💡 Backward propagation
Algorithm based on the chain rule
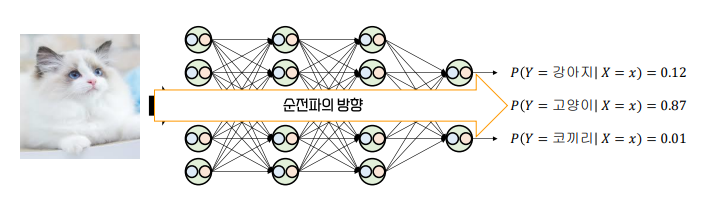
🥨 Forward Propagation
Data is propagated from the input layer to the output layer, with calculations occurring at each neuron.
-
Transmission of input data: The input data is passed to the input layer of the neural network, typically in the following form:
- Here, is the number of input features.
-
Linear Transformation: The neurons in each layer perform a linear transformation by receiving the output of the previous layer. This transformation is calculated by taking the dot product of the weights with the input and adding the bias:
- In the first hidden layer,
- : Linear transformation result (pre-activation value) of the -th layer.
- : Weight matrix of the -th layer.
- : Activation (output) of the previous layer.
- : Bias vector of the -th layer.
-
Application of Activation Function: An activation function is applied to the result of the linear transformation, adding non-linearity and generating the output to be passed to the next layer.
-
Prediction Calculation at Output Layer: In the output layer, a suitable activation function is chosen based on the problem type to generate the final predicted values.
- Regression problem: Linear output or identity function is used without an activation function.
- Binary classification problem: Sigmoid function is used to convert the output to probability values.
- Multiclass classification problem: Softmax function is used.
-
Loss Function Calculation: The predicted value is compared with the actual value .
- For regression problems: MSE (Mean Squared Error).
- For binary classification problems: Cross-Entropy Loss.
- For multiclass classification problems: Multiclass Cross-Entropy Loss.
🥨 Chain Rule
-
Definition: A method to calculate the derivative of a composite function.
-
Assume function is a function of the variable , and is a function of the variable :
-
Here, is a composite function of : . According to the chain rule, the derivative of with respect to is expressed as:
-
In other words, the derivative of the composite function is the product of the derivative of with respect to the intermediate variable and the derivative of with respect to .
-
-
Chain Rule with Multiple Variables
-
Assume is a function of two variables and , and and are functions of :
-
In this case, the chain rule states that the derivative of with respect to is:
-
This means that the total derivative is found by summing the products of the partial derivatives of with respect to each variable and the derivative of each variable with respect to .
-
🥨 Backward propagation
-
Definition
- The process of calculating the gradients of each weight by propagating the error from the output layer back through the hidden layers to the input layer.
- Chain rule is used to compute the gradients at each layer.
-
Applying Chain Rule in a Single Layer
-
In a multilayer perceptron, the linear transformation in the -th layer is defined as:
- : Output (activation) of the previous layer
- : Weight matrix of the -th layer
- : Bias vector of the -th layer
-
The activation value of the -th layer is calculated using the activation function :
- Loss function : The difference between the predicted value and the actual value from the output layer.
-
Backpropagation involves calculating the gradient of each weight with respect to the loss .
-
-
Role of Chain Rule in Backpropagation
-
The gradient of the loss function with respect to the weight in the -th layer using the chain rule:
- : The gradient of the loss function with respect to the activation value in the -th layer (which is related to the error passed from the next layer).
- : The derivative of the activation function.
- : The derivative of the linear transformation with respect to the weight, which is the activation value from the previous layer.
-
The gradient of the loss function with respect to the bias in the -th layer using the chain rule:
- Since , the gradient with respect to the bias is the same as the error in the -th layer:
- Since , the gradient with respect to the bias is the same as the error in the -th layer:
-
-
Error Propagation in Backpropagation
- Error Calculation at Output Layer: After calculating the derivative of the loss function, this value is used to compute the gradients of the weights and biases in the output layer.
- The error at the output layer is defined as:
- : The predicted value from the model.
- : The actual value.
- Error Propagation to Hidden Layers: To propagate the error to the hidden layers, use the chain rule to compute the error at each layer. The error at the -th layer is calculated by multiplying the error from the -th layer by the weight matrix:
- : The derivative of the activation function at the -th layer.
- Updating Weights and Biases Across All Layers: After calculating the error and gradients for each layer, the weights and biases are updated using gradient descent.
- Weight update:
- Bias update:
- : Learning rate.
