New Features
여러개 feature를 하나로 합쳐서 새로운 feature로 이용할 수 있음. 새로윤 feature x1 은 기존의 feature들의 곱의 형태로 정의할 수도 있다.
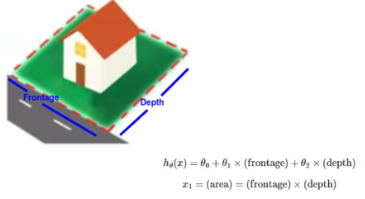
Polynomial(다항) Regression
Hypothesis function이 반드시 리니어해야 하는 것은 아니다. 데이터에 잘 fit하는 형태로 나타내면 된다. Polynomial Regression은 입력 feature의 거듭제곱(새로운 feature를 만드는 것은 거듭제곱이 아니어도 되지만 보통 Polynomoial Regression에서는 거듭제곱)을 이용해서 비선형 관계를 모델링 하는 회귀 방법으로 모델 자체는 여전히 선형 회귀 구조이다.
Polynomial Regression이 선형인 것은 에 대해 선형이기 때문
Validation 예제
-
torch.np_grad(): 작은 모델에서는 차이를 만들지 않지만, validation inner loop를 context manager로 감싸서 gradient calculation을 방지하는 것이 좋다.
-
eval(): model을 evaluation mode로 설정
for epoch in range(n_epochs):
for x_batch, y_batch in train_loader:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
loss = train_step(x_batch, y_batch)
losses.append(loss)
with torch.no_grad():
for x_val, y_val in val_loader:
x_val = x_val.to(device)
y_val = y_val.to(device)
model.eval()
yhat = model(x_val)
val_loss = loss_fn(yhat, y_val)
val_losses.append(val_loss.item())Normal Equation
최소값을 직접 계산 하는 공식. 선형회귀의 cost fucntion을 미분하고 0으로 두어 계산
차이점:
| 항목 | Gradient Descent | Normal Equation |
|---|---|---|
| 방식 | 반복 계산 | 한 번에 계산 |
| learning rate | 필요 | 필요 없음 |
| iteration | 필요 | 없음 |
| 계산 방법 | gradient 사용 | 행렬 역행렬 사용 |
| 데이터 많을 때 | 유리 | 매우 느림 |
Gradient descent를 더 많이 사용하는 이유는 행렬 크기가 n x n이면 계산량이 O(n3)로 너무 많아질 수 있기 때문
- 주의 - Normal Equation은 역행렬이 존재해야 하는데 어떤 경우에는 존재하지 않음
Logistic Regression
선형회귀(Linear Regression)는 주어진 특징(feature)을 바탕으로 연속적인 목표 값을 예측하는 방법인 반면에, 분류(Classification)는 주어진 특징에 따라 데이터를 이산적인 클래스에 분류하는 방법.
Binary Classification
Binary Classification에서는 y가 0 또는 1의 값을 갖는다.
- 0은 nagative class
- 1은 postive class
Logistic regression의 hypothesis function은 0과 1 사이의 값만 내보내는 형태가 되도록:
위의 조건을 만족하며 미분 가능한 함수의 예)
- sigmoid fuction, or logistic function
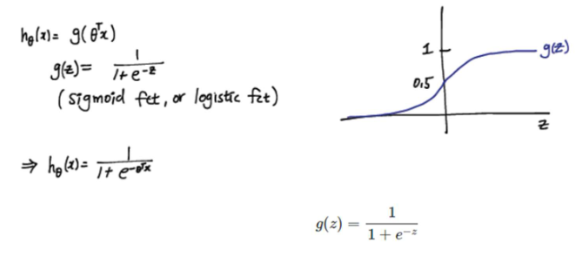
sigmoid function/logistic function
z에 x에 관한 함수를 넣어 hypothesis로 만들 수 있다. Linear regression hypothesis인 를 대입하는 것으로 시작해 보자.
=
Hypothesis function의 출력값은 '주어진 feature가 x라는 값을 가질 때 class1에 들어갈 확률'이라는 의미를 갖는다.
y=1 (class 1)일 확률과 y=0 (class 0)일 확률은 합이 1이 되어야 함
P(y=0|x;) + P(y=1|x;) = 1
= 0.7 이란 output이 1일 확률이 70% 0일 확률은 30%
Decision Boundary
Decision Boundary는 y=0 과 y=1을 가르는 경계선
Decision Boundary는 에 의해 결정되는 것으로 Training data는 Parameter를 결정하는 데에 이용될 뿐, decision boundary에 직접적으로 영향을 미치지는 않는다.
Non-Linear Decision Boundaries
Linear하지 않은 데이터에 대해서 class를 구분하려면?
한 가지 방법은 Polynomial 하게 feature dimension을 높이는 방법이 있다.
예)
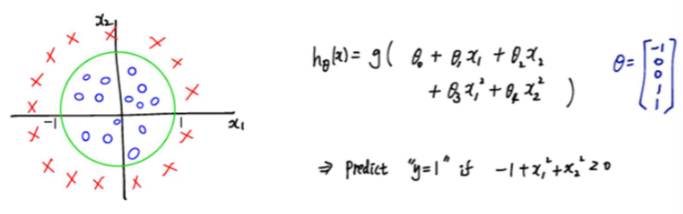
sigmoid function의 input을 원의 방정식으로 대체하여 데이터에 적절한 hypothesis를 만들 수 있다.
비용함수와 경사하강
Linear regression에서는 LSE criteion을 사용했는데 이 것을 logistic regression에 그대로 사용할 수 있을까?
에 를 대입하면 될 것 같기도 하다. 그러나 그 경우, cost function이 non-convex function(볼록하지 않은 함수 - 여러개의 봉우리와 골짜기를 가진 함수)이 된다. 그리고 이러한 함수는 Local optima에 빠질 수 없다는 문제가 있다. 그렇기 때문에 logistic regressiond의 cost function은 다르게 정의한다.
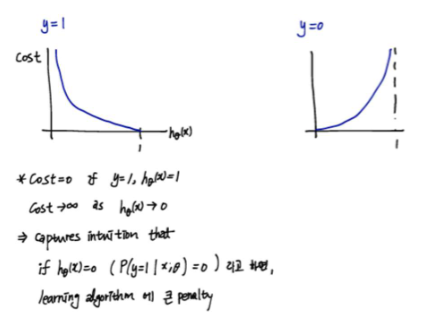
만약 y=1일 확률을 알아내려고 한다고 가정하면,
왼쪽 그래프 (y = 1인 경우)
실제 정답이 1일 때
x축: (예측 확률)
y축: cost (손실)
= 1 -> 완벽하게 맞춤 -> cost = 0
= 0 -> 완전히 틀림 -> cost가 무한대 (엄청 큰 패널티)
(y=0인 경우는 오른쪽 그래프)
왜 로그를 사용하나
정답이 나올 확률을 최대화하려는 것이 로지스틱 회귀인데, 데이터가 여러개일 경우 확률을 전부 곱하면 값들이 계속 작아져서 거의 0이 될 수 있고, 미분이 어렵다는 문제가 있을 수 있다.
그렇기 때문에 곱을 로그로 바꾸는 것
log(ab) = log a + log b
머신러닝은 보통 손실을 최소화하는 형태를 취하므로
Loss = - log P(y|x)
Logistic regression은
이 cost function의 특징은,
- Maximum likelihood estimation criterion
- Convex
이제 최적의 parameter 를 찾으려면 를 구하고, 그 후에 주어진 새로운 값을 어떤 class에 넣을지 판단하려면
가 0.5보다 큰지 작은지를 확인하면 된다.
Multi-Class Classification
class를 여러가지로 나눠야 하는 경우에는 binary classifier 로는 부족하다.
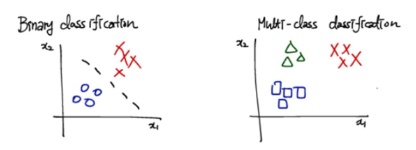
그 때 한 가지 방법이 각 class 별로 해당 class vs 나머지 class로 binary decision을 내리도록 만들고 hypothesis function 값이 가장 큰 것을 고르는 것이다.
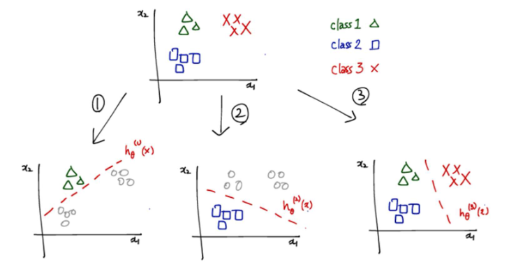
One-vs-ALL 또는 One-vs-Rest는 다중 클래스 분류 문제를 해결하는 한 가지 방법으로, 이 방법은 각 클래스에 대해 해당 클래스와 나머지 모든 클래스를 비교하는 이진 분류(binary decision)을 수행한 후, 각 클래스의 가설 함수(hypothesis function) 값이 가장 큰 클래스를 선택하는 방식
-
각 클래스마다 확률을 따로 계산한다.
class i에 들어갈 확률 P(y=i)를 구하기 위해 regression classifier 를 train 한다.
클래스가 만약 3개라면:
- 모델1: 이거 class 1인가?
- 모델2: 이거 class 2인가?
- 모델3: 이거 class 3인가?
이렇게 3개의 로지스틱 회귀 모델을 따로 학습
(각 모델은 한 개의 class인가 아닌가를 판정하는 것으로 학습) -
새로운 데이터 (x)를 받으면, 가 최대인 class i를 선택한다. 즉,
- 각 모델이 확률을 출력하고, 그 중에서 가장 큰 값의 class로 판정
- 각각 따로 학습했기 때문에 확률의 합이 1이 아닐 수 있다.
