Basic Elements of DNN Training
데이터
데이터셋을 3부분으로 나눔
- Training Set (훈련셋) : 모델이 학습하는 데 사용하는 데이터
이걸로 가중치를 조정한다. - Validation Set (검증셋) : 학습 도중 모델이 잘 학습하고 있는지, 과적합(overfitting) 되고 있는지를 판단하기 위해 사용
- Test Set (테스트셋) : 최종 성능 평가용으로 모델 학습에서 사용되지 않아서 성능을 객관적으로 측정할 수 있다.
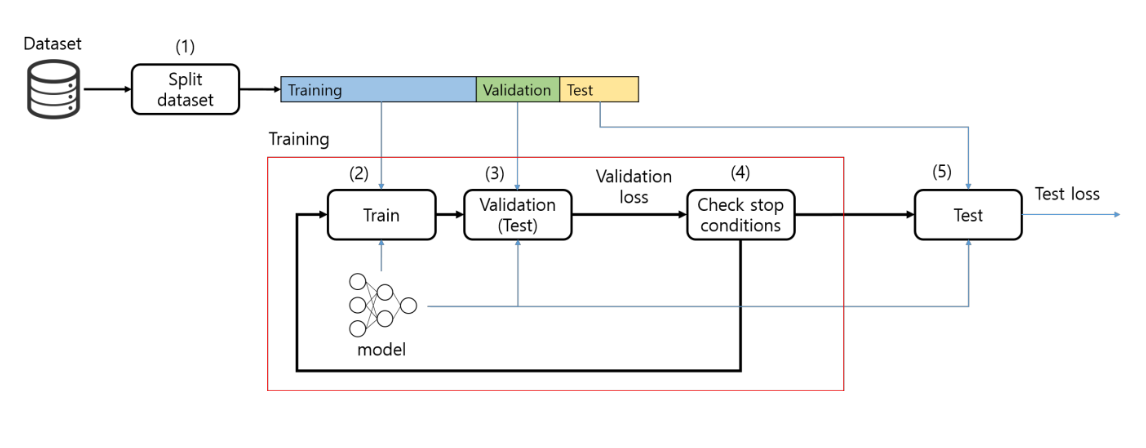
- 전체 데이터를 3부분으로 나눈다.
- 훈련셋으로 학습한다.
- 검증셋으로 검증한다. (Validation Loss 측정)
- 조건 만족하면 학습 멈춤 (예 : 검증 손실 증가 시 Early Stop)
- 최종 모델을 테스트셋으로 평가 → Test Loss 확인
Loss Function
모델 예측이 얼마나 틀렸는지를 수치로 측정하는 함수
MSE (Mean Squared Error)
회귀 문제에서 사용- 예측값과 실제값 차이를 제곱해서 평균을 냄
Cross Entropy (CE) Loss
-
분류 문제에 사용됨 -
이진 분류용 (예 : 개 vs 고양이)
-
다중 클래스 분류용 (예 : 고양이, 개, 토끼)
왜 Cross-Entropy ?
- 정답 확률 분포와 예측 확률 분포의 차이를 줄이는 방향으로 학습됨 (KL Divergence 최소화)
- 미분이 가능하고 안정적으로 학습됨
- 자신 없는 예측(낮은 confidence)에 대해 큰 패널티 → 학습 유도에 좋음
Loss Curve
학습 도중 손실 (loss)이 어떻게 변하는지를 나타내는 그래프
- Training loss : 모델이 훈련 데이터에 얼마나 잘 예측하는지
- Test loss : 테스트 데이터에 대해 얼마나 잘 예측하는지
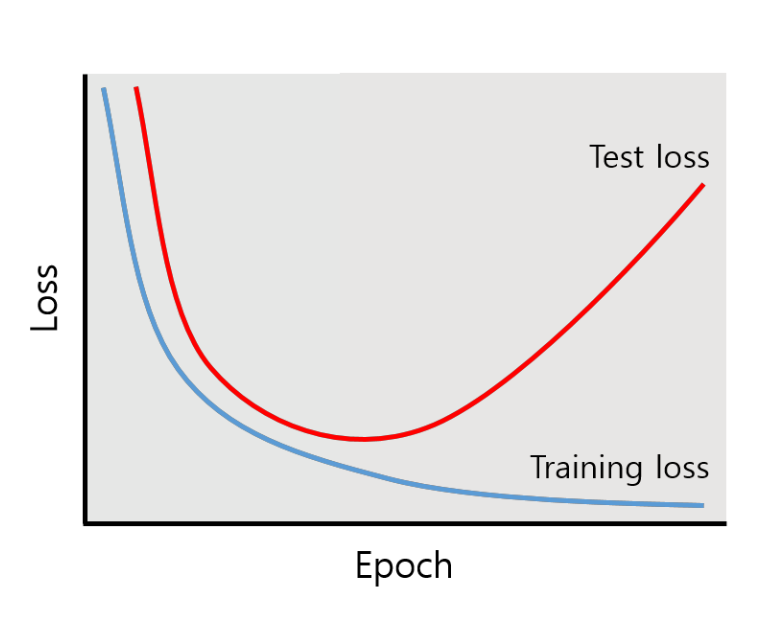
- 처음에는 둘 다 줄어듦 (학습이 잘 됨)
- 어느 순간부터 Training loss 는 계속 감소하지만, Test loss는 증가한다. → 과적합 발생
- 이 시점이 모델 학습을 멈춰야하는 타이밍 (early stopping)
검증셋을 포함한 손실 곡선을 살펴보면,
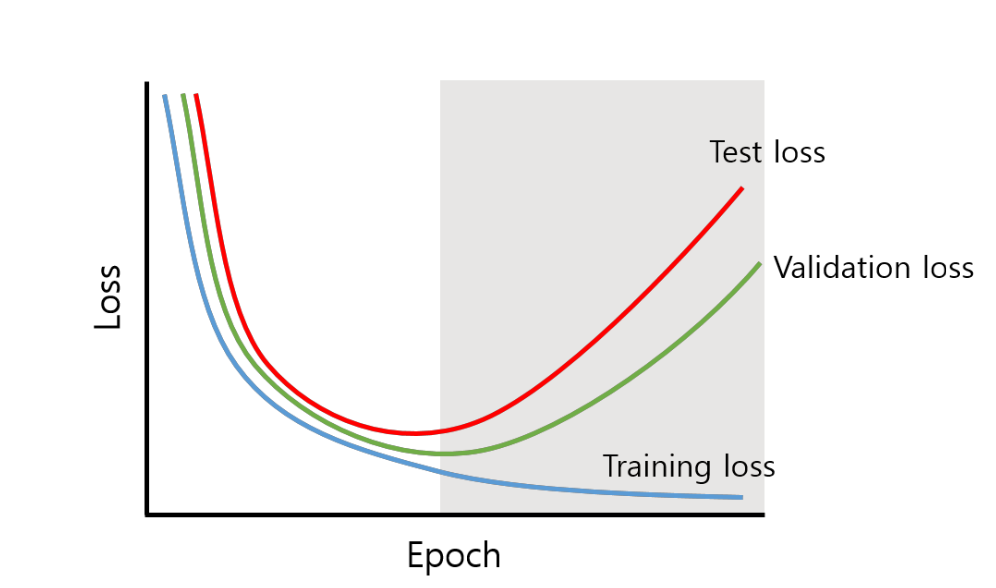
- Training loss는 계속 낮아지지만,
- Validation/Test loss는 특정 시점 이후 오히려 증가한다 → 과적합 징후
- 따라서, Validation loss가 최소가 되는 시점에서 모델 저장 및 학습 중단하는 것이 필요하다.
Training Process
신경망이 학습하는 순환 구조
- Epoch : 전체 데이터셋을 한 번 다 학습하는 과정
- Mini-batch : 데이터를 작은 덩어리로 나누어서 학습
- 한 미니배치에서의 과정
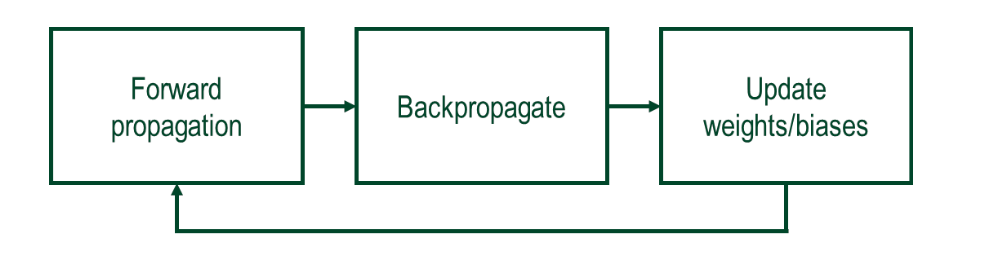
- Forward propagation : 입력을 넣고 출력까지 계산
- Back propagation : 예측과 실제값의 오차를 바탕으로 기울기 계산
- Update : 계산된 기울기를 기반으로 가중치와 편향 업데이트
→ 이 과정을 수십~수백 번 반복하여 모델이 점점 정확한 예측을 하게 된다.
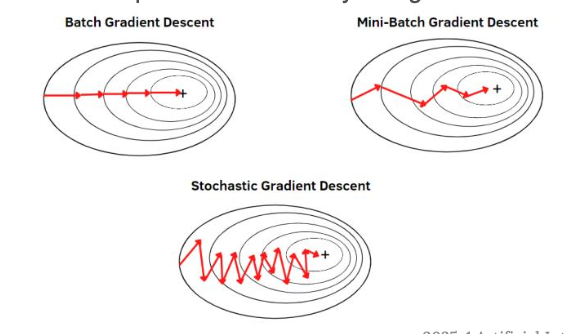
Gradient Descent Variants
경사하강법(Gradient Descent)에는 3가지 주요 방식이 있다.
- Batch Gradient Descent (BGD)
- 전체 데이터를 한 번에 써서 기울기를 계산
- 정확하지만 느리고 메모리를 많이 씀
- Stochastic Gradient Descent (SGD)
- 한 샘플씩 사용해서 업데이트
- 빠르지만 너무 요동쳐서 불안전
- 그래도 일반화 성능은 좋음
- Mini-Batch Gradient Descent
- 소수의 샘플 묶음(예 : 32개, 64개) 을 사용
- 속도와 정확도의 균형
- 실제로 가장 많이 사용됨
Learning Rate
학습률은 학습 속도 조절의 핵심이다.
- Constant : 고정된 학습률 → 단순하지만 비효율적
- Decay Schedules : 시간이 지날수록 학습률 줄이기
- 예 : step decay, exponential decay, cosine decay
- Adaptive : 파라미터마다 자동 조절 (Adam, RMSProp 등)
- Warmup : 처음에는 작은 학습률로 시작해서 점점 키움 (폭주 방지 !)
Optimizers (최적화 알고리즘)
'가중치를 어떻게 업데이트할 것인가' 에 대한 학습 알고리즘 = 옵티마이저 (Optimizer)
모델의 오차를 줄이기 위해 가중치를 바꾸는 방식 !
쉽게 말해, 딥러닝 학습은 아래 3가지의 흐름으로 구성된다.
- 손실 계산
- 기울기 계산 : 이 손실을 줄이기 위해 가중치를 얼마나 바꿔야 하는 지 계산
- 가중치 업데이트 : 이 기울기를 바탕으로 어떻게 바꿀 것인지 → 이것이 SGD, Adam 등이
옵티마이저에 해당한다.
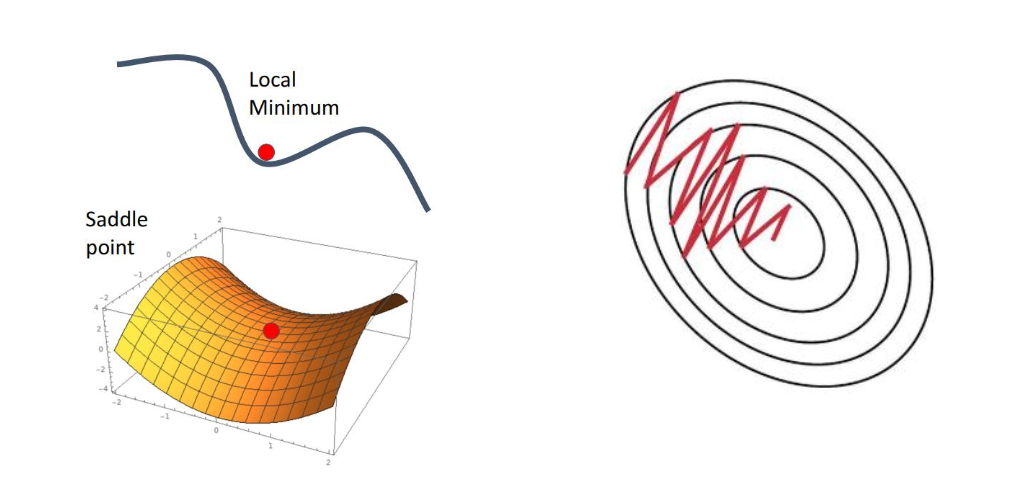
기울기를 따라 내려가다 보면 로컬 미니멈이나 새들 포인트에 걸릴 수 있다.
- 로컬 미니멈 : 진짜 최소점이 아닌데, 거기서 멈춰버리는 현상
- 새들 포인트 : 한 뱡항으로는 낮지만, 다른 방향으로는 높아서 헷갈리는 지점
→ 이럴 때 좋은 옵티마이저(예 : momentum, adam)이 필요하다 !
SGD + Momentum
기본 SGD는 기울기 방향으로만 이동해서 진동이 심하고, 속도가 느릴 수 있다.
→ 그래서 등장한 것이 Momentum (관성) !
- 예전 기울기 방향을 기억해서 관성처럼 쭉 나아가게 만듦
- 방향이 계속 같다면 → 점점 빨라짐 (가속 효과)
- 진동이 많은 경우 → 흔들림을 줄여줌 (감속 효과)
수식
-
기본 SGD
-
SGD + Momentum
→ 여기서, rho 는 마찰계수 (보통 0.9 ~ 0.99)
코드 차이
# SGD
dw = compute_gradient(w)
w -= learning_rate * dw
# SGD + Momentum
v = rho * v + dw
w -= learning_rate * v
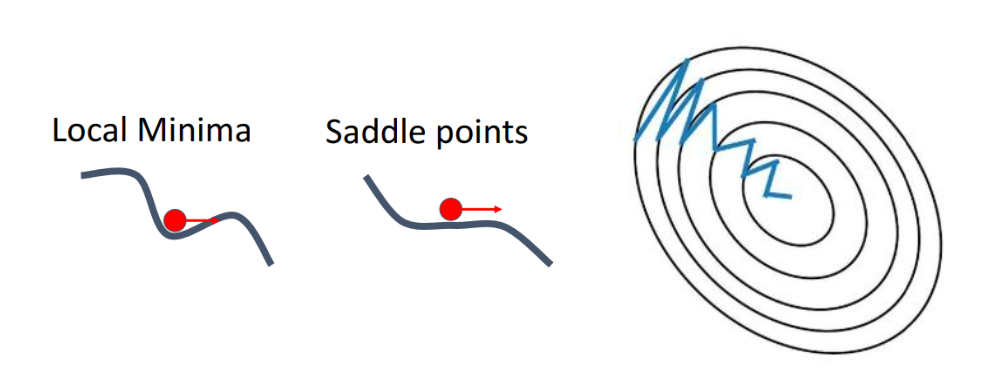
- local minima (국소 최소점) : 빠르게 도달 가능함
- saddle point (새들 포인트) : 진동 줄이고 벗어날 수 있게 도와줌
- contour map : 경로가 매끄럽게 수렴 (덜 흔들림)
AdaGrad : 파라미터별 학습률 조정
기울기가 자주 발생하는 파라미터는 학습률을 줄이고, 거의 변화가 없는 파라미터는 학습률을 유지하거나 늘린다.
핵심 아이디어
- 기울기를 누적해서, 나누어 주는 방식
- 기울기가 자주 나타난다 → 나눗셈이 커짐 → 업데이트 적게
- 희귀한 특징 → 많이 반영됨 → 드물게 등장하는 정보에 강함
수식
grad_squared += dw * dw
w -= learning_rate * dw / (sqrt(grad_squared) + epsilon)
단점 : grad_squared 가 계속해서 쌓이다 보니 → 학습률이 너무 작아져서 학습이 멈추는 경우도 있다.
RMSProp : AdaGrad 보안
AdaGrad의 학습률이 너무 작아지는 문제를 해결
핵심 차이
- grad_squared를 그냥 누적하는 대신, 감쇠율(decay)를 적용한 이동 평균을 사용한다.
수식
grad_squared = decay_rate * grad_squared + (1 - decay_rate) * (dw * dw)
- 보통 decay _rate = 0.9
- 최근 기울기를 더 중요하게 반영하는 효과
- 지속적으로 학습률을 유지할 수 있다.
Adam : RMSProp Momentum
거의 모든 딥러닝 프레임워크의 기본 옵티마이저 !
핵심
- Momentum(1차 모멘텀) + RMSProp (2차 모멘텀) 동시에 사용 → 빠르고 안정적이고, 적응적으로 학습률 조정
동작 방식
moment1 = beta1 * moment1 + (1 - beta1) * dw
moment2 = beta2 * moment2 + (1 - beta2) * (dw * dw)
w -= learning_rate * moment1 / (sqrt(moment2) + epsilon)
- moment1 : 기울기 평균 (속도)
- moment2 : 기울기 제곱 평균 (스케일)
- beat1 = 0.9, beta2 = 0.999 가 일반적인 값
장점
- 초기 학습 속도 빠름
- 진동이 적음
- 많은 하이퍼파라미터 튜닝 없이도 잘 작동함
Vanishing & Exploding Gradients
딥러닝에서 기울기가 너무 작아지거나, 너무 커지면 학습이 잘 안된다.
1. Vanishing Gradient (기울기 소실)
기울기가 너무 작아져서 앞쪽(초기) 층들이 거의 학습이 안되는 현상
- 흔히 깊은 신경망에서 발생
- 특히 sigmoid, tanh 같은 s자 함수에서 자주 나타남
- 역전파할 때 곱해지는 수가 너무 작으면 → 앞쪽은 거의 0으로 수렴
→ 그래서 학습이 느리거나 멈춘다.
해결법
- ReLU 같은 활성화 함수 사용
- Batch Normalization
- Residual Connection
2. Exploding Gradient (기울기 폭주)
기울기가 너무 커져서 학습이 불안정해지고 발산하는 현상
- 마치 폭주하는 기차처럼 파라미터가 막 튀어버린다.
- 손실도 커지고 NaN 이 뜨기도 한다.
해결법
- Gradient Clipping : 기울기 크기 제한하기
- 가중치 초기화 조심하기
- LSTM/RNN에서 자주 발생함 → 이럴 때 더 중요함
Overfitting vs. Underfitting
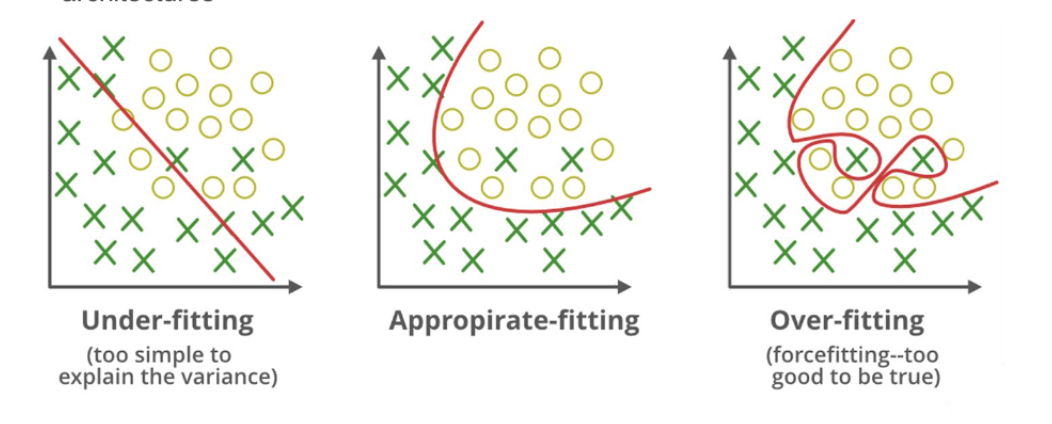
Overfitting 과적합
학습 데이터를 너무 잘 외워서, 새로운 데이터에 일반화가 안 되는 경우
- 학습 데이터는 성능이 좋음
- 검증/테스트 데이터는 성능이 안 좋음
- Training error 은 줄고 Validation error는 증가한다.
왜 문제냐 ?
- 진짜 똑똑한 모델은 새로운 상황에서도 잘 맞추는 모델이지만, 과적합은 암기만 잘해서 현실에서는 잘 쓰지 못한다.
해결법
- Regularization
- Data augmentation
- Early stopping
- simpler model 사용
Underfitting 과소적합
모델이 너무 단순해서 학습도 제대로 못하는 경우
- Training 데이터 조차 잘 못 맞춤
- 모델이 데이터의 복잡한 패턴을 못 맞춤
- 너무 얕은 신경망, 너무 작은 모델일 때 자주 발생
해결법
- 더 깊은 모델, 더 많은 파라미터
- 학습 더 오래 시키기
- 좋은 feature 사용하기
정리를 해보자면
옵티마이저는 모델이 공부할 때 '어떻게 공부할지' 정해주는 학습 전략
- SGD : 한 발 한 발 경사를 따라 내려감
- Momentum : 이전 방향을 기억해서 더 빠르게 내려가기
- AdaGrad : 자주 간 길은 덜 가고, 덜 간길은 더 가기
- RMSProp : AdaGrad 의 단점을 보완해서 계속 적절하게 조절하기
- Adam : 빠르고 부드러운, 실전용 올라운더 최적화 전략
(RMSProp + Momemtum)
