- 적대적 학습(Adversarial Training)
- 생성자(Generator, counterfeiter위조범)
: 더 현실적인 샘플을 생성하려고 노력
- 판별자(Discriminator, 경찰관)
: 실제 데이터와 가짜 데이터를 구별하려고 노력, 실패 시 패널티 받음
- 생성적 적대 신경망 Generative Adversarial Networks(GANs)
- 목표: 모델이 실제 데이터와 구별할 수 없는 샘플을 생성하도록 하는 것
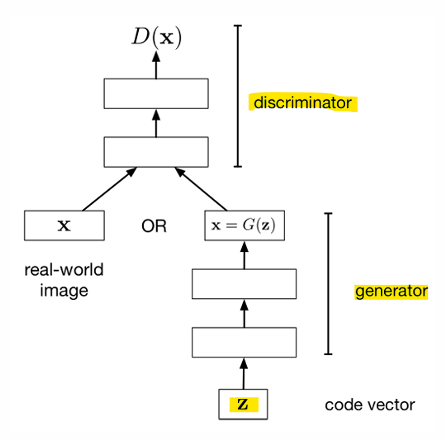
- Discriminator, 판별자
- 손실 함수: 실제 샘플과 가짜 샘플을 분류하기 위해 Cross-entropy loss 사용
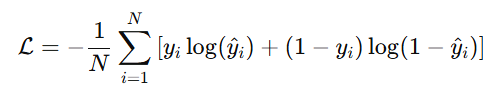
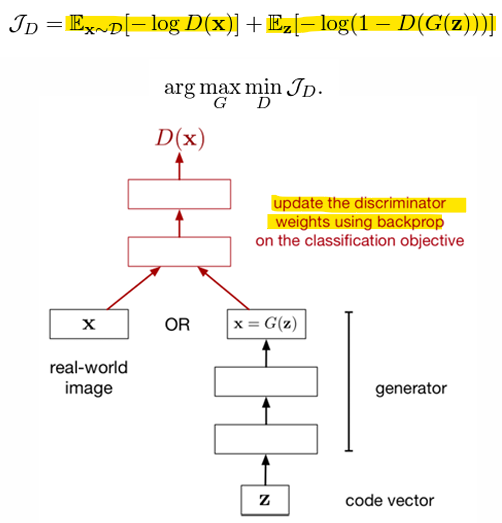
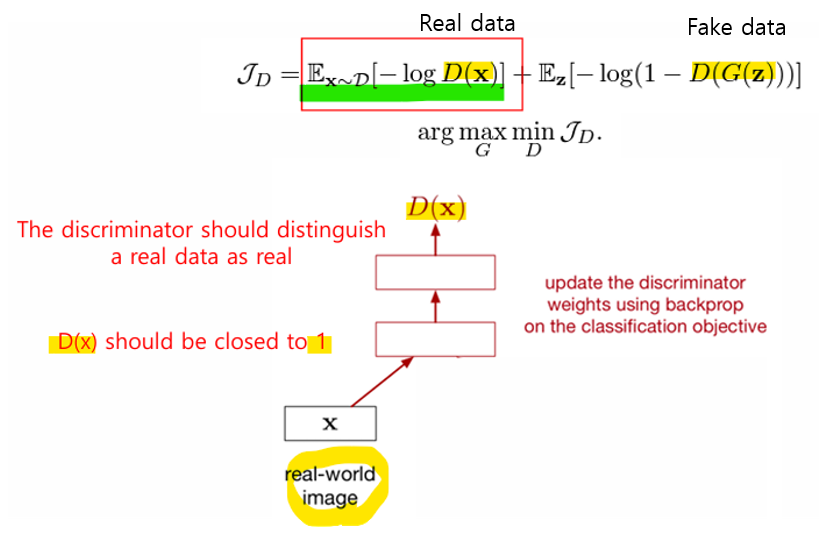
- real data인 x로부터 D(x)는 1에 가까워야 함
- fake data인 G(z)로부터 D(G(z))는 0에 가까워야 함
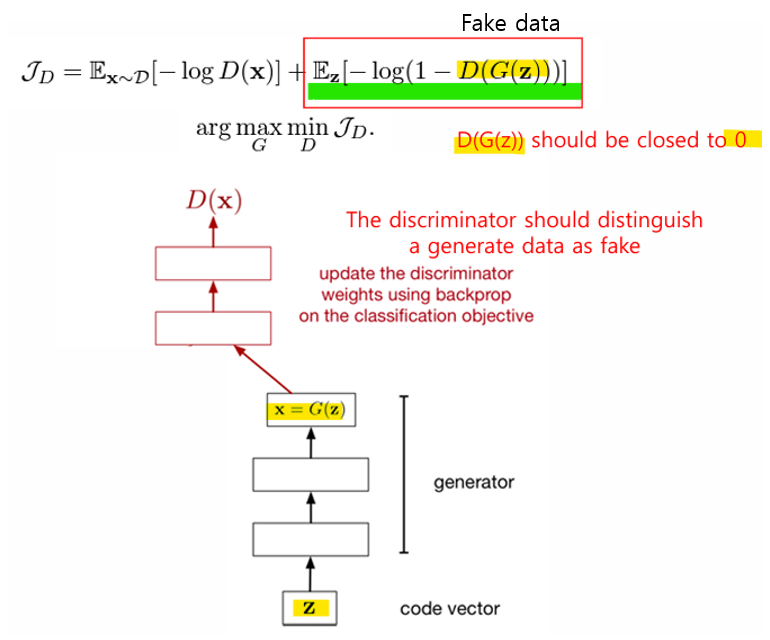
- Generator
- 손실 함수: 판별자의 Cross-Entropy를 최대화하기 위해(그래야 real로 판별) 음의 교차 엔트로피 손실(Negative Cross-Entropy Loss) 사용

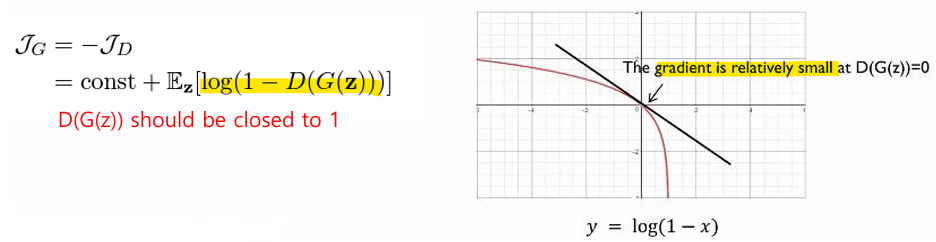
- Modified Generator Loss
- Original Generator Loss(Minimax Loss)
: 초기 학습 단계에서는 생성자가 저품질 샘플을 생성
: 따라서 판별자가 가짜 샘플을 쉽게 구별 → D(G(z)) 값이 0에 가까움
: D(G(z))=0일 때, 그래디언트(Gradient)가 매우 작아짐
-> 모델이 포화 문제(saturation problem)를 겪게 됨
-> D(G(z)) 값이 1에 가까워야 문제를 해결할 수 있음
- 포화 문제(Saturation problem): 생성자(Generator)가 학습 초기 단계에서 제대로 학습하지 못하게 되는 현상 -> GAN 학습의 효율성을 떨어트림
- Modified generator Loss

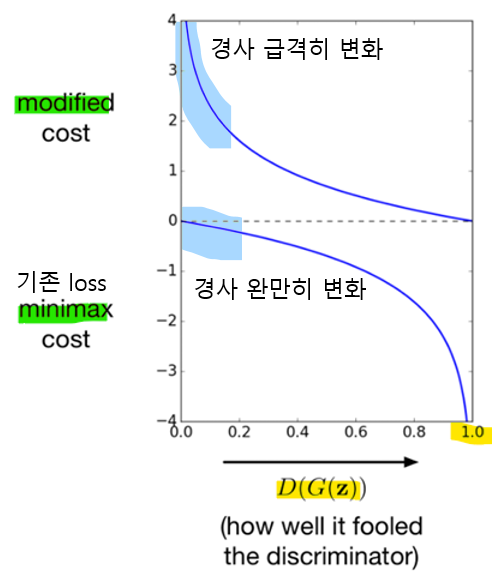
- Minimax Cost
-> D(G(z))가 0에 가까운 경우 기울기가 거의 0이므로, 초기 학습에서 생성자가 충분히 학습하지 못할 수 있음
-> D(G(z))=0.5 이후 그래디언트가 조금 더 증가하지만, 여전히 학습 속도가 제한적임- Modified Cost
-> D(G(z))가 0일 때도 기울기가 크므로 초기 학습이 더 빠르게 진행됨
-> 수정된 손실 함수는 학습 초기와 중반 모두에서 더 큰 그래디언트를 제공해, 생성자가 판별자를 더 잘 속이는 방향으로 학습할 수 있게함
- How can GAN generate good samples?
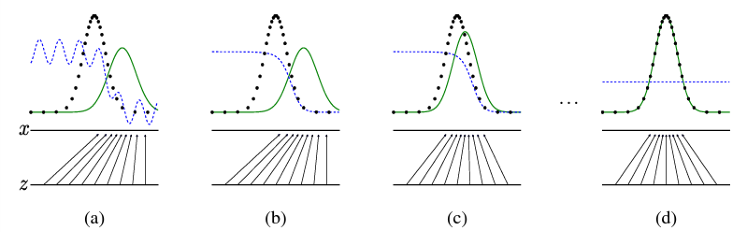
몇 번의 학습 단계를 거친 후, 생성자와 판별자는 더 이상 개선할 수 없는 지점에 도달하게 되며, 이때 pg = pdata (즉, D(x)=1/2)
-> 학습이 진행되면서 pg가 pdata에 가까워지다, 둘이 균형을 이루는 지점에서 pg(생성된 데이터의 분포) = pdata(실제 데이터의 분포) 가 됨
-> discriminator의 출력이 D(x) = 1/2로 수렴함 (discriminator가 데이터의 real or fake를 구별할 수 없다는 것을 의미)
-> 생성된 데이터가 실제 데이터와 구별할 수 없을 정도로 현실적이라는 의미
- 검은 선 (Black line): 실제 샘플의 데이터 분포
- 초록색 선 (Green line): 생성된 샘플의 데이터 분포
- 파란색 선 (Blue line): 판별 분포 (Discriminative Distribution)
- Theoretical Results
-
GAN의 목표: 최종적으로 생성된 데이터의 분포 pg가 실제 데이터의 분포 pdata와 같아지도록 학습
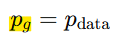
-
GAN의 학습: minimax 최적화 문제

-> 판별자 D: V(G,D)를 최대화(maxD)하여 진짜와 가짜 데이터를 더 잘 구분하도록 학습
-> 생성자 G: V(G,D)를 최소화(minG)하여 판별자를 속이도록 학습
- 고정된 G에서 D를 최적화하여 V(G,D)를 최대화함

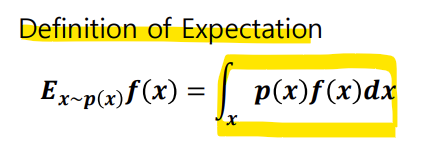
-
Expectation 공식에 의해서 풀어쓰면,
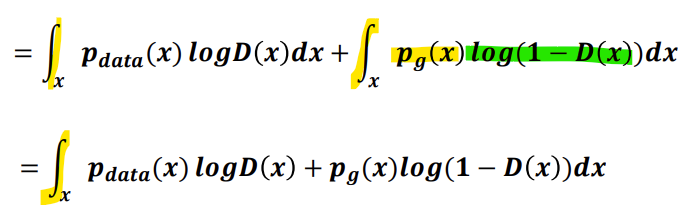
-
a, b, y로 대체하여 공식을 써보면,

-> 이를 maximize시키는 지점을 찾기 위해 미분하여 기울기가 0인 지점을 찾는다.

-> 미분한 식의 값이 0이 되는 지점이 Local maximum이므로

-> a, b, y로 대체했던 것을 다시 바꿔써주면,
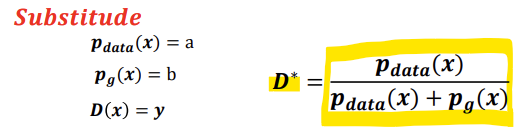
이렇게 구한 Optimal D 식을 이용해서 기존 V(G,D)식을 V(G,D)로 바꿔쓰면,

-> D* = 1/2일 때(pdata = pg)가 최적이므로, 위 식에 대입해서 계산하면
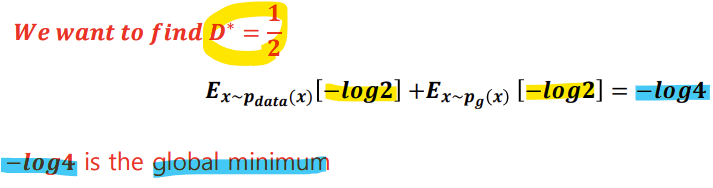
-> -log4가 global minimum인 것을 알 수 있다.
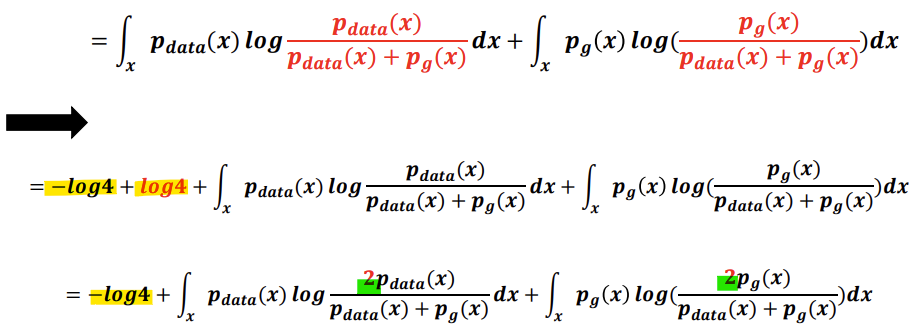

-> Jensen-Shannon Divergence, JSD는 항상 음이 아닌 값을 가지며, 두 분포가 같을 때 0이 됨
-> Global Minimum = -log4
-> 유일한 해는 pg = pdata
-> 따라서 생성 모델을 최적화하는 것은 2*JSD(Pdata||pg)를 최소화하는 것과 동일함!
- GANs for Image Generation
- DCGAN [ICLR, 2016]
- Deep Convolutional Generative Adversarial Networks (DCGANs)
: Convolutional Neural Networks-based Generator structures
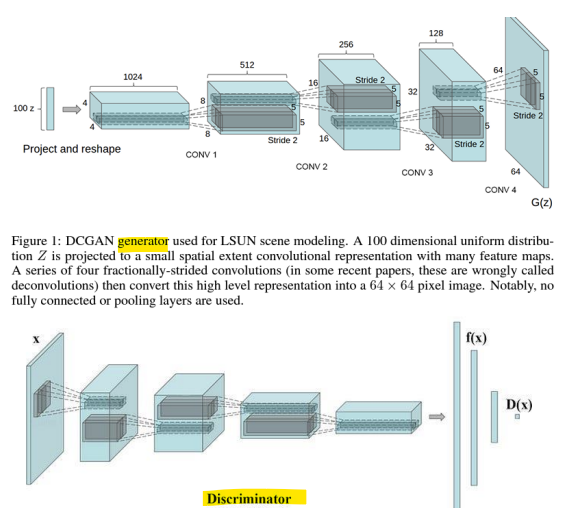
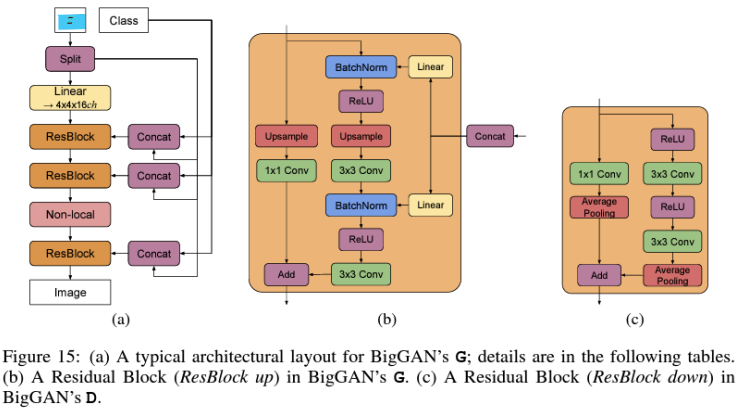
- Generator architecture
-
전치 합성곱(Transposed Convolution) 기반 upsampling
-> 전치 합성곱은 deconvolution이라고도 불리며, feature map의 크기를 확장(upsampling)하는 데 사용됨(latent vector z를 점진적으로 큰 이미지로 변환함)
-> 일반적인 합성곱: 입력 이미지 축소용 / 전치 합성곱: 입력 이미지 확장용 -
안정적인(stable) GAN 학습을 위한 배치 정규화(Batch Normalization)
-> 각 레이어에서 입력 데이터의 분포를 정규화하여 학습이 더 안정적이고 빠르게 이루어지도록 도움(기울기 폭발 or 소실 문제 완화, overfitting 방지에 도움) -
심층 네트워크를 위한 ReLU 활성화 함수
-> 비선형성을 부여하여 더 복잡한 데이터 분포를 학습할 수 있게함, 계산량 적어 효율적, Sparse Activation
- Discriminator
-
Convolutional Layer -> 데이터의 고차원 특징을 추출
-
BatchNorm -> 각 레이어의 입력 데이터를 정규화하여 학습을 안정적이게 함
-
Leaky_ReLU -> 비선형성 추가하여 더 복잡한 분포 학습, 음수 값에서도 정보 유지하므로 dead neurons 문제 방지
-
Sigmoid -> 마지막 레이어에서 출력값을 [0,1] 범위로 정규화하여, 입력 데이터가 "진짜"(1에 가까움) 인지 "가짜"(0에 가까움)인지 나타냄(확률값으로 사용)
-
DCGAN은 Discriminator가 새로운 작업에 대해 finetuning될 수 있음을 입증함
-> Discriminator는 적대적 학습(adversarial training) 중 유용한 정보를 학습
-> Discriminator는 진짜 데이터와 가짜 데이터를 구별하는 과정을 통해 비지도 학습 방식으로 학습할 수 있음
- LSGAN [ICCV, 2017]
- GAN 목표에서 Sigmoid 활성화 함수의 한계
-> Generator를 업데이트할 때, 이 손실 함수는 decision boundary의 올바른 쪽에 있는 샘플에서도 기울기 소실 문제가 발생함
-> 하지만 이러한 샘플이 여전히 실제 데이터와는 멀리 떨어져있는 경우가 있음
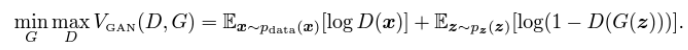
- LSGAN (Least Squares GAN)
- 최소 제곱 손실 함수(least squares loss function)는 오직 한 지점에서만 평평함
- 반면, sigmoid cross entropy loss function은 x가 상대적으로 큰 경우 포화(saturate) 상태에 도달함 -> 기울기 소실 문제 발생

- Conditional GANs
-
class가 많은 경우, GAN을 label 정보 없이 여러 클래스에서 학습시키면 현실적인 데이터셋을 생성하지 못할 수 있음(모델이 어떤 클래스의 데이터를 생성해야 하는지 모름)
-> 이유: 입력에 여러 클래스가 포함되어 있지만, 출력은 단일 클래스만 포함하기 때문
-> 해결방법: Conditional GANs 사용 -
label 정보에 조건을 추가하면 입력과 출력 사이에 결정론적 관계(deterministic relationship)를 생성할 수 있음(특정 조건에 맞는 일관된 데이터를 생성하도록 학습)
-> 먼저 큰 label vector를 작은 vector로 매핑하기 위해 linear mapping layer를 사용
-> 그리고, 이 작은 vector를 모델의 레이어에 병합(concatenate)
<cGANs 작동 원리>
1) 조건 정보 추가: 입력 x와 함께 label 정보 y를 모델에 제공
-> label 정보는 입력 벡터와 결합되어 G,D 모두에서 활용됨
2) label vector 매핑: 큰 label vector를 바로 사용 시 계산량 많고 효율 떨어짐
-> 그래서 label vector를 Linear Mapping을 통해 작은 크기의 vector로 변환(차원 줄임)
3) 모델의 병합(concatenate): 매핑된 작은 vector를 모델의 각 레이어에 결합
-> label 정보가 추가됨으로써, 모델은 특정 조건에 맞는 데이터를 학습 및 생성 가능
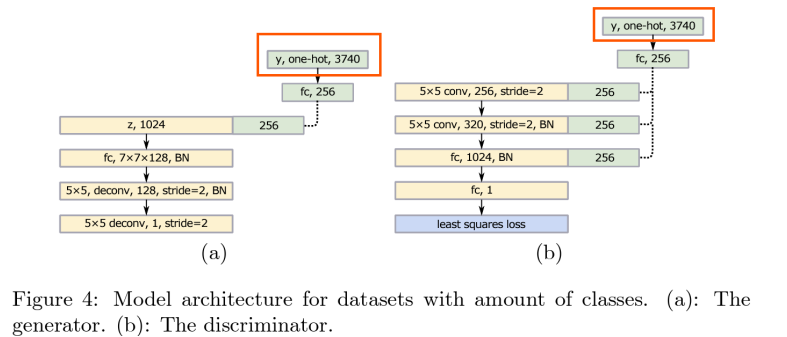
-> y: one-hot encoding된 label 정보, 각 클래스에 해당하는 벡터
예: 3740개의 클래스가 있다면, 레이블 y는 [0,0,...,1,...,0] 형태의 3740차원 벡터
-> 선형 레이어(fc)로 y를 256차원 벡터로 축소하여 랜덤 latent vector z(1024차원)와 결합하여 입력으로 사용
<cGANs의 장점>
- 조건 기반 생성: 특정 클래스를 생성하도록 제어 가능
- 다중 클래스 학습 가능: 입력에 조건 정보를 포함하여 여러 클래스를 동시에 학습 가능
- 결과 제어 용이: 생성할 데이터의 조건을 명시적으로 지정할 수 있어, 원하는 데이터를 더 쉽게 생성 가능
<cGANs의 한계>
- 레이블 의존성: 모델이 레이블 정보에 의존하므로, 레이블 데이터가 부정확하거나 누락되면 성능이 저하될 수 있음
- 복잡한 레이블 처리: 고차원의 레이블을 매핑하거나 적절히 결합하지 않으면, 학습 속도와 성능이 저하될 수 있음
- StyleGAN [CVPR, 2019]
- Adaptive Instance Normalization(AdalN)
: 각 합성곱 레이어에서 AdalN을 사용하여 Generator를 제어함
-> 주어진 스타일 벡터나 조건 정보에 따라 Feature map을 동적으로 조정(재스케일, 변환)하는 방법
-> 특히 Generator에서 특정 스타일 또는 조건을 반영하여 데이터를 생성하는 것에 강력 - 학습된 affine transformation을 활용
-> 조건 정보 y에서 Affine Transform(선형 변환)을 통해 스케일(Scale: σ(y))과 변환(Shift: μ(y)) 값을 생성함
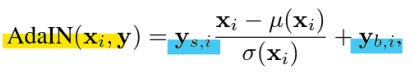
-> 스타일 벡터 y로부터 계산된 학습된 재스케일(scale)과 변환(shift)값
- x: 입력 feature map
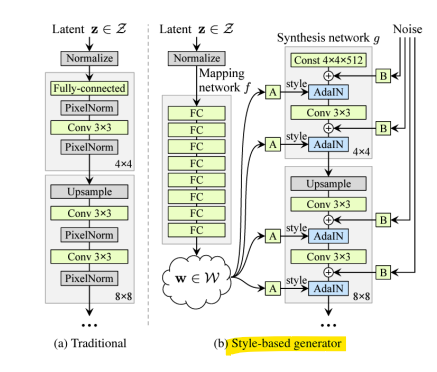
- Style mixing
: latent representation을 섞음
- BigGAN [ICLR 2019]
- 목표: GAN의 확장 가능성을 조사하여 성능 극대화
- 기존 GAN 모델의 한계
: 모델을 확장할 때(scaling up) 학습의 불안정성(Instability) 발생
-> 학습 붕괴(Training Collapse) 문제
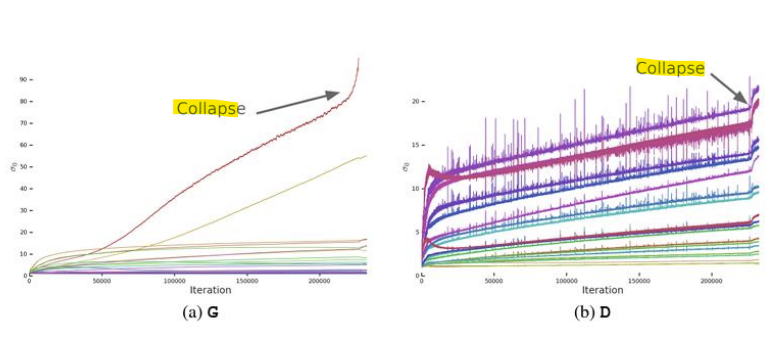
- Large Batch size
- Shared Embedding
- Skip-z (latent vector를 여러 레이어에 연결하는 Skip Connection)
- Orthogonal Regularization (직교 정규화)
- Weight regularization method
- Shared Embedding, Skip-z
-
Generator에서 단일 공유 클래스 임베딩(shared class embedding)을 사용하고, latent vector z에 대해 skip connections을 적용함 (Skip-z)
-
Shared Embedding: 하나의 공통된 임베딩 벡터를 Generator에서 모든 클래스에 대해 공유하는 방식
-> 즉, 여러 클래스의 임베딩 정보를 별도로 저장X, 같은 임베딩 공간에서 클래스를 나타내는 벡터를 생성함
-> 계산량 감소, 학습 속도 향상 -
Skip-z: latent vector z를 Generator의 여러 레이어에 직접 연결하는 스킵 연결 방식
-> 특정 레이어가 latent vector 정보를 잃지 않도록 도움
-> 학습 과정에서 기울기 손실을 방지, 학습 안정화(Stability)에 도움
- Truncation Trick(절단 기법)
- 일반적으로, GAN 모델 학습 시 z를 N(0,I)에서 샘플링하여 사용
- Truncation Trick에서는 정규분포 N(0,I)의 극단적인 값(멀리 떨어진 값)을 제거하여 절단된 정규분포(Truncated Normal Distribution)에서 z를 샘플링
-> 다양성(Diversity)과 품질(Quality) 사이에서 Trade-off(균형)
-> 다양성 감소: z를 절단하면 분포 범위가 줄어들어, 생성된 샘플의 다양성이 낮아짐
-> 품질 향상: 극단적인 z 값을 제거함으로써, 생성된 데이터의 품질이 높아짐

- 결론
- Improving generative model quality with GANs (GAN을 활용한 생성 모델 품질 향상)
-> 재구성 품질 향상
학습 안정성 최적화 및 지각적 척도(perceptual metrics)를 도입하여 출력 충실도를 개선
-> 적대적 피드백(Adversarial feedback)
지각적 품질을 향상시키고, 생성 모델에서 더 현실적인 결과를 생성 - StyleGAN
- AdaIN
- BigGAN
- VAE + GAN
-> 강건한 잠재 표현(Robust latent representation)
-> 제어 가능성(Controllable)
-> 고품질 재구성(High-quality reconstruction)
-> 빠른 추론(Fast inference)
- GANs for Speech Generation
- Deep Learning-based TTS System
- 기존의 딥러닝 기반 TTS 시스템 구성: 음향 모델링(Acoustic Modeling), 파형 생성기(Waveform Generator)

- Acoustic Features
- Acoustic modeling(음향 모델링)
: 음소 시퀀스(phoneme sequence)로부터 음향 특징(acoustic features)을 추정
- Acoustic features
- 기본 주파수(Fundamental Frequency, F0), 유성음/무성음(Voice, Unvoice, V/UV), 에너지(energy)
- Mel-scale Frequency Cepstral Coefficients, MFCC)
- Mel-Spectrogram, Linear Spectrogram
- Speech Analysis
- Waveform in speech(음성의 파형)
-
Sampling rate: 44,100Hz
-
음성 인식(Speech recognition)에서는 파형 신호를 16,000Hz로 다운 샘플링함
-
음성 합성(Speech synthesis)에서는 파형 신호를 22,050Hz로 다운 샘플링함
-> 16,000 Hz, 24,000 Hz, 44,100 Hz, 48,000 Hz도 사용됨 -
음성 신호(Speech signal)는 시간 축(time axis) 상에서 고유한 에너지와 특정 형태의 파형을 갖는 특징이 있음
-
음성 신호는 시간 축 상에서 에너지의 변화를 나타내는 신호
-
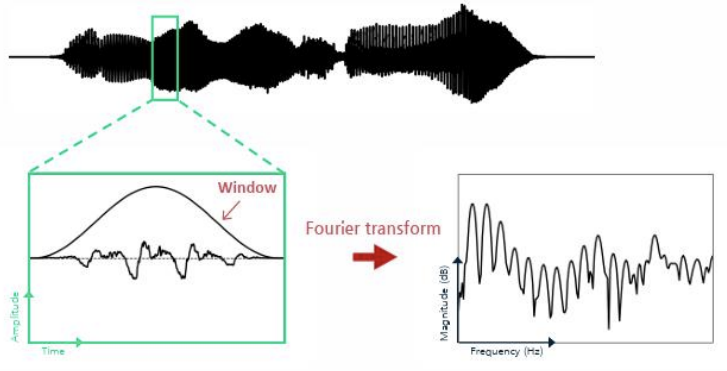
파형(Waveform)은 신호가 시간에 따라 어떻게 변하는지를 시각적으로 표현한 그래프
-
가로축(X축): 시간(Time, 보통 초 단위로 표시)
-
세로축(Y축): 진폭(Amplitude, 신호의 세기)
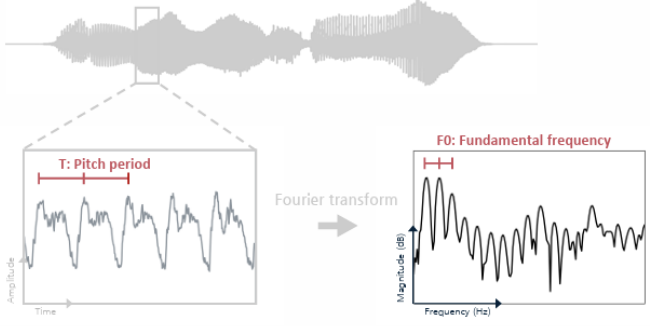
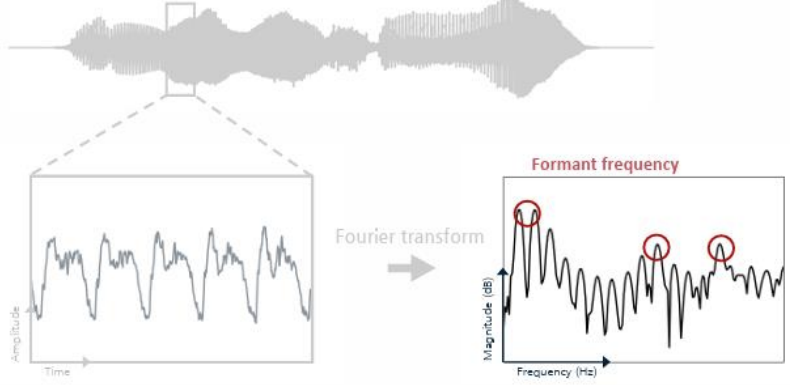
-> Formant frequency -> 발음 결정
- Short-time Fourier Transform (STFT, 단시간 푸리에 변환)
- 파형(waveform)에서 시간에 따라 변하는 사인파 주파수(sinusoidal frequency)와 위상 정보(phase info)를 분석
-> 신호를 짧은 시간 구간(Window)으로 나누어, 각 구간에서 푸리에 변환을 적용하는 방식
-> 음성 신호는 비정상(non-stationary)신호로, 시간에 따라 주파수 성분이 변함
-> STFT는 이를 효과적으로 분석하기 위해 신호를 짧은 시간 구간으로 분리하여 처리함
<주요 특징>
- 시간-주파수 분석:
STFT는 시간 축에서 신호를 분석하면서, 각 시간 구간의 주파수 성분을 추출
이를 통해 신호의 주파수가 시간에 따라 어떻게 변화하는지 파악 가능 - 사인파 주파수 분석:
STFT는 신호를 사인파(sinusoidal waves)로 분해하고, 각 주파수 성분의 세기(Amplitude)와 위상(Phase)을 계산
이는 음성 신호의 음조(Pitch)와 음색(Timbre)를 분석하는 데 유용 - 위상 정보 추출:
주파수의 세기만이 아니라, 신호의 위상 정보를 포함하여 음성의 원래 특성을 복원하거나 변형할 때 사용

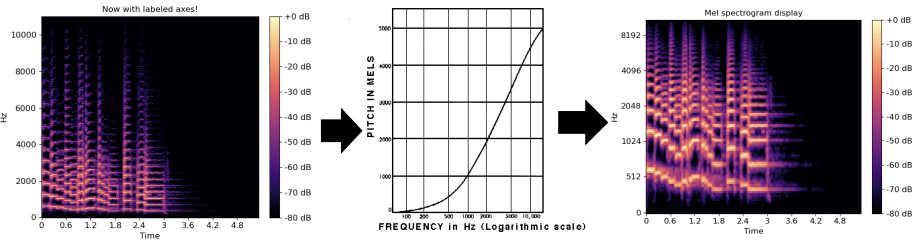
- Mel-spectrogram
: Mel-filter를 사용해 사람의 가청 주파수(audible frequency)에 집중하도록 스펙트로그램을 재구성함
- Mel-spectrogram은 음성 신호의 주파수 정보를 사람의 청각 특성에 맞게 변환한 스펙트로그램
- 스펙트로그램은 시간에 따른 주파수 에너지를 시각적으로 표현한 것
- Mel-spectrogram은 일반 스펙트로그램에서 멜 스케일(Mel Scale)을 적용해, 사람의 가청 주파수 범위에 집중한 형태로 변환한 것
- Mel Scale: 낮은 주파수 대역에서는 세밀하게, 높은 주파수 대역에서는 더 간략하게 표현함
<Mel-spectrogram의 특징>
- 가청 주파수 집중:
사람의 청각 특성에 맞춘 멜 스케일로 주파수를 변환하여, 의미 있는 주파수 정보에 집중 - 효율성:
낮은 주파수 대역은 자세히, 높은 주파수 대역은 간략히 표현하므로 주파수 분석이 더 효율적 - 시간-주파수 분석:
시간과 주파수 정보를 모두 포함하여 음성 신호의 구조적 패턴을 효과적으로 분석
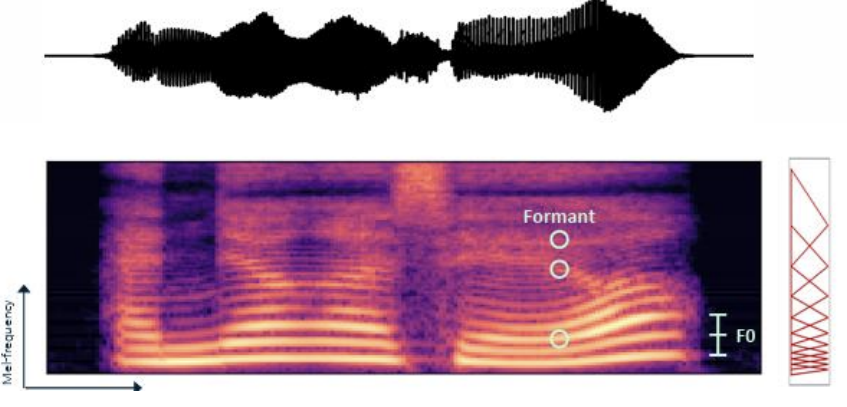
- Formant: 음성 신호의 주파수 스펙트럼에서 에너지가 특히 강하게 집중된 주파수 대역
-> 음성의 음색(timbre)과 언어적 특징(예: 모음)을 결정짓는 중요한 요소
- Neural Vocoder (신경 보코더)
- 중간 음향 특징(intermediate acoustic features)(ex.Mel-Spectrogram)을 파형 신호(waveform signal)로 변환
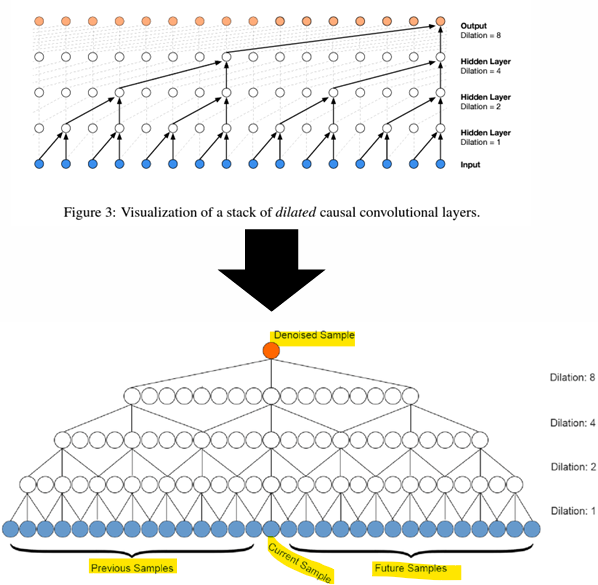
- WaveNet
- 목표
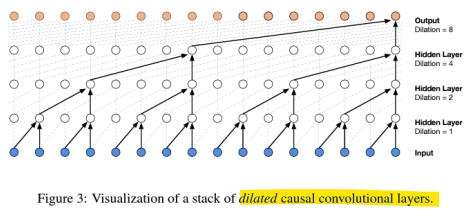
: 효율적인 오디오 모델링을 위해 팽창 인과 합성곱(Dilated Causal Convolution) 도입
: 신경 보코더(Neural Vocoder)를 통해 음향 특징(acoustic features)으로부터 파형(Waveforms)을 생성
-
Causal Convolution (인과 합성곱)
: 인과성(Causality)을 보장하는 합성곱, 현재 시점 t의 출력을 계산할 때, 입력 데이터의 현재 시점 및 과거 시점만을 참고함(미래 데이터 참조X) -> 실시간 처리에 적합
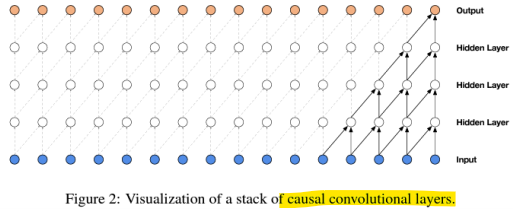
-
Dilated Convolution (팽창 합성곱)
: 합성곱 필터를 적용할 때, 샘플 간 간격(dilation rate)을 설정하여 입력 데이터의 더 넓은 범위를 한 번에 참조할 수 있도록 확장함 -> 큰 수용 영역(receptive field)을 확보
- 팽창 인과 합성곱 (Dilated Causal Convolution)
: 입력 데이터의 과거 시점만을 참조하면서도, 팽창 합성곱을 통해 더 넓은 범위를 한 번에 처리함(효율적)
- Residual and Skip Connections
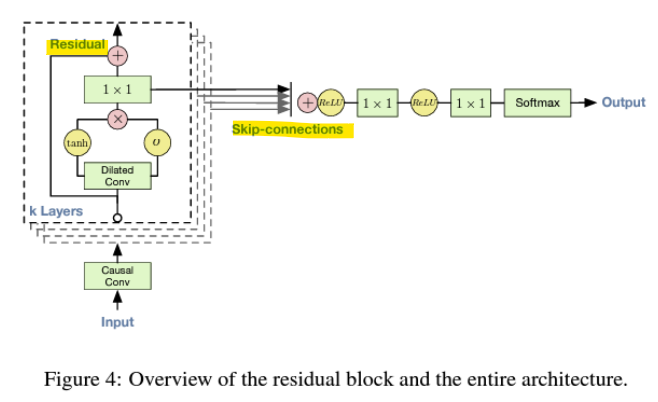
-
Residual Connections(잔차 연결)
: 입력 데이터를 네트워크의 출력과 더하는 방식으로, 신경망이 학습할 때 입력 정보를 유지하면서 더 깊은 특징을 학습할 수 있도록 도움
-> 기울기 소실 문제 완화, 효율적 학습 -
Skip Connections(스킵 연결)
: 네트워크의 각 레이어에서 학습된 정보를 최종 출력 레이어로 전달하여, 더 풍부한 정보를 사용해 음성을 생성, 네트워크의 모든 층의 정보를 효율적으로 활용
-> 다양한 시간 스케일 반영, 복잡한 패턴 학습, 효율적인 정보 전달
<장점>
- 고품질 음성 생성: 잔차와 스킵 연결은 네트워크가 시간적 및 주파수적 세부 정보를 보존하면서 자연스러운 음성을 생성하도록 도움
- 학습 안정성 향상: 기울기 소실 문제를 완화하고, 더 깊은 네트워크에서 학습이 가능하게 함
- 효율적인 다층 정보 활용: 스킵 연결은 모든 레이어에서 학습된 정보를 활용하여 음성의 다양한 특성을 반영함
- Parallel WaveGAN [ICASSP, 2019]
- 목표: 비자기회귀(Non-autoregressive) 파형 생성
-> 기존 비자기회귀 파형 생성 모델은 지각적으로 낮은 품질의 음성(자연스럽지X)을 생성함
- 비자기회귀 방식: 음성 데이터를 생성할 때 순차적으로 하나씩 생성하는 자기회귀 방식(Autoregressive)과 달리, 병렬적으로 데이터를 생성하는 방법
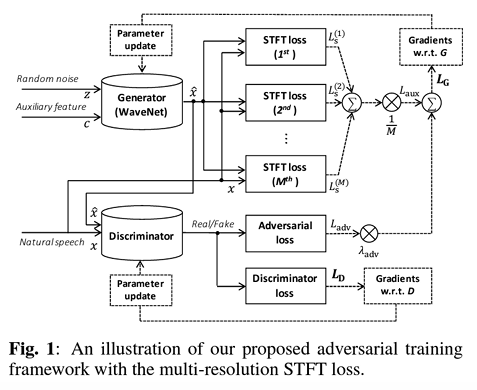
- Non-causal(비인과적) WaveNet
: 신호의 전체 범위(이전 + 이후 데이터)를 활용
: 과거뿐만 아니라 미래의 정보도 모델이 학습에 사용
<구조>
- 비인과적 WaveNet은 기존 인과적 구조 대신 비인과적 합성곱을 적용하여 전체 시퀀스 데이터를 동시에 활용
- 입력:
- 입력 𝑧: 모델이 신호를 생성하기 위해 초기화하는 랜덤 잡음
- 조건부 입력 (Acoustic features): Mel-스펙트로그램과 같은 음향 특성을 기반으로 신호의 특성을 제어
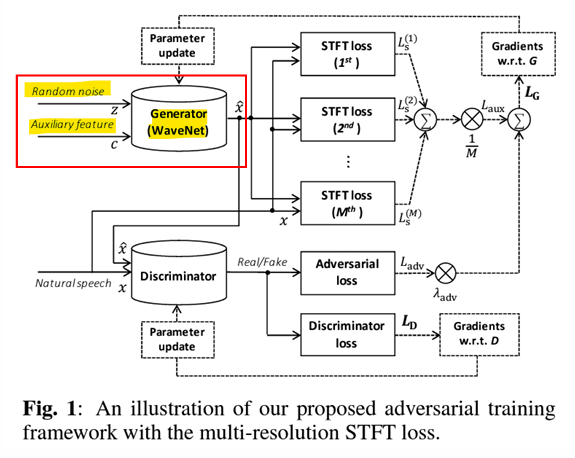
대립적 학습 (Adversarial Training)
목적: 생성된 데이터(예: WaveNet이 생성한 오디오)와 실제 데이터(자연 음성)를 구분하는 판별자(Discriminator)를 훈련하여 생성 모델(Generator)을 더욱 정교하게 만들기
-
판별자 손실 LD:
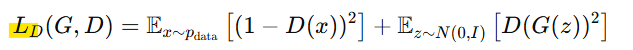
-
생성자 손실 Ladv:

<판별자 구조>
- 10개의 비인과적 1D 팽창 합성곱(non-causal dilated) 레이어로 구성
- 활성화 함수: Leaky ReLU (기울기 α=0.2)
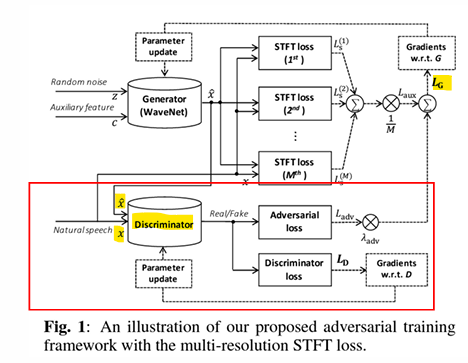
Generator (WaveNet): - 랜덤 노이즈 𝑧와 보조 특성 c를 입력으로 받아, 오디오 신호를 생성
- 𝐿𝐺: STFT (Short-Time Fourier Transform) 손실을 기반으로 학습하여 생성된 신호의 주파수 특성을 자연 음성과 유사하게 만듦
Discriminator: - 생성된 신호와 실제 신호를 입력으로 받아 진짜/가짜 여부를 판별
- 판별 결과에 따라 대립적 손실이 생성 모델의 학습에 사용
STFT 손실: - 생성된 신호와 실제 신호 간의 주파수 도메인 차이를 측정하는 다중 해상도 손실(Multi-resolution STFT Loss)을 사용
- Reconstruction loss
: 모델이 정답 데이터(ground-truth)와 생성 데이터(generated data) 사이의 차이를 최소화하려는 손실 함수
-
보통 L1 거리를 사용하여 생성된 파형과 실제 파형 간의 차이를 계산
-> L1 거리: 각 데이터 포인트의 절대적인 차이의 평균으로 정의
단순하지만, 오디오 데이터에서는 지각적으로 중요한 차이를 잘 반영하지 못함 -
일반적으로, 파형 손실(waveform loss)은 모델이 학습한 신호의 지각적 품질(perceptual quality)에 거의 영향을 주지 X
-
오디오 신호의 주파수 정보(예: 음색, 음질, 화질 등)는 파형 단위의 손실보다 주파수 도메인에서 더 효과적으로 표현됨
-> 따라서 L1 손실을 제거
-> L1 대신 Multi-resolution STFT Loss(다중 해상도 STFT 손실) 사용
- STFT(Short-Time Fourier Transform): 신호를 시간-주파수 도메인으로 변환하는 기술
-> 생성된 신호와 실제 신호의 주파수 분포를 비교하여 학습
-> 다중 해상도는 서로 다른 분석 창 크기(윈도우 크기)와 이동 간격(스트라이드)을 사용해 다양한 스케일에서 손실을 측정
<Multi-resolution STFT Loss 장점>
- 주파수 도메인 기반 평가:
오디오의 음색, 품질, 선명도와 같은 지각적 특징을 더 잘 반영 - 다중 스케일 분석:
다양한 해상도에서 신호를 분석함으로써, 파형의 세부적인 특성과 전반적인 구조를 모두 평가 가능 - 지각적 품질 향상:
단순한 L1 파형 손실에 비해, 실제 인간의 청각으로 느끼는 품질(Perceptual Quality)을 개선
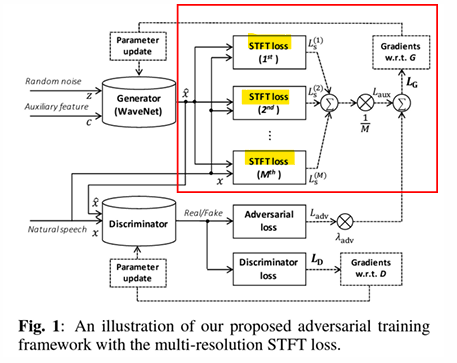
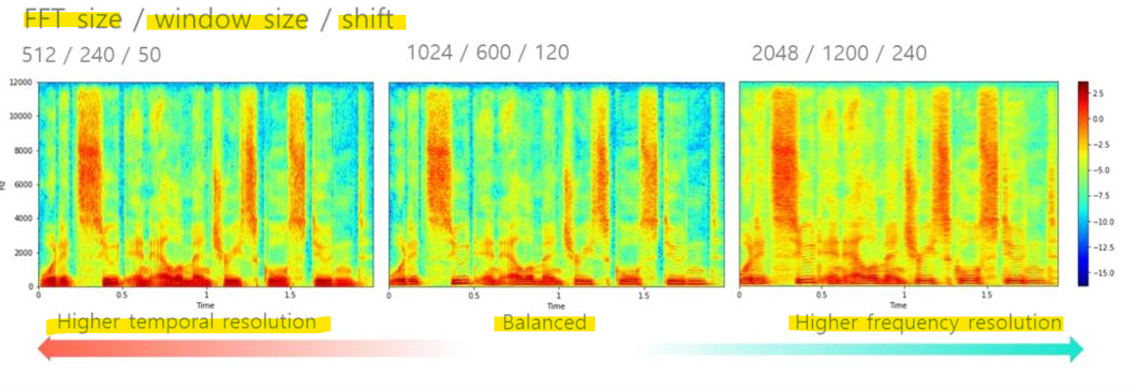
- FFT 크기: 한 번에 분석할 데이터 샘플의 크기를 결정
- 윈도우 크기: 시간 창(window)의 길이
- 이동 간격(Shift): 각 창이 다음 창으로 이동할 때 겹치는 샘플 수
512 / 240 / 50
:작은 FFT 크기와 짧은 윈도우는 시간 해상도(Temporal resolution)가 높아짐
: 하지만 주파수 해상도(Frequency resolution)는 낮아 세부 주파수 정보를 덜 표현
1024 / 600 / 120
: 균형 잡힌 설정으로 시간과 주파수 해상도 모두 적당히 표현
2048 / 1200 / 240
: 큰 FFT 크기와 긴 윈도우는 주파수 해상도(Frequency resolution)가 높아짐
: 하지만 시간적 변화를 정확히 표현하는 능력은 떨어짐
- STFT는 다양한 시간 및 주파수 해상도에서 계산됨
- 2가지 손실 함수: 에너지 성분(Energy components)이 큰 경우/작은 경우 패널티 부여
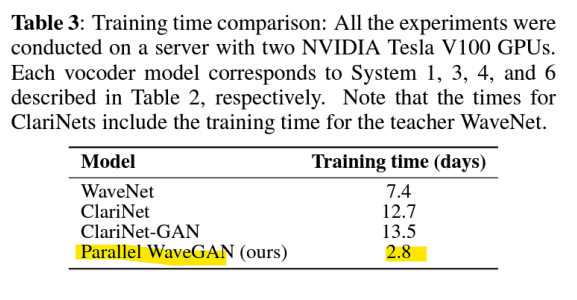
-> 빠른 학습 시간

- MelGAN [NeurIPS, 2019]
-
목표: 오디오 파형(waveform) 생성을 수행하기 위해 비자기회귀적(non-autoregressive) feed-forward convolutional 구조를 도입
-> MelGAN은 원시(raw) 오디오 생성을 위해 GAN을 성공적으로 학습한 최초의 연구 -
비자기회귀적(non-autoregressive) 방식
: 기존의 WaveNet과 같은 모델은 자기회귀적(autoregressive) 접근 방식을 사용하여 한 번에 한 샘플씩 순차적으로 오디오를 생성
-> 이는 높은 품질을 제공하지만, 계산 비용이 크고 속도가 느림
-> MelGAN은 비자기회귀적(non-autoregressive) 방식을 사용하여, 오디오 샘플 전체를 병렬적으로 한꺼번에 생성
-> 이는 시간 순서를 따르지 않고 병렬적으로 오디오를 처리하므로 훨씬 더 빠르게 작동
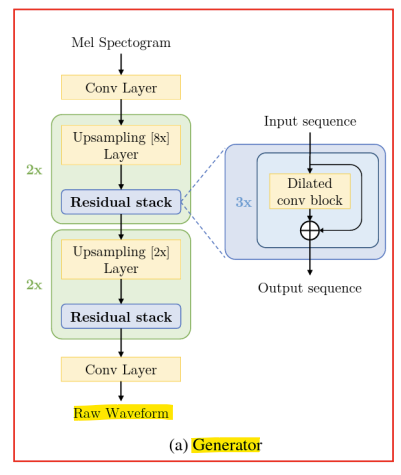
- Generator
: parallel waveform 생성을 위한 feed-forward convolutional generator
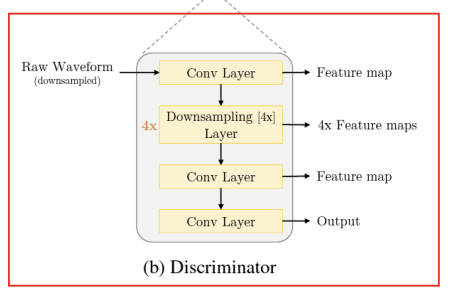
- Multi-scale discriminator
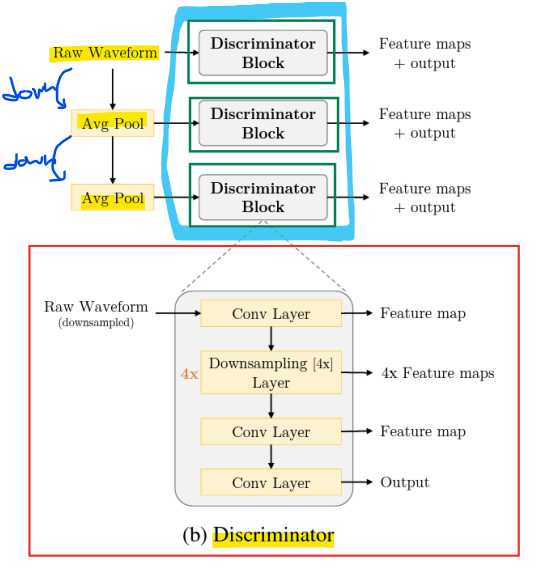
-
다양한 오디오 스케일에 대해 3개의 discriminator를 사용
-> 오디오를 2배 및 4배로 다운샘플링 -
다운샘플링된 오디오는 고주파수 정보를 잃음
-> 다운샘플링된 오디오를 사용하는 discriminator는 저주파수 정보(low-frequency)를 포착 가능함! -
다중 스케일 판별기는 오디오의 고주파수와 저주파수 정보를 모두 평가하기 위해 3개의 독립적인 판별기를 사용
-
다운샘플링 과정을 통해 저주파수 특성을 더 잘 분석하고, 이를 통해 보다 자연스럽고 고품질의 오디오 생성이 가능함
- Window-based objective(윈도우 기반 목적)
- 큰 커널 크기를 가진 스트라이드 합성곱 레이어(strided convolutional layers)를 사용해 표현을 다운샘플링함으로써, 전체 오디오 시퀀스의 분포 대신 작은 오디오 청크(audio chunks)의 분포를 분류하도록 학습 가능
-> 이는 PatchGAN과 유사
-> 오디오 생성에서 전체 오디오 시퀀스를 평가하려면 계산 비용이 크고 복잡도가 증가함
-> 이를 해결하기 위해 윈도우 기반 접근법(Window-based Objective)을 사용
-> 전체 오디오 시퀀스를 평가하는 대신, 작은 청크(chunks)로 나누어 분석
-> 계산 효율성을 높이고, 작은 윈도우 내에서 신호의 지역적인 특성을 학습 가능
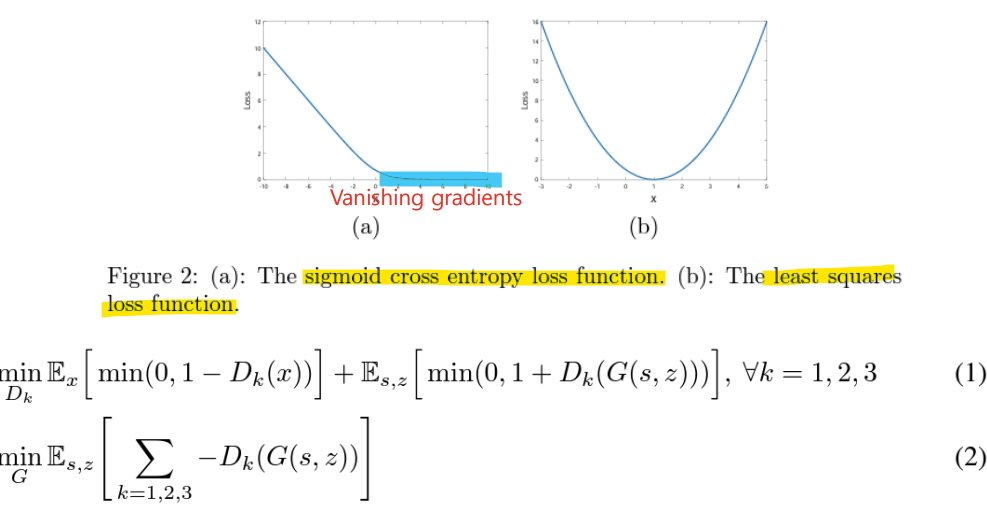
- Least-Square GAN (LSGAN)
- 전통적인 GAN은 Binary Cross Entropy(BCE)를 기반으로 학습
<문제점>
BCE 손실 함수는 Sigmoid 활성화 함수와 함께 사용되어, 극단적인 값에서 Vanishing Gradients(기울기 소실) 문제가 발생
-> D(x) 값이 매우 크거나 작아지면 손실 변화가 작아져 학습이 느려짐
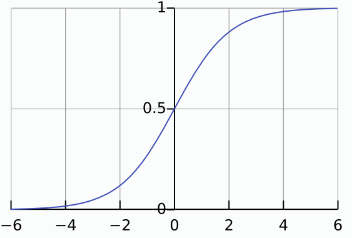
<해결방법>
- Least Squares Loss Function:
LSGAN은 BCE 대신 Least Squares(최소 제곱) 손실을 사용
-> 이 손실은 판별기의 출력을 1(진짜) 또는 0(가짜)에 가깝게 조정하려고 함
-> 기울기 소실 문제를 완화
-> 출력 값을 확률처럼 해석할 필요 없이, 판별기가 1과 0 사이의 값을 가지도록 학습
- Feature matching loss
-
Feature Matching Loss는 GAN(Generative Adversarial Network)에서 판별기(Discriminator)의 특징 맵(feature maps)을 사용하여 생성 모델(Generator)을 학습시키는 손실 함수
-
특징 맵(feature maps): 입력 데이터를 판별기가 분석하면서 추출한 고수준의 표현(특징)
-
L1 거리: 실제 오디오와 합성 오디오의 특징 맵 간의 차이를 계산하는 거리 척도

<Feature matching의 역할>
- Feature Matching Loss는 판별기의 특징 맵을 기반으로, 실제 오디오와 합성 오디오가 유사한 특징을 가지도록 학습함
- 단순히 "진짜처럼 보이는" 신호를 생성하는 것이 아니라, 실제 데이터와 비슷한 구조와 주파수 특성을 가지는 신호를 생성(단순히 신호의 모양만 복사하는 것이 아니라, 오디오의 구조적, 주파수 특성을 더 잘 반영)
- Total loss

1) GAN 손실
: 생성기가 판별기를 속여, 생성된 데이터 G(s,z)가 진짜(real)로 분류되도록 학습
2) Feature matching 손실
: 생성 데이터와 실제 데이터 간 특징 맵(feature maps)의 차이를 측정하는 손실
- 특징 맵은 판별기 Dk 의 중간 레이어에서 추출된 값
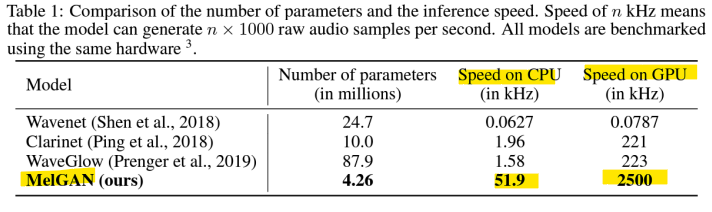
-> MelGAN은 최적화된 경량화 모델로, 다른 모델들에 비해 압도적으로 빠른 추론 속도와 효율성을 제공
특히 GPU 환경에서 실시간 오디오 생성이 가능하며, CPU에서도 상당히 빠른 속도
MelGAN은 파라미터 수와 속도의 균형을 잘 맞춘 모델로, 실시간 애플리케이션에 적합
- Ablation Study(소거 실험)
: 오디오 공간에서의 L1 손실은 지각적 품질(perceptual quality)을 저하시킴
-> 오디오 신호는 고주파수와 저주파수 요소가 모두 포함된 매우 복잡한 데이터
-> L1 손실은 전체 신호의 샘플 차이를 단순히 계산하므로, 신호의 주파수 정보(음질, 음색 등)를 적절히 반영하지 못함
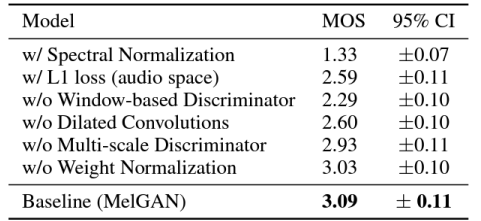
- MelGAN은 파형 오디오를 병렬적으로 생성할 수 있지만, MelGAN의 품질은 다른 기준 모델(baseline)들보다 뛰어나지 않음
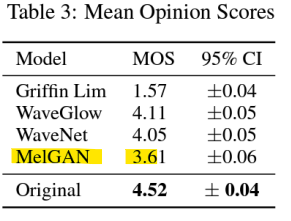
- HiFi-GAN [NeurIPS, 2020]
- 목표: GAN을 사용하여 고충실도(high-fidelity) 파형을 생성
- High-fidelity (HiFi)
: 소리의 고품질 재현(reproduction)
- Generator
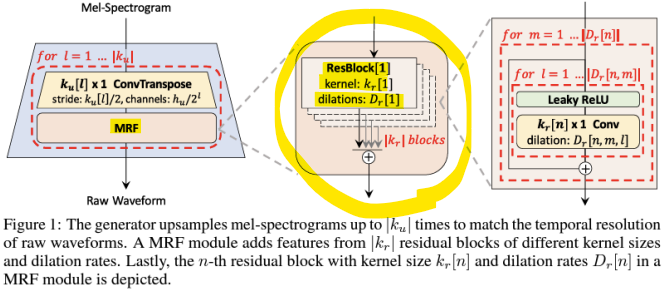
- 다중 수용 영역 융합(Multi-receptive field fusion, MRF)
-> 서로 다른 커널 크기(kernel size)와 팽창 크기(dilation size)의 조합을 사용하여 쌓아 올린 다중 합성곱 레이어와 잔차 연결(residual connections)
kernel size ex) 3, 7, 11
dilation size ex) 1, 3, 5
- Multi-scale discriminator (MSD)
위에서 다룬 내용
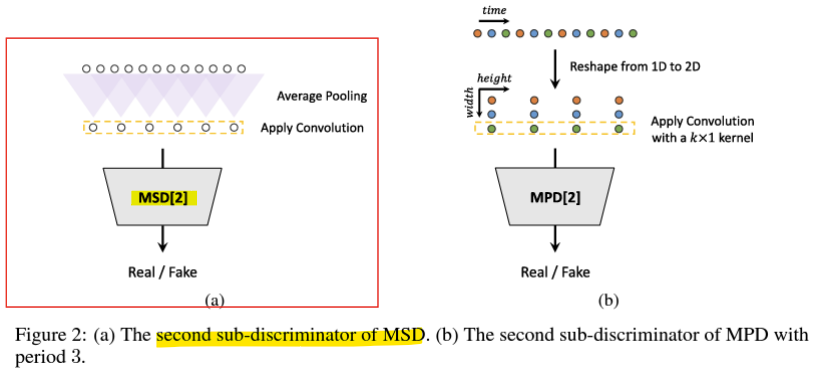
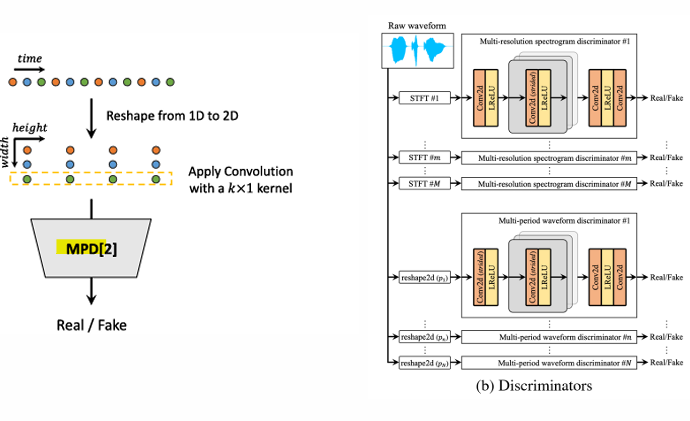
- Multi-Period Discriminator, 다중 주기 판별기 (MPD)
- 음성 오디오는 다양한 주기를 가진 사인파 신호(sinusoidal signals)로 구성됨
- 서로 다른 주기의 패턴을 포착하기 위해, 오디오를 다양한 주기로 변형하여 재구성함
-> 주기(period)는 가능한 중복(overlap)을 피하기 위해 [2, 3, 5, 7, 11]로 설정됨(prime number) - 각 판별기는 서로 다른 주기로 재구성된 오디오를 입력으로 사용함
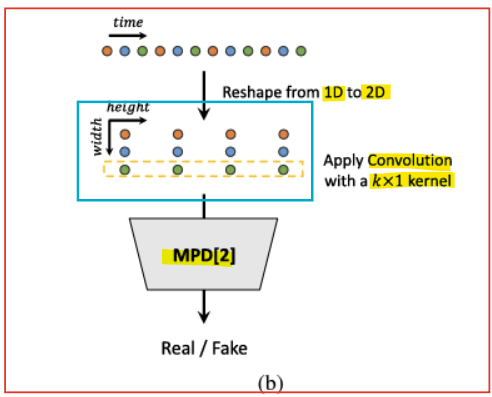
<구조>
1) 1D 신호를 2D로 변환 (Reshape from 1D to 2D):
입력 데이터는 1D 시간 축(time)으로 이루어진 오디오 신호
이 신호를 주기(period)를 기준으로 2D 형태로 재구성
예: 주기가 3일 경우, 신호를 3개의 열로 나누어 행렬 형태로 변환
이를 통해 주기적 패턴을 더 잘 포착할 수 있도록 준비
2) 합성곱 연산 (Apply Convolution):
변환된 2D 신호에 대해 k×1 커널을 사용하는 합성곱 연산을 적용
- k: 커널의 높이로, 주기적 패턴을 분석하기 위해 사용
- 1: 폭이 1인 커널을 사용하여 각 열(주기)을 독립적으로 처리
합성곱은 신호 내의 주기적 특성과 로컬 패턴을 추출하는 데 효과적임
3) MPD[2]:
재구성된 오디오와 합성곱 결과를 입력으로 받아, 해당 신호가 실제(Real)인지 가짜(Fake)인지 판별
MPD는 주기적 신호를 분석하여, 생성된 신호가 실제 신호처럼 보이는지 평가
4) Real / Fake Classification:
판별기의 최종 출력으로, 입력 신호가 실제인지 가짜인지에 대한 확률을 반환
-> 음성 오디오는 여러 주기를 가진 사인파 신호로 구성
-> 다양한 주기(periods)를 분석하기 위해 입력 신호를 특정 주기(예: [2, 3, 5, 7, 11])로 변형하여 2D 형태로 만듦
-> 각 MPD sub-discriminator는 다른 주기에서 신호를 평가하여, 생성 모델이 다양한 주기의 특성을 잘 학습하도록 도움!
<주기를 [2, 3, 5, 7, 11]로 설정한 이유>
- 음성 신호는 여러 주기적 패턴으로 구성
-> 하지만 특정 주기들이 공통 배수를 가질 경우, 서로 다른 주기의 신호들이 겹칠 수 있음
-> 이 값들은 소수(Prime Numbers)로, 공통 배수가 거의 없음
-> 소수는 자신과 1을 제외한 다른 수로 나누어지지 않기 때문에, 주기적 중복을 최소화할 수 있음
-> 서로 다른 주기의 신호가 독립적으로 학습될 수 있도록 도움
- LSGAN Loss
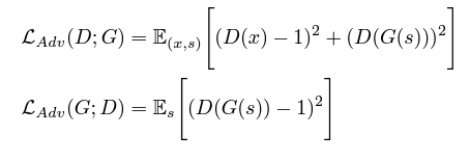
-> 기울기 소실(Vanishing Gradient) 문제 완화, 학습 안정성 증가
- Feature matching loss
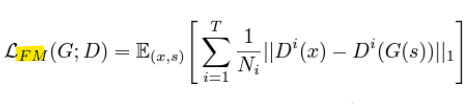
-> 생성 데이터의 구조적 품질 개선, 학습 안정화, 지각적 품질(Perceptual Quality) 향상
- Reconstruction loss
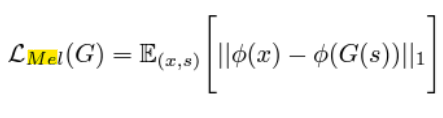
-
Mel loss
: Mel-spectrogram을 기반으로 생성된 데이터와 실제 데이터 간의 차이를 계산하는 손실 함수
-> Mel 손실은 생성된 오디오와 실제 오디오의 주파수 특성(Mel-spectrogram)을 비교하여, 두 신호가 유사한 주파수 분포를 가지도록 학습
-> 인간이 실제로 듣는 주파수 대역과 유사한 방식으로 신호를 평가하므로, 자연스럽고 고품질의 오디오를 생성하는 데 도움 -
ϕ: Mel-spectrogram 변환 함수(STFT(Short-Time Fourier Transform)(시간 도메인 오디오 신호를 주파수 도메인으로 변환)와 Mel 필터뱅크(Mel filter bank)**(STFT로 얻은 스펙트럼을 인간의 청각 특성에 맞춘 Mel 스케일로 변환)를 결합한 변환 과정)
- Total loss
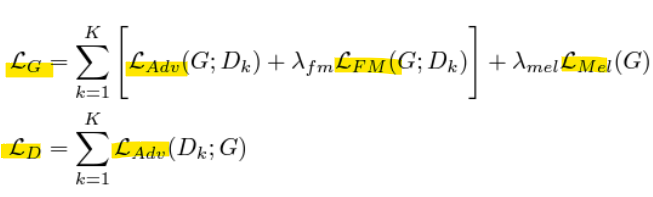
<생성자 Loss>
-
LAdv: Adversarial Loss
각 판별기 Dk에서 생성된 샘플 G가 진짜(Real)로 분류되도록 학습하는 손실 -
LFM: Feature Matching Loss
각 판별기 Dk의 특징 맵(Feature Map)을 기준으로, 실제 데이터와 생성된 데이터 간의 차이를 최소화하는 손실 -
LMel: Mel Loss
생성된 신호와 실제 신호의 Mel-spectrogram 간의 차이를 최소화하는 손실 -
λfm: Feature Matching Loss의 중요도를 조정
-
λmel: Mel Loss의 중요도를 조정
<판별자 Loss>
- LAdv: Adversarial Loss
각 판별기 Dk에서 실제 데이터는 진짜(Real), 생성된 데이터는 가짜(Fake)로 정확히 구분하도록 학습
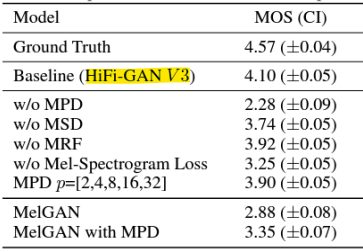
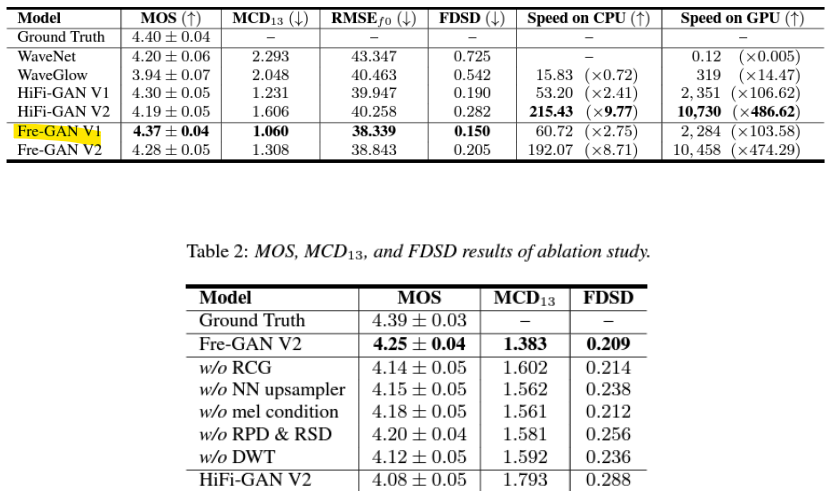
- Mos and Inference speed
- MOS
: 고품질 파형 생성 - 추론 속도 (Inference speed)
: 빠른 파형 생성
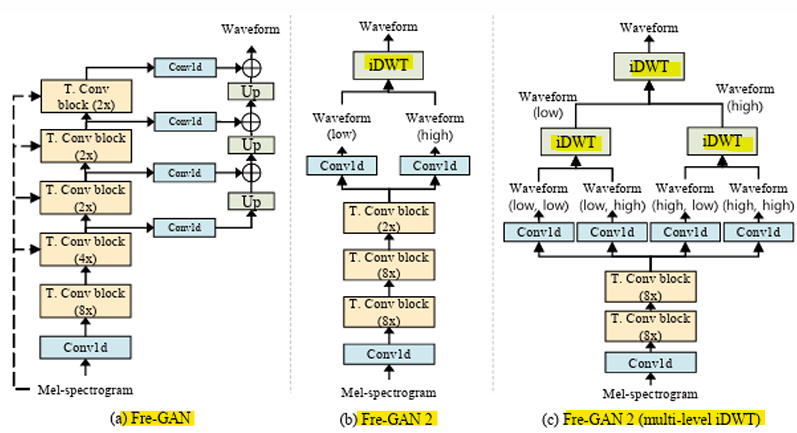
- Fre-GAN [Interspeech, 2021]
- 목표
: 다중 주파수 대역에서 다양한 스펙트럼 분포를 학습하기 위해, 해상도 연결 생성기(resolution-connected generator)를 사용한 점진적 파형(progressive waveform) 생성
: 손실 없는 주파수 모델링을 위해 평균 풀링(average pooling)을 이산 웨이블릿 변환(discrete wavelet transform, DWT)으로 대체
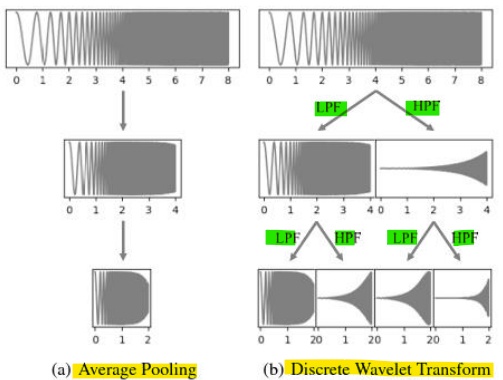
- Average Pooling
: 입력 신호의 값을 일정 크기로 다운샘플링
예: 2개의 샘플 평균을 계산하여 샘플 수를 절반으로 줄임
: 단순히 입력 신호를 공간적으로 압축하며, 주파수 정보 손실이 발생
: 신호의 고주파수 성분과 저주파수 성분을 구별하지 않음
-> 다운샘플링 후 고주파수 정보를 포함하지 못해, 손실(lossy) 압축이 발생
- 이산 웨이블릿 변환(Discrete Wavelet Transform, DWT)
: 나이퀴스트(Nyquist) 규칙에 따르면, 신호의 절반 주파수가 제거되므로 합성곱 결과 샘플의 절반을 버릴 수 있음
: 입력 신호를 저주파수 성분(LPF, Low-Pass Filter)과 고주파수 성분(HPF, High-Pass Filter)으로 분리
: 나이퀴스트(Nyquist) 규칙에 따라 샘플의 절반을 제거
: 이를 반복하여 신호를 다양한 주파수 대역으로 분해
-> 신호의 주파수 대역을 효율적으로 분리하며, 손실 없는 주파수 모델링 가능
-> 고주파수 성분과 저주파수 성분을 각각 보존하여 신호의 세부적인 특성을 유지
-> 주파수 대역별로 분리된 신호가 제공되므로, 더 풍부한 주파수 정보를 학습 가능
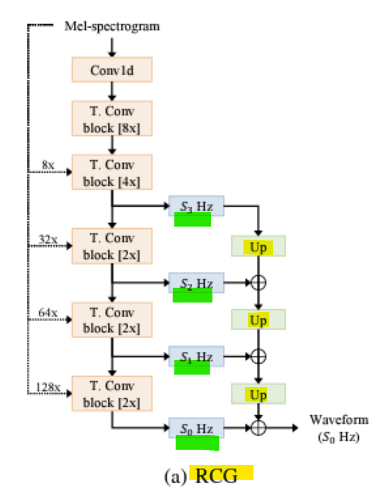
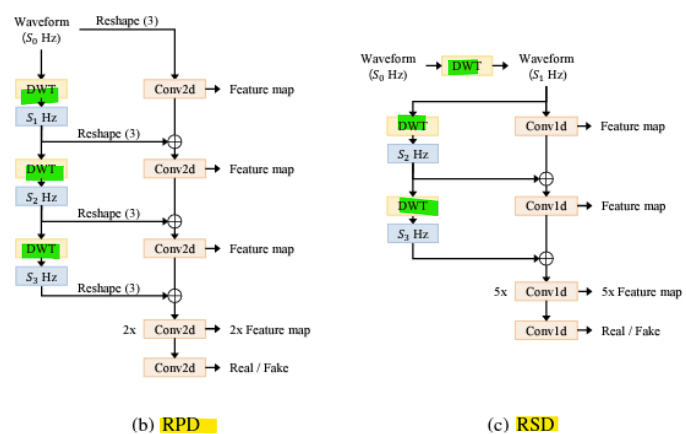
- 해상도 연결 생성기(Resolution-connected Generator, RCG)
-
RCG는 서로 다른 해상도에 해당하는 상위 K개의 파형 출력을 업샘플링하고 합산함
-> 다양한 해상도에서 여러 파형을 명시적으로 합산하여 스펙트럼 분포의 다양한 수준을 포착함 -
다중 해상도 파형 활용
: RCG는 신호의 여러 해상도(예: 낮은 해상도에서 높은 해상도까지)에서 생성된 상위 K개의 파형 출력을 사용
: 이를 통해 다양한 주파수 대역과 신호의 구조적 특징을 포괄적으로 학습 가능 -
업샘플링(Upsampling)
: 각 해상도에서 생성된 파형을 동일한 해상도로 변환하기 위해 업샘플링을 수행
: 업샘플링은 저해상도의 파형이 고해상도 신호에 기여할 수 있도록 함 -
명시적 합산(Summation)
: 여러 해상도에서 생성된 파형을 합산하여 최종 신호를 생성
: 이렇게 합산하면, 각각의 해상도에서 추출된 스펙트럼 분포가 유지되며, 더 풍부한 주파수 특성을 가진 신호를 생성할 수 있음
-> 각 해상도에서 학습된 파형을 결합하므로, 생성된 신호는 다양한 주파수 대역과 해상도를 아우르는 높은 품질을 가짐
- Resolution-wise discriminators
- 고주파수 정보 손실을 줄이기 위해, 평균 풀링(average pooling)을 이산 웨이블릿 변환(DWT)으로 대체
-> 오디오의 저주파수(Low)와 고주파수(High) 성분을 결합하여 판별기에 입력 - 판별기가 고주파수 성분의 누락된 세부 정보에 집중할 수 있도록 설계
- Discrete wavelet transform (DWT)
- Mel-spectrogram 공간에서의 픽셀 단위 차이
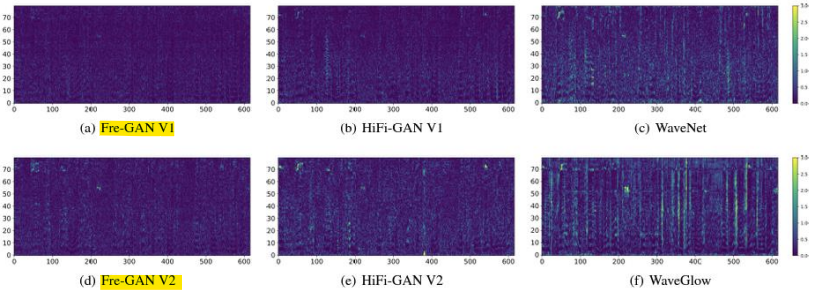
->Fre-GAN은 원하는 스펙트럼 분포를 재현
개선된 주파수 분포와 세부 정보 표현
- RCG는 점진적 학습(progressive learning)의 이점을 누림
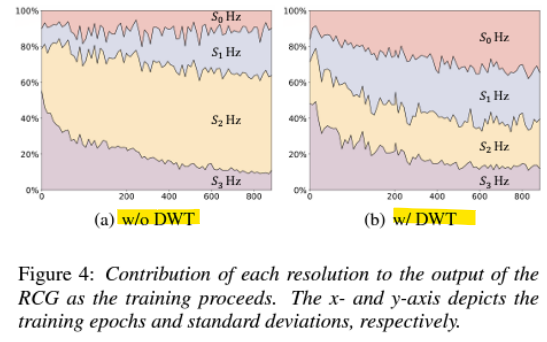
- 최종 오디오에 대한 기여도를 측정하여, 다양한 해상도의 여러 파형 간 상대적 중요도를 평가
-> 오디오 샘플의 표준편차를 계산하여 기여도를 측정 - 초기 학습 단계에서는 RCG가 저해상도 학습에 집중하며, DWT를 사용할 때 점진적으로 고해상도로 관심을 전환
-> 평균 풀링(average pooling)을 사용할 경우, 모델이 각 해상도를 고르게 학습하지 못함
- Fre-GAN 2 [ICASSP, 2022]
- 목표: 높은 효율성과 빠른 속도를 가진 역 이산 웨이블릿(inverse discrete wavelet) 변환(iDWT)을 이용한 파형 생성
-> 업샘플링을 위한 고정된 필터 파라미터 사용
- iDWT: iDWT는 DWT의 반대 과정으로, 웨이블릿 변환을 통해 얻은 주파수 성분(세부 계수와 근사 계수)을 다시 원래의 신호나 이미지로 복원하는 역할
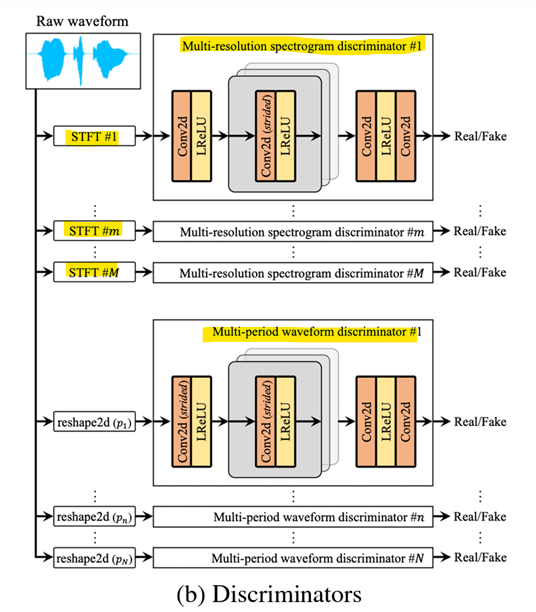
- UnivNet [Interspeech, 2021]
- 다중 해상도(multi-resolution) 스펙트로그램 판별기
-> 훨씬 더 현실적인 spectral info(스펙트럼 정보)를 포함하는 파형 생성
-
STFT (Short-Time Fourier Transform):
파형을 스펙트로그램으로 변환하는 과정, 각 STFT 변환은 서로 다른 해상도를 사용하여 다양한 주파수 및 시간 정보를 캡처 -
Multi-resolution spectrogram discriminator:
다양한 STFT 설정을 통해 여러 해상도로 데이터를 처리하여 정교한 주파수 정보를 추출 -
구성 요소
Conv2D (strided) : 스펙트로그램을 처리하는 합성곱 레이어
LReLU : Leaky ReLU 활성화 함수 -
Multi-period waveform discriminator:
파형의 여러 주기를 분석하여 실제(real)와 가짜(fake)를 구별
-> 파형의 시간적 구조를 세밀히 분석하여 모델이 생성한 파형의 정합성을 평가
reshape2d(p_n) 단계에서 파형 데이터를 주기에 따라 나누고, 이를 2D로 변환하여 판별기에 입력
구성 요소는 스펙트로그램 판별기와 유사
- BigVGAN [ICLR, 2023]
- 목표: 대규모 학습을 통한 범용(universal) 오디오 생성, GAN 생성기에 주기적(periodic) 활성화 함수와 anti-aliased representation 도입
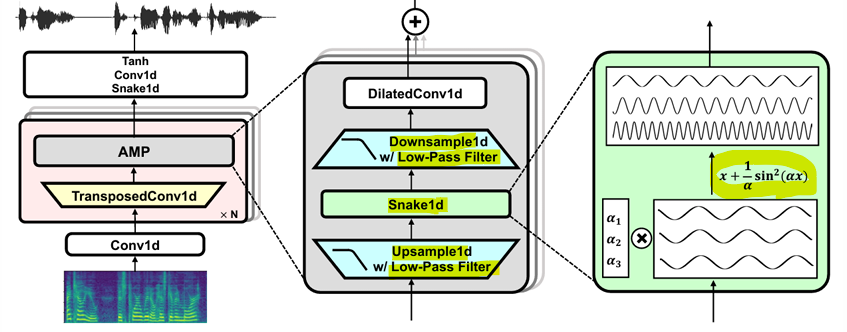
- 유도 편향(Inductive Bias)
-
학습 알고리즘은 학습자가 이전에 접하지 않은 입력에 대해 출력값을 예측하기 위해 사용하는 가정들의 집합
-> 유도 편향은 학습 알고리즘이 새로운 입력 데이터에 대해 출력을 예측하기 위해 가지는 사전 가정
-> 모델이 학습되지 않은 데이터에 대해 예측을 가능하게 하는 핵심 원리 -
Leaky ReLU 대신 주기적(periodic) 활성화 함수인 Snake1d로 변경
-> 기존의 Leaky ReLU와 같은 선형 활성화 함수는 특정 비선형 패턴을 학습하기 어려움
-> 대신 Snake1d와 같은 주기적 활성화 함수를 도입하여, 주기적이고 복잡한 신호(예: 오디오 파형, 주기적 데이터 패턴 등)를 더 효과적으로 학습
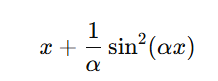
- Anti-aliased representation
- 업샘플링/다운샘플링 시 low-pass 필터를 사용하여 앨리어싱 문제를 줄임
-> 다운샘플링(데이터를 줄이는 과정)과 업샘플링(데이터를 늘리는 과정) 중, 고주파 성분이 신호에 섞이면서 발생하는 앨리어싱(Aliasing) 문제를 해결하기 위한 방법
-> 저역 통과 필터(Low-pass filter)**를 사용하여 업/다운샘플링 과정에서 불필요한 고주파 성분을 제거
-> 신호 왜곡 없이 더 깨끗한 데이터를 처리하고 생성
- 앨리어싱 (Aliasing): 샘플링 주파수가 원 신호의 최대 주파수의 두 배보다 작을 때(주파수 부족), 인접한 스펙트럼이 겹치면서 출력 신호에 왜곡이 발생하는 현상
-> 샘플링 주파수가 부족하면 고주파 성분이 왜곡된 신호로 겹쳐져 데이터가 손상
- 업샘플링: 데이터를 고해상도로 변환하거나, 신호를 더 부드럽고 촘촘하게 만들어 복원하거나 생성
- 다운샘플링: 데이터를 압축하거나 크기를 줄여 효율적으로 저장, 처리, 전송
- 결합 사용: 고해상도 데이터 생성과 품질 제어를 위해 둘 다 필수적
- Discriminator
- HiFi-GAN의 다중 주기 판별기 (MPD: Multi-Period Discriminator)
- UnivNet의 다중 해상도 스펙트로그램 판별기 (Multi-resolution Spectrogram Discriminator)
- Spectral: 주파수 영역(Frequency Domain)에서의 정보 표현
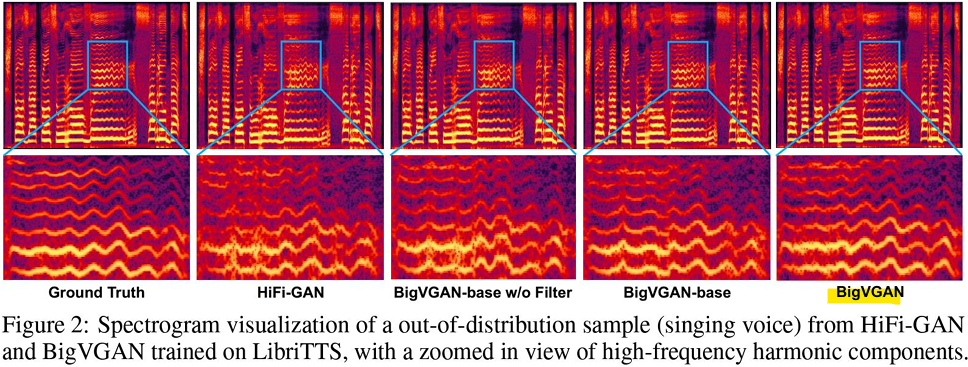
-> 최종적으로 고주파 성분과 시간적 조화가 가장 명확하게 복원된 모델
-> Ground Truth와 거의 유사하며, 고품질 음성 생성이 가능함
- iSTFT-Net [ICASSP, 2022]
- 목표: 디코더의 출력 레이어를 iSTFT로 대체하여 빠른 파형 생성을 실현
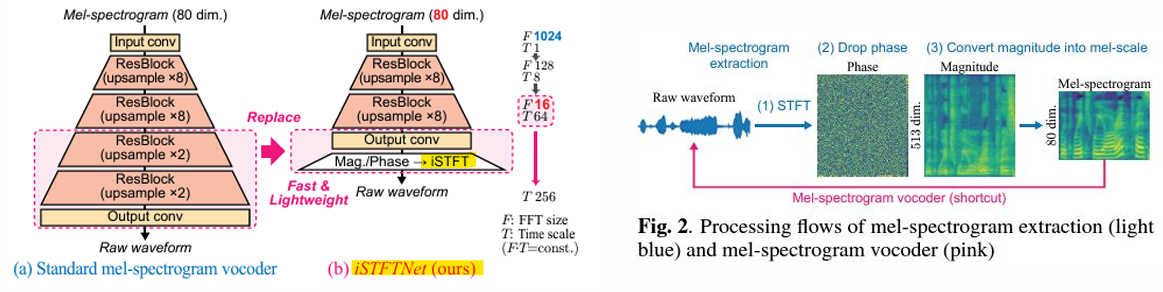
- STFT (Short-Time Fourier Transform)
: 파형 (Waveform) → STFT → 위상 (Phase) + 크기 (Magnitude)
: 위상 (Phase) + 크기 (Magnitude) → iSTFT → 파형 (Waveform)
: 크기 (Magnitude) → 멜 필터 (Mel-filter) → 멜 스펙트로그램 (Mel-spectrogram)
-> STFT는 파형 데이터를 주파수 영역으로 변환하여, 크기(Magnitude)와 위상(Phase) 정보를 얻음
-> iSTFT는 이를 다시 시간 영역(파형)으로 복원하는 과정
-> 디코더의 복잡한 구조를 iSTFT로 대체하면, 빠르고 효율적인 오디오 생성이 가능함
-> 멜 스펙트로그램은 크기 정보(Magnitude)를 멜 필터로 처리한 결과
<iSTFT의 장점>
기존 방식의 문제: 디코더가 오디오 파형을 생성할 때, 많은 복잡한 연산과 신경망 레이어를 사용
-> 이는 연산량 증가, 시간 지연 등의 문제 유발
-> iSTFT를 사용하면 위상(Phase)과 크기(Magnitude) 정보를 효율적으로 합성하여 파형 복원 가능
-> 계산량이 줄어들고, 속도 향상과 모델 경량화가 가능
-> 실시간 오디오 생성이나 대규모 데이터 처리에서 유리

- Vocos [ICLR, 2024]
-
목표: 업샘플링 없이 직접 푸리에 스펙트럼 계수(Fourier spectral coefficients)를 생성
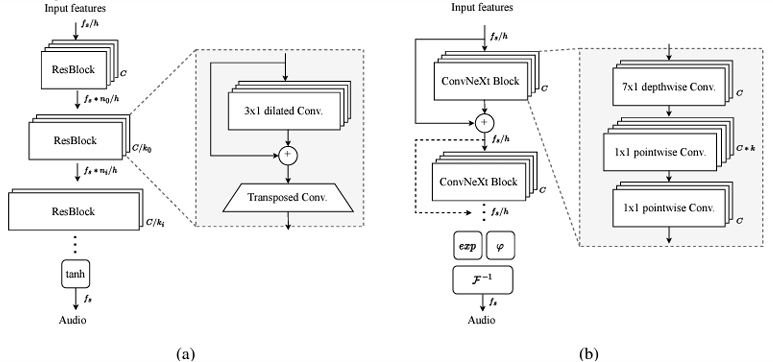
-
기존 방식: 오디오 생성 모델은 보통 업샘플링(Upsampling)을 통해 파형을 생성. 하지만 업샘플링은 GPU 메모리 사용량을 크게 증가시키고, 연산 비용이 높음
- 새로운 접근법: 이 모델은 업샘플링 없이, 푸리에 변환(Fourier Transform)을 사용해 스펙트럼 계수(Fourier spectral coefficients)를 직접 생성
-> 즉, 푸리에 변환의 크기(Magnitude)와 위상(Phase) 정보를 직접 예측하고, 이를 iSTFT를 통해 파형으로 복원
-> 업샘플링을 제거하여 GPU 메모리 문제 없이 긴 문맥(Context)을 처리 가능
-
위상 스펙트럼(Phase Spectrum) 모델링의 도전 과제
-> 크기(Magnitude): 신호의 지속 시간 동안 서로 다른 주파수 성분의 진폭을 나타냄(직관적이고 모델링이 비교적 쉬움)
-> 위상(Phase): 위상 정보는 직관적이지 않으며, 조작 시 종종 예측 불가능한 결과를 초래
위상 정보를 잘못 다루면 왜곡된 파형을 생성할 가능성이 높음 -
아키텍처 (Architecture)
-> Mel → ConvNext → m, p → iSTFT (exp(m)∙(cos(p)+j∙sin(p)))
-> Mel 스펙트로그램 → ConvNext로 m (크기)와 p (위상) 추출 → iSTFT로 파형 복원
-> 긴 문맥(Context)을 모델링하기 위해 입력 시퀀스를 증가시킴
-> 표현을 업샘플링하지 않기 때문에 GPU 메모리 문제 없이 가능
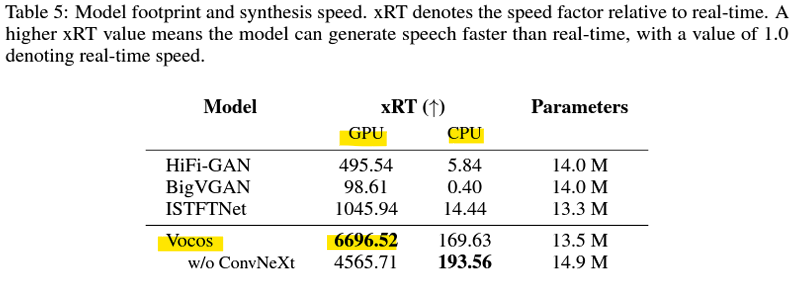
- Audio Codec
(audio enCOder/DECoder)
- 디지털 오디오 신호를 압축하고 압축을 해제하는 소프트웨어
- MP3, Windows Media Audio(WMA), Dolby Digital, DTS는 디지털 오디오를 압축하고 해제하는 인기 있는 코덱의 예
- 오디오 코덱은 하드웨어 회로일 수도 있음
<오디오 코덱과 토큰화의 공통점>
=> 데이터를 더 작은 단위로 변환하거나 효율적으로 처리하려는 목적
1) 데이터 압축 및 변환
오디오 코덱: 신호를 압축하여 저장 공간 절약 및 전송 효율성을 높임
토큰화: 텍스트를 작은 단위(토큰)로 변환하여 자연어 데이터를 효율적으로 처리
2) 입력 데이터를 더 작은 단위로 변환
오디오 코덱: 오디오 데이터를 샘플링하여 더 작은 주파수 단위로 변환
토큰화: 텍스트 데이터를 단어, 서브워드 또는 문자 단위로 분리
3) 모델 입력 준비
오디오 코덱: 모델이 오디오 데이터를 이해하거나 처리하기 쉽게 변환
토큰화: NLP 모델이 텍스트 데이터를 처리할 수 있도록 숫자로 변환
- SoundStream [TASLP, 2021]
- 목표
: 음성, 음악 및 일반 오디오를 효율적으로 압축
: 코덱과 신경 보코더(Neural Vocoder)의 결합
-> 벡터 양자화(Vector Quantization)
-> 고품질 파형 생성을 위한 적대적 학습(Adversarial Training)
- Residual Vector Quantization (RVQ)
- 여러 단계로 구성된 벡터 양자화 기법으로, 𝑁𝑞개의 VQ 레이어를 계단식으로 연결
-
비양자화된 입력 벡터가 첫 번째 벡터 양자화기 VQ를 통해 처리됨
Q1(x): 첫 번째 양자화기의 출력 (원본 데이터의 초기 근사값)
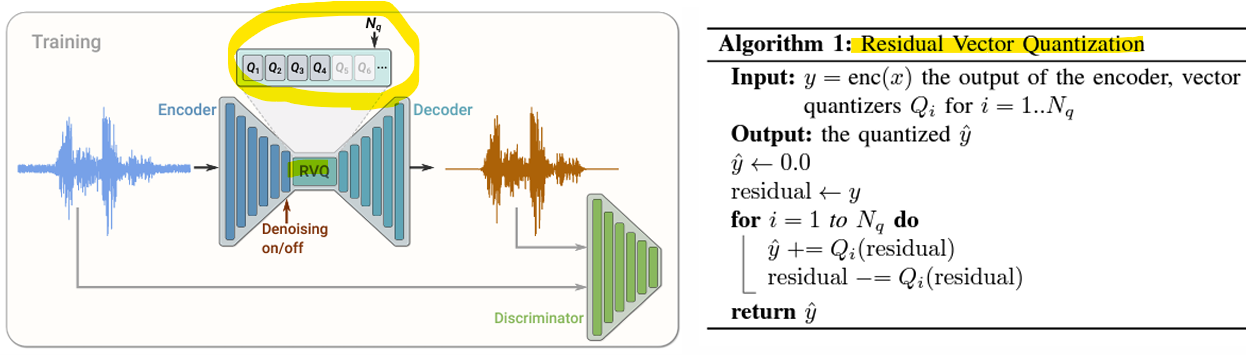
-
양자화 잔차(Residuals)를 계산
잔차 = 잔차 - 𝑄𝑖(잔차)
-> 첫 번째 양자화기에서 나온 출력과 원래 입력 데이터의 차이를 계산
-> 이 잔차는 원본 데이터의 세부적인 정보(양자화로 손실된 정보)를 포함 -
잔차는 추가적인 양자화기(Quantizer) 시퀀스에 의해 반복적으로 양자화됨
-> 구해진 잔차를 다음 벡터 양자화기 𝑄2에 전달
-> 이 과정을 𝑁𝑞번 반복하며, 각 단계에서 잔차를 점점 줄여나감
<RVQ의 장점>
=> 여러 단계로 잔차를 양자화하면 대략적인 구조 → 세부 정보 → 미세한 디테일을 점진적으로 보정하므로, 원본 데이터에 가까운 정밀한 표현을 얻을 수 있음
- 더 높은 표현력: 단일 VQ와 달리, 잔차를 점진적으로 처리함으로써 데이터의 세부 정보를 더욱 정밀하게 표현 가능
- 효율적인 데이터 압축: 각 단계에서 잔차를 양자화하므로, 전체 데이터 표현의 품질을 높이면서도 효율적으로 압축 가능
- 유연성: 각 단계에서 다른 양자화기를 사용할 수 있어, 다양한 데이터 유형에 적응 가능
-> Loss 역전파로 높은 품질의 waveform 생성 가능함
- 양자화(Quantization): 연속적인 값을 유한한 개수의 이산적인 값으로 변환하는 과정
-> 원본 데이터가 매우 많은 값을 가지는 경우, 이를 제한된 범위 내에서 대표값으로 근사하여 표현
- EnCodec [TMLR, 2023]
- 목표: 고품질 오디오 샘플을 실시간으로 생성할 수 있는 신경망 기반 오디오 압축 모델
- 다중 스케일 STFT 판별기(Multi-scale STFT Discriminator)
- 네트워크의 입력은 복소수 값 STFT(Short-Time Fourier Transform)이며, 실수부와 허수부가 연결된 형태로 입력됨
-> 실수부(Real): 크기(Magnitude)
-> 허수부(Imaginary): 위상(Phase) - STFT 창 길이가 [2048, 1024, 512, 256, 128]인 5가지 서로 다른 스케일을 사용
-> 단기 푸리에 변환(STFT)의 결과를 입력으로 받아 오디오 데이터의 품질을 평가하는 모델
-> 이 모델은 복소수 기반 입력 데이터를 다양한 시간-주파수 스케일에서 분석하여 오디오 신호의 현실성을 판별
<장점>
- 다중 스케일 접근 방식: 다양한 창 크기를 사용하여, 신호의 시간적 및 주파수적 특성을 모두 포괄
- 복소수 데이터 처리: 실수부와 허수부를 모두 고려하여, 오디오 신호의 진폭(Magnitude)과 위상(Phase) 정보를 함께 분석
- 고품질 오디오 생성 지원: 생성 모델이 신호의 모든 세부 사항을 반영하도록 학습을 유도
<아키텍처>
2D 합성곱(Conv2D) 기반 구성
- 초기 Conv2D 레이어:
입력된 STFT 데이터를 2D 컨볼루션 레이어로 처리
이는 주파수 및 시간적 특성을 동시에 고려 - 증가된 dilation rate를 가진 Conv2D 레이어들:
네트워크에는 점진적으로 dilation rate(확장된 합성곱 커널 간격)을 늘리는 2D Conv 레이어들이 포함
dilation rate의 증가를 통해 네트워크는 더 넓은 범위의 정보를 포착 가능
예: dilation rate = [1, 2, 4, 8].
이 방법은 데이터의 시간적 및 주파수적 맥락을 더 잘 이해하도록 도움 - 마지막 Conv2D 레이어:
마지막 2D 합성곱 레이어는 logits 값을 출력
logits 값은 입력 신호가 진짜(real)인지 가짜(fake)인지 판별하는 데 사용
- HiFi-Codec
- Group Vector Quantization
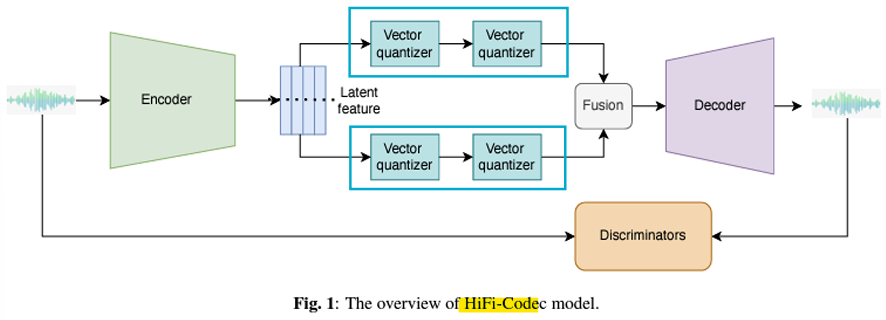
- Residual VQ는 첫 번째 VQ 레이어의 표현에 크게 의존
- 더 많은 정보를 저장하기 위해 잔차 양자화를 두 개의 RVQ 그룹으로 나눠 병렬적으로 수행
-> 이를 통해 잔차 블록(residual block)의 개수를 줄일 수 있음
<Residual VQ의 문제점>
- RVQ는 데이터의 잔차(Residual)를 반복적으로 양자화하여 데이터 표현을 점진적으로 개선
- 그러나, 첫 번째 VQ 레이어의 표현 품질이 낮으면 이후 단계에서 잔차가 제대로 처리되지 않아 최종 데이터 표현에 문제가 발생할 수 있음
-> 첫 번째 레이어가 중요한 이유: 첫 번째 VQ에서 데이터의 대략적인 구조를 잡지 못하면, 이후 단계들이 불필요한 세부 정보를 양자화하게 되어 효율이 떨어짐
<장점>
- 잔차 블록 수 감소
: 여러 단계로 잔차를 처리하는 대신, 그룹으로 나누어 병렬 처리하여 더 적은 잔차 블록을 사용
: 결과적으로 모델이 더 간결해지고 계산량 감소 - 효율적인 정보 보존
: 두 그룹이 서로 다른 잔차를 처리하므로, 데이터의 다양한 측면을 더 효율적으로 보존 가능 - 첫 번째 VQ 레이어의 중요성 감소
: 첫 번째 VQ 레이어가 모든 데이터를 처리해야 하는 부담이 줄어듦
: 첫 번째 레이어가 완벽하지 않아도, 그룹 간 협력을 통해 잔차 정보를 보완할 수 있음 - 모델 효율성 향상
: 병렬 처리로 인해 연산 속도가 증가하고 메모리 사용량이 감소
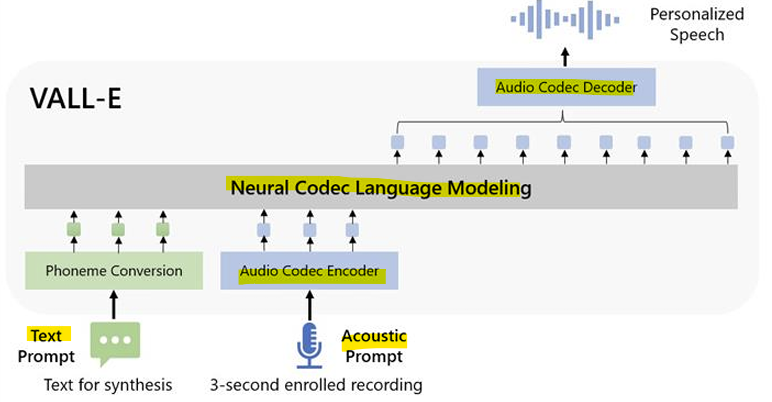
- Neural Codec Language Models
- 목표
: 인컨텍스트 학습(In-context Learning)을 위한 신경망 코덱 언어 모델 개발
: 신경망 코덱을 입력 및 대상 토큰으로 사용하여 언어 모델을 활용, 제로샷(Text-to-Speech) 모델에서 효과적인 인컨텍스트 학습을 가능하게 함
<동작 과정>
입력 변환:
입력 텍스트 또는 음성을 신경 코덱을 통해 코드(Token) 형태로 변환
예: 음성을 벡터화하여 언어 모델이 처리할 수 있는 시퀀스로 변환
언어 모델의 활용:
언어 모델은 입력 코드를 기반으로 출력 코드를 생성
이 과정에서 기존 언어 모델이 가진 맥락 학습 능력을 사용하여 음성 스타일, 발화 패턴 등을 학습 없이 처리
출력 복원:
언어 모델의 출력(생성된 코드)을 신경 코덱을 통해 복원하여 최종 음성 출력
- 결론
- GAN은 고품질의 파형 신호를 생성할 수 있음
-> GAN은 파형 생성 작업에서 Diffusion보다 더 나은 성능을 보임
<분석>
-
다양성(Diversity) VS 정확도(Fidelity)
-> Diffusion 모델은 더 높은 다양성을 가질 수 있음. 하지만 신경 보코더(Neural Vocoder)는 다양한 파형을 생성할 필요가 X
-> 다양한 판별기(Discriminators)는 파형 신호의 다양한 패턴을 모델링 가능 -
추론 속도(Inference Speed)
-> GAN 기반 모델은 반복적인 생성 과정 없이 바로 파형 신호를 생성할 수 있음 -
GAN: Diversity가 좋지만, 느림
-
Diffusion: Fidelity(정확도)가 좋지만
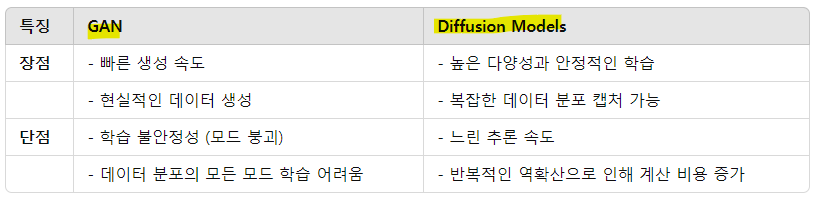
1) 생성 품질 (Fidelity)
GAN:
높은 정확도로 현실적인 데이터를 생성 가능
판별기(Discriminator)를 사용해 생성 데이터를 정교하게 개선
Diffusion:
안정적이고 정교한 생성이 가능하지만, 데이터에 따라 GAN보다 낮은 정확도를 보일 수 있음
2) 다양성 (Diversity)
GAN:
종종 모드 붕괴(Mode Collapse)가 발생하여 특정 데이터 유형만 생성
예: 특정 화자의 음성만 반복적으로 생성
Diffusion:
높은 다양성을 보이며, 데이터 분포의 모든 모드를 효과적으로 캡처 가능
