- ResNet
* 문제
-
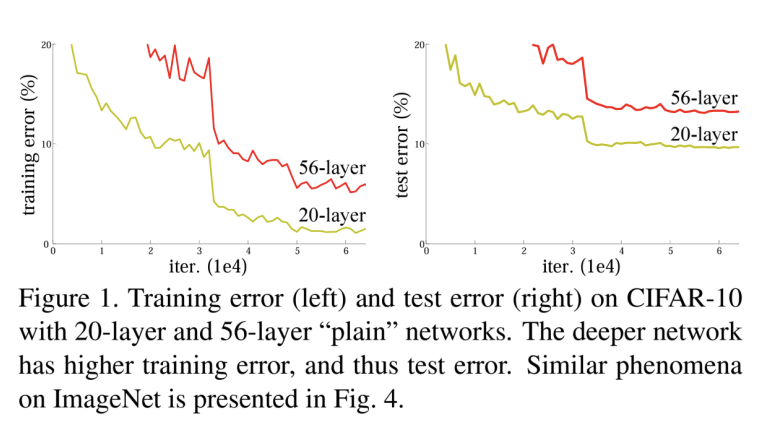
deeper networks가 수렴을 시작할 수 있을 때, 성능 저하 문제(degradation problem) 발생
-> 이는 overfitting에 의해 발생된 게 아님
-> 적절하게 깊은 모델에 더 많은 층을 추가하면 훈련 오류가 증가함 -
훈련 정확도의 저하는 모든 시스템이 동일하게 최적화하기 쉬운 것이 아님을 나타냄
-> 얕은(shallow) 모델은 최적화가 더 쉬울 수 있음
* 목표
- deeper model을 훈련하면서 훈련 오류가 증가하지 않게 만드는 것
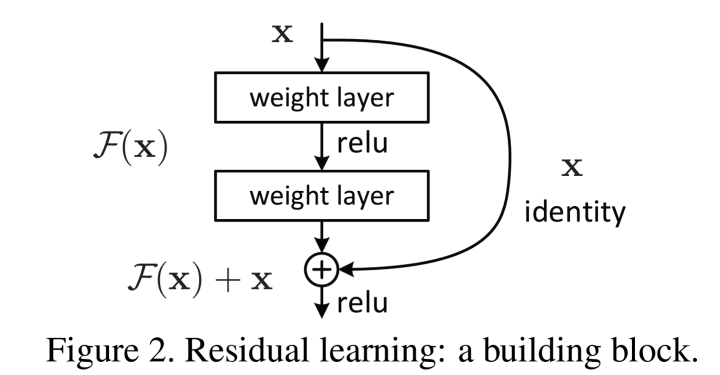
* Residual Learning (Skip Connection), 잔차 학습
: 신경망이 학습하는 대상이 직접적인 출력이 아니라, 잔차(residual), 즉 입력에서 출력으로 가는 변화량(출력이 입력과 얼마나 다른지)을 학습하는 방식
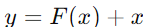
-> Residual learning의 수식적 표현
-> 항등 함수(identity function) 적용(x를 그대로 더해줌)
-> 항등 함수는 입력값에 아무런 변화를 주지 않기 때문에, X를 그대로 더해준다는 의미에서 항등 함수라고 부르는 것
* Skip Connection (스킵 연결)
: Residual learning을 구현하기 위한 구조적 기법
: 일반적으로 2개 이상의 layer를 건너뛰어 입력을 다음 층에 더해주는 방식
ex) 3번째 layer에서 F(x3)라는 출력값이 나왔다면, skip connection을 통해 이 값이 5번째 layer의 출력값에 더해짐
y5 = F(x5) + F(x3)

- F(x) + x의 형태는 단순 연결이 있는 feedforward networks로 구현할 수 O
-> 단순 연결(shortcut connections)은 단순히 항등 매핑(identity mapping)을 수행하며, 원래의 x값이 쌓인 층의 출력에 더해짐-> residual learning으로 인해 네트워크는 계속해서 새로운 정보를 학습하면서도, 입력 정보의 일부를 잃지 않고 보존할 수 있음! 순방향 신호와 역방향 신호 모두 사라지지 않음
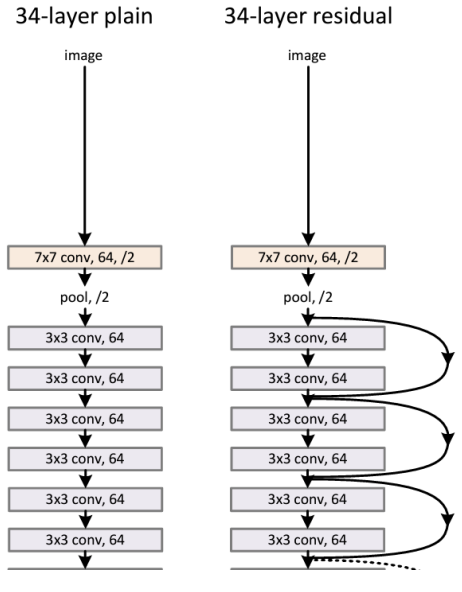
- Plain Network
: VGG를 베이스로 함
: 3x3 convolution을 사용
- ResNet
: blocks 사이에 skip connection을 추가
-> 순방향 신호도, 역방향 신호도 사라지지 않음
* 결과
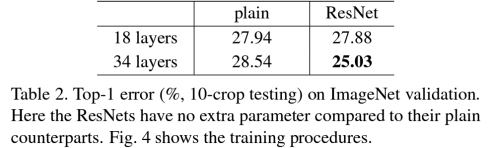
-> 18개의 layer보다 34개의 layer의 경우의 test error가 더 낮았음
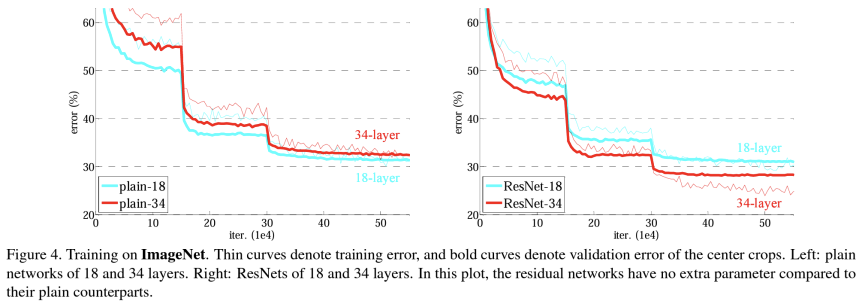
-> plain의 경우 34 layers가 18 layers 보다 성능이 더 떨어짐
-> ResNet의 경우 34 layers가 18 layers 보다 성능이 좋아짐
* Deeper ResNet
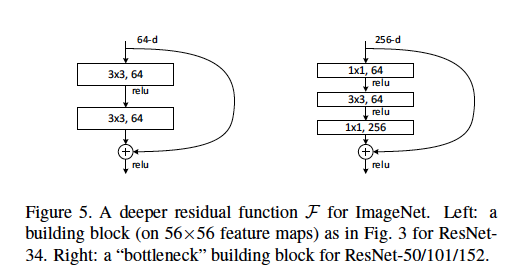
: 18/34/50/101/152 layers
* Deeper Bottleneck Architectures
: 1x1 layer를 추가하여 차원을 줄이고 늘림으로써, 3x3 layer는 더 작은 입력/출력 차원을 가진 병목 지점(bottleneck)이 됨
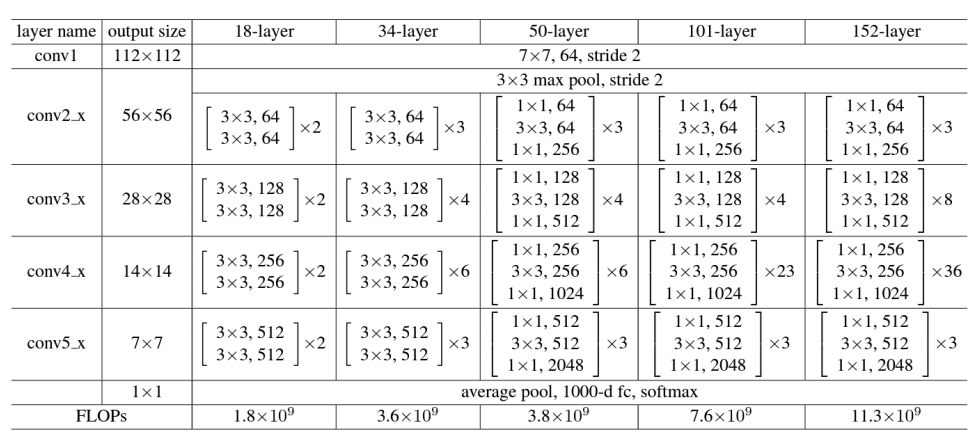
-> 18 layers와 34 layers는 간단한 3x3 합성곱 레이어로만 구성된 반면, 50 layers 이상에서는 1x1 합성곱 레이어가 추가되어 더 깊은 네트워크에서 차원을 조정하며(줄임) 효율성을 높이는 병목 구조 사용
* ResNet
: ILSVRC2015에서 1위
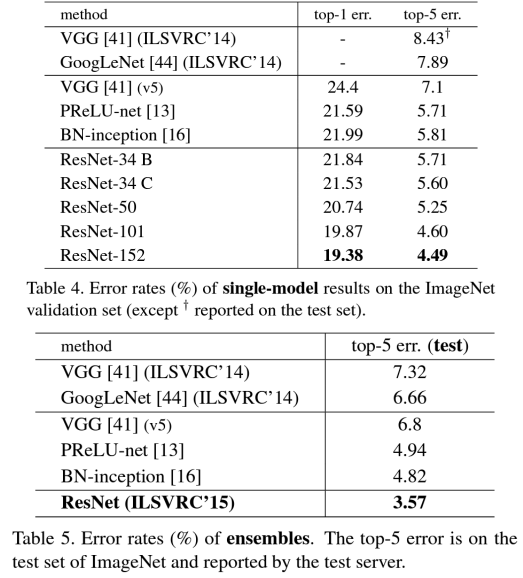
-> 에러가 가장 낮음
- ResNet with MNIST
* MNIST dataset
: 다양한 이미지 처리 시스템 학습에 사용되는 손으로 쓴 숫자들의 큰 데이터베이스
- Improving ResNets: Stochastic Depth
* 목표
: 테스트 시에는 네트워크의 depth를 유지하면서, training 중에는 네트워크의 depth가 줄어들게 만드는 것
* Stochastic Depth
: 학습 중에 ResBlock 전체를 무작위로 drop하고, skip connections을 통해 변환을 우회함(Dropout과 유사)
-> ResBlock : F(x) + x
-> Stochastic depth가 적용된 ResBlock : Drop_path(F(x)) + x
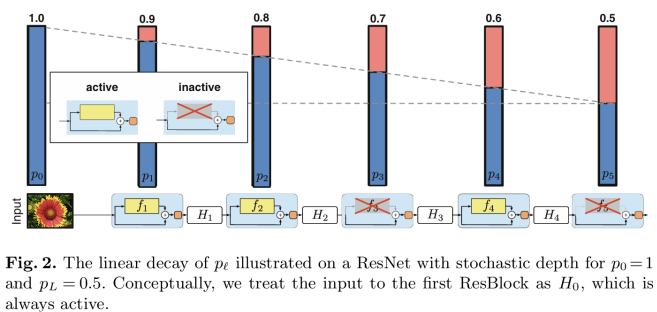
-> 학습 중에 확률적으로 ResBlock을 비활성화(inactive)시킴
-> 비활성화된 블록은 skip connection을 통해 우회됨
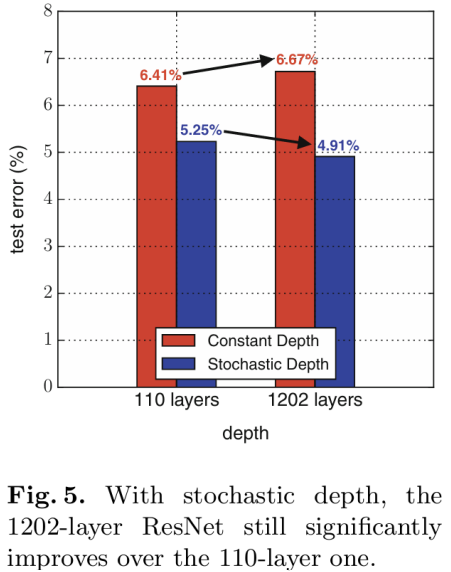
- 훈련 중 짧은 네트워크를 사용하여 소실되는 기울기를 줄이고, 훈련 시간을 단축함
- 훈련 시 각 패스에서 일부 레이어를 무작위로 삭제함
- identity function으로 우회함(skip connection)
- 테스트 시에는 full deep network를 사용함
-> 동일한 아키텍처로 ResNet의 성능을 개선함
- 학습 시:
확률적으로 ResBlock을 비활성화 함(무작위로 Drop)
skip connections를 통해 기울기 소실을 방지, 네트워크가 더 깊어지더라도 중요한 정보가 잃어버리지 않고, 네트워크가 더 복잡한 패턴 학습 가능- 테스트 시:
Dropout을 사용하지 않음(모든 뉴런이 활성화인 상태)
skip connections 사용해서 더 깊은 네트워크에서 효율적으로 정보를 전달, 더 정교한 예측 가능(+ 모델 일관성 유지)-> 이러한 과정을 통해 테스트 시에는 네트워크의 depth를 유지, 학습 시에는 네트워크의 depth가 줄어들게 함!
- Improving ResNets: Wide Residual Networks
: 잔차(Residuals)가 중요한 요소이지, 깊이가 중요한게 아님을 주장
: 더 넓은 Residual Block을 사용
-> 각 층에서 F 필터 대신 F x k 필터 사용
- 깊이 : layer 개수
- 너비 : 각 layer가 처리할 수 있는 정보의 양 (필터 개수나 뉴런 수)
: 50 layers의 넓은 ResNet이 152 layers의 original ResNet을 능가함
: 깊이를 늘리는 대신 너비를 늘리는 것이 더 계산 효율적임 (병렬처리가능, parallelizable)
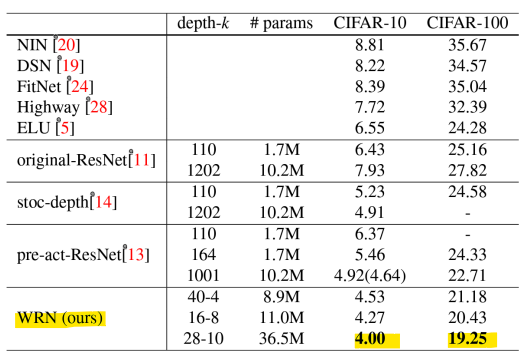
-> 잔차 네트워크의 깊이를 줄이고 너비를 늘려 성능과 효율성 개선!
-> 가장 낮은 에러율을 보임
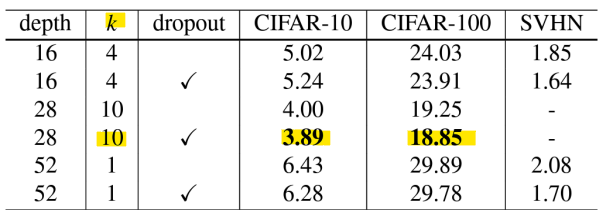
- 잔차 네트워크의 깊이가 다르더라도 너비를 넓히는 것은 일관되게 성능을 향상시킴
- 깊이와 너비를 동시에 증가시키는 것은 파라미터 수가 너무 많아져서 더 강한 정규화가 필요해질 때까지 성능을 향상시킴
-> 깊이와 너비를 모두 증가시키면 성능이 좋아지지만, 어느 시점에서는 모델의 파라미터 수가 지나치게 많아지기 때문에 정규화가 필요함
- Improving ResNets: ResNeXt
: 이미지 분류를 위한 간단하고 고도로 모듈화된 네트워크 아키텍처를 제시함
- 깊은 신경망을 위한 집합된 잔차 변환(Aggregated Residual Transformations)
-> ResNet을 기반으로 함
-> 여러 개의 병렬 경로를 통해 Residual block의 너비를 증가시킴 (Cardinality, 경로의 개수)- Cardinality : 병렬 경로의 수 (하나의 residual block 내에서의 경로 수)
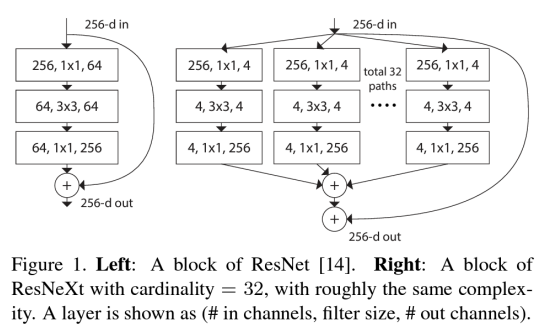
- 병렬 경로는 Inception module과 유사
* Group Convolution
: 데이터를 여러 그룹으로 나누어 처리함으로써 병렬 경로의 수(Cardinality)를 증가시키는 방식
: 분할, 변환, 집합의 조합으로 재구성할 수 있음
- 분할(Splitting): 벡터 x를 저차원 임베딩으로 분할함 (큰 데이터를 여러 작은 조각으로 나눔)
입력 벡터를 여러 그룹으로 나누어 각 그룹이 저차원의 임베딩을 처리할 수 있도록 함- 변환(Transforming): 저차원 표현을 변환함 (나눈 조각을 각각 따로 처리)
각 그룹이 독립적으로 필터를 사용하여 저차원 임베딩을 변환함. 즉, 각 그룹이 개별적으로 정보를 처리- 집합(Aggregating): 모든 임베딩에서 변환된 결과를 집합함 (각각 처리한 결과를 다시 합쳐서 하나로 만듦)
변환된 저차원 임베딩들을 다시 하나로 결합하여 전체적인 출력 결과를 만듦
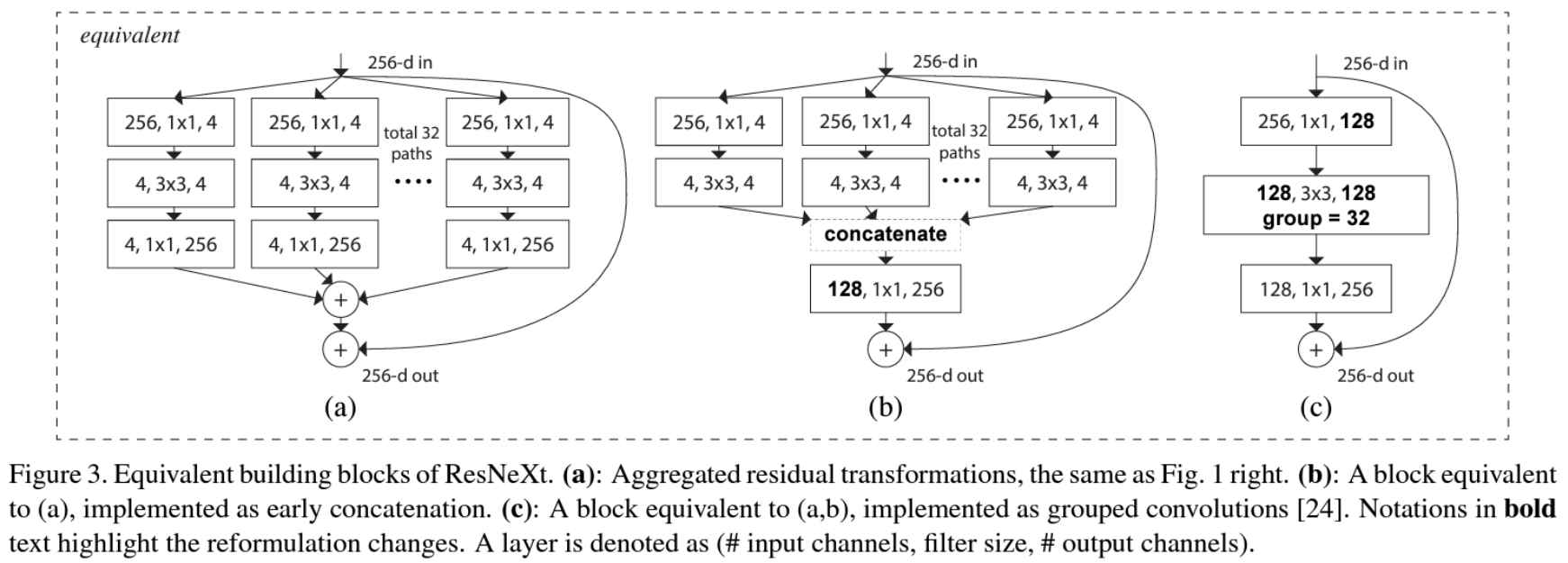
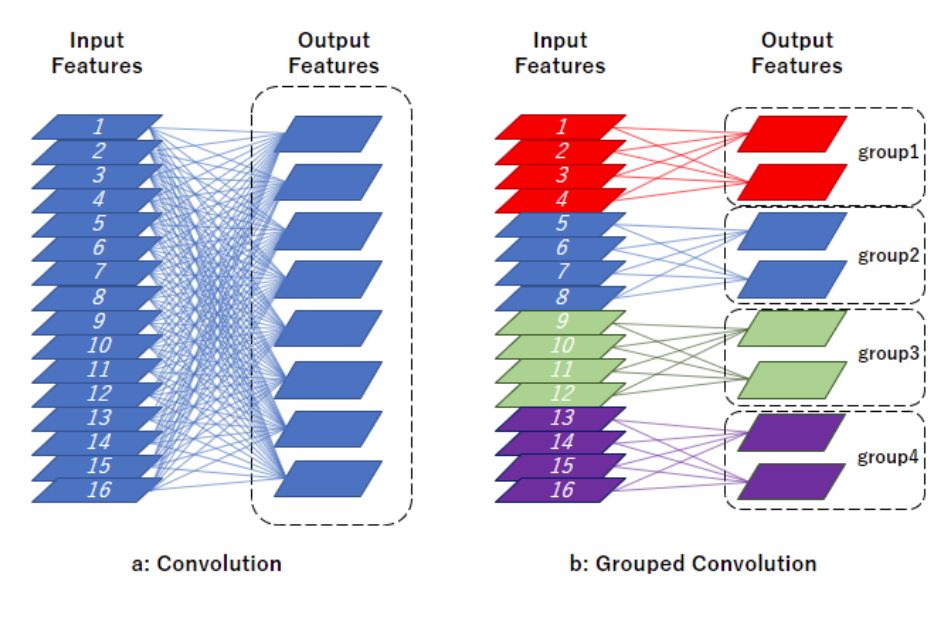
- Width VS Cardinality

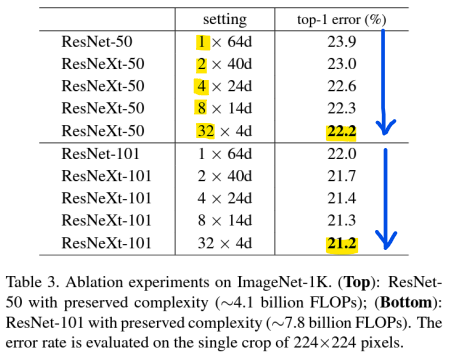
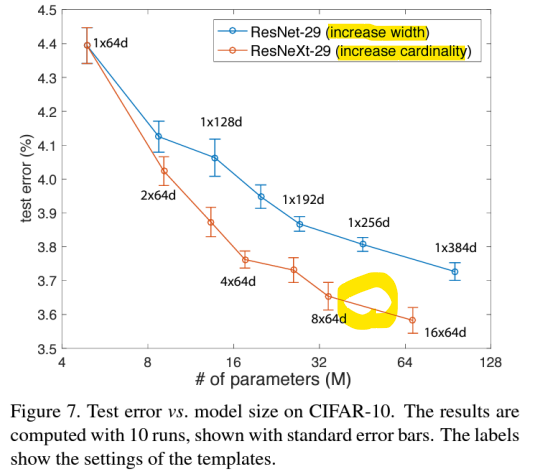
-> 복잡도(Complexity)를 유지하면서 카디널리티 C를 1에서 32로 증가시키면, 오류율이 지속적으로 감소함
- Cardinality C를 증가시키거나 깊이 또는 너비를 증가시켜 복잡도를 높이는 방법 비교
- ResNet-200: 200개의 layers로 깊이를 증가시킴
- ResNet-101, 너비 증가: 병목 너비를 늘려 네트워크의 너비를 증가시킴
- ResNeXt: Cardinality(C)를 2배로 늘려 복잡도를 증가시킴
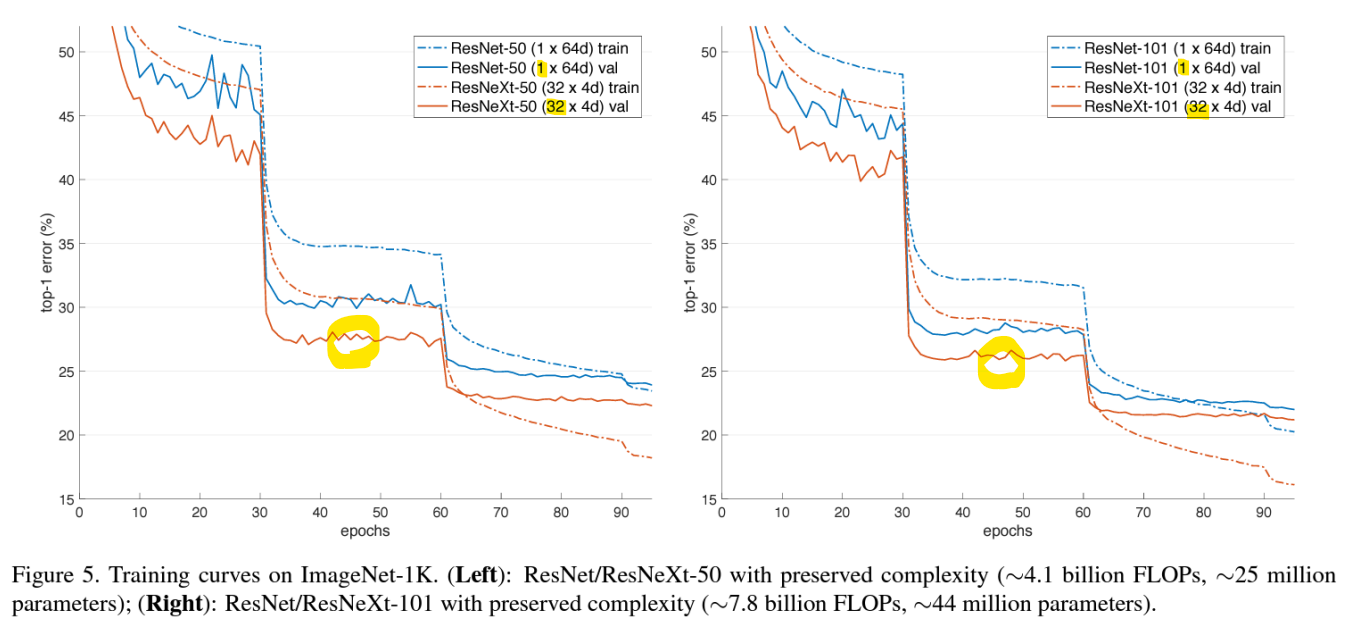
-> Cardinality를 증가시키면(ResNeXt) 성능이 꾸준히 향상됨
-> 너비(Width)를 늘리면 성능이 향상되긴 하지만, Cardinality 증가보다는 성능 향상 폭이 적음
-> FLOPs(연산 복잡도)를 2 배로 늘려도 Cardinality를 더 많이 증가시킨 ResNeXt 모델이 가장 효율적, 성능 굿
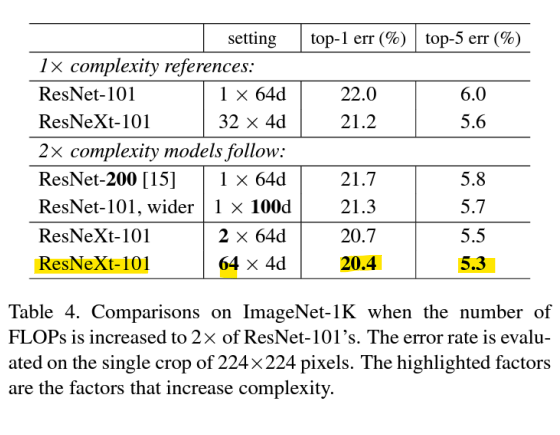
-> Cardinality를 증가시키는 것이 width를 증가시키는 것보다 훨씬 효과적임
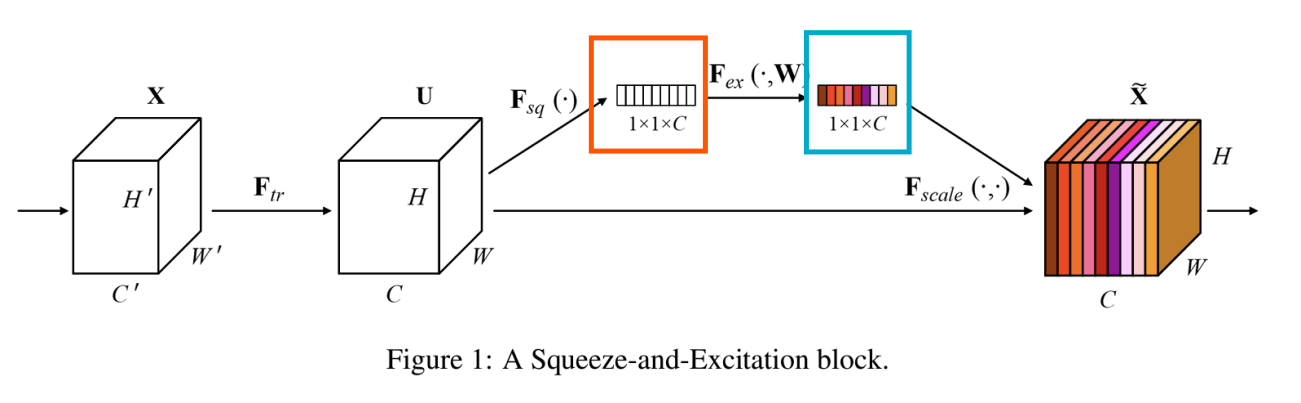
- Improving ResNets: Squeeze-and-Excitation Networks(SENet)
: ILSVRC 2017 1등 모델
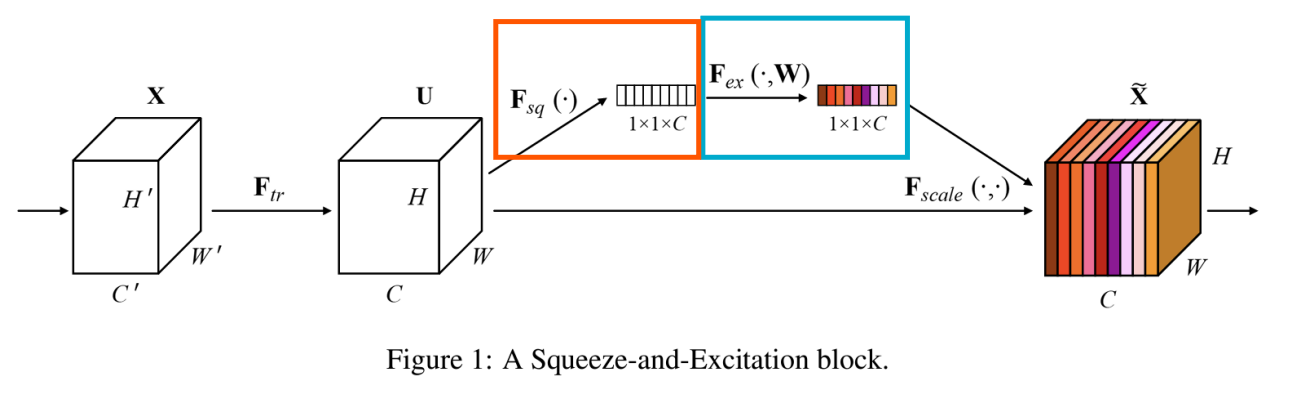
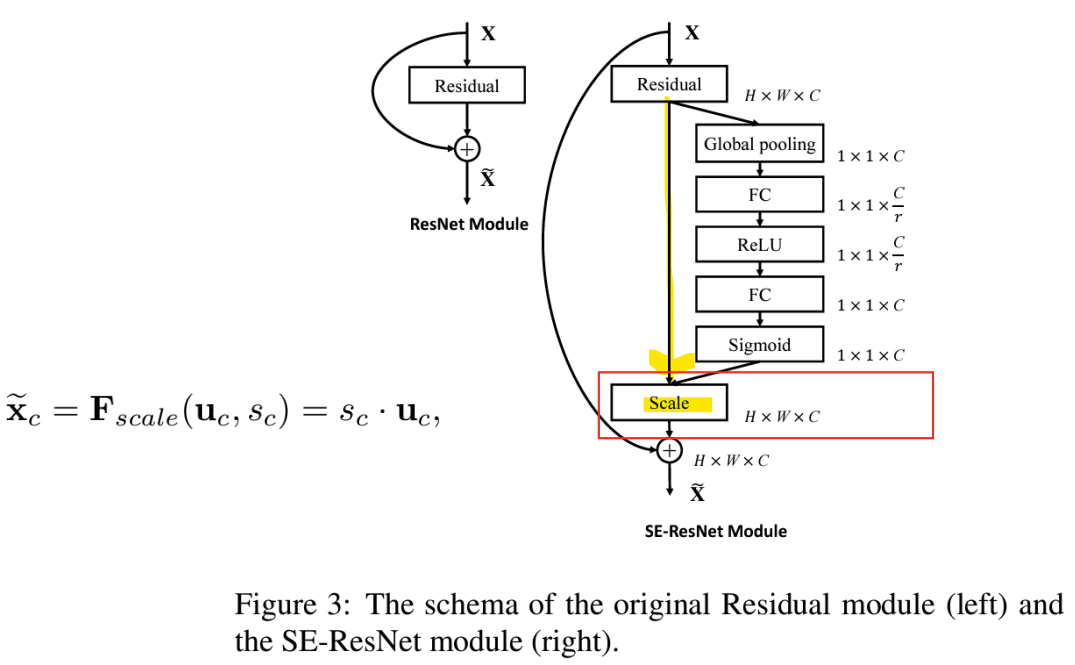
<SE 블록>
- 주황 부분: Squeeze(압축)
-> feature map의 각 채널에 대해 글로벌 평균 pooling을 수행하여 채널 간의 정보를 요약(feature map의 공간적 차원을 제거하여 채널별 통계 정보를 얻음) - 파랑 부분: Excitation(재조정)
-> 축소된 정보를 통해 2개의 Fully Connected Layer를 거쳐 각 채널의 중요도를 결정하는 가중치(0~1사이의 값)를 학습함
-> 가중치는 원래 feature map의 각 각 채널에 곱해짐
- 모듈 내에서 채널 간 상호 의존성을 명시적으로 모델링
- Feature Recalibration(특징 재조정)
-> 유용한 특징을 선택적으로 강화, 덜 유용한 특징을 억제
-> 각 채널의 scale을 곱함 (learnable, 학습 가능)
- 어떤 network에도 적용 가능
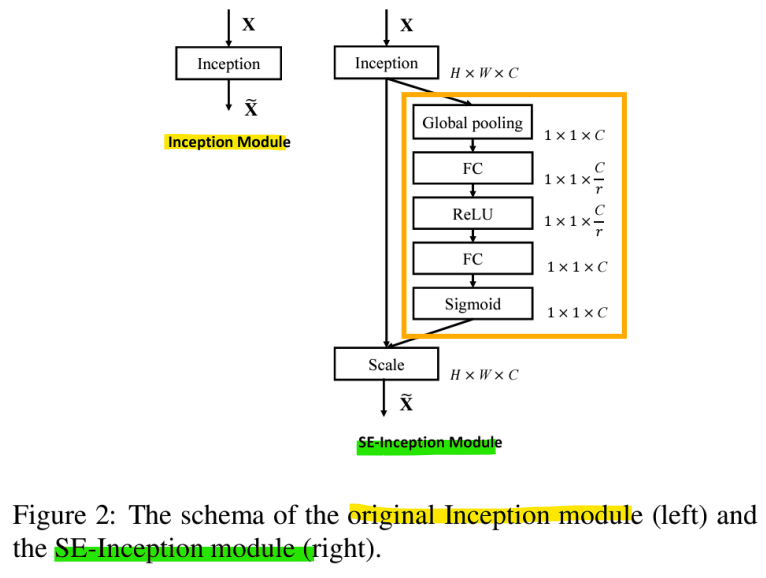
-> SE-Inception Module
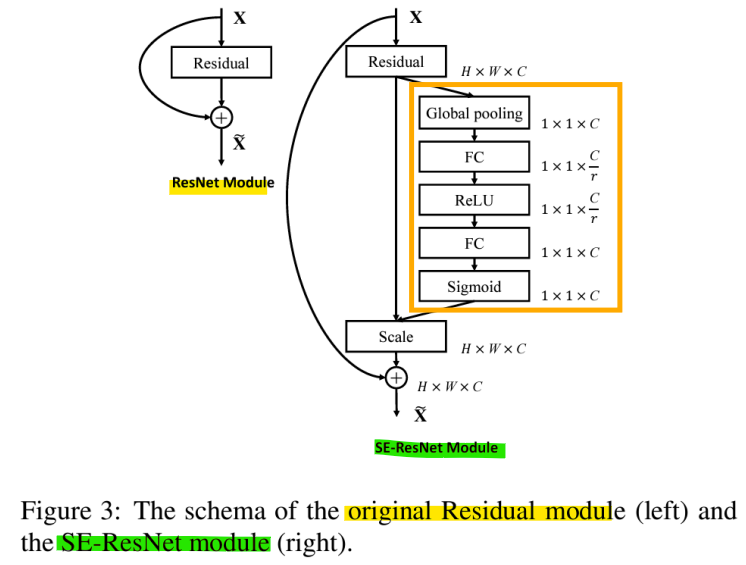
-> SE-ResNet Module
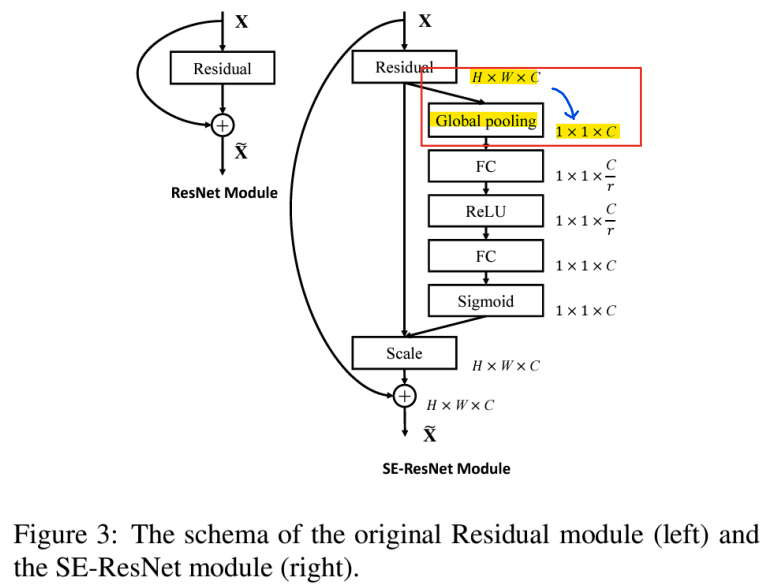
- Squeeze: Global Information Embedding
-> channel-wise statistics(채널별 통계)를 생성하기 위해 글로벌 평균 pooling을 통해 feature map [H,W,C]를 [1,1,C]로 축소
-> 채널별 response의 글로벌 distribution(분포)
- Excitation: Adaptive Recalibration (적응형 재조정)
-> Squeeze 연산에서 집계된 정보를 활용하기 위해 Excitation 모듈은 채널 간 의존성을 완전히 포착하는 것을 목표로 함
-> 채널별 가중치를 생성하기 위한 Gating mechanism(Sigmoid) -> 활성화 함수를 사용하여 각 채널에 대한 가중치를 0~1 사이의 값으로
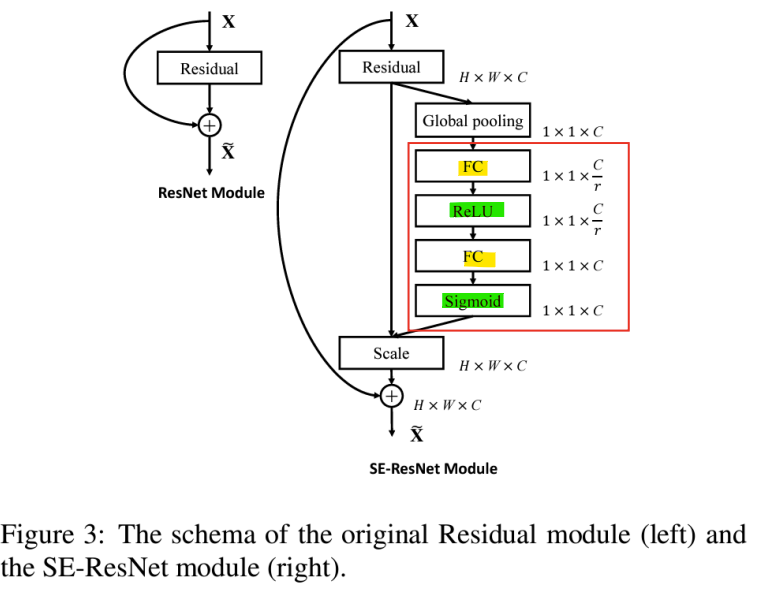
- Scale
-> feature map과 scalar(SE 블록의 출력) 사이에 채널별 곱셈을 통해 feature map의 가중치를 재조정
- Model and Computational Complexity(계산 복잡도)
- SE-ResNet-50 vs ResNet-50
파라미터: 2%~10% 추가 파라미터
계산 비용: 1% 미만의 추가 계산
GPU 추론 시간: 10% 추가 시간
CPU 추론 시간: 2% 미만의 추가 시간
-> SE Block의 유/무: 계산 복잡도의 큰 차이는 없음!
- Performance
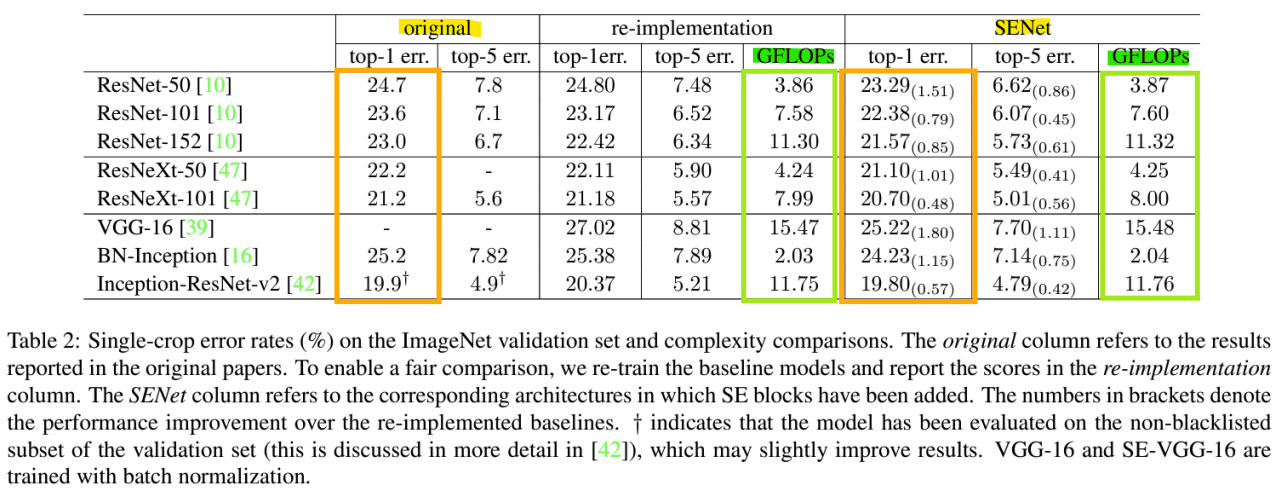
-> SE Block을 추가한 모델의 error율이 더 작음
-> SE 블록은 계산 복잡도(GFLOPs)가 극히 적게 증가하면서, 성능을 향상시킴!
- DenseNet
- 기본 연결성
: feedforward만 사용
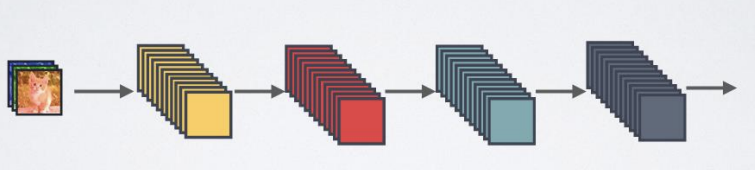
- ResNet 연결성
: Identity mapping(입력이 변형 없이 출력으로 전달되는 것)은 gradient propagation(전파)을 촉진함
-> 요소별 덧셈을 통한 skip-connection 사용
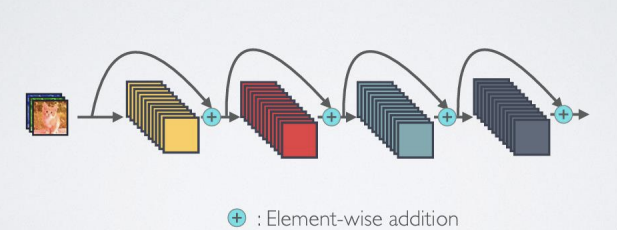
- Dense 연결성
: Identity mapping(입력이 변형 없이 출력으로 전달되는 것)은 gradient propagation(전파)을 촉진함
채널별 연결(concatenation)을 통한 skip-connection 사용
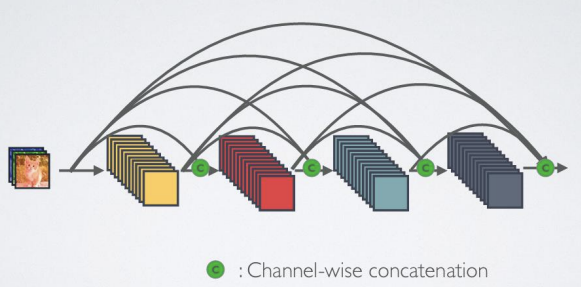
- Dense and Slim
: 비교적 작은 growth rate로도 최첨단 결과를 얻기에 충분함
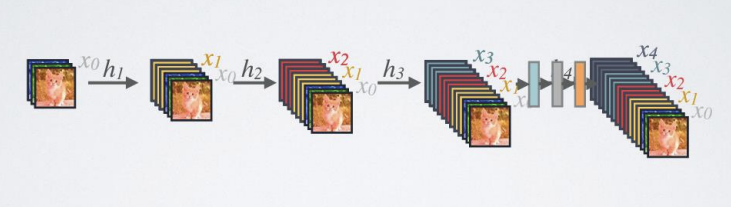
- Forward propagation
-> 모든 레이어에서 이후의 모든 레이어로 직접 연결을 도입
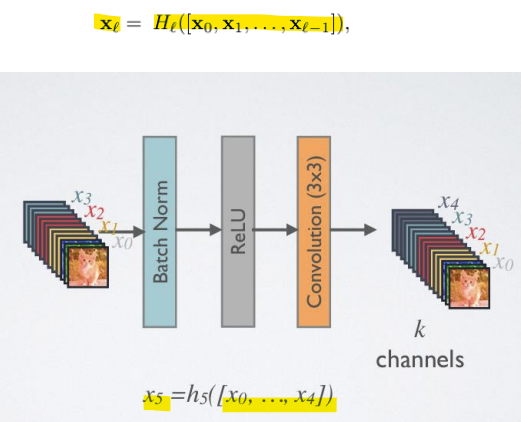
-> l번째 레이어는 모든 이전 레이어의 특징 맵을 받음
- Pooling layer
-
feature map의 크기가 변할 때는 연결(concatenation) 연산을 사용할 수 없음
-
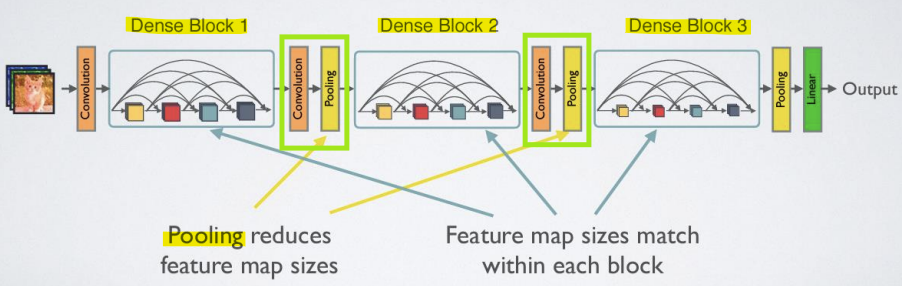
컨볼루션 네트워크의 필수적인 부분은 feature map의 크기를 변경하는 down-sampling layers
-> down-sampling을 용이하게 하기 위해 네트워크를 여러 개의 밀집 연결된 Dense Block으로 나눔 -
Dense Block 간의 Transition layer
-> convolution과 pooling 수행 -
convolution: 특징 맵의 크기와 채널 수를 조정하여, 다음 Dense Block으로 전달할 때 적합한 형식을 만듦
-
pooling: 풀링 연산을 통해 특징 맵의 공간적 크기를 줄임. 주로 평균 풀링(average pooling)이나 최대 풀링(max pooling)이 사용
<장점>
- Strong Gradient flow
: 효과적인 gradient 전파(vanishing gradient 문제 최소화) - Parameter and Computational Efficiency(파라미터 및 계산 효율성)
: 적은 파라미터 및 적은 계산 자원으로 높은 성능을 냄 - Maintains low complexity features
: 복잡도가 낮은 특징을 유지하면서 성능을 보장
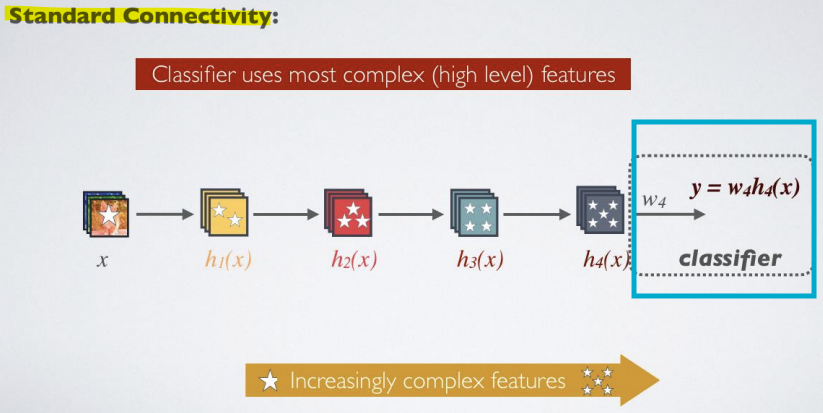
-> 기본 연결성: Classifier는 가장 복잡한 features를 사용
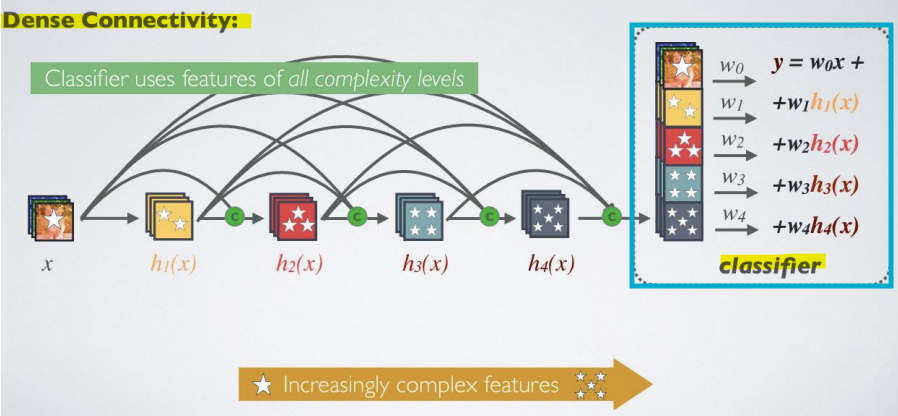
-> Dense 연결성: Classifier는 모든 복잡도 레벨의 feature를 사용
- 성능
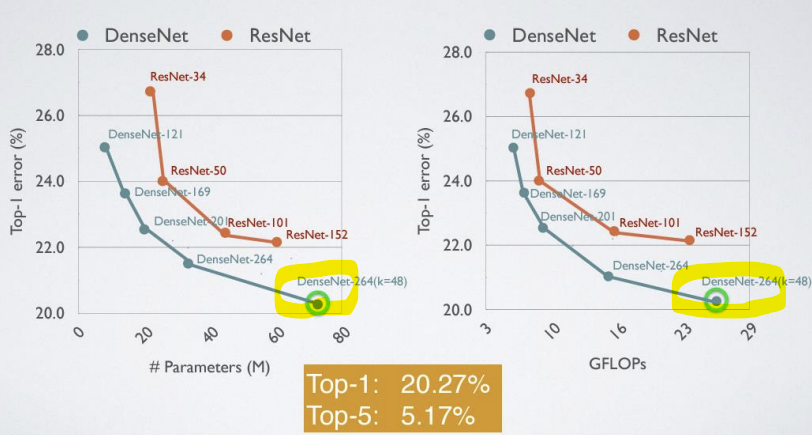
-> ResNet보다 DenseNet이 더 좋음!
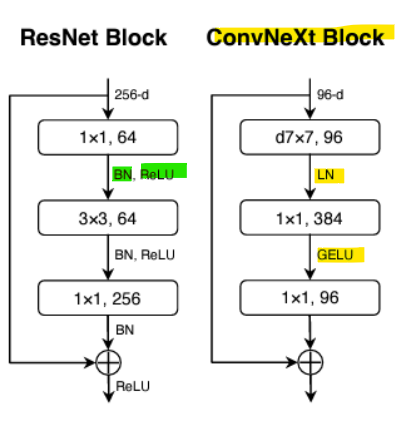
- ConvNeXt
-
(~2022) Vision Transformer(ViT) Networks가 기존의 컨볼루션 신경망(CNN)을 능가함
-
ConvNeXt는 표준 ResNet을 Vision Transformer 설계로 현대화함
-
ConvNeXt는 CNN의 전통적인 구조를 현대화하여, ViT와 같은 최신 비전 모델과 경쟁할 수 있도록 설계됨
-
ResNet의 구조를 기반으로 하면서 CNN의 강점을 유지하고, 최신 기술 트렌드를 통합한 모델
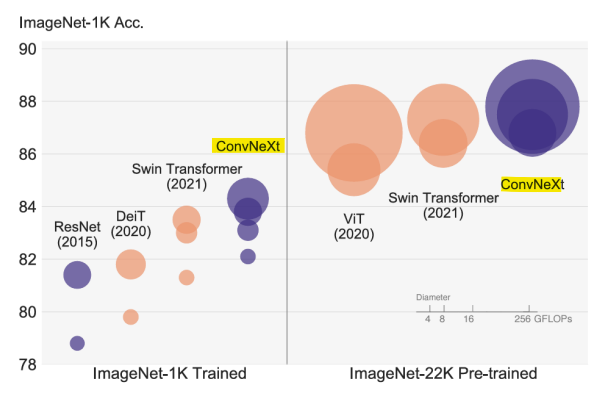
-
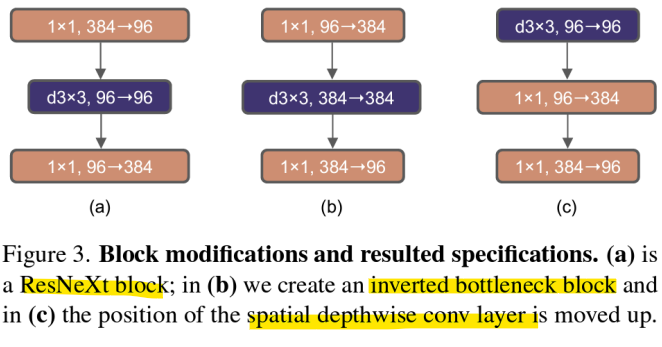
ResNeXt -> ResNeXt의 그룹화된 컨볼루션 방식에서 착안하여 더 큰 커널과 다양한 개선을 도입
-
Inverted Bottleneck -> 채널 수를 먼저 확장한 후에 차원을 줄이는 방식으로 설계
-
Large Kernel -> 큰 커널과 Depthwise Convolution을 도입하여 공간적 정보 처리의 효율성을 높임
- GELU 활성화 함수
- 더 적은 활성화
- 더 적은 정규화
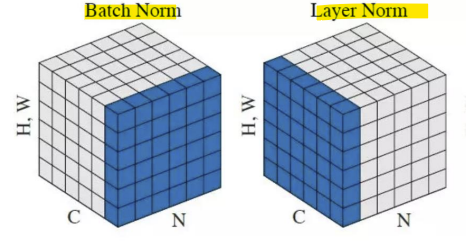
- BN(Batch normalization) 대신 LN(Layer normalization) 사용
-> 배치 정규화: 미니배치(batch) 내의 각 특성(feature)별로 정규화
-> 레이어 정규화: 각 샘플(sample)별로 전체 특성에 대해 정규화
< In-layer normalization techniques for training very deep neural networks >
: 매우 깊은 신경망을 효과적으로 학습시키기 위해 각 레이어 내부에서 입력을 정규화하는 방법(feature scaling)
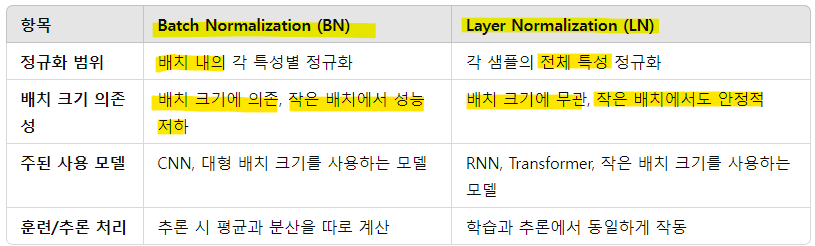
- Batch Normalization
- 내부 공변량 변화(internal covariate shift)를 줄이고, 이를 통해 딥 뉴럴 네트워크의 학습 속도를 가속화하는 것을 목표로 함. 레이어 입력의 평균과 분산을 고정하는 정규화 단계를 통해 이를 달성함
- 배치 정규화는 네트워크를 통과하는 그래디언트 흐름에도 긍정적인 영향을 미치며, 파라미터의 스케일이나 초기 값에 대한 그래디언트 의존성을 줄여줌
- 미니배치(batch) 내의 특성(feature)별로 정규화를 수행. 즉, 배치 안에 있는 모든 샘플에 대해 각 특성의 평균과 분산을 계산하여 정규화함 -> 배치 단위로 동작하기 때문에 배치 크기에 의존적
- Layer Normalization
- 숨겨진 레이어 내 뉴런으로 들어오는 입력의 합에서 직접 정규화 통계를 추정하므로, 정규화가 학습 사례들 간에 새로운 의존성을 도입하지 않음
- 최근 LN은 트랜스포머 모델에서 사용되고 있음
- 각 샘플의 전체 특성(feature)을 정규화함. 즉, 배치 크기에 관계없이 각 샘플의 특성들에 대해 평균과 분산을 계산하여 정규화. 배치 크기와 무관하게 작동함
-
BN이 더 좋은 경우:
큰 배치 크기를 사용하는 경우.
컴퓨터 비전 작업(CNN)에서 주로 활용.
이미지/영상 처리 작업에서 널리 검증된 방식.
고속 수렴을 원할 때. -
LN이 더 좋은 경우:
작은 배치 크기나 배치 크기가 변동할 때.
순차 데이터 처리(RNN, Transformer) 및 자연어 처리에서 주로 사용.
배치 크기와 관계없이 일관된 학습 성능을 원할 때.
- ConvNeXt for Speech Modeling
- ConvNeXt를 이용한 음성 인코딩
: 2D Convolution -> 1D Convolution
-> 음성 모델링을 위해 시간 축에 따라 (7x7 커널) → (7x1 커널)로 변환
-> 트랜스포머 네트워크와 비교하여 효율적인 구조
