💡 Optimizer
An algorithm to minimize the Loss Function
🥨 Gradient Descent
-
Definition: A method to find the minimum value of a given function (usually a Cost function or Loss function) using its gradient.
- When a function is given, the goal is to find its minimum value -> Gradient Descent calculates the gradient and moves in the opposite direction of the gradient.
-
Formula
- In the formula, is called the learning rate, which determines how much the parameters should be updated in one iteration, i.e., how much to adjust the parameter value.
- This formula represents one iteration of the update, and in practice, this step is repeated multiple times.
-
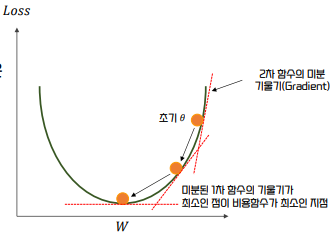
Example
- If the loss function is a parabolic second-order function like the figure below, Gradient Descent applies differentiation from the initial , and then sequentially updates in the direction where the gradient of the function decreases.
- Finally, it returns the value of at the point where the gradient no longer decreases, which is considered the point where the loss function is minimized.
🥨 Stochastic Gradient Descent
-
Definition: Unlike standard Gradient Descent, which calculates the gradient over the entire dataset and updates the weights at once, SGD calculates the gradient for a single data point at a time and updates the weights immediately.
-
SGD Update Formula
- : The parameter to be learned.
- : Learning rate, which determines how much the parameter moves during one update.
- : The gradient of the cost function for the -th data point .
-
Operation Process
- Initialization: Randomly initialize the model's weight .
- Random Sample Selection: Randomly select one sample from the dataset.
- Gradient Calculation: Calculate the gradient of the loss function for that sample.
- Weight Update: Use the gradient to update the weight .
- Repeat: Repeat this process until all samples in the dataset are processed, and the training is performed over multiple epochs.
-
Disadvantages
- Oscillation and Instability: Since the gradient is calculated for random samples, the weight updates can be inconsistent and oscillate, which may slow down convergence.
- Difficulty in Ensuring Convergence: Unlike standard Gradient Descent, the convergence of the loss function is not always guaranteed and can be unstable, so proper adjustment of the learning rate is crucial.
🥨 Mini-Batch Gradient Descent
-
Definition: A method that divides the entire dataset into small batches and calculates the gradient for each mini-batch to update the weights.
- Each mini-batch is composed of randomly selected samples from the entire dataset.
- The gradient of the loss function is calculated using this mini-batch, and the weights are updated.
-
Mini-Batch Gradient Descent Update Formula
- : Weight vector of the model.
- : Learning rate.
- : A set of data samples in the mini-batch.
- : Size of the mini-batch.
- : Gradient of the loss function for the sample .
-
Operation Process
- Initialization: Randomly initialize the model's weights .
- Dataset Division: Divide the entire dataset into small mini-batches, each mini-batch consisting of data points.
- Mini-Batch Selection: Select one mini-batch and calculate the gradient.
- Gradient Calculation: Calculate the gradient of the loss function for all data points in the mini-batch and compute the average of the gradients.
- Weight Update: Update the weights using the average gradient from the mini-batch (using the formula above).
- Repeat: Repeat this process until all mini-batches in the dataset have been processed, and training is performed over multiple epochs.
-
Disadvantages
- Noise Issues: If the mini-batch size is too small, the gradient may oscillate like in SGD, causing slower or unstable convergence.
- Impact of Mini-Batch Size: If the mini-batch size is too large, it may use too much memory and slow down learning like Batch Gradient Descent. If too small, it may cause noisy and unstable learning.
- Computational Complexity: If hyperparameters are not set correctly, the learning process can be unstable or inefficient.
🥨 Momentum
-
Definition: Instead of simply moving in the direction of the gradient, Momentum adds acceleration by partially reflecting the gradient information from the previous step.
- It increases speed in flat regions and reduces oscillation in regions where the gradient changes sharply.
-
Momentum Update Formula: The previous step's update is treated as an acceleration.
-
Velocity calculation:
-
Weight update:
- : Velocity, representing the direction of weight update.
- : Momentum coefficient, determining how much of the previous gradient is reflected.
- : Learning rate.
-
-
Features of Momentum
- When Gradient Descent reaches flat regions of the loss function, the gradient becomes small, and weight updates slow down. Momentum maintains speed in such cases, enabling faster convergence by using the previous gradient.
- Proper setting of the momentum coefficient and learning rate is crucial.
🥨 RMSprop
-
Definition: RMSprop calculates the moving average of the squared gradients and adjusts the learning rate based on the magnitude of the gradients.
- It makes the size of each weight update inversely proportional to the size of the gradient.
- Helps maintain a stable learning rate when the gradient magnitude varies significantly during training, particularly effective in mitigating the vanishing gradient problem.
-
RMSprop Update Formula: The exponential moving average (EMA) of the squared gradient is calculated, and this is used to adjust the learning rate.
-
EMA of squared gradients calculation:
- : Exponential moving average of the squared gradient at time step
- : The current gradient
- : The decay rate of the exponential moving average, typically set to 0.9
-
Weight update:
- : Learning rate
- : A small constant for numerical stability, usually set to to prevent division by zero
- : The current gradient
-
As shown in the formula, the larger the gradient, the smaller the learning rate becomes, and the smaller the gradient, the larger the learning rate. RMSprop dynamically adjusts the learning rate to perform appropriate weight updates.
-
-
Disadvantages:
- Complex Hyperparameter Tuning: Proper tuning of and is crucial.
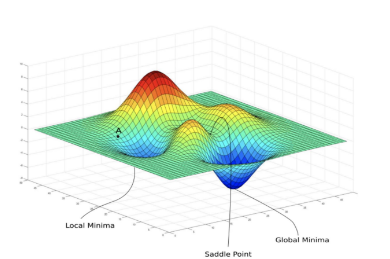
- Difficulty in Moving Toward Global Minimum: If it converges too quickly at the start of training, there is a risk of getting stuck in a local minimum.
🥨 Adam
-
Definition: Adam is a combination of Momentum and RMSprop.
- Adam uses separate learning rates for each weight and adaptively adjusts them while applying momentum to account for the direction of the gradients.
- Adam updates the weights using two EMA estimates:
- First Moment: The mean of the gradients, capturing the direction of the gradients through momentum.
- Second Moment: The squared gradients, adjusting the learning rate based on gradient magnitude, similar to RMSprop.
-
Adam Update Process:
-
First Moment Estimate:
The EMA of the gradient (first moment) is calculated as:- : Exponential moving average of the first moment (mean) of the gradient
- : Decay rate for the first moment, typically set to 0.9
- : The current gradient
-
Second Moment Estimate:
The EMA of the squared gradient (second moment) is calculated as:- : Exponential moving average of the second moment (variance) of the squared gradient
- : Decay rate for the second moment, typically set to 0.999
- : The square of the current gradient
-
Bias-Correction: At the early stages of Adam, the estimates for and are biased toward 0, so bias correction is applied:
-
Bias correction for the first moment:
-
Bias correction for the second moment:
-
-
Weight Update: The weights are updated using the bias-corrected moment estimates:
- : The current weight
- : Learning rate
- : A small constant for numerical stability, typically set to to prevent division by zero
- : Bias-corrected first moment (mean of the gradients)
- : Bias-corrected second moment (variance of the gradients)
-
