이제 드디어 머신러닝을 활용하여 생존자를 예측하는 모델을 만들어 본다.
먼저 머신러닝 데이터에는 문자열 데이터가 오는게 아닌 숫자형만 와야 하는데,
info() 를 찍어보니,
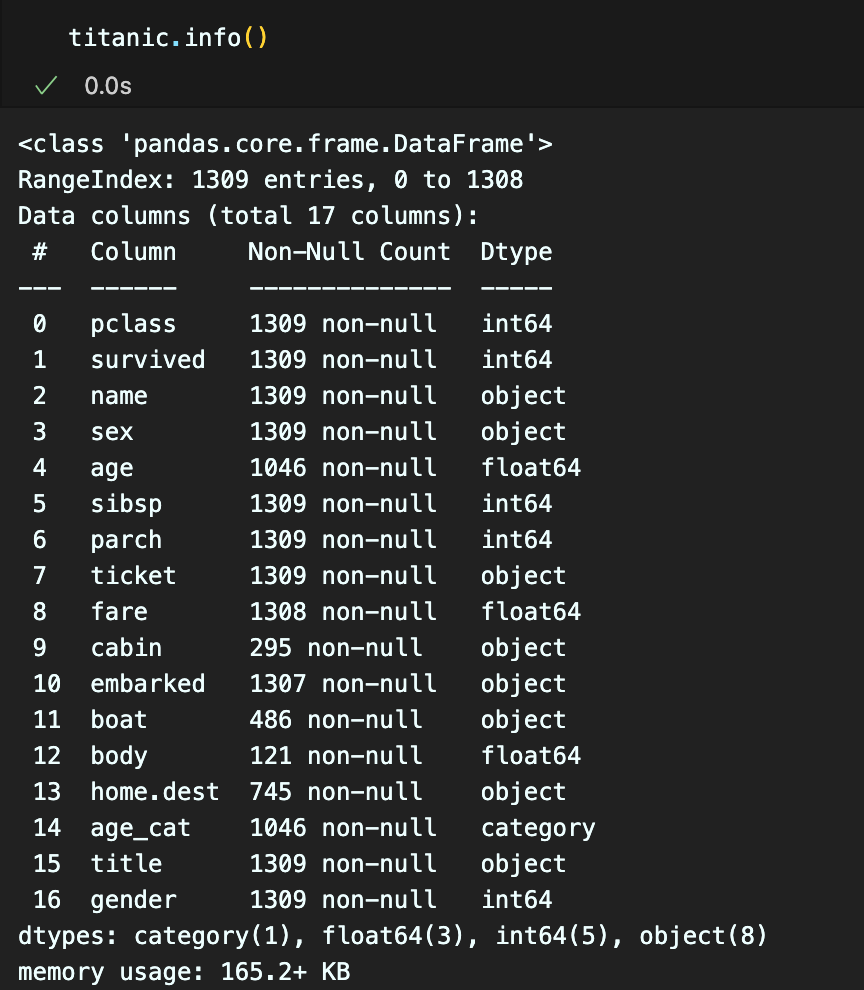
내가 사용 할 feature 인 sex가 문자로 되어있다.
그래서 이것을 형변환 해주기 위해 사이킷런에 labelencoder 를 사용해보겠다.
1. LabelEncoder
# 머신러닝을 이용한 생존자 예측
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(titanic['sex'])

labelencoder모델에 타이타닉의 sex값을 넣어서 학습을 돌렸다.
2. class 확인
le.classes_
array(['female', 'male'], dtype=object)
3. gender 변수 생성
titanic['gender'] = le.transform(titanic['sex'])
titanic.head()gender 라는 새로운 변수를 만들어 sex의 값을 0,1 로 나뉘어 지도록 했다.

4. 결측치 제거
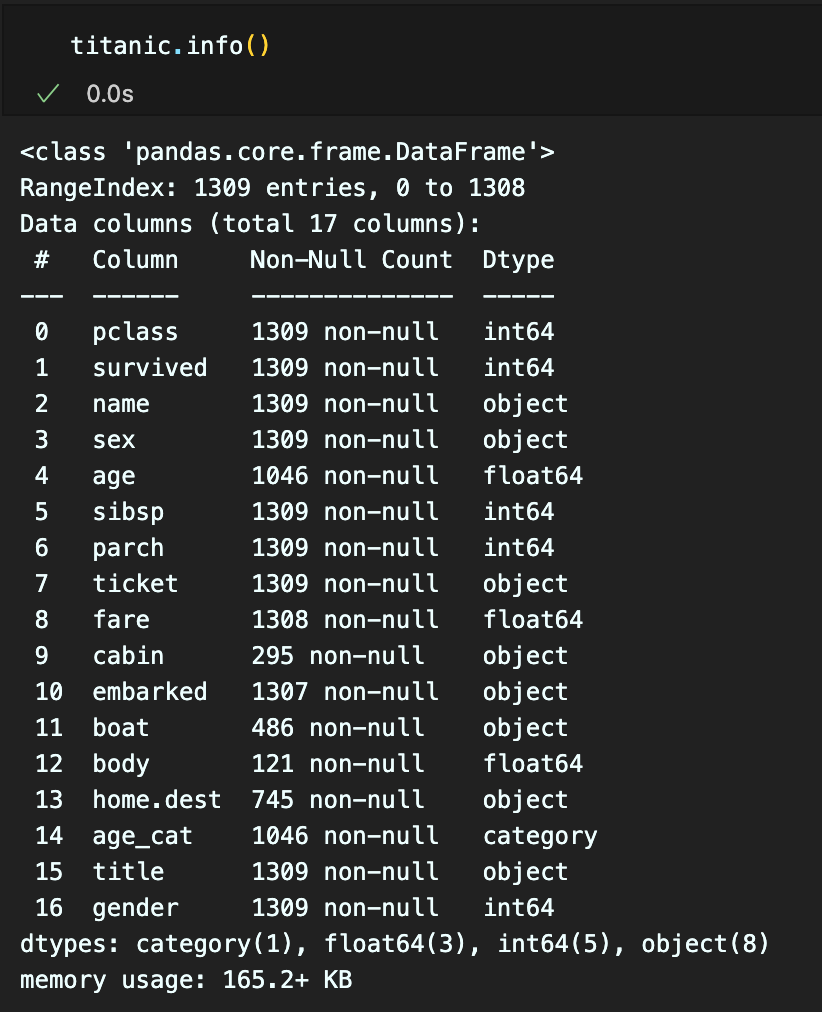
현재 age, fare 의 개수가 다른 변수에 비해 적은 수가 나온 것을 확인 할 수 있다.
그래서 지금은 Null값을 제거하는 식으로 진행을 하도록 한다.
titanic = titanic[titanic['age'].notnull()]
titanic = titanic[titanic['fare'].notnull()]
titanic.info()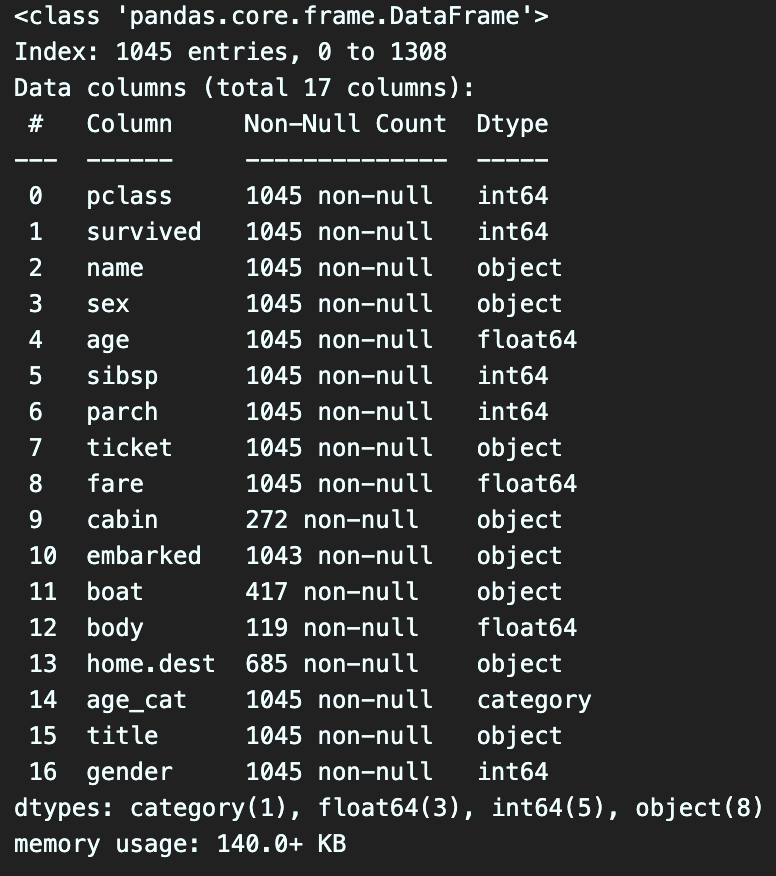
모든 값이 동일해 졌다.
데이터 나누기
데이터를 학습시키기 위해서 학습데이터 와 테스트데이터로 split 을 해보겠다.
from sklearn.model_selection import train_test_split
X= titanic[['pclass','age','sibsp','parch','fare','gender']]
y = titanic['survived']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.8, random_state=13)
학습진행
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier(max_depth=4, random_state=13)
dt.fit(X_train,y_train)DecisionTreeClassifier(max_depth=4, random_state=13)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeClassifier(max_depth=4, random_state=13)
예측
pred = dt.predict(X_test)
print(accuracy_score(y_test, pred))결과:
0.7655502392344498
디카프리오 생존 확률
import numpy as np
dica = np.array([[3,18,0,0,5,1]])
print('Dicarprio: ', dt.predict_proba(dica)[0,1])
Dicarprio: 0.22950819672131148로즈 생존 확률
winslet = np.array([[1,16,1,1,100,0]])
print('Winslet: ', dt.predict_proba(winslet)[0,1])
Winslet: 1.0: 정말 간단한 EDA와 예측주제를 가지고 해보았는데 과연 나는 이 정도의 난이도여도 혼자서 코딩을 짜고 진행할 수 있을지 생각이 들었다. 실력이 쌓이고 있는건지 늘 고민이 된다. 욕심은 나고 마음은 조급해서 그런 것 같기도 하다.
그래도 늘 초심을 잃지 않고, 겸손하게 배워나가야겠다. 그리고 모르는 것에 창피해 하지말고 알려고 하지 않는 것에 창피해 해야겠다. 또한 노력하지 않으면서 잘 하려고 하는 것을 창피해 해야겠다. 절대 포기 하지 않을 것 이다.
그냥 꾸준히 꾸준히 공부해 나가자. 화이팅 !
