정 길이 인코딩으로 처리하는 데 제한이 있음
-> 기존의 인코더-디코더 구조에서는 인코더가 소스 문장의 모든 단어를 하나의 고정된 크기의 벡터로 압축한 후, 이 벡터를 디코더에 전달함.
-> 긴 문장을 처리할 때 정보가 손실되거나, 소스 문장의 특정 부분에 더 집중해야 하는 경우 집중하지 못하는 문제가 발생함.
-> 긴 문장이나 복잡한 문맥을 다룰 때 번역 품질이 저하될 수 있음.
-> Long-term dependency를 잃음(문장이나 데이터 시퀀스의 초반에 나타난 정보가 나중에 등장하는 단어들과 밀접하게 연관될 때)2) Encoder + Attention -> Decoder
: Attention을 사용하는 모델은 긴 문장을 고정 길이 벡터로 인코딩할 필요가 X
: Attention은 소스 문장과 타켓 문장을 정렬할 수 있음
- 어텐션(Attention)
-> Context Vector는 인코더 출력과 어텐션 스코어의 가중합으로 계산됨
-> 디코더는 소스 문장의 어느 부분에 집중할지를 결정함
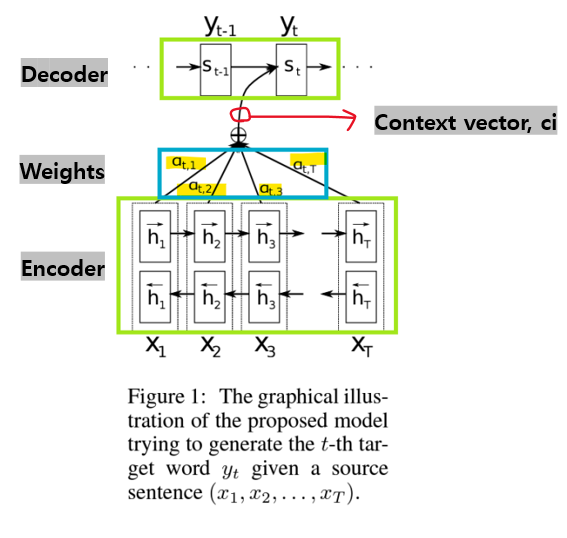
<Attention 메커니즘>
1) 인코더의 출력:
인코더는 소스 문장의 각 단어에 대해 은닉 상태 h₁, h₂, …, hₜ를 생성함. 이 은닉 상태는 소스 문장의 각 단어를 표현하며, 어텐션 메커니즘에서 사용됨.
2) 디코더의 은닉 상태:
디코더는 타겟 문장을 생성할 때, 현재 시점에서의 은닉 상태 sₜ를 사용함. 이 은닉 상태는 디코더가 타겟 단어를 예측하는 데 필요한 정보를 담고 있음.
3) 가중치 계산:
소스 문장의 각 단어가 타겟 단어 예측에 얼마나 중요한지를 결정하기 위해, 가중치 αₜ,i가 계산됨. 이 가중치는 인코더의 은닉 상태 hᵢ와 디코더의 은닉 상태 sₜ를 바탕으로 계산됨. 이 가중치가 클수록 해당 소스 단어가 타겟 단어를 예측하는 데 더 중요한 역할을 함.
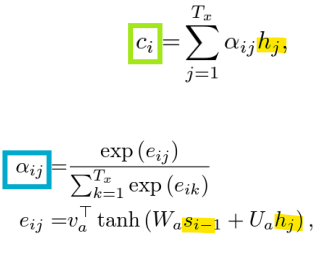
-> ci : Context vector
-> alpha: weight
4) 가중합(weighted sum):
각 소스 단어의 은닉 상태 h₁, h₂, …, hₜ에 계산된 가중치 αₜ,₁, αₜ,₂, …, αₜ,T를 곱해 가중합을 구함. 이 가중합은 소스 문장에서 타겟 단어를 예측하는 데 필요한 중요한 정보만을 추출한 결과
5) 타겟 단어 예측:
디코더는 가중합된 결과를 바탕으로 현재 시점에서의 타겟 단어 yₜ를 예측함.
