- RNNs VS Transformers
- 두 모델 모두 Sequence modeling에 사용됨
- 차이점: long-range dependencies(장기 의존성 처리) and parallelization(병렬 처리)
- RNN의 단점: Recurrent computation이 느림
- Introduction to Transformers
- Transformer: 주로 Attention에 기반한 특별한 신경망 구조, 더 고급스러운 feedforward 네트워크와 유사한 형태
- LLMs은 트랜스포머를 기반으로 구축됨
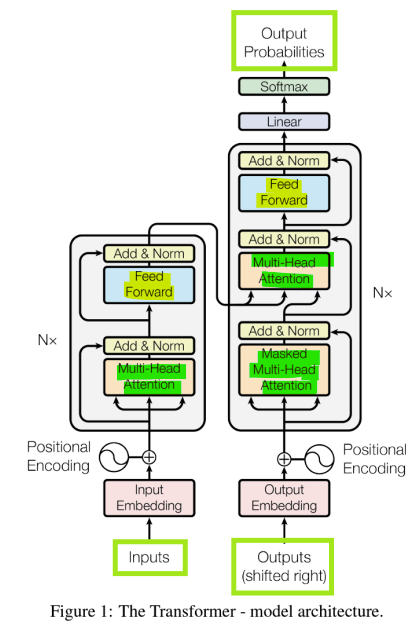
- Transformer Networks
- Feed-forward Neural Networks (no recurrent) + Attention Module
- Decoder
- Next token prediction (Inference, 추론)
input: Text Tokens Sequences [x_1: x_t-1]
output: Next Token x_t (토큰 하나)
-> 모델이 한 번에 한 토큰씩 예측해 나가는 과정. 이를 통해 새로운 텍스트를 생성함
- Parallel Token Prediction (Training)
Input: Text Tokens Sequences [x_1: x_t]
Output: Text Tokens Sequences [x_2: x_t+1] (토큰 시퀀스)
x_t+1: EOS Token (end of sequence)
-> 모델이 문장 전체를 보고, 각 위치에서 다음 올 토큰을 병렬로 예측하는 방식. 훈련 시에는 문장을 한 번에 입력하고 병렬로 예측 결과를 얻어 더 빠르게 학습할 수 있음
- Encoder
- Next Token Prediction (Inference)
Input: Text Tokens Sequences [x_1: x_t]
Output: Hidden Representation Sequences [h_1: h_t] - Parallel Token Prediction (Training)
Input: Text Tokens Sequences [x_1: x_t]
Output: Hidden Representation Sequences [h_1: h_t]
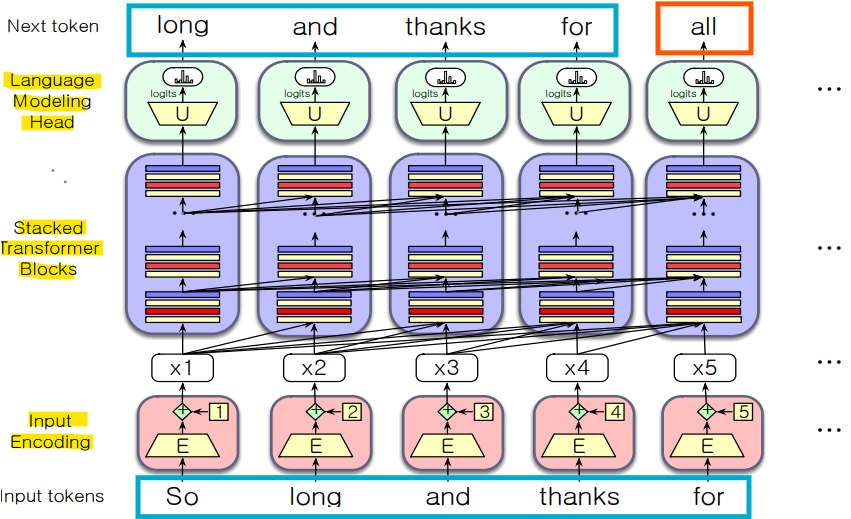
- Contextual Embedding
- Static Embedding: Word2Vec
- Contextual Embedding: 각 단어는 주변 단어에 따라 서로 다른 의미를 표현하는 서로 다른 벡터를 가짐
-> Attention으로 계산함
- Attention
- 단어의 Contextual Embedding은 모든 이웃 단어들로부터 정보를 선택적으로 통합하여 구축됨
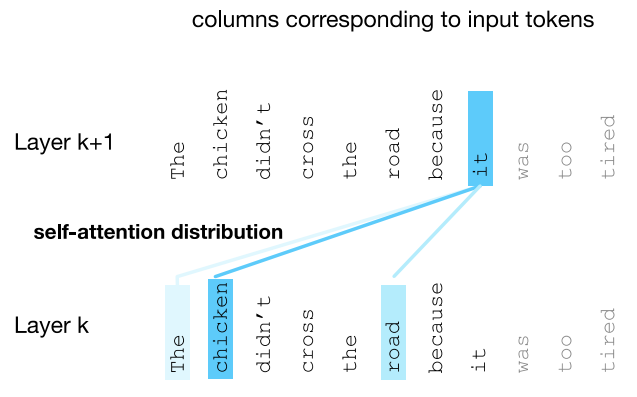
- 토큰의 임베딩을 계산할 때, 주변 토큰들(이전 레이어에 있는)로부터 선택적으로 주목하고 정보를 통합하여 도움을 주는 메커니즘.
- 벡터들의 가중 합(Weighted sum)을 수행하는 방법.
- 어텐션은 왼쪽에서 오른쪽으로 수행됨
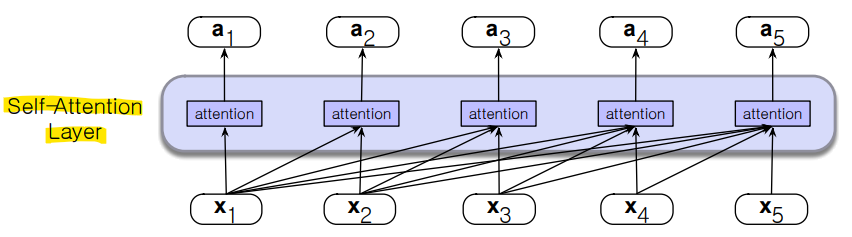
< Attention의 간단한 버전 >
: 현재 단어와의 유사성에 따라 가중된 이전 단어들의 합

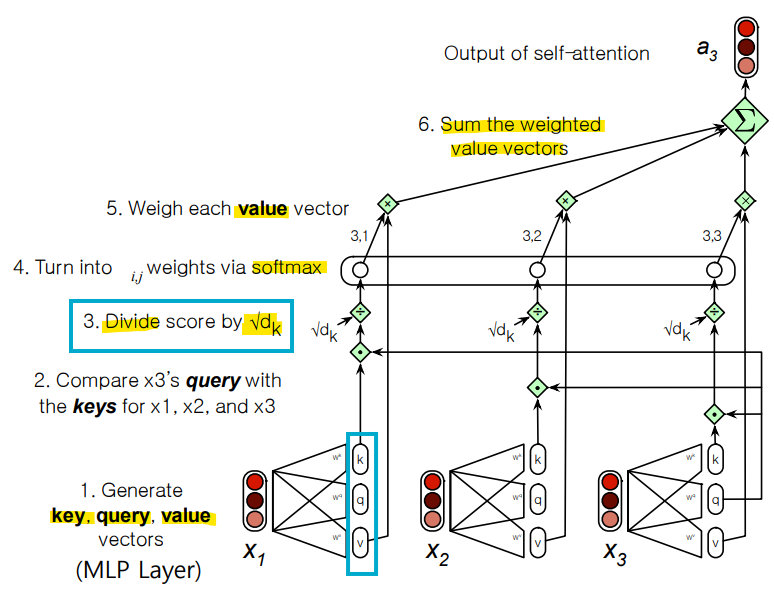
-> x1부터 xi까지의 토큰 임베딩을 현재 토큰 xi와의 유사도에 기반하여 가중합을 계산하는 것
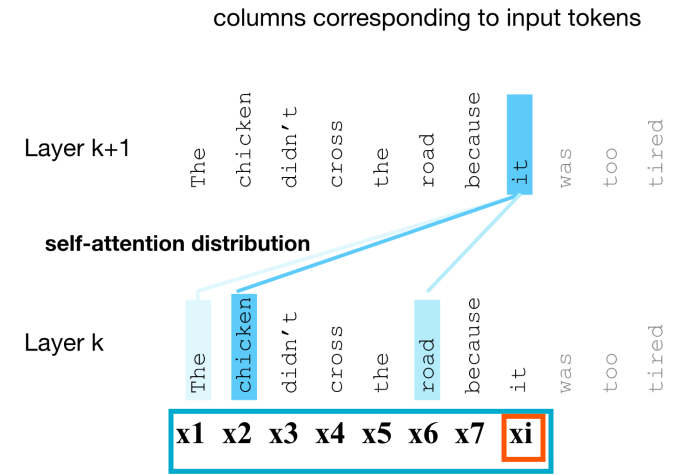
-> ai: xi와의 유사성에 따라 x1부터 x7(자기 자신인 xi까지 포함)까지의 가중합
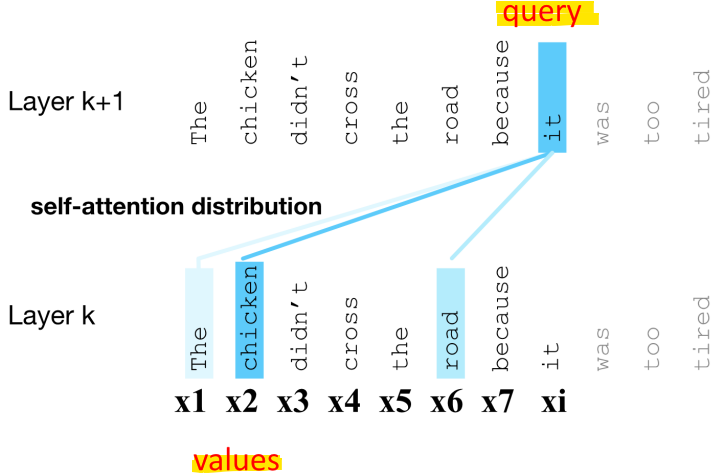
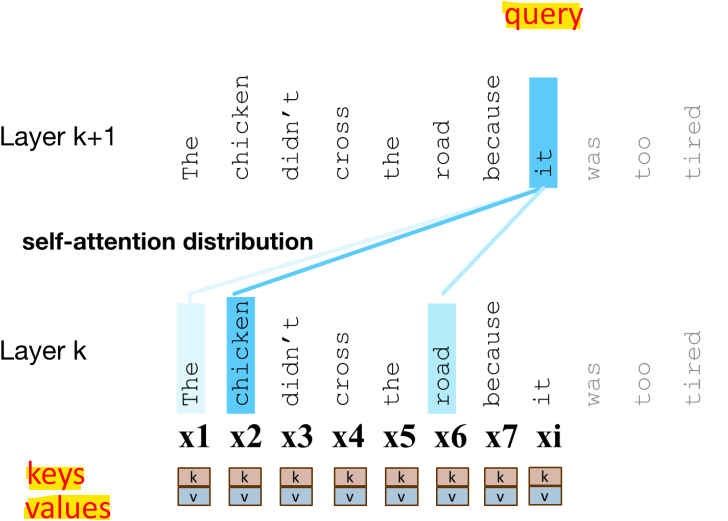
- 벡터(예: xi)를 직접 사용하는 대신, 각 벡터 xi가 수행하는 3가지 역할로 나누어 표현
* Query(Q): 현재 요소로서, 앞서 입력된 값들과 비교됨
* Key(K): 앞서 입력된 값으로서, 현재 요소와 비교되어 유사성을 판단하는 역할
* Value(V): 앞서 입력된 값 중에서 가중치가 적용되어 합산되는 값
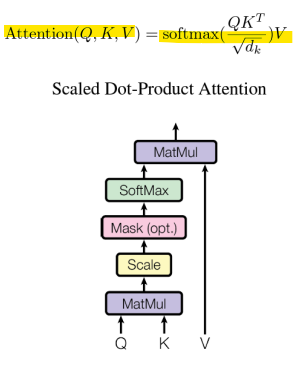
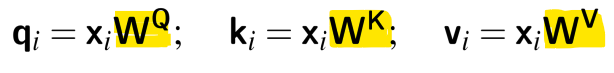
-> 현재 요소 xi와 이전 요소 xj의 유사성을 계산하기 위해 qi(Query)와 kj(Key) 사이의 내적(dot product)을 사용
-> xj를 합산하는 대신, vj(value)를 합산
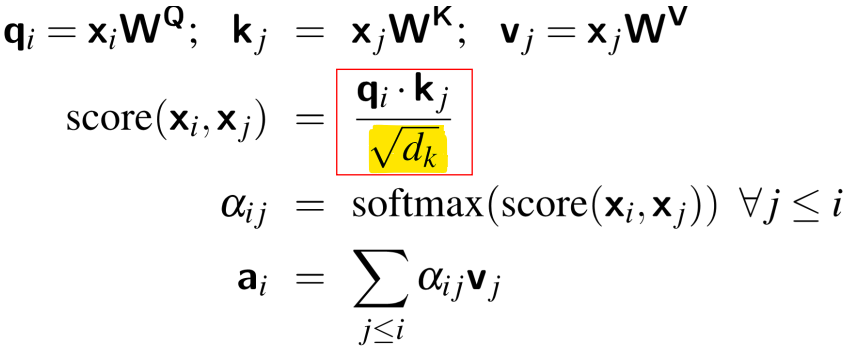
-> 내적의 결과가 양수or음수의 매우 큰 값(arbitrarily large value)이 될 수 있음
-> 이러한 큰 값을 지수 함수로 변환하면 학습 중에 수치적 문제와 기울기 소실이 발생할 수 있음
-> 문제 해결 방법: Scaling
내적(Score)을 Query와 Key vector의 차원 dk의 제곱근으로 나누는 방식으로 값을 조정하여 임베딩 크기와 관련된 요소로 내적 값을 스케일링함
<실제 Attention: Multi-Head Attention>
*Attention Head: 각 독립적인 가중합 계산 과정
- 하나의 Attention Head가 아닌 여러개의 Attention Head를 사용
- 각 Head는 서로 다른 목적을 위해 Context를 살펴볼 수 있음
- Context에서 서로 다른 언어적 관계나 패턴에 주목할 수 있음
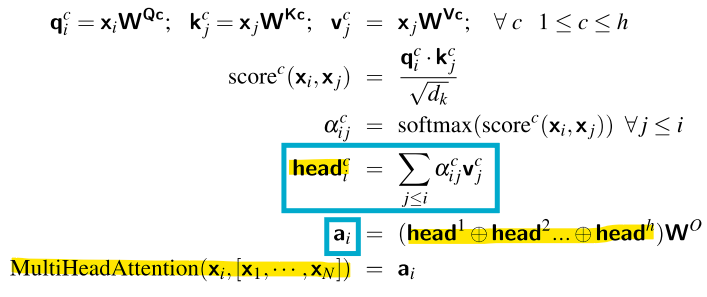
-> Head가 여러개로, 여러개의 독립적인 가중합을 계산함!
-> 여러 헤드에서 계산된 가중합(즉, 여러 어텐션 헤드의 결과)을 결합하여 최종 어텐션 출력
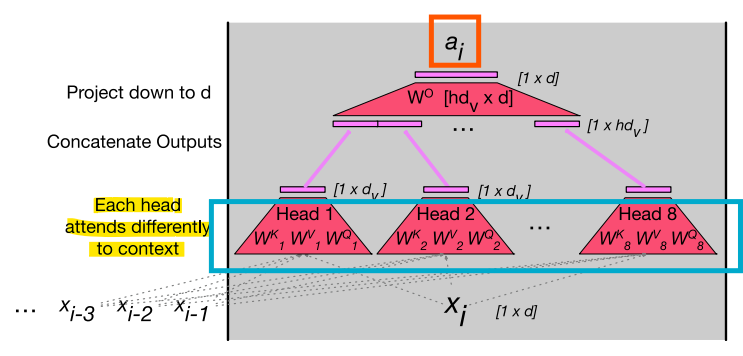
-> 각각의 Attention Head는 서로 다른 문맥적 정보를 처리함
- Attention for Contextual Embeddings
- Attention은 Contextual information을 통합하여 토큰의 표현을 풍부하게 만드는 방법
-> 각 단어의 embedding은 서로 다른 문맥에서 다르게 나타남
- 정보를 한 토큰에서 다른 토큰으로 이동시키는 방식
- Attention을 통해 얻은 Contextual Embeddings
: 단어가 그 Context 안에서 가지는 의미를 표현한 것
- Transformer Details
- Residual stream (잔차 스트림)
: 각 토큰은 상위로 전달되며 수정됨
: 모델이 각 토큰을 처리하는 동안 이전 층의 출력을 유지하면서 그 위에 새로운 정보를 더하는 방식
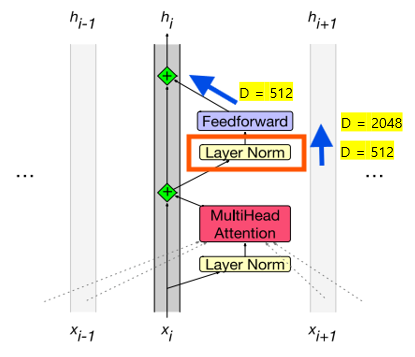
- "Prenorm" 아키텍처
: 현재 방식, Feedforward Layer 전에 Layer Norm이 적용됨
-> 잔차 연결에 포함된 정보가 모델의 변환을 거치기 전에 정규화하여 신호가 왜곡되지 않도록 하는 방법- "Postnorm" 아키텍처
: 예전 방식, Feedforward Layer 이후에 Layer Norm이 적용됨
-> 신호가 이미 처리된 후에 정규화하는 방식
< Feedforward Layer >
-> 비선형성(Non-linearilty)이 필요하므로, Feedforward layer가 필요함
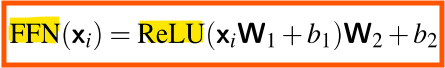
-
Feedforward Layer의 가중치
: 토큰 위치 i에 대해 동일하게 적용됨
: But, layer가 달라지면 가중치도 달라짐
-> 각 layer 에서 다른 방식으로 입력을 처리하고 학습함 -
Feedforward network의 은닉층 차원 dff는 종종 모델 차원 d보다 큼
-> 이는 네트워크가 더 많은 정보를 학습할 수 있도록 용량을 늘리는 방법
-> 모델의 차원 d = 512 -> 은닉층 차원 dff = 2048 -> 512
-> 더 복잡한 패턴을 학습할 수 있음
< Layer Norm >
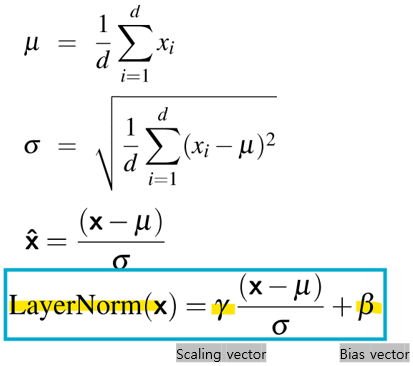
-
벡터 xi는 두 번 정규화됨
-
통계학에서 사용되는 z-스코어의 변형으로, 은닉층의 단일 벡터에 적용됨
- Skip Connection
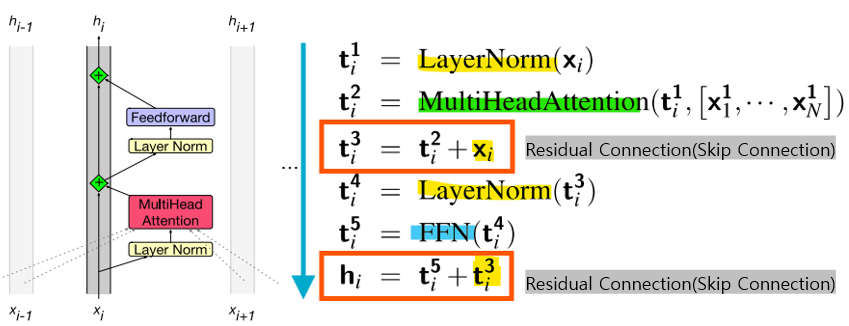
-> Skip Connection으로 attention 결과 t2에 원래 입력 xi를 더해줌(원래 정보 유지)
-> 최종 Skip connection: t5에 이전 단계의 t3를 더해줌
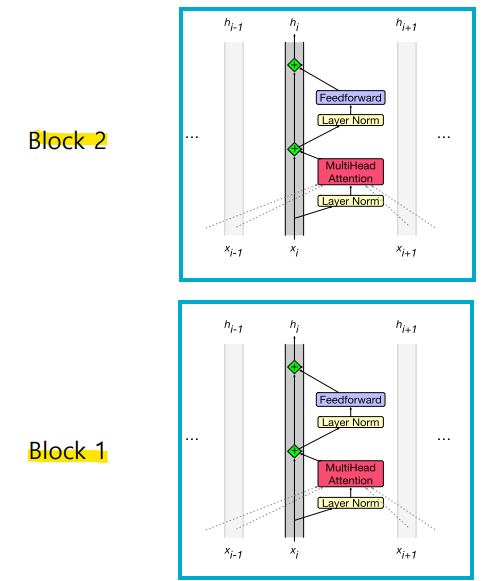
-> 트랜스포머는 이러한 블록들이 쌓인 구조로 이루어져있으며, 모든 벡터는 동일한 차원 d를 가짐
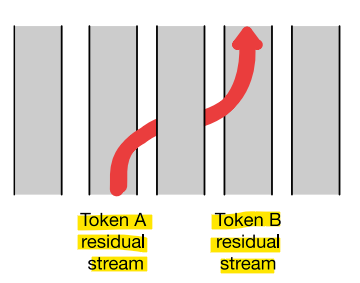
- Residual Stream은 개별 토큰의 정보 흐름을 유지하는 반면, Attention은 이웃한 토큰에서 정보를 가져와 정보를 이동시킴!
- 잔차 스트림(Residual Stream)
: 잔차 스트림은 각 토큰에 대해 정보가 흐르는 경로
트랜스포머 블록의 모든 부분은 하나의 잔차 스트림(1개의 토큰)에 적용
-> 한 토큰에 대한 정보는 그 토큰 내에서만 처리됨!- Attention은 다른 토큰들로부터 정보를 가져옴
-> 문맥을 고려- Attention Head
: 이웃한 토큰의 잔차 스트림에서 현재 스트림으로 정보를 이동시키는 과정-> 다른 토큰에서 중요한 정보를 현재 토큰으로 끌어와 더 나은 문맥 이해를 가능하게 함
-> 이를 통해 각 토큰은 자신의 주변 단어들과의 관계를 학습함
- Parallelizing Attention Computation
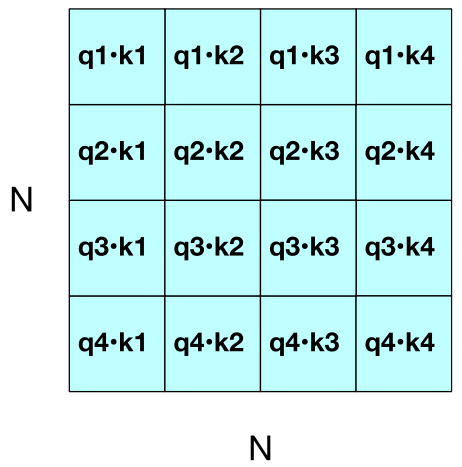
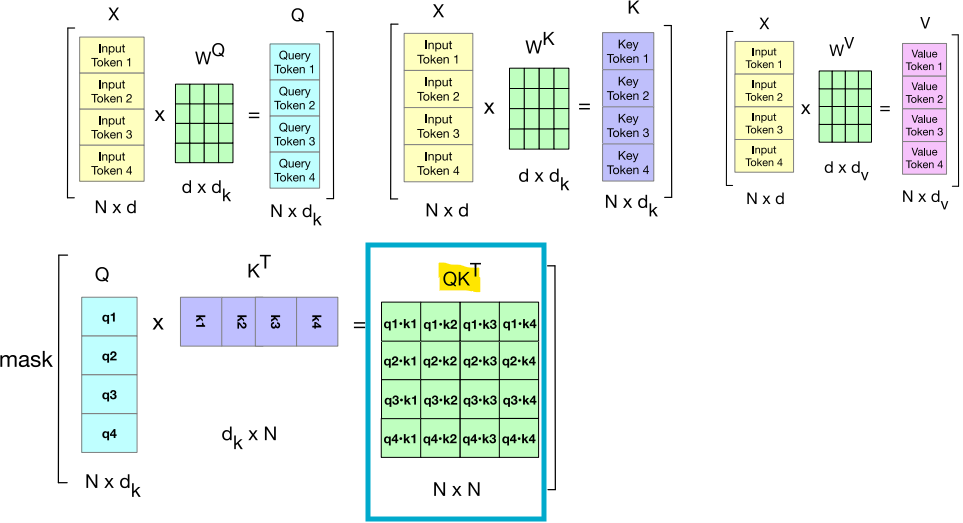
- 입력 시퀀스의 N개의 토큰을 하나의 행렬 X에 모두 넣을 수 있음(X의 크기는 [N x d]
- X의 각 행은 입력의 하나의 토큰에 대한 임베딩
- X는 임베딩 차원 d를 가진 1K~32K개의 행을 가질 수 있음
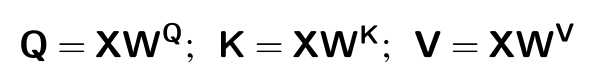
-
Q*KT
-
각 입력 토큰에 대한 Attention vector (A), N x d 크기의 행렬
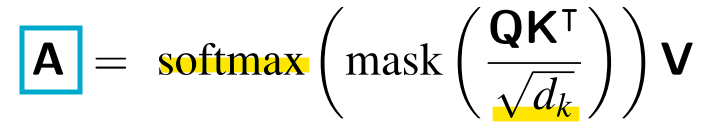
- Mask function
: 주로 트랜스포머(Transformer) 모델의 디코더(Decoder)에서 사용되는 기법으로, 미래 정보가 모델에 미리 노출되지 않도록 막는 역할
-> Q*KT는 각 쿼리와 모든 키(쿼리 이후의 미래 키도 포함하여)의 점수(score)를 가지고 있음
-> 마스킹 기법을 통해 모델은 현재 시점에서 아직 나오지 않은 단어를 추측해야 하는 상황을 학습함 (다음 단어를 알고 있으면 너무 쉬우니까)
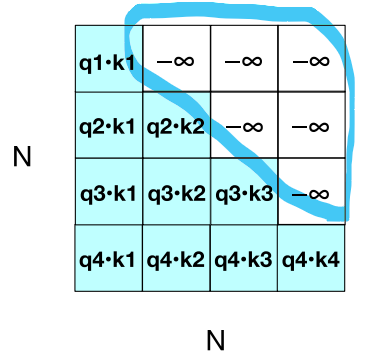
<Masking 과정>
- upper triangle에 해당하는 cell에 -무한대를 추가함
-> Softmax는 해당 값을 0으로 만듦 (미래를 마스킹함)
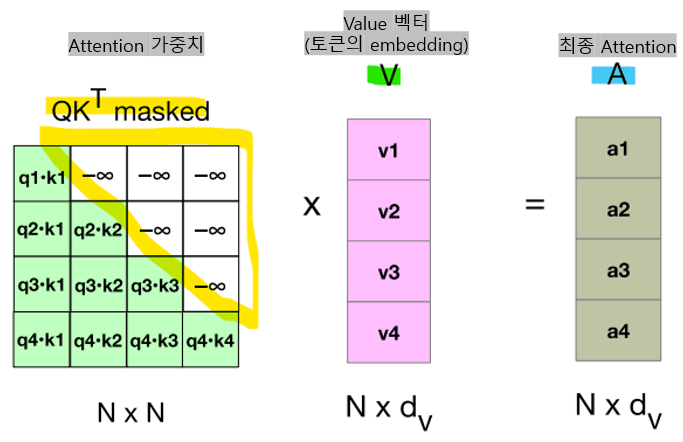
-> 최종 Attention A: 입력 토큰들 간의 관계를 고려하여 최종적으로 가중합된 정보(문맥적 정보를 반영한 벡터)
=> Forward process만을 사용하여 Attention 계산을 병렬화함
- Input and output: Position embeddings and the Language Model Head
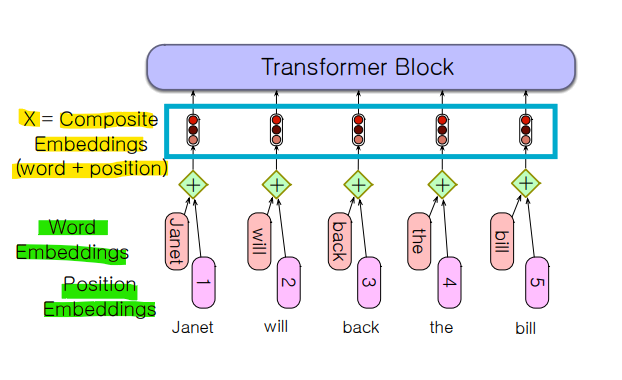
- 입력이 되는 행렬 X[N x d]는 문맥 내 각 단어에 대한 임베딩을 가짐
- 해당 임베딩 = 토큰 임베딩 + 위치 임베딩
- Input
- Token Embeddings
: 각 단어를 고정된 차원의 벡터로 변환하는 과정
- 임베딩 행렬 E의 크기는 [|V| x d]
-> |V|: 단어 개수
-> d: 임베딩 벡터의 차원
-> 각 단어는 d차원의 행 벡터로 나타남
ex) Fish = 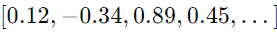
- Position Embeddings
: 각 단어의 위치 정보를 나타내는 행렬을 생성
-
위치 임베딩 행렬 Epos는 [1 x N]크기
-> N: 입력 시퀀스의 최대 길이 -
Absolute position embedding(절대 위치 임베딩): 각 단어가 문장 내에서 몇 번째에 위치하는지를 나타내는 방식
-> 처음에는 위치 임베딩이 임의로 초기화(절대 위치 임베딩)되며, 훈련 과정에서 학습을 통해 모델이 이 임베딩을 문맥에 맞게 더 나은 위치로 조정함
-> 위치 임베딩도 학습 가능한 파라미터
- Output
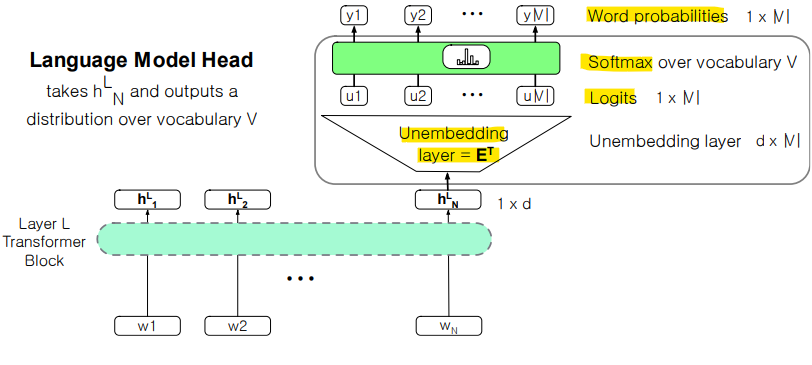
- Unembedding layer
- 선형 레이어가 hLN에서 logit vector(각 단어에 대한 선호도)로 투영함
-> Softmax는 logit을 vocabulary에 대한 확률로 변환함 [1 x |V|]
-> 가장 높은 확률의 단어가 최종 선택되어 출력됨
< Transformer Networks 전체 과정 >
- Input → Token Embeddings
- Add Positional Embedding
- Transformer
- Linear → Softmax
- Training, 훈련 시에는
: 마스킹을 사용한 병렬 계산- Inference, 실제 추론 시에는
: 자기회귀식(Autoregressive) 다음 단어 예측
-> 마스킹 없이!
- Large Language Models(LLM)
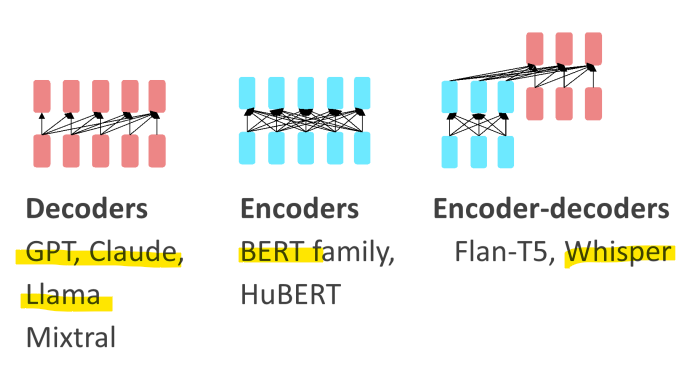
1) Encoder-only Transformer
- Masked Language Models(MLMs)
- BERT family
- 양쪽의 주변 단어들로부터 특정 단어를 예측하는 방식
- 주로 classification 작업을 위해 Finetuning됨
2) Encoder-Decoder Transformer
- 하나의 시퀀스를 다른 시퀀스로 매핑하도록 학습됨
-> Sequence-to-Sequence Model - 기계 번역(특정 언어를 다른 언어로 매핑), 음성 인식(음향을 단어로 매핑)에 사용됨
3) Decoder-only Transformer (=LLM)
- LLM
- 비록 사전 학습이 단어 예측에만 기반하더라도, 많은 유용한 언어 지식을 학습함(대량의 텍스트로 학습하기 때문)
- Decoder-only models
= Causal(인과적) LLMs
= Autoregressive(자기회귀적) LLMs
= Left-to-right LLMs
-> 좌에서 우로 단어를 예측
-> 입력된 텍스트를 기반으로 다음 단어를 순차적으로 예측
- Conditional Generation(조건부 생성)
: 이전 텍스트를 조건으로 하여 텍스트를 생성함
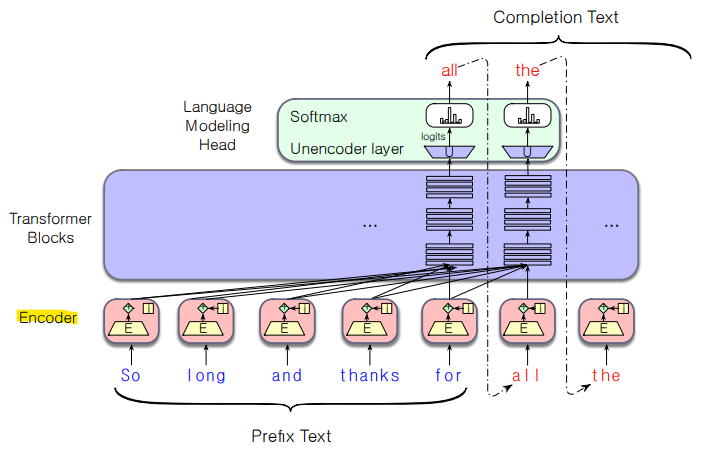
- 많은 실제 NLP 작업은 단어 예측 문제로 변환할 수 있음
ex) 감정 분석(Sentiment analysis): “I like Jackie Chan”
이 문장을 언어 모델에 입력:
The sentiment of the sentence "I like Jackie Chan" is:
그리고 모델이 다음에 어떤 단어를 예측하는지 확인

- 많은 작업을 conditional generation으로 Framing하기

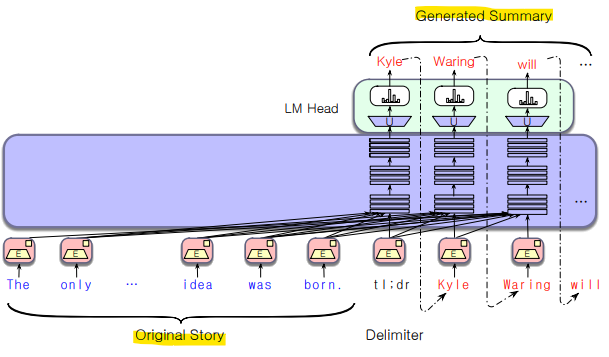
- Decoding
: 모델의 확률을 기반으로 단어를 선택하여 생성하는 작업
- LLM에서 가장 일반적인 decoding 방법: Sampling
- 모델의 단어 분포에서 sampling하는 방법
: 모델이 할당한 확률에 따라 무작위로 단어를 선택 - 각 토큰 이후에, 이전 선택에 따라 조건부로 단어의 확률을 바탕으로 sampling함
: 트랜스포머 언어 모델이 해당 단어의 확률을 제공함
-> 모델은 각 단어에 대해 확률을 부여하며, 확률이 높은 단어는 선택될 가능성이 높아짐. But 무작위성 때문에 확률이 낮은 단어도 선택될 가능성은 존재함
- Sampling method for Next Token
-
word sampling의 고려 요소: quality and diversity(다양성)
-
높은 확률의 단어 강조 시
-> 품질 상승: 더 정확, 더 일관성(coherent), 사실적
-> 다양성 감소: 지루하고, 반복적 -
중간 확률의 단어 강조 시
-> 품질 저하: 덜 사실적, 일관성 떨어짐(incoherent)
-> 다양성 증가: 더 창의적, 다양한 결과
1) Top-k sampling
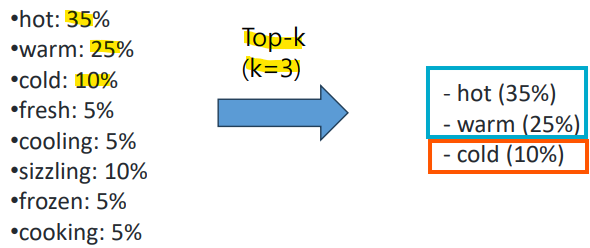
1) 선택할 단어의 수 k를 정함
2) vocabulary V에 있는 각 단어에 대해, 언어 모델을 사용하여 주어진 문맥에서 이 단어의 가능성 p를 계산
3) 단어들을 가능성 순으로 정렬하고, 가장 가능성이 높은 상위 k개의 단어만 남김
4) 남은 k개의 단어들의 점수를 다시 정규화하여 합이 1이 되는 확률 분포로 만듦
5) 이 상위 k개의 가장 가능성 높은 단어들 중에서, 각 단어의 확률에 따라 무작위로 하나의 단어를 sampling
-> 문제점: k는 고정되어 있기에 상황에 따라 매우 다른 확률 질량을 포함할 수 있음
2) Top-p sampling
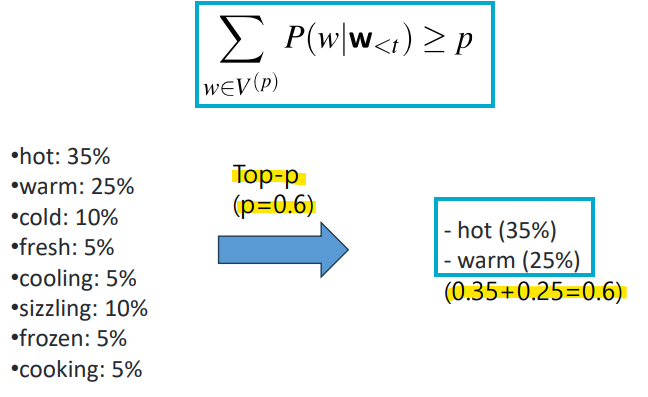
: 상위 p% 의 확률 질량만 유지함
: 위 조건을 만족하는 가장 작은 단어 집합
3) Temperature sampling
: 분포를 자르는 대신 재구성함
: 열역학으로부터 아이디어
-> 높은 온도에서 시스템은 유연, 다양한 상태 탐색 가능
-> 낮은 온도에서 시스템은 더 나은 상태만 탐색할 가능성 높음
- 낮은 온도 샘플링(τ ≤ 1)에서는 부드럽게
-> 가장 확률이 높은 단어들의 확률을 증가시키고
-> 드문 단어들의 확률을 감소시킴
- softmax에 통과시키기 전에 logit을 온도 매개변수 τ로 나눔
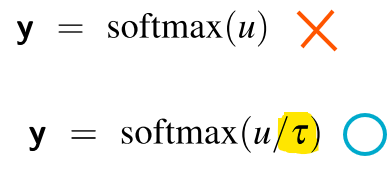
- (τ는 0~1 사이의 값)
- τ가 1에 가까울수록:
분포는 거의 변하지 않아서, 원래 모델이 계산한 확률대로 단어를 선택- τ가 낮을수록:
소프트맥스로 넘어가는 입력값이 커지기 때문에, 소프트맥스는 높은 값을 1에 가깝게, 낮은 값을 0에 가깝게 만듦
즉, 확률이 높은 단어는 더 확실하게 높아지고, 확률이 낮은 단어는 거의 선택되지 않게 함(Greedy)- τ가 0에 가까워질수록:
가장 확률이 높은 단어의 확률이 거의 1에 가까워지기 때문에, 가장 가능성 높은 단어만 선택됨
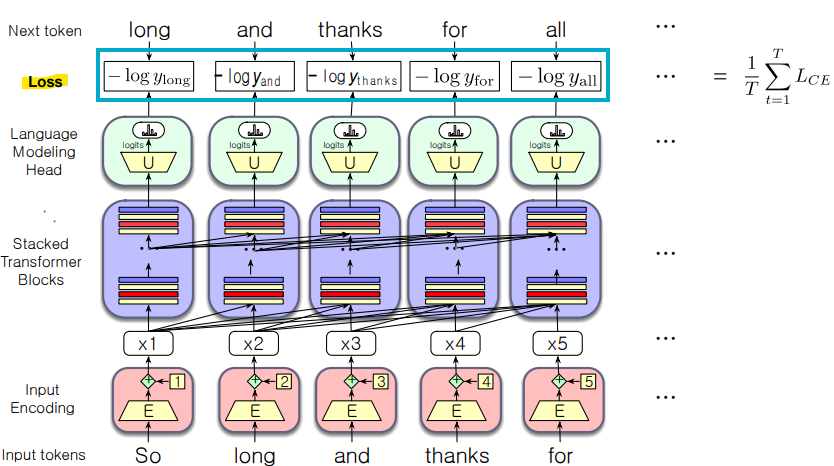
- Training LLM
- Cross Entrophy Loss을 사용한 트랜스포머 언어 모델 학습
- Tokenization
1) Word-based Tokenization
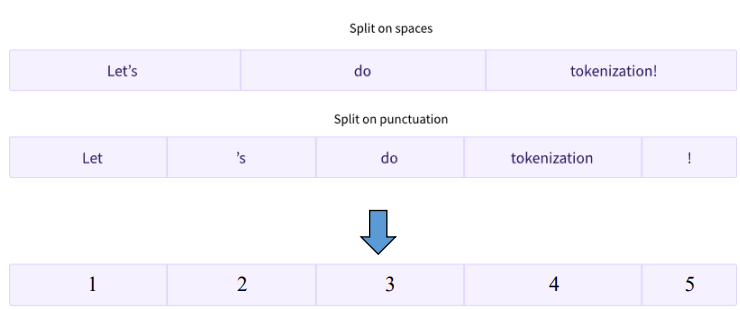
: 텍스트를 개별 단어로 분리하여 각 단어를 별도의 단위로 처리하는 과정
<장점>
- 개별 단어의 의미를 보존 + 텍스트 처리 작업에서 직관적, 간단
<단점>
- 어휘집에 없는 단어들과 단어 형태의 변화를 처리하는 데 어려움이 있으며, 큰 어휘집 크기와 희귀 단어 처리의 한계가 있음
2) Character-based Tokenization

: 텍스트를 개별 문자로 분리하여, 각 문자를 고유한 토큰으로 취급
<장점>
- 어휘집에 없는 단어도 효과적으로 처리 + 문자를 조합하여 어떤 단어도 생성 가능
<단점>
- 더 긴 시퀀스를 생성하며, 단어 수준에서의 의미를 잃을 수 있어 모델의 복잡성이 증가할 수 있음
3) Subword Tokenization

: 단어를 의미있는 subword 단위로 분리하여, 단어 기반과 문자 기반 접근 사이의 균형을 맞춤
<장점>
- 어휘집에 없는 단어를 효율적으로 처리 + 어휘 크기 적절하게 유지 + 빈번한 단어와 의미있는 subword 단어를 모두 포착
<단점>
- 최적의 subword 단위를 결정하는 데 복잡성이 있음 + 매우 희귀한 단어나 특이한 텍스트 형식에서는 어려움
-> 이러한 제한점은 대규모 corpus를 사용하여 해결 가능
- Corpus: 언어 모델 학습을 위해 사용되는 대규모 텍스트 데이터 모음
- LLM Training
- Pretraining
- 언어 모델의 놀라운 성능의 기본 개념
: 먼저 Transformer 모델을 엄청난 양의 텍스트로 사전 학습 후, 이를 새로운 작업에 적용함
- Self-supervised training algorithm
- 모델을 단순히 다음 단어를 예측하도록 훈련
-> 텍스트 corpus를 사용하여 매 시점 t에서 모델에게 다음 단어를 예측하도록 요청
-> 이 예측에서 발생하는 오류를 최소화하기 위해 gradient descent를 사용해 모델을 훈련 - 다음 단어를 label로 사용하기 때문에 "self-supervised"
- 같은 손실 함수: Cross-Entropy Loss
-> 모델이 실제 단어 w에 높은 확률을 할당하도록 하고 싶음
-> 즉, 모델이 w에 너무 낮은 확률을 할당하면, 손실이 커져야 함
- CE 손실: 모델이 실제 다음 단어 w에 할당한 음의 log 확률
-> 모델이 w에 너무 낮은 확률을 할당하면 모델의 가중치를 w에 더 높은 확률을 할당하는 방향으로 조정
- CE 손실: 정확한 확률 분포와 예측된 분포 간의 차이
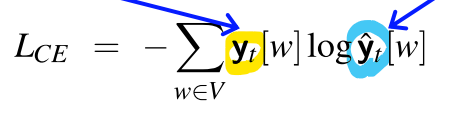
- 정확한 분포 yt는 다음 단어를 알고 있기 때문에, 실제 다음 단어에 대해서는 1이고, 다른 단어에 대해서는 0
- 따라서 이 합(sum)에서, 하나를 제외한 모든 항은 0이 되며, 남는 항은 모델이 실제 다음 단어에 할당한 logp임
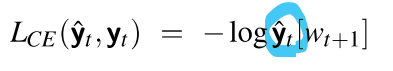
- Teacher Forcing Training
: 학습 중에 모델이 잘못된 예측을 하더라도, 그 예측을 사용하지 않고 정답 단어를 제공하여 모델이 다음 단어를 더 정확하게 예측할 수 있게 함
: 정답을 기반으로 다음 단어를 계속 예측하기 때문에, 모델이 더 빠르게 학습
<한계점>
-
추론 시 다르게 동작: 실제 추론 단계에서는 Teacher Forcing을 사용할 수 없기 때문에, 모델이 학습 중 경험하지 못한 잘못된 예측을 기반으로 문장을 생성할 때 어려움 (학습과 추론의 불일치)
-
각 토큰 위치 t에서, 모델은 정답 토큰 w1:t를 봄
-> 다음 토큰 wt+1에 대한 손실(-로그 확률)을 계산 -
다음 토큰 위치 t+1에서는 모델이 wt+1에 대해 예측한 것을 무시함
-> 대신, 정답 토큰 wt+1를 문맥에 추가하고, 다음 단계로 넘어감
- Scaling Laws
: power laws: 모델 성능(손실)이 모델 크기, 데이터 양, 연산량의 증가에 따라 비례적으로 향상되지 않음 -> 성능 향상률이 점점 줄어듦
<LLM 성능의 의존 요소>
- 모델 크기: 임베딩을 제외한 파라미터 수
- 데이터셋 크기: 훈련 데이터의 양
- 연산량(Compute): 연산량(FLOPS 등)
-> 위 3가지 요소들을 증가시킬수록 성능은 향상되지만, 일정 수준 이상부터는 성능 향상이 점점 느려짐(성능이 power law에 따라 증가하기 때문)
-> Scaling laws를 사용하여 학습 초기 단계에서 더 많은 데이터를 추가하거나 모델 크기를 증가시켰을 때 손실이 어떻게 변할지 예측할 수 있음
-> 모델 성능을 개선하려면 파라미터 수(더 많은 레이어, 더 넓은 문맥), 더 많은 데이터, 또는 더 많은 학습 반복을 추가할 수 있음
- 손실 L은 파라미터 수 N, 데이터셋 크기 D, 연산량 C의 함수로 표현됨
- 나머지 두 요소가 고정되어 있을 때, 하나의 요소가 증가하면 손실이 특정 패턴에 따라 감소함
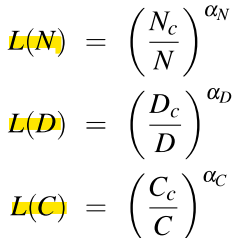
- LLM Fine-tuning
-
pretraining에서 보지 못한 새로운 도메인에 적응하기 위한 Fine tuning
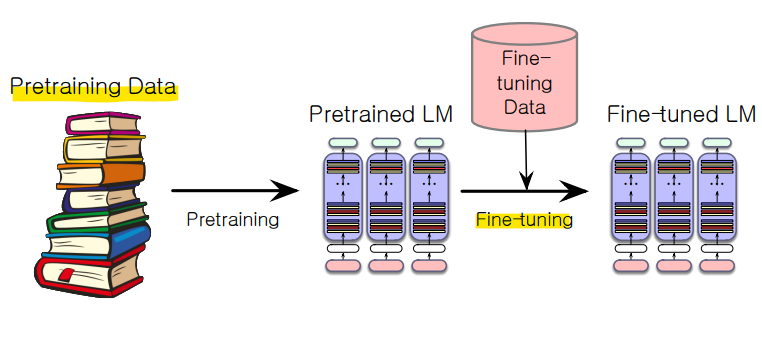
-
계속된 pretraining(finetuning)을 통한 새로운 도메인 적응은 대형 LLM에서 문제가 됨
-> 훈련해야 할 엄청난 수의 파라미터
-> 배치 경사 하강법의 각 패스에서 매우 많은 거대한 레이어를 통해 역전파를 해야함
-> 처리 능력, 메모리, 시간 면에서 비용이 많이 듦
-> 해결방법: PEFT
- Parameter-Efficient Finetuning (PEFT)
- 파인튜닝 시 업데이트할 파라미터의 일부만 효율적으로 선택
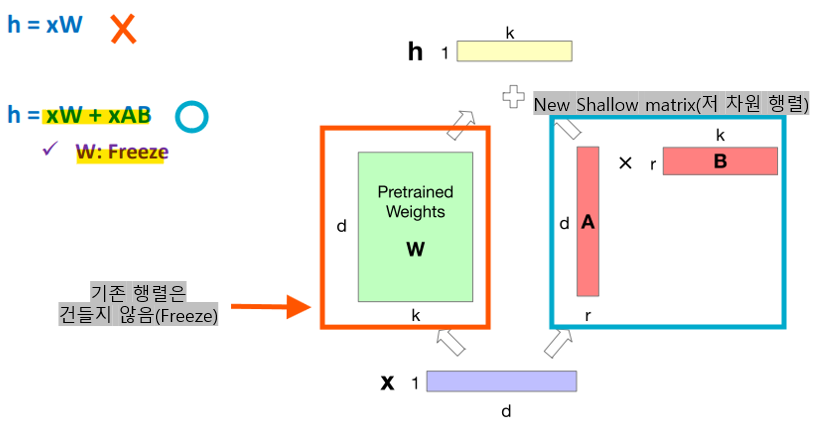
-> 일부 파라미터를 freeze하여 변경하지 않고, 일부 소수 파라미터만 업데이트-> LoRA (Low-Rank Adaptation)
- 트랜스포머 모델은 많은 dense matrix 곱셈 레이어를 가지고 있음
ex) Attention에서의 WQ, WK, WV, WO 레이어- 파인튜닝 시 이 레이어들을 업데이트하는 대신,
-> 레이어를 동결하고, 더 적은 파라미터로 Low-rank approximation(저차원 근사)을 업데이트함
-> 원래의 파라미터 W는 동결하고, 대신 A와 B라는 저차원 행렬을 추가로 학습시켜서 파라미터 업데이트를 효율적으로 줄이는 방법
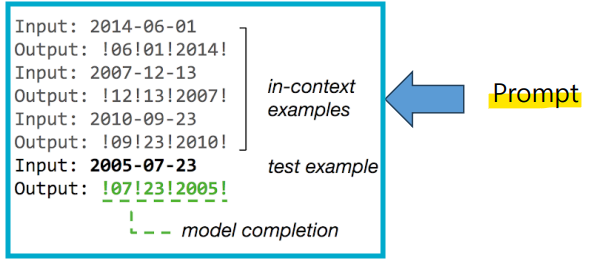
- In-context Learning (ICL)
: 과제 시연을 자연어 형식으로 프롬프트에 통합하는 기술
-> pretraining된 LLM이 모델을 파인튜닝하지 않고도 새로운 작업을 처리할 수 있게 함
-> 대규모 데이터로 사전 학습된 모델일수록 In-context learning의 성능이 더 좋아짐- Prompt
: 모델의 사고 과정과 이후 출력을 이끄는 의미적 선행 정보(Semantic prior)
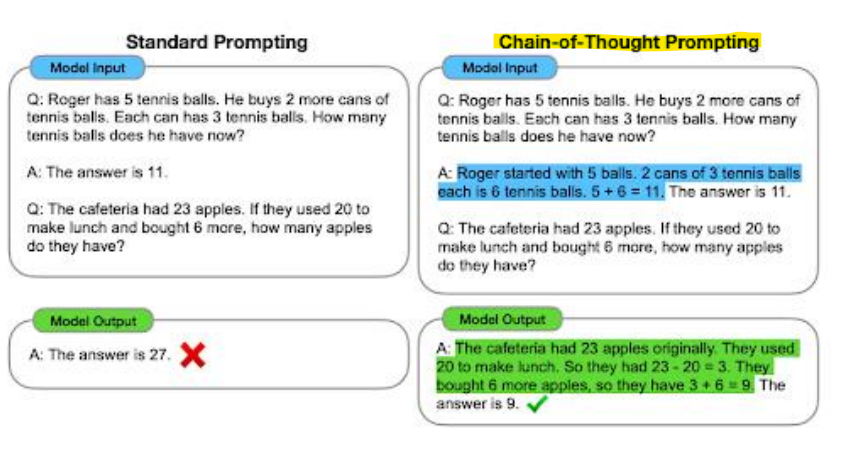
- Chain-of-Thought (CoT) Prompting
: 프롬프트에 중간 추론 과정(intermediate reasoning steps)을 포함시켜 LLM의 추론 능력을 향상시키는 기술
-> 특히 복잡한 추론 작업에서 few-show 프롬프트(모델이 수행해야 할 작업을 몇 가지 사례를 통해 보여주고, 그 사례를 기반으로 새로운 입력에 대한 결과를 생성하도록 유도)와 결합될 때 효과적
- 최근 Transformer Architecture
-
Positional Embedding
: 절대 위치 임베딩(Absolute Position Embedding) → 상대 위치 임베딩(Relative Position Embeddings, RoPE) -
Layer Norm
: Layer Norm(LN) → Root Mean Square (RMS) Norm
