Min-Max-Scaler / 정규화하기
1. 데이터프레임 만들기
#min-max scaling
df =pd.DataFrame({
'A' : [10,20,-10,0,25],
'B' : [1,2,3,1,0]
})
| A | B | |
|---|---|---|
| 0 | 10 | 1 |
| 1 | 20 | 2 |
| 2 | -10 | 3 |
| 3 | 0 | 1 |
| 4 | 25 | 0 |
2. min max scaler 로 학습시키기
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(df)mms.data_max_, mms.data_min_ , mms.data_range_(array([25., 3.]), array([-10., 0.]), array([35., 3.]))
3. transform 변환하기
df_mms = mms.transform(df)
df_mmsarray([[0.57142857, 0.33333333],
[0.85714286, 0.66666667],
[0. , 1. ],
[0.28571429, 0.33333333],
[1. , 0. ]])
4. 역변환
# 역변환
mms.inverse_transform(df_mms)array([[ 10., 1.],
[ 20., 2.],
[-10., 3.],
[ 0., 1.],
[ 25., 0.]])
역변환을 통해 데이터가 다시 돌아왔다.
5. fit + transfrom 한 번에 하기
mms.fit_transform(df)array([[0.57142857, 0.33333333],
[0.85714286, 0.66666667],
[0. , 1. ],
[0.28571429, 0.33333333],
[1. , 0. ]])
6. StandardScaler
표준화(StandardScaler)
: 데이터의 피처 각각이 평균이 0, 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 행위
표준화는 이상치(outlier)가 존재할 경우 이상치가 모델의 성능을 떨어뜨리는 경향이 있기 때문에, 이상치가 존재하는 데이터에 대해서는 사용이 제한적일 수 있습니다. 이 경우에는 다른 스케일링 기법을 사용하거나 이상치 제거 과정을 거쳐야 합니다.
* 참고 : train 데이터셋에서 특정 feature(columns)에 대해서 표준화를 적용하였다면, 동일한 feature(columns)에 대해서 test 데이터셋에도 동일한 표준화를 적용해야 합니다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(df)ss.mean_, ss.scale_(array([9. , 1.4]), array([12.80624847, 1.0198039 ]))
7. Robust Scaler
-> 평균과 분산대신, 중간값과 사분위 값을 조정
->아주 동 떨어진 데이터를 제거
*이상치: 측정된 데이터 사이의 경향성을 지나치게 해치는 데이터 ex)측정 에러
StandardScaler와 비슷 하지만 평균과 분산대신 중간값(median)과 사분위값(quartile)을 사용합니다.
이런 방식 때문에 RobustScaler 는 전체 데이터와 아주 동떨어진 데이터 포인트(예를 들면 측정 에러)에 영향을 받지 않고,
이런 이상 데이터를 이상치라고 하며 다른 스케일 조정 기법에서는 문제가 될 수 있습니다.
-> median 이 0 되는 것
# Robust Scaler 50% 지점을 1로
df = pd.DataFrame({
'A' : [-0.1 , 0., 0.1, 0.2, 0.3, 0.4, 1.0, 1.1, 5.0]
})
df
| A | |
|---|---|
| 0 | -0.1 |
| 1 | 0.0 |
| 2 | 0.1 |
| 3 | 0.2 |
| 4 | 0.3 |
| 5 | 0.4 |
| 6 | 1.0 |
| 7 | 1.1 |
| 8 | 5.0 |
from sklearn.preprocessing import MinMaxScaler , RobustScaler , StandardScaler
mm = MinMaxScaler()
ss = StandardScaler()
rs = RobustScaler()
df_scaler = df.copy()
df_scaler['MinMaxScaler'] = mm.fit_transform(df)
df_scaler['Standard'] = ss.fit_transform(df)
df_scaler['Robust'] = rs.fit_transform(df)
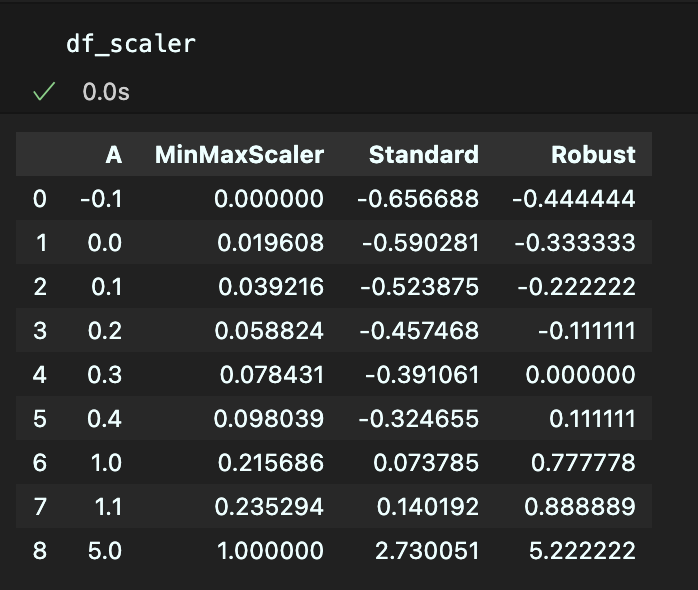
3가지 스케일링을 모두 적용해 보았다.
확실히 값의 차이가 있는 걸 보니, 계산되는 방식이 다르다는 걸 느꼈고
상황에 맞게 잘 사용해야겠다는 생각이 들었다.
시각화하기
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style='whitegrid')
plt.figure(figsize=(16,6))
sns.boxplot(data=df_scaler, orient='h');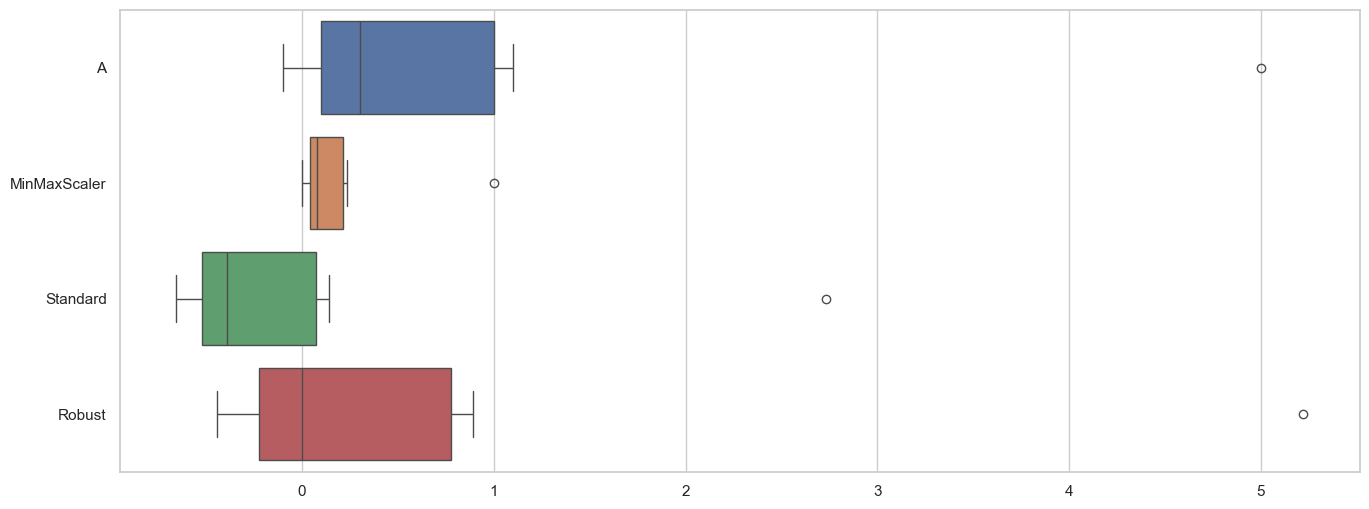
시각화를 통해 3가지 스케일러의 특성을 더 잘 볼 수 있다.
