kNN 알고리즘..!
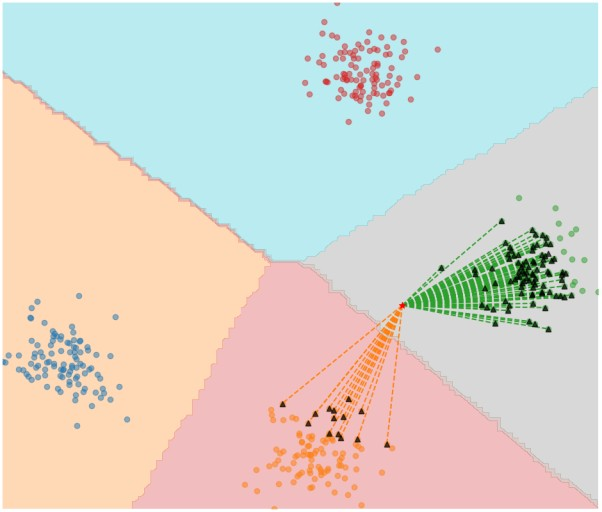
특징
- 새로운 데이터가 있을 때 기존 데이터의 그룹 중 어떤 그룹에 속하는지를 분류하는 문제
- K 는 몇 번째 가까운 데이터까지 볼 것 인가를 정하는 수치
- k 값에 따라 결과가 달라진다는 특징이 있다.
- 두 점 사이의 거리를 계산 하는 법은 유클리드 기하학이 가장 유명하다.

- 거리를 재는 특징인만큼 x,y축인 데이터의 특성의 표준화가 굉장히 중요하다.
- 이론적으로는 학습과정이 필요하지는 않다. (테스트 데이터만 가지고 할 수 있다.)
- 결국 속도는 빨라진다.
단점
- 거리를 계속 재야하는 것이 단점이다.
- 고차원 데이터에서는 적합하지 않다.
[실습]
iris _data
1. 데이터 불러오기 (사이킷런 데이터셋에서 지원)
from sklearn.datasets import load_iris
iris = load_iris()
2. 데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, stratify= iris.target, random_state=12)
knn 은 학습할 게 없어서 fit을 하지만 절차상 진행
3. 학습
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
KNeighborsClassifier()
4. 평가지표로 정확도 확인
from sklearn.metrics import accuracy_score
pred = knn.predict(X_test)
print('accuracy score: ', accuracy_score(y_test, pred))
accuracy score: 0.9777777777777777
5. confusion_matrix,
from sklearn.metrics import confusion_matrix, classification_report
confusion_matrix(y_test, pred)
#참값과 예측값을 비교하여 오차행렬을 만들어준다.
array([[15, 0, 0],
[ 0, 14, 1],
[ 0, 0, 15]])
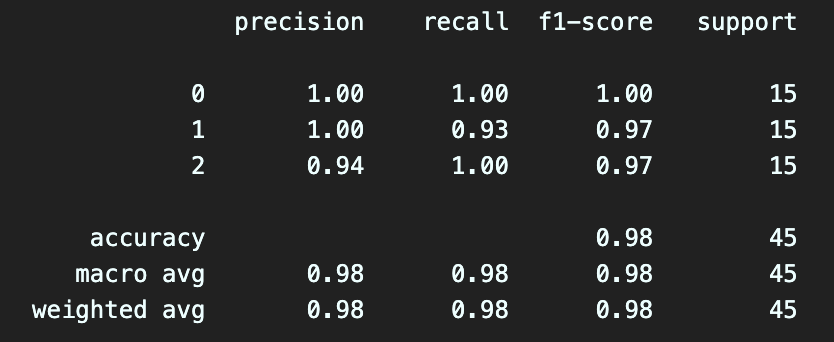
6. classification_report
print(classification_report(y_test, pred))
#정밀도, 재현율, f1-score, 지지도를 출력해준다.
kNN은 프로젝트를 진행할 때 많은 역할이 요구되기 때문에 간단한 개념 정도만 익히고 넘어가고자 한다.

Analytics Engineer