💡 Decision Tree
- Tree-based classification rules that automatically discover patterns in data through learning
- On what criteria should the data be based to create the most efficient classification rules?
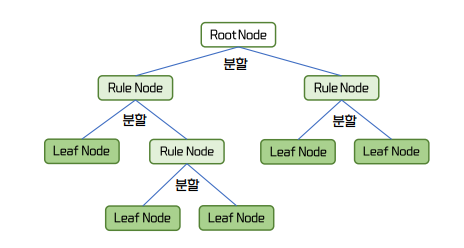
Decision Tree Components
- Node : The point at which the data is split
- Root Node : Located at the top of the tree, the starting point of tree splitting.
- Internal Node : Nodes branched from the root node, providing additional splitting criteria.
- Leaf Node : The final node of the tree that is not split any further.
- Branch : Connections between nodes, with each branch representing a splitting condition.
- Splitting Criteria : The rule for dividing data at each node.
- Depth : The maximum path length from the Root Node to the Leaf Node.
- The deeper the tree, the more complex it becomes, increasing the risk of overfitting.
- If the tree is shallow, it becomes too simple and may not adequately represent the data.
Node creation process
- Root node selection : Set the root node to include all the data
- Determine the optimal splitting criterion : Select the attribute that best splits the data based on specific criteria (e.g., Gini Impurity, Entropy, etc.)
- Data splitting : Split the data based on the selected attribute and create new nodes
- Iteration : Repeat the above process on the split data to create lower nodes. If further splitting is not possible or predefined conditions (e.g., max_depth, min_samples, etc.) are met, create a Leaf Node
Uniformity-based rule conditions
- Gini Impurity
- a measure of the degree of mixture within a dataset
- A smaller value indicates that the data is more uniformly distributed
- formula
- presents the proportion of clss
- Entropy
- A measure of the degree of mixture within the data
- A larger value indicates that the data is distributed across a variety of classes
- formula
- Information Gain
- Calculate the difference in entropy before and after the split, and choose the splitting criterion with the highest information gain
- formula
- Variance Reduction
- Primarily used in regression trees, it calculates the difference in variance before and after the split
- Choose the criterion with the largest variance reduction
Main Hyperparameters
- Max Depth : Set the maximum depth of the tree to prevent it from becoming too deep and overfitting
- Minimum Samples
- Minimum Samples Split : The minimum number of samples required to split a node
- Minimum Samples Leaf : The minimum number of samples required to be in a leaf node
- Max Features : The maximum number of features (attributes) to consider when making a split
- Pruning : The process of reducing the branches of the tree to prevent overfitting
- Post-Pruning
- Pre-Pruning
Decision Tree Model Using Iris
Decision Tree Model Code Example Using the Iris Dataset
# Import the necessary libraries
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Create and train the decision tree model
clf = DecisionTreeClassifier(random_state=0)
clf.fit(X, y)
# Visualize the decision tree
plt.figure(figsize=(20,10))
tree.plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()
Data Analysis