- Automatic Speech Recognition (ASR)
- 자동 음성 인식: 음성을 텍스트로 변환
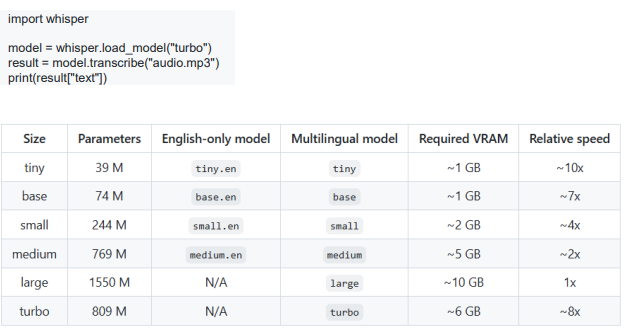
- Whisper [OpenAI, ASR model]
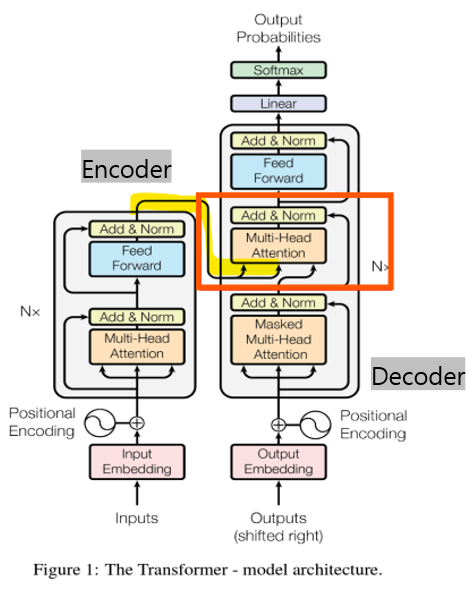
- 아키텍처: Encoder-decoder Transformer
- Encoder-Decoder Transformer는 Sequence-to-sequence 학습이 필요한 작업에서 주로 사용됨
-
기계 번역
: 인코더는 소스 언어를 처리, 디코더는 타겟 언어로 번역을 생성 -
텍스트 요약
: 모델은 입력 텍스트를 인코딩하고, 이를 요약된 형태로 디코딩하여 큰 텍스트를 짧고 일관성 있는 요약으로 변환 -
음성 인식 및 합성
: 자동 음성 인식(ASR) 또는 음성 합성(TTS) 작업에서, 모델은 오디오 신호를 인코딩하고 이를 텍스트로 디코딩함 -
이미지 캡셔닝
: 인코더는 이미지의 특징을 처리, 디코더는 해당 이미지를 설명하는 캡션을 생성
- Encoder-Decoder Transformer
- Cross-Attention
: 두 개의 다른 입력 시퀀스(소스 시퀀스/타겟 시퀀스) 사이에서 정보를 상호 교환하는 방식
- Q (쿼리): 디코더에서 생성 중인 타겟 시퀀스의 정보를 바탕으로 쿼리 벡터를 만듦
- K (키)와 V (값): 소스 시퀀스에서 생성된 정보를 바탕으로 인코더가 제공하는 키와 값 벡터
- 교차 어텐션은 타겟 시퀀스를 생성할 때, 쿼리(Q)를 바탕으로 소스 시퀀스에서 키(K)와 값(V)를 활용하여, 어느 부분이 중요한지 판단함
-> K와 V는 인코더가 처리한 소스 시퀀스의 특징을 나타내며, 소스 문장의 여러 부분에 대한 정보를 담고 있음
-> Q는 현재 디코더가 생성 중인 타겟 문장의 특정 단어에 대한 정보=> 디코더는 Cross-Attention을 통해 타겟 문장의 각 단어를 생성할 때 소스 문장의 특정 부분에 집중함
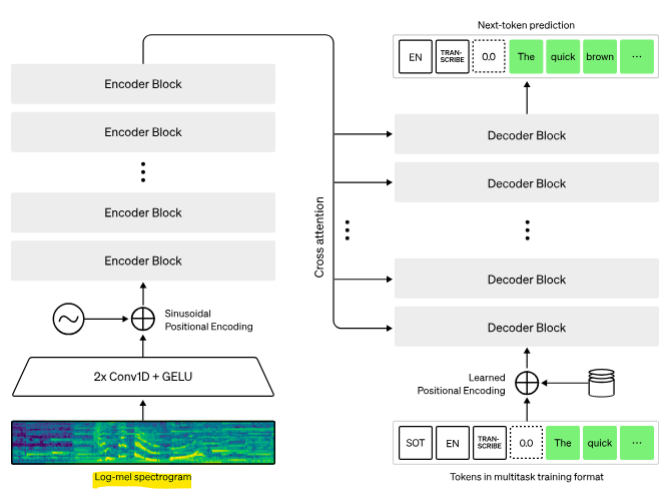
- Whisper [OpenAI, ASR model]
- 인코더(Encoder): 음성을 인코딩
- 디코더(Decoder): 텍스트 토큰을 예측
-> 사용이 쉬움
-> 다국어 자동 음성 인식을 지원
-> 680,000시간의 데이터를 사용하여 모델을 학습
- Speech Synthesis
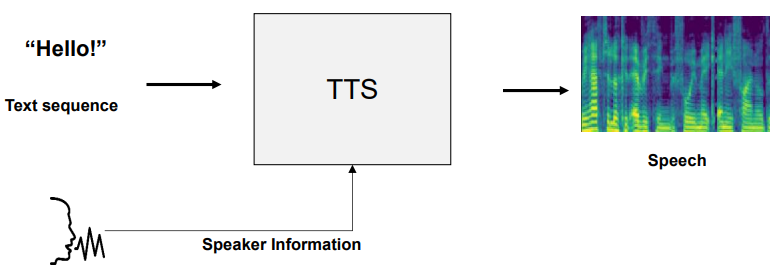
Transformer TTS
- 인코더(Encoder): 텍스트를 인코딩
- 디코더(Decoder): 다음 Mel-spectrogram과 Stop 토큰을 예측
-> Mel-spectrogram: 음성의 음향적 특징
-> Stop 토큰: 음성 생성의 끝을 알리는 토큰으로, 모델이 오디오 출력을 중지해야 할 시점을 나타냄 (EOS 토큰 대신 사용됨)
- Self-supervised Pre-training with Transformers
- Self-supervised Learning (SSL)
- 인간이 제공하는 external label에 의존하지 않고, 데이터 자체에서 감독 신호를 생성하여 모델을 학습시키는 머신러닝 패러다임
- 데이터 내의 핵심 특징이나 관계를 파악하도록 설계
- Encoder-only Transformer
- 양방향 Encoder-only transformer 모델은 주로 자기 지도 학습에 사용됨
-> BERT(Bidirectional Encoder Representations from Transformers)
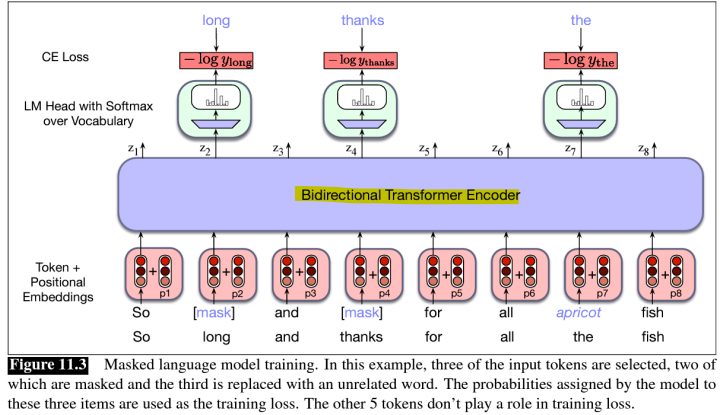
- Masked Language Models (MLM)
- MLM은 대규모 corpus의 주석 없는 텍스트를 사용함
- 입력 토큰 중 일부가 무작위로 [mask] 토큰으로 대체됨
- MLM의 훈련 목표는 양방향 인코더를 사용하여 마스킹된 각 토큰의 원래 입력을 예측하는 것
-> Cross-entropy loss
- Pre-trained MLM은 입력의 각 토큰에 대해 유용한 Contextual embeddings을 추출할 수 있음
-> Hidden representation(contextual embeddings or self-supervised representation)은 문맥적 정보를 포함하고 있음
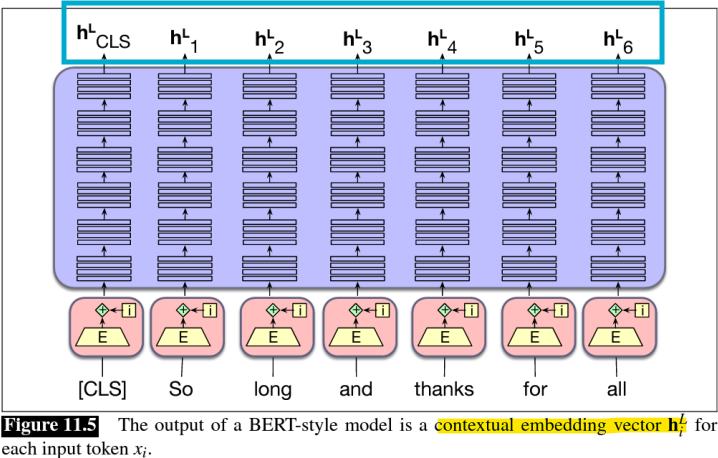
- BERT는 모든 층에서 왼쪽과 오른쪽 문맥을 동시에 고려하여, 주석이 없는 텍스트로부터 deep bidirectional representation을 사전 학습하도록 설계됨(Masked Language Modeling(MLM) 방식으로 학습)
- 그 결과, 사전 학습된 BERT 모델은 추가 출력 레이어 하나만으로 다양한 작업에 대해 최첨단 성능의 모델로 파인튜닝할 수 있음
-> 질문 응답 및 언어 추론과 같은 작업에서, 별도의 작업별 아키텍처 수정 없이 가능함
- Wav2Vec 2.0
: 대체 손실 함수로 Contrastive Loss(대조 손실)을 사용한 마스킹 언어 모델 (Cross-entropy 손실 대신)
-> 100배 적은 레이블된 데이터를 사용하면서도, 100시간 데이터 하위셋에서 이전 최첨단 성능을 능가
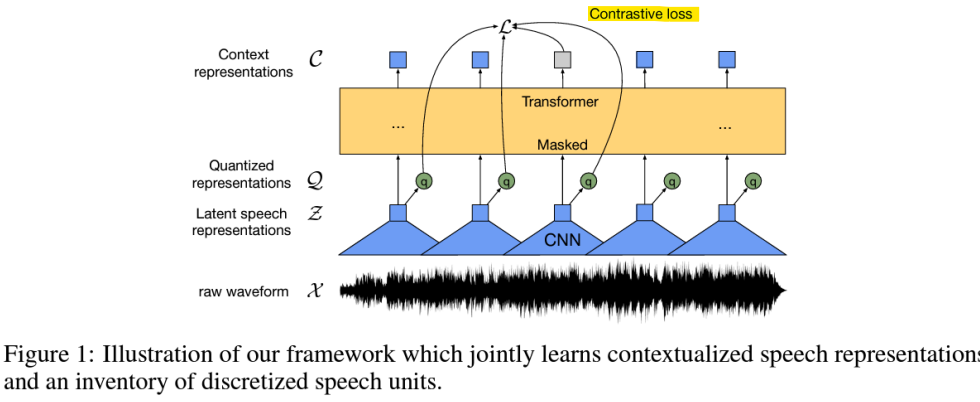
- HuBERT (Hidden-Unit BERT)
: 자기 지도 학습(self-supervised learning) 방식을 사용하여 음성 신호에서 숨겨진 유닛(hidden units)을 학습하는 음성 모델
: 텍스트 레이블 없이 대규모 음성 데이터에서 중요한 특징을 학습
-> 특히 음성 인식과 음성 합성
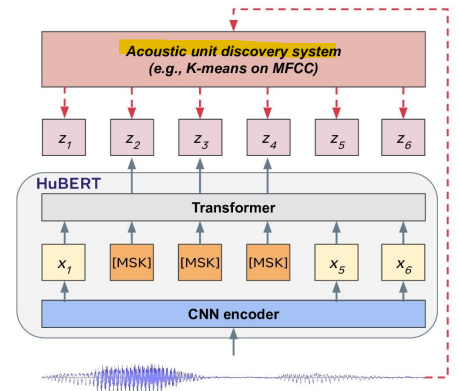
- Discretization of Speech
: 음성 데이터를 연속적인 신호에서 이산적인 토큰으로 변환하는 과정
-> 이 방법은 주로 self-supervised learning과 K-means 클러스터링을 통해 음성 데이터를 처리하고, 그 결과를 언어 모델에서 사용할 수 있는 토큰으로 변환함
1. 마스킹되지 않은 음성 입력을 의미 있는 연속적 잠재 표현으로 인코딩 (컨볼루션 레이어 사용)
2. K-means 알고리즘을 통해 학습된 표현의 장기적인 시간적 관계를 포착하기 위해 이산적 목표를 예측- 음성 → 이산적 단위(Discrete Units)
-> 이산적 음성 단위를 기존 언어 모델의 토큰으로 사용할 수 있음
: 원래의 음성 데이터를 모델에 입력하면, 모델은 이를 연속적인 벡터로 변환한 후, K-means를 통해 이 벡터를 이산적 토큰으로 변환함
=> 이산적 토큰들은 음성 데이터의 특정 패턴을 요약한 정보로, 언어 모델에서 이를 사용하여 텍스트 처리처럼 음성 데이터를 다룰 수 있음
ex) 음성 인식, 음성 합성, 음성 기반 대화 시스템
-> 음성 신호가 이산적 토큰으로 변환되면, 언어 모델은 이를 입력으로 받아 텍스트로 변환하는 작업을 수행
- Language Model for Generative Models
- 이미지 Tokenization
- 언어 모델이 이미지 토큰을 예측
- Audio codec
: 오디오 Encoder/Decoder: 디지털 오디오 신호를 압축(토큰화)하고 압축 해제하는 소프트웨어
ex) MP3, Windows Media Audio(WMA), 돌비 디지털, DTS는 디지털 오디오를 압축하고 해제함
- 오디오 코덱은 하드웨어 회로일 수 있음
- 인코딩(Encoding): 원본 오디오 신호를 수치적으로 분석하여 토큰이나 압축된 표현으로 변환
-> 이 과정에서 신호의 중요 요소를 남기고, 불필요한 정보를 제거하여 데이터 크기를 줄임- 디코딩(Decoding): 압축된 데이터를 다시 원본에 가깝게 복원하는 과정
- SoundStream [TASLP, 2021]
- 목표: 음성, 음악 및 일반 오디오를 효율적으로 압축하는 것
-> Codec + neural vocoder(신경 보코더)를 결합
-> Vector quantization(벡터 양자화)
-> Adversarial training(적대적 학습), (고품질 파형 생성을 위해)
- Vector Quantization (VQ), 벡터 양자화
: 샘플들을 유사한 그룹으로 분류하는 작업(K-means와 비슷)
- 고전적 방법: 각 환경에서 대표적인 소리를 나타내는 템플릿 벡터를 선택
- 소리를 분류하려면, 해당 녹음과 가장 가까운 템플릿 벡터를 찾음
- Residual Vector Quantization (RVQ)
- 여러 단계의 vector quantizer를 Nq 층으로 연쇄적으로 연결한 구조
- vector quantizer: 입력 벡터를 가장 가까운 템플릿 벡터(코드북에서 선택된 벡터)로 변환
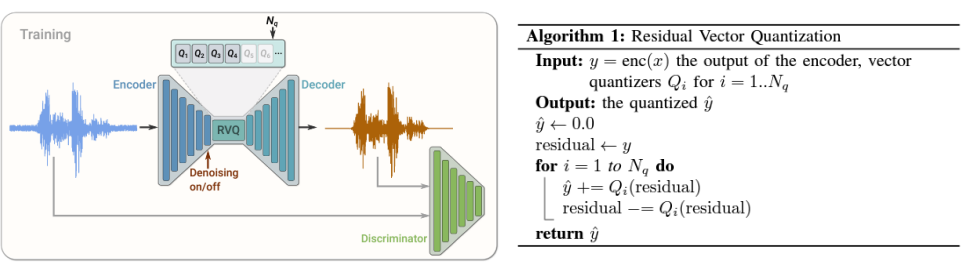
1) 양자화되지 않은 입력 벡터가 첫 번째 quantizer를 통과
2) Residual을 계산 (양자화된 벡터와 원래 입력 벡터 사이의 차이)
Residual = Residual(입력 벡터) - Qi(양자화된 벡터)
3) 잔차는 추가적인 quantizer들의 시퀀스에 의해 반복적으로 양자화됨
-> 추가적인 양자화기들이 첫 번째 양자화기에서 남은 오류를 더 세밀하게 보완해줌
-> 이 과정이 여러 단계(다층)로 반복되며, 각 단계는 이전 단계에서 남은 잔차를 점진적으로 양자화
- EnCodec [TMLR, 2023]
: 신경망 기반 오디오 코덱(Neural Audio Codec)으로, 음성, 음악, 그리고 기타 오디오 데이터를 실시간으로 효율적으로 압축하고 고품질로 복원하는 기술
- 목표: 고품질의 오디오 샘플을 실시간으로 생성할 수 있는 neural audio compression model
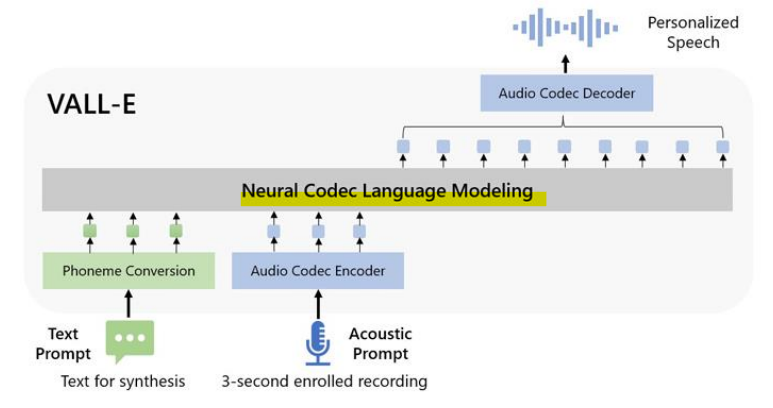
- Neural Codec Language Models
- 목표: In-context learning을 위한 신경망 코덱 언어 모델
- 신경망 코덱을 입력 및 목표 토큰으로 사용하여 언어 모델을 zero-shot text-to-speech 모델에 활용할 수 있고, 언어 모델의 효과적인 In-context learning을 활용할 수 있음
- Speech Quantization
- EnCodec
-> 24 kHz 오디오 → 75 Hz 코덱 (320의 홉 크기)
-> 잔차 벡터 양자화(Residual Vector Quantization, RVQ) 8단계
-> 75 * 8
<Mel-spectogram과 Codec 비교>
-
Mel-spectogram: 연속 신호 회귀 (80 bins)
-> Mel-스펙트로그램은 음성 신호를 주파수 패턴으로 변환하여 연속적인 값으로 표현하며, 시간-주파수 정보를 시각적으로 분석하는 데 유리 -
Codec: 다음 토큰 예측
-> 코덱은 음성을 토큰화된 데이터로 변환하고, 이를 바탕으로 다음 토큰을 예측하거나 신호를 압축 및 복원하는 데 유용
-> 이 방식은 효율성을 중시하며, 특히 신경망 기반 코덱은 음성 데이터를 효율적으로 처리
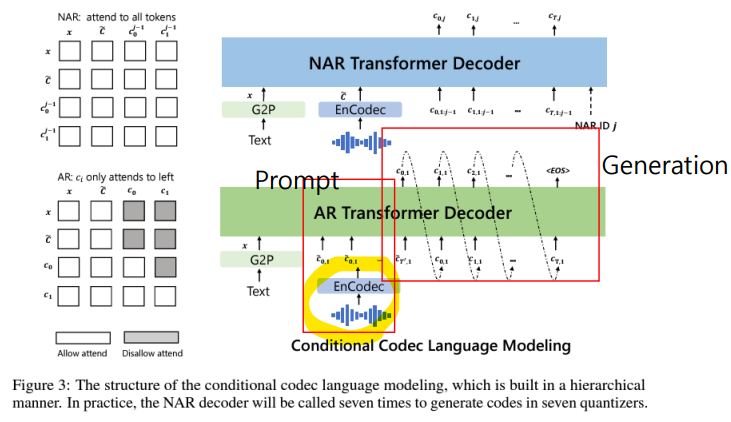
- Codec Language Model
1단계: AR GPT-3 스타일 Transformer decoder
-> RVQ의 첫 번째 토큰을 예측
2단계: NAR Transformer decoder
-> 나머지 7개의 양자화기(1:8) 토큰을 예측
- AR(Autoregressive) 방식: 이전 토큰을 기반으로 순차적으로 다음 토큰을 예측하는 방식
- NAR(Non-Autoregressive) 방식: 여러 토큰을 동시에 예측하는 방식
- Inference(추론): 프롬프팅을 통한 In-context Learning
-
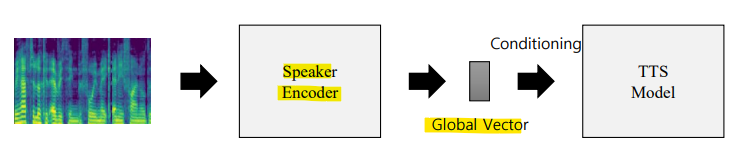
이전 방법: Mel-spectogram 또는 waveform signal(파형 신호)에서 Global Style Embedding을 추출하는 방식
-
Prompting 방법: 목표 화자로부터 추출된 음향 토큰 시퀀스 앞에 등록된 음성을 추가하여 사용
-> 등록된 음성 데이터를 프롬프트로 제공하여 모델이 작업에 적합한 방식으로 음성을 처리할 수 있도록 함
<Prompting이나 In-context learning의 제한사항>
- 모델 학습을 위해 대규모 데이터셋이 필요
-> 그러나 언어 모델은 다른 방법들보다 대규모 데이터셋에서 정보를 학습하는 능력이 더 뛰어남 - 사전 학습된 신경망 기반 오디오 코덱 또는 이산 음성 단위에 크게 의존함
-> 이러한 모델들의 오디오 품질은 종단간 음성 합성 프레임워크보다 상대적으로 낮음 - 추론 속도가 느리고, 강인성(robustness)이 부족하여, 오토리그레시브 생성 방식으로 인해 반복, 생략, 발음 오류가 발생할 수 있음
