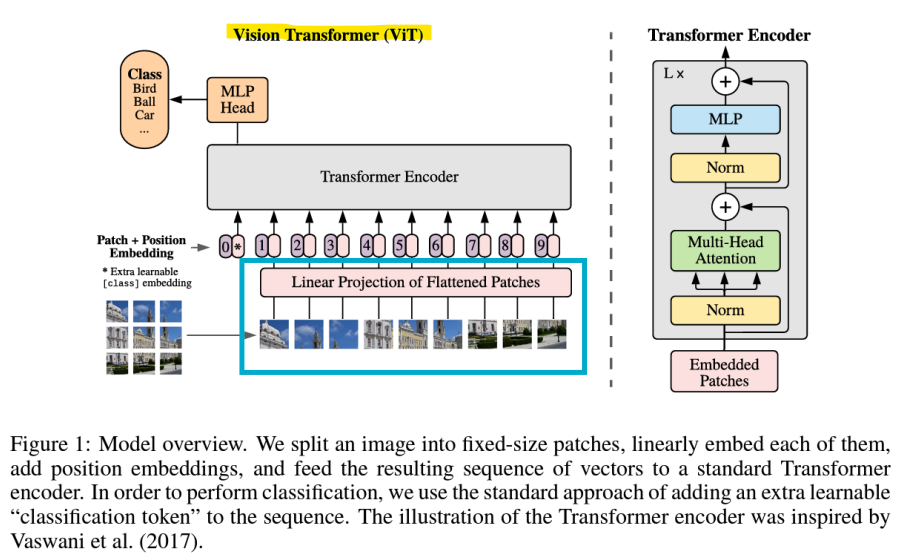
- Vision Transformer(ViT)
: 컴퓨터 비전을 위해 설계된 Transformer
- Image Patch
- 입력 이미지가 patch로 나뉘며, 각각은 patch embedding layer를 통해 선형적으로 mapping된 후, 표준 Transformer encoder에 입력됨
- Transformer는 image patch를 text token처럼 사용함
-
이미지를 [H, W, C]에서 2D patch로 평평하게 변환한 시퀀스 [N, PxPxC]로 재구성함
-> (H, W)는 원본 이미지의 해상도
-> C는 채널 수
-> (P, P)는 각 이미지 패치의 해상도 -
ViT는 16x16 입력 패치 크기를 사용
-> 트랜스포머의 시퀀스 길이는 패치 크기의 제곱에 반비례하므로, 패치 크기가 작은 모델일수록 계산 비용이 더 많음(더 작게 쪼개면 전체 패치가 많아지므로) -
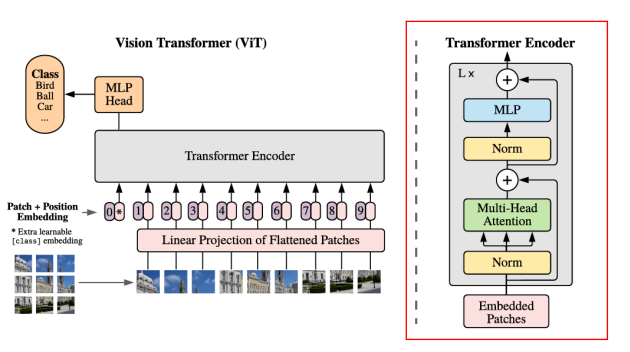
image patch를 위한 Positional Embedding
-> 이미지를 대신해 평평하게 변환된 2D patch sequence를 사용할 때, 이미지의 위치 정보를 잃게 됨
-> ViT는 공간적 정보를 인코딩하기 위해 입력 패치에 positional embedding을 추가함
-> positional embedding이 없는 모델과 있는 모델의 성능 사이에는 큰 차이 O
-> positional information을 인코딩하는 다양한 방법들 사이에는 거의 차이 X
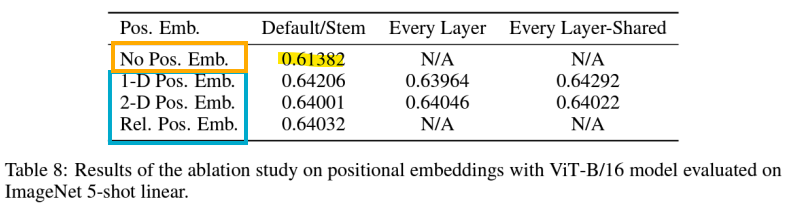
- Transformer Encoder

- Multi-head attention
- Self-attention은 ViT가 이미지 전체에 걸쳐 정보를 통합할 수 있게 함
- 각 head는 다른 정보를 주목, 그리고 각각의 특징들이 통합됨
- Classification Head (MLP layer)
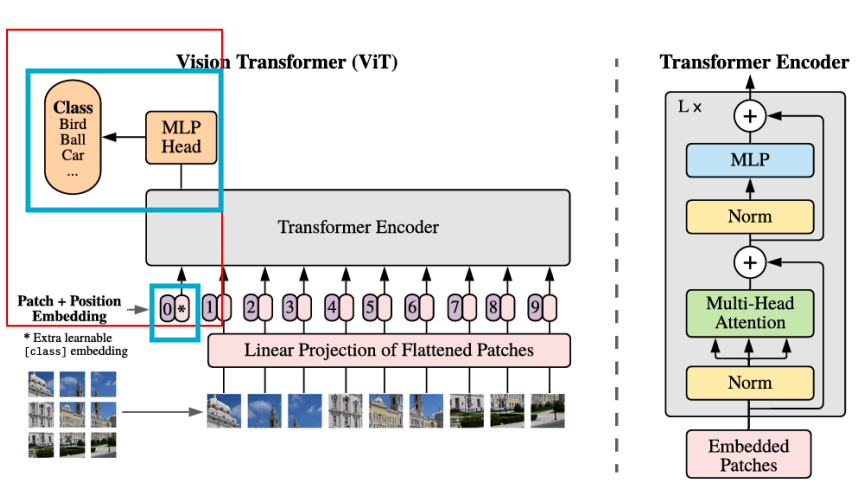
-
입력: CLS(Classification) token
-> 입력 이미지 시퀀스 맨 앞에 CLS token이 추가됨
-> (이미지의 전체적인 정보를 종합하여 최종적으로 분류 작업을 수행하기 위한 토큰)
-> 최종적으로 CLS token이 해당 이미지의 중요한 특징을 담음 -
classification을 위한 MLP layer
-> Transformer encoder에서 나온 CLS token을 사용하여 MLP layer에서 분류 작업을 수행
-> MLP layer는 이미지가 속한 클래스를 결정하기 위해 입력된 CLS token의 특징을 기반으로 최종 출력을 생성하는 역할
- 결과
- ViT는 여러 이미지 분류 데이터셋에서 최신 기술과 비슷하거나 그 이상의 성능을 보여주며, pre-training 비용도 비교적 저렴함
- Masked Auto-Encoder(MAE)
- Vision Transformer를 pre-training 시키기 위한 자가 지도 학습(Self-supervised learning) 방법

-
랜덤 masking을 사용한 BERT 스타일의 pre-training
-
마스크(Mask)를 적용하여 입력 데이터의 일부를 가리고, 모델이 가려진 부분을 복원하는 과정을 통해 학습을 진행

-
MAE pre-training은 downstream 작업의 성능을 향상시킬 수 있음
*downstream: 사전 훈련된 모델이 특정한 실제 응용 분야나 문제를 해결하기 위해 사용하는 작업
