Artificial Intelligence
1.1. Neural Networks (Perceptron, Multi-Layer Perceptron)
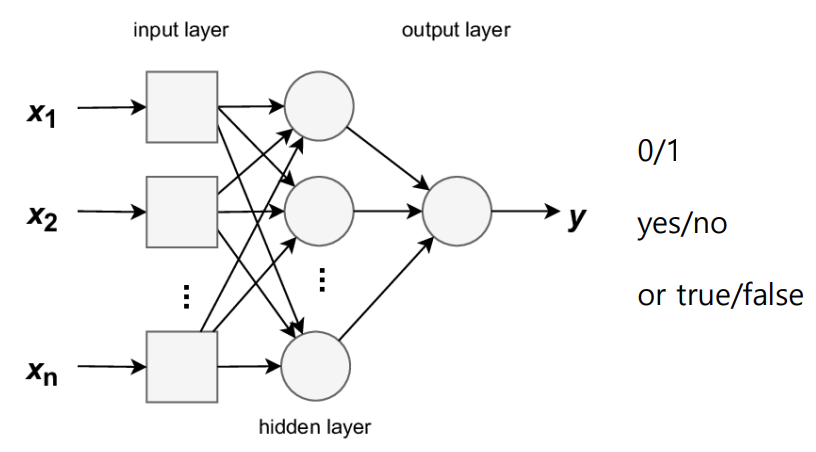
- Dataset의 종류 -> 보통 6:2:2 비율로 나눔 - Training Data - Validation Data : Training Set과 별도로 분리된 data set으로, 훈련 중 모델의 성능을 검증하는 데 사용됨 - Test Data : 학습과 검증
2.2. Neural Networks (Multi-class classification, Regression, Backpropagation)
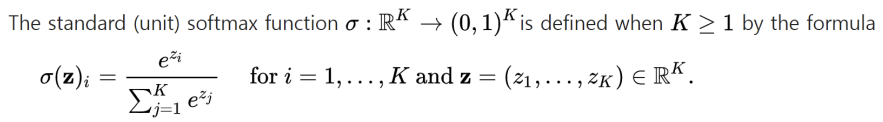
2개보다 더 많은 class를 사용해야 할 땐, multinomial(다항) logistic regression을 사용함\-> Softmax regression\-> Multinomial logit: 다중 클래스 분류 문제에서 주로 사용됨: 입력된 값들을 확률 분포로
3.3. CNN (Convolutional Neural Networks, Deep CNN)

Feed-forward Networks(FNN) : 이미지 및 비디오 처리에는 확장성 부족CNN : 이미지 및 비디오 처리에 특화됨\-> FNN에서는 한 층의 모든 노드가 다음 층의 모든 노드와 연결됨\-> 각 연결에는 가중치가 있으며, 학습 알고리즘을 통해 학습되어
4.4. CNN (ResNet, DenseNet, Modern Conv models)
- ResNet * 문제 deeper networks가 수렴을 시작할 수 있을 때, 성능 저하 문제(degradation problem) 발생 -> 이는 overfitting에 의해 발생된 게 아님 -> 적절하게 깊은 모델에 더 많은 층을 추가하면 훈련 오류가 증가
5.5. Recurrent Neural Networks (RNN)

언어의 sequential nature(순차적 특성)를 직접 처리하는 매커니즘을 갖고 있어, 임의의 고정된 크기의 윈도우를 사용하지 않고도 언어의 temporal nature(시간적 특성)를 다룰 수 있음이전 문맥을 recurrent connections(순환 연결)을
6.6. Transformer and Large Language Models
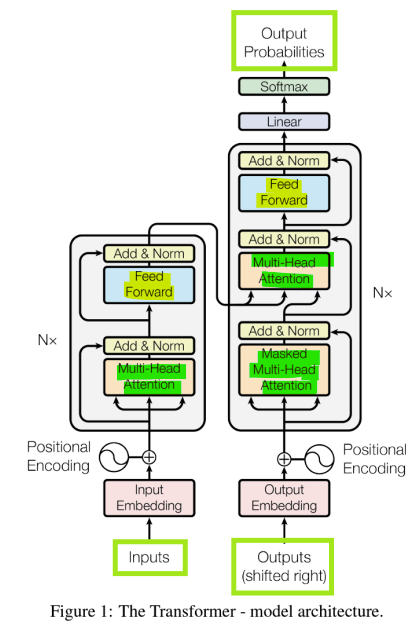
차이점: long-range dependencies(장기 의존성 처리) and parallelization(병렬 처리)RNN의 단점: Recurrent computation이 느림Transformer: 주로 Attention에 기반한 특별한 신경망 구조, 더 고급스러운
7.7. Transformers for Speech
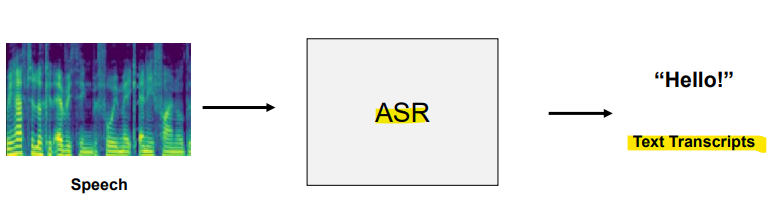
자동 음성 인식: 음성을 텍스트로 변환아키텍처: Encoder-decoder Transformer기계 번역: 인코더는 소스 언어를 처리, 디코더는 타겟 언어로 번역을 생성텍스트 요약: 모델은 입력 텍스트를 인코딩하고, 이를 요약된 형태로 디코딩하여 큰 텍스트를 짧고 일
8.8. Vision Transformers
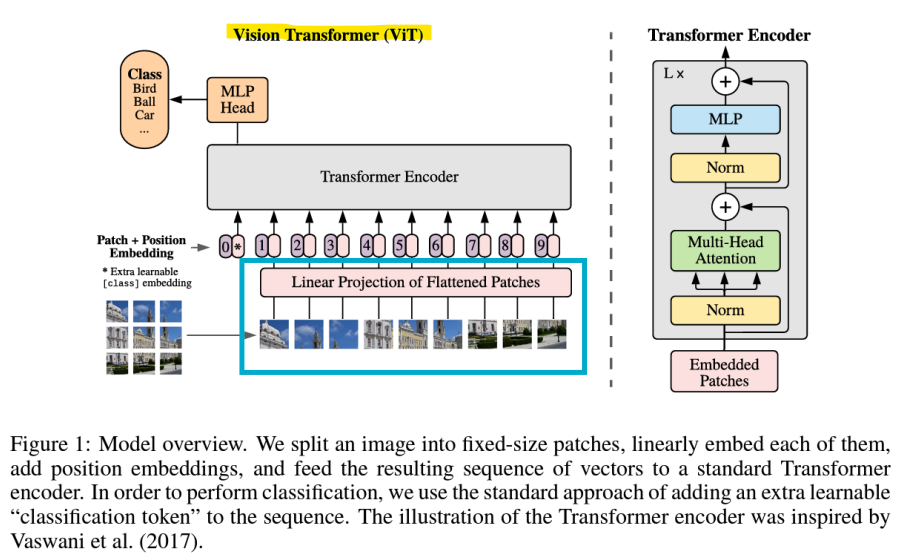
: 컴퓨터 비전을 위해 설계된 Transformer입력 이미지가 patch로 나뉘며, 각각은 patch embedding layer를 통해 선형적으로 mapping된 후, 표준 Transformer encoder에 입력됨Transformer는 image patch를 t
9.Generative Model 1. Variational Autoencoder
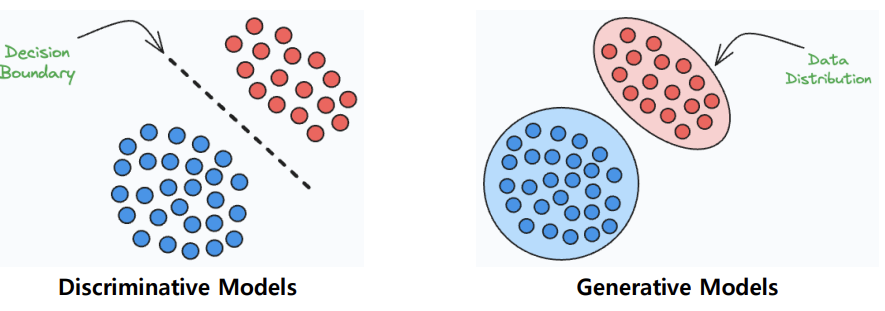
Discriminative Model(구분 모델) : 서로 다른 클래스들을 구분하는 결정 경계(Decision Boundary)를 학습하는 모델 목표: Conditional probability (조건부 확률)을 최대화하는 것 -> 주어진 입력 x에 대해 정답 레이블
10.Generative Model 2. Generative Adversarial Networks (GAN)
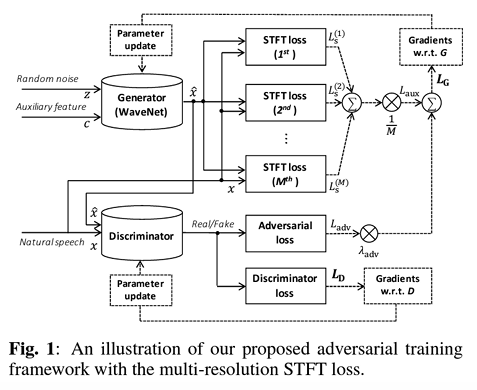
- 적대적 학습(Adversarial Training) - 생성자(Generator, counterfeiter위조범) : 더 현실적인 샘플을 생성하려고 노력 - 판별자(Discriminator, 경찰관) : 실제 데이터와 가짜 데이터를 구별하려고 노력, 실패 시 패널티
11.Generative Model 3. Normalizing Flow
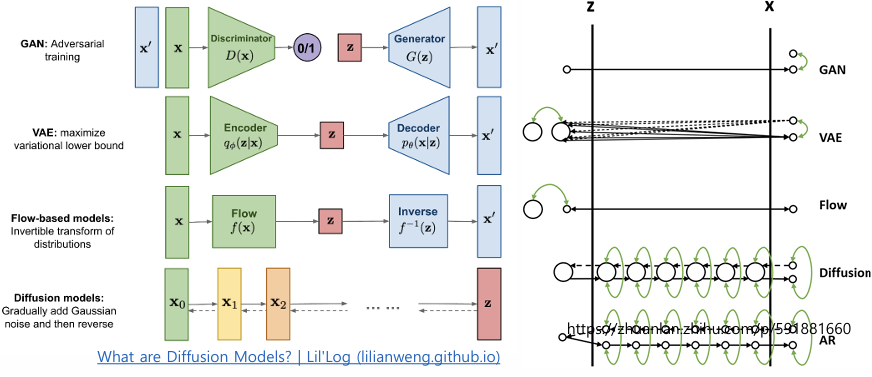
정규화 흐름은 가역적 변환(invertible transformation)을 사용하여 단순한 분포에서 데이터 분포를 추정단순히 로그 우도(log-likelihood) 목표만으로 모델을 학습 가능: 단순한 분포를 시작으로 가역적 변환을 통해 복잡한 데이터 분포를 학습하는