last modified 24.4.15. by sooh-JLXMERT
Vision-and-language reasoning에서는 각 모달리티에 대한 이해 뿐만 아니라, 두 모달리티 간의 alignment와 관계를 파악하는 것이 중요하다.
LXMERT 이전의 연구들은 대부분 single modality에만 중점을 두고 있었다. 이에 논문에서는 vision과 language의 두 모달리티를 연결짓는 cross-modality framework인 LXMERT를 제안한다.
LXMERT는 이미지를 위한 object relationship encoder, 텍스트 표현을 위한 language encoder, 그리고 두 모달리티 간의 관계를 파악하기 위한 cross-modality encoder의 총 3가지 Transformer encoder로 구성되어 있으며, vision, language, 그리고 cross-modal에 대한 총 5가지 task로 pre-train되어 SOTA 성능과 일반화 능력을 갖는다.
LXMERT : Model Architecture
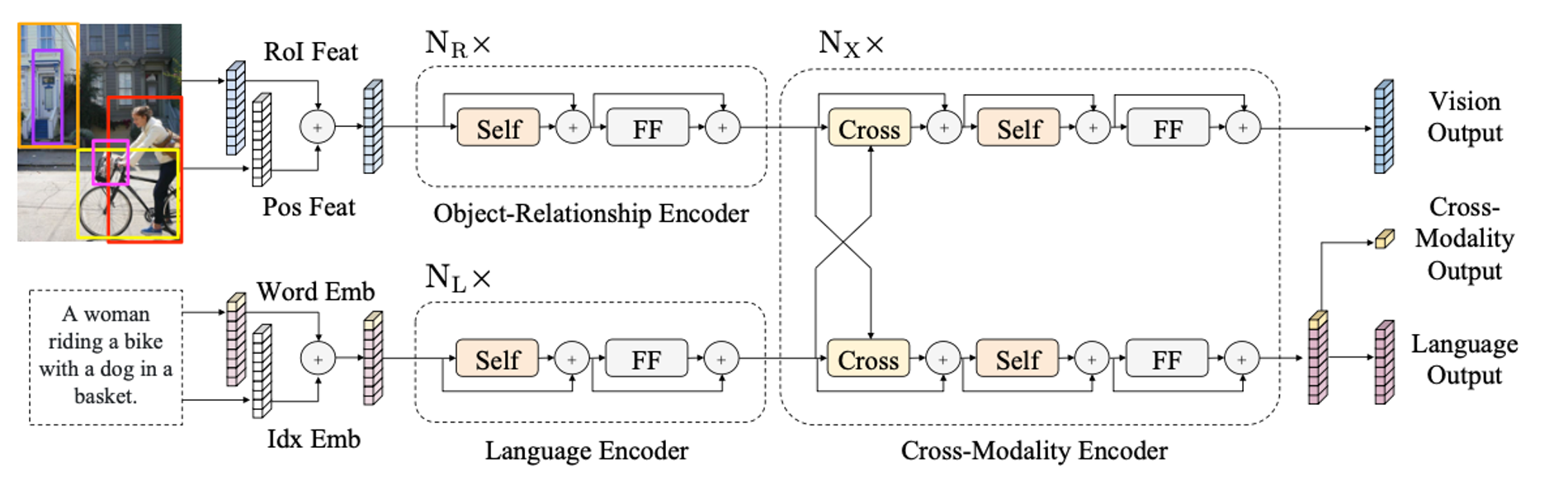
이미지와 텍스트는 각각 embedding layer를 통해 임베딩으로 계산된 후, 각자의 encoder를 통과한 후, cross-modality encoder에서 fusion된다.
Embedding layers
Word-Level Sentence Embeddings
입력 문장은 먼저 단어들로 쪼개지고, 워드 임베딩과 위치 임베딩의 합으로 계산된다.
Object-Level Image Embeddings
이미지에서는 CNN에서 feature map을 추출하는 대신, 검출된 object의 feature들을 이미지의 임베딩으로 사용한다. 이미지에서 m개의 object를 검출하고, 각 object의 위치 정보와 합쳐져 계산된다.
Encoders
Single-Modality Encoders
각 모달리티의 임베딩은 각각의 single-modality encoder를 거친다. 각 single-modality encoder는 self-attention sub-layer와 feed-forward sub-layer로 구성되어 있다. sub-layer를 통과할 때마다 residual connection과 layer normalization이 진행된다.
object-relationship encoder는 개, language encoder는 개의 동일한 인코더가 반복된다.
Cross-Modality Encoder
두 single-modality encoder에서 출력된 값은 공통의 cross-modality encoder에 입력된다.
- Cross-attention layer 각 모달리티는 bi-directional cross-attention sub-layer를 통해 두 모달리티의 alignment를 학습한다.
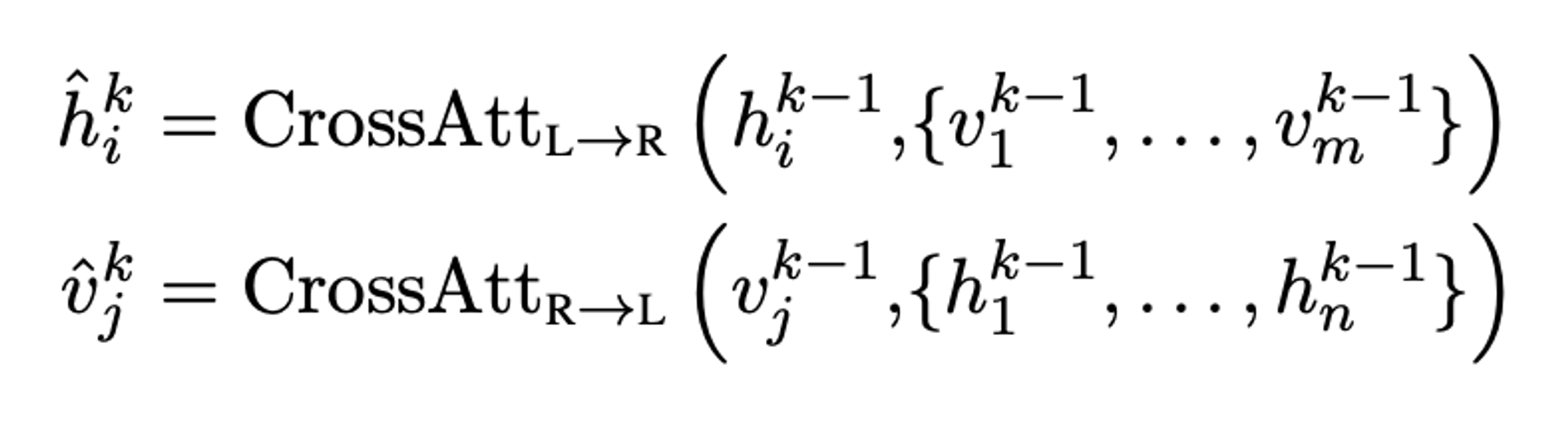 수식에서 language feature인 를 보면, 이전 단계의 language feature와 이전 단계의 모든 object에 대한 image features를 cross attention을 진행해 얻게 된다. image feature도 동일하게 이전 단계의 image feature와 이전 단계의 모든 단어에 대한 language feature를 가지고 cross-attention을 진행해 얻는다.
수식에서 language feature인 를 보면, 이전 단계의 language feature와 이전 단계의 모든 object에 대한 image features를 cross attention을 진행해 얻게 된다. image feature도 동일하게 이전 단계의 image feature와 이전 단계의 모든 단어에 대한 language feature를 가지고 cross-attention을 진행해 얻는다.
- Self-attention layer
cross-attention layer 다음에, 각 모달리티의 self-attention layer를 거치게 된다.
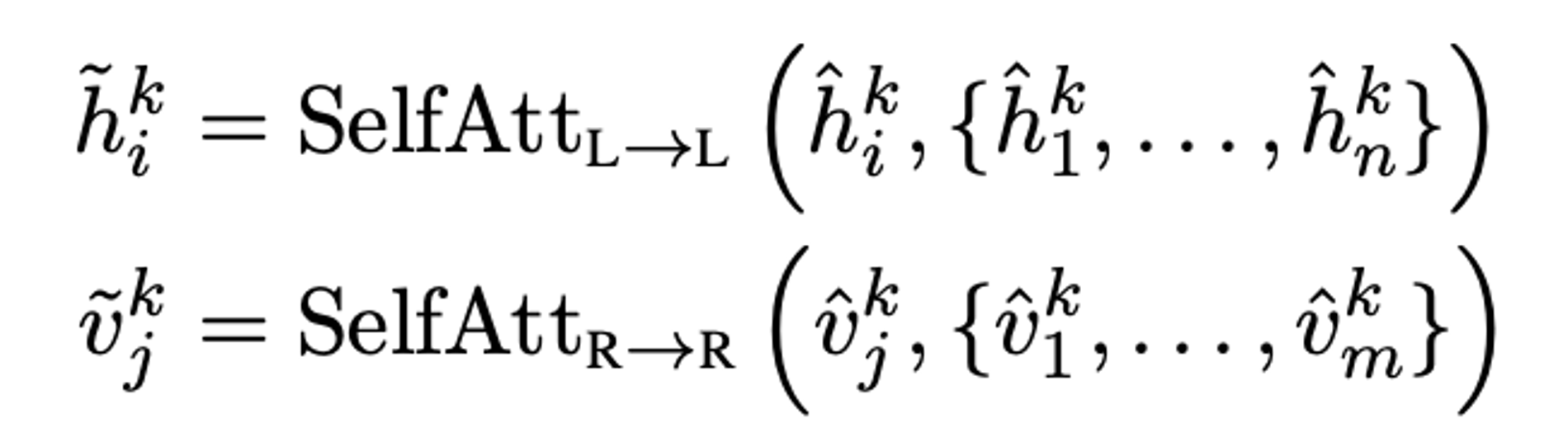
- Feed-forward layer
attention의 두 단계를 통과한 출력은 feed-forward sub-layers를 거친다.
Cross-Modality Encoder도 single-modality encoder와 동일하게 각 sub-layer를 통과할 때마다 residual connection과 layer normalization이 진행된다.
Cross-Modality Encoder은 아래의 3가지 출력을 가진다.
- Language output & Vision output
각 모달리티의 정보를 가진 feature sequences이다.
- Cross-modality output
language feature sequences 에서 special token인 [CLS]를 추출하여 사용한다.
Pre-training Strategies
LXMERT는 Language, Vision, Cross-Modality 각각의 tasks에 대해 pre-training을 진행한다.
Language Task : Masked Cross-Modality LM
언어 표현을 학습하기 위해 LXMERT는 BERT에서 사용한 방법인 Masked Language model task를 사용한다. 이 task에서는 단어들의 15%를 랜덤하게 마스킹 처리하고, 모델이 그 마스킹된 단어를 예측한다.
BERT에서는 마스킹된 단어를 예측할 때 language context만 사용하지만, LXMERT는 visual information도 함께 고려한다. 기존의 BERT의 pre-trained parameter는 언어 정보만을 가지고 학습되었기 때문에, 다른 모달리티와의 연결이 부족하다. 따라서 LXMERT에서는 BERT의 pre-trained parameter를 사용하기보다 랜덤 초기값에서 학습을 진행한다.
Vision Task : Masked Object Prediction
Language task에서 단어를 무작위 마스킹한 것처럼, Vision task에서는 이미지 내 객체의 15%를 랜덤으로 마스킹 처리하고 예측한다.
- RoI-Feature Regression
- Faster R-CNN을 통해 검출한 객체에서 RoI의 visual feature를 예측
- vision 정보를 예측하는 과정에서 object relationship을 학습
- Detected-Label Classification
- Faster R-CNN을 통해 검출한 객체의 종류를 예측
- language 정보를 예측하는 과정에서 cross-modality alignment를 학습
Cross-Modality Tasks
- Cross-Modality Matching 50%의 확률로 각 문장을 이미지와 맞지 않는(mis-matched) 문장으로 변경한다. 그 후 이미지와 문장이 match하는지 여부를 예측한다.
- Image Question Answering (QA) 이미지를 기반으로 질문에 대한 대답을 예측한다.
예측을 진행할 때에는 이미지-질문이 match할 때에만 답변을 출력한다.
Pre-training Procedure
Dataset
- captioning :
MS COCO,Visual Genome - image QA :
VQA v2.0,GQA(balanced version),VG-QA - size : 9.18M image-and-sentence pairs.
Pre-training
- input sentences → WordPiece tokenizer
- input images → (frozen) Faster R-CNN
- Faster R-CNN에서 101-layer를 사용하기 때문에, language encoder가 visual encoder보다 더 많은 layer를 갖도록 한다.
- Encoders와 embedding layer의 경우, BERT의 pre-trained parameter를 사용하지 않고 처음부터 학습을 진행 (이유: 기존의 BERT의 pre-trained parameter는 언어 정보만을 가지고 학습되었기 때문에, 다른 모달리티와의 연결이 부족하기 때문)
Evaluation
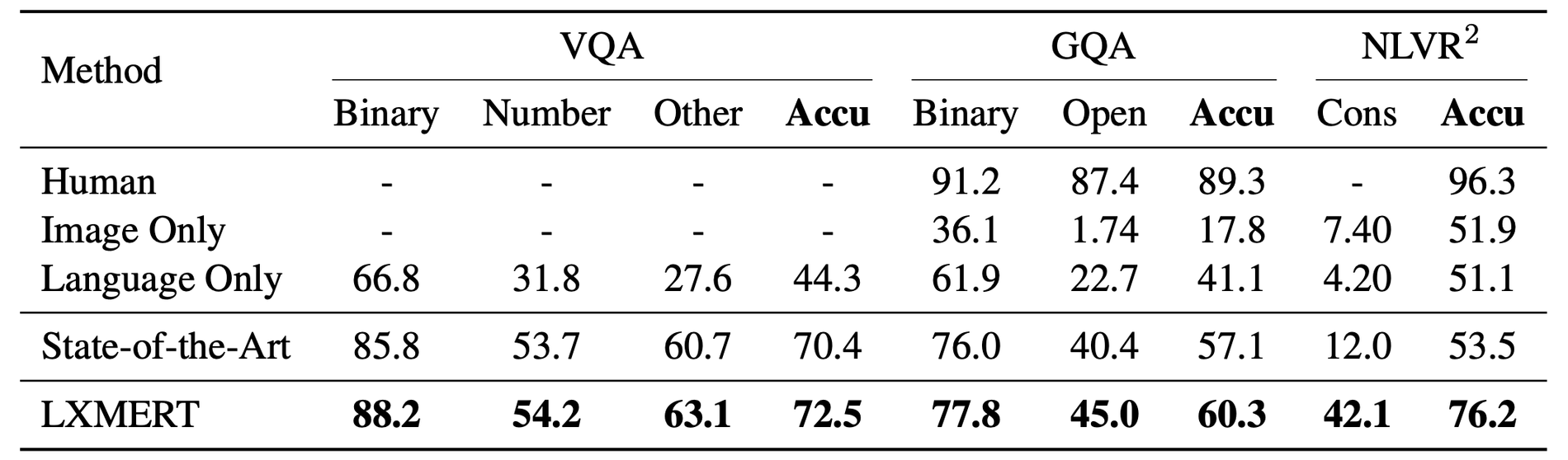
- Visual Question Answering
- dataset :
VQA v2.0,GQA - test dataset에 대해 data augmentation없이 finetuning 진행
- LXMERT가 기존 SOTA 모델들(VQA :
BAN+Counter, GQA :BAN)을 제치고 SOTA 달성. - 특히 GQA의 open-domain question에 대해 기존 SOTA모델 보다 4.6%나 향상된 성능.
- dataset :
NLVR^2- 두 이미지 에 대한 language statement 에 대한 image-statement pair를 각각 만들고 classifier를 학습시킴.
- LXMERT가 기존 SOTA 모델(
MaxEnt)을 제치고 SOTA 달성.
Analysis & Ablation studies
BERT v.s. LXMERT
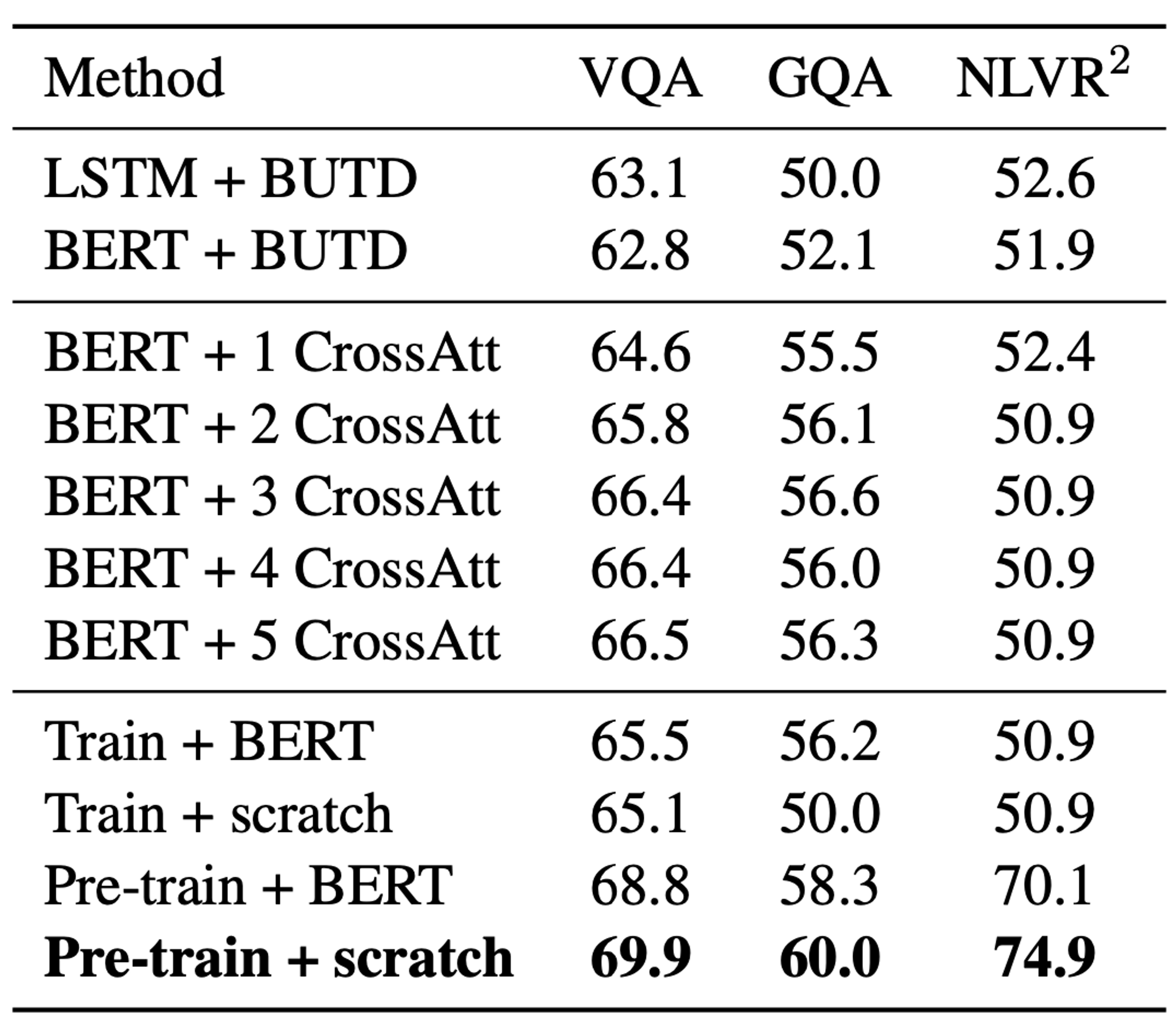
1. BERT 인코더 + BUTD 방식의 경우는 LSTM 인코더 + BUTD의 경우와 성능이 비슷하다.
2. Cross-attention layer와 object embedding에 위치 정보를 추가하여 성능 향상을 확인할 수 있다.
3. BERT는 언어 데이터로만 pre-train되었기 때문에, BERT의 pre-trained parameter를 사용하는 것보다 ‘from scratch’한 방법으로(랜덤 초기화에서 시작) 학습하는 것이 LXMERT의 성능을 향상시킨다.
Effect of the Image QA Pre-training Task
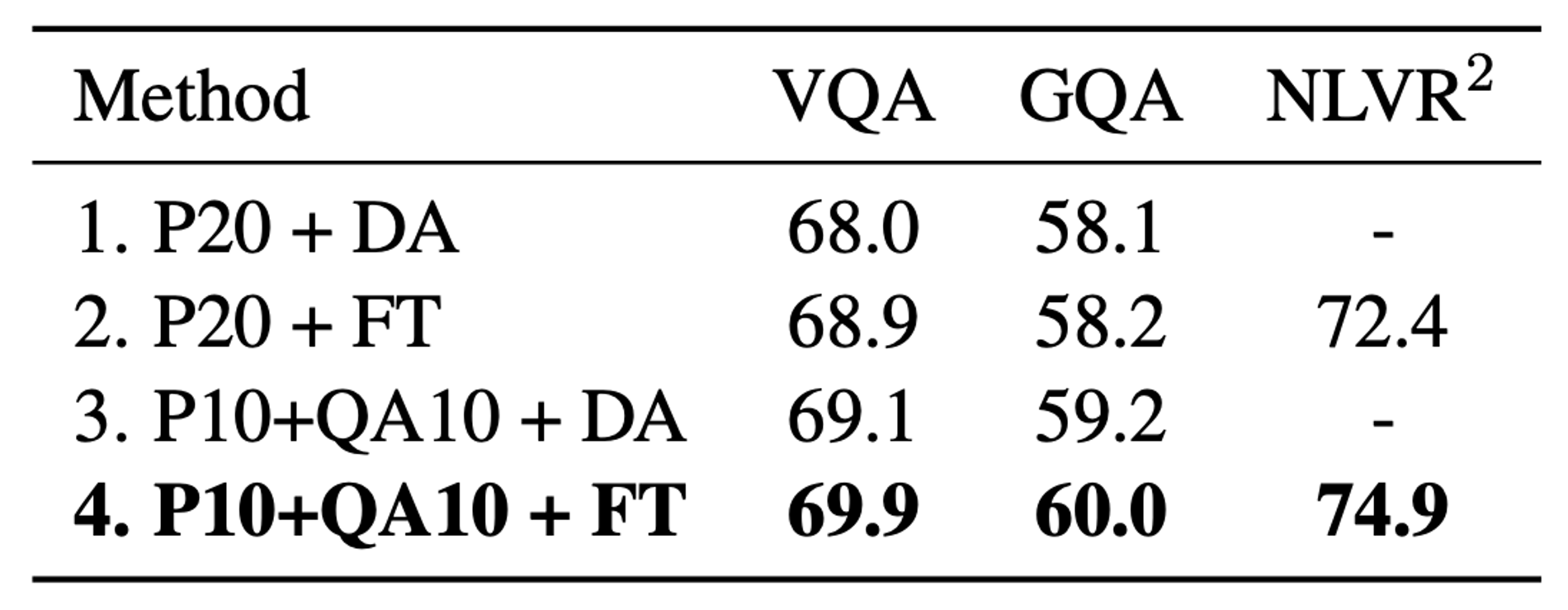
위 표는 image-QA pre-training task의 중요성을 보여준다. image-QA의 사전학습을 진행(QA)하고 Data augmentation없이 fine-tuning하는 것(FT)이 그렇지 않은 것보다 성능이 좋은 것을 확인할 수 있다.
Effect of Vision Pre-training Tasks
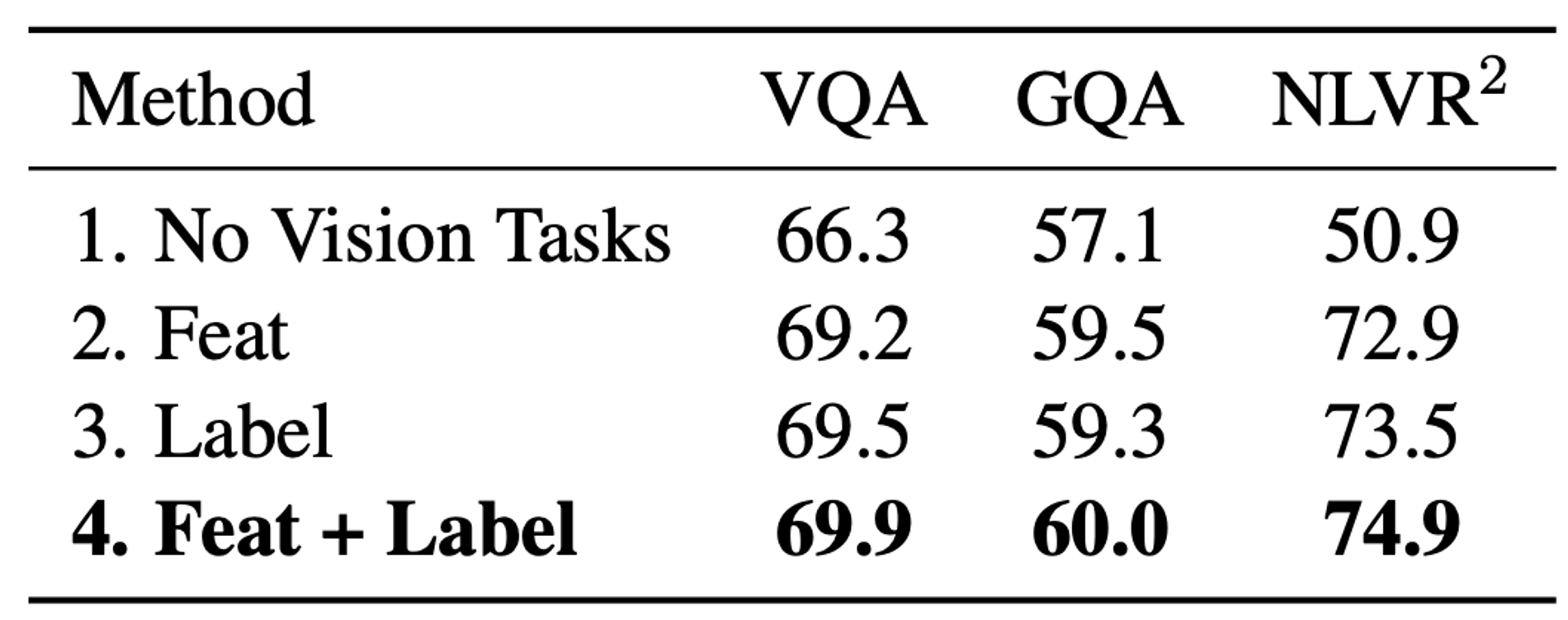
pre-training에서 vision task(RoI-Feature Regression, Detected-label Classification)가 없는 경우, 성능이 떨어진다.
Conclusion
LXMERT는 vision과 language의 두 모달리티를 연결짓는 cross-modality framework로, single-modal transformer encoders와 그 둘을 연결하는 cross-modal encoder로 구성된다. 이 모델은 vision, language, cross-modal에 대한 총 5가지 task로 pre-train되어 SOTA 성능과 일반화 능력을 갖는다.
