기본 Seq2Seq의 한계
Seq2Seq : LSTM을 기반으로 구성된 Encoder-Decoder 구조
Encoder가 전체 입력 문장을 하나의 벡터 c로 요약했기 때문에, 긴 문장에서는 정보 손실이 발생 → Decoder가 제대로 번역하지 못함
문제점
- 긴 문장을 처리할 수록 정보가 뭉개짐
- 디코더가 입력의 어느 부분을 참고해야 할지 알 수 없음
해결책 : Attention
Decode가 매 시점마다 입력 전체를 바라보게 해서, 중요한 부분에 집중 (attend) 하도록 만든 구조
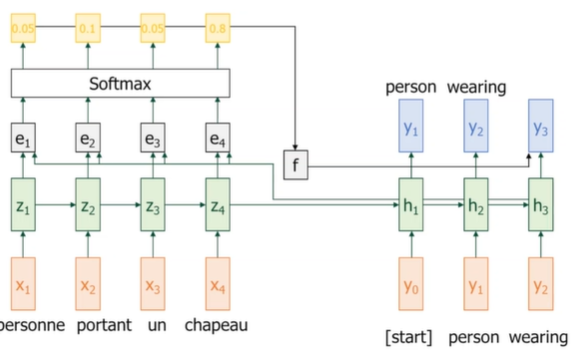
1. Encoder hidden states 준비
- 입력 문장을 인코더에 통과시키면 hidden state 시퀀스가 생성됨
- 각 는 입력 단어 에 대한 벡터 표현
2. Decoder가 현재 시점의 hidden state 생성
- 디코더가 이전 단어 와 이전 hidden state , context vector 등을 바탕으로 새로운 를 만든다.
3. 유사도 계산
디코더의 현재 상태 와 각 인코더 hidden state 사이의 유사도를 구함
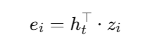
→ 각 입력 단어가 디코더 현재 시점과 얼마나 관련이 깊은지 점수화함
4. Softmax로 Attention Weight 생성
모든 에 Softmax를 적용해 확률처럼 정규화된 가중치 를 생성
→ 가중치가 크면, 그 단어에 더 집중(attend) 하게 됨
5. Context Vector 계산
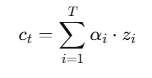
인코더의 hidden state들을 attention weight 만큼 곱해서 더한 결과이며,
디코더가 다음 단어를 예측할 때 참고하게 되는 정보 요약본이다.
6. 디코더가 다음 단어 예측
context vector, 이전 단어 예측값, 이전 hidden state 등을 바탕으로 다음 hidden state와 단어를 예측한다.
Attention 은 디코더가 입력의 특정 위치에 집중할 수 있게 해주는 매커니즘이다. 이로써 긴 문장에서도 더 정확하게 번역하거나 예측할 수 있게 되었다.

위의 그림을 보면
- 왼쪽 열 : 프랑스어 입력 문장 단어들
- 위쪽 행 : 영어 출력 문장 단어들
- 격자 하나하나 : 해당 영어 단어가 프랑스어 단어에 얼마나 attention을 줬는지 보여준다.
→ 색이 밝을 수록 집중 (high attention)
→ 색이 어두울수록 무시 (low attention)
Query-Key-Value (QKV) Attention Layer
Attention 은 단순한 기계 번역에만 쓰이는게 아니라, 입력 위치와 상관없이 유연하게 중요한 정보를 추출하는 일반 기술이다.
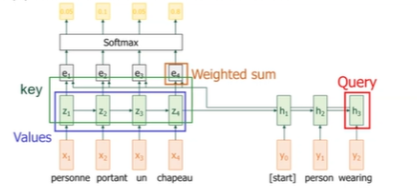
1. 입력 시퀀스 → 인코더를 통해 각 위치별 벡터 생성
2. 각 입력 벡터 를 3개로 선형변환
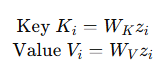
3. 디코더는 현재 단어를 예측하기 위해 hidden state 를 가지고 있음
이거를 선형변환해서 Query = 생성
4. Query 와 모든 Key 들 간 유사도 계산 (내적)
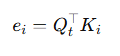
Query가 각 Key에 대해 얼마나 연관되어 있는지 score 얻음
5. Softmax 로 정규화 → Attention Weights
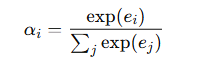
각 입력 단어에 얼마나 집중할지 비율이 정해짐
6. Value 벡터들을 Attention Weights 로 가중 평균
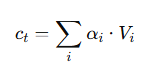
이게 context vector
현재 예측 시점에 필요한 정보 요약본임.
Query는 지금 뭐를 찾고 싶은지, Key는 가 ㄱ위치가 뭐를 나타내는지, Value는 그 위치가 실제로 들고 있는 정보
→ Query와 Key의 유사도를 계산해 Value들 중 필요한 것을 꺼내는 과정이 Attention
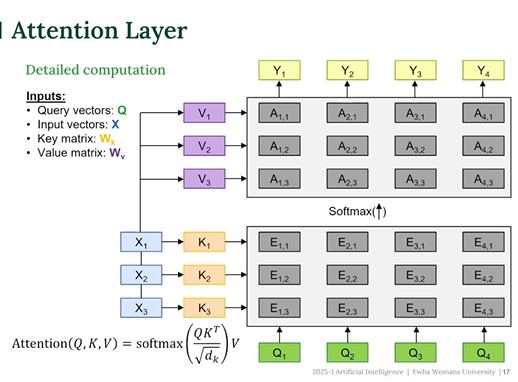
Image Captioning with Attention
예 : 이미지를 보고 'a cat sitting outside' 같은 문장을 생성하는 모델
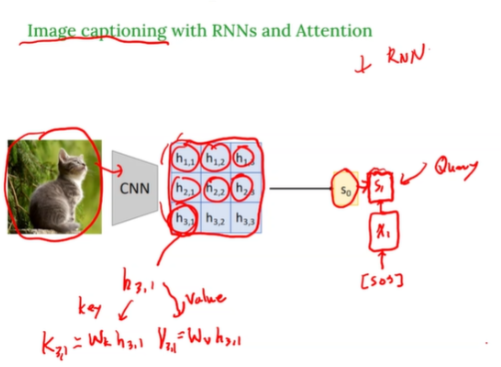
- CNN : 이미지를 쪼개서 feature map으로 변환
- Encoder 결과 : 위치 별 특징 벡터 → key & value
- Decoder (RNN) : 문장을 한 단어씩 생성 (Query)
- Attention : Decoder가 집중할 이미지 위치를 계산 (QKV)
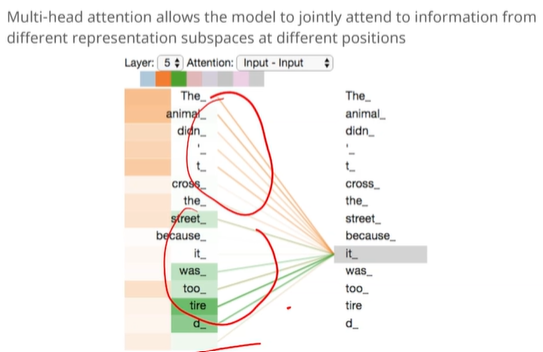
Self-Attention
입력 시퀀스 안의 단어들끼리 얼마나 관련 있는지를 계산해서 각 단어를 더 풍부하게 표현하는 방법
입력 시퀀스 안에서 단어들끼리의 관계를 동적으로 파악하는 것
- 예를 들어서 문장 "The animal didn't cross the street because it was too tired" 에서 "it" 이라는 단어는 "animal"과 깊은 연관이 있지, "street"과는 그다지 관련 없음
→ Self-Attention은 이런 관계성을 스스로 학습해서 표현할 수 있게 해준다.
보통 Attention은 Decoder가 Encoder를 보며 집중하는 구조였다면, Self-Attention은 자기 자신 안에서 Query-Key-Value 연산을 진행함.
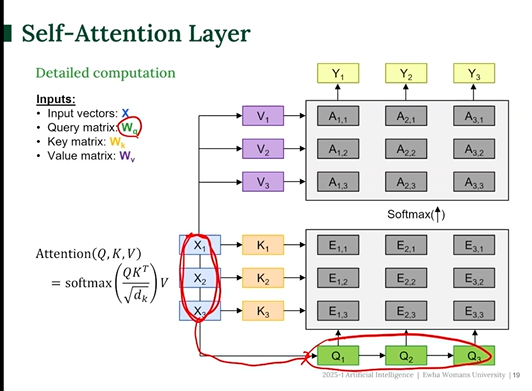
- 입력 벡터 : X1, X2, X3
모든 입력 단어가 동일한 원본 X에서 나옴 - Query, Key, Value로 선형 변환
- 모든 Query를 Key와 내적 → 유사도 행렬 E
- Softmax 적용
- Attention Output 계산

여기서 안정성은 '스케일링 벡터' 에 해당한다. 너무 큰 값이 나오면 softmax가 터지기 때문에 나누어서 값을 적당한 크기로 조절하는 것이다.
Query Matrix
일반 Attention에서는
- =
- 즉, 디코더의 현재 상태 하나로 Query 하나를 만듦
Self-Attention에서는
- 모든 입력 에 대해 Query를 만듦
- 그래서 Q = XW 는 모든 단어의 Query들을 동시에 만든다.
Self-Attention은 입력 내부에서 Query-Key-Value를 만들어, 각 단어가 문맥에서 누구를 봐야할지를 스스로 학습하는 매커니즘이다.
Mini-Head Attention
여러 개의 독립적인 Self-Attention 을 병렬로 수행한 뒤, 그 결과를 합치는 구조
- 하나의 Attention Head는 한 종류의 관계나 패턴에만 집중이 가능하다.
- 하지만, 문장 속에는 다양한 종류의 관계가 있다.
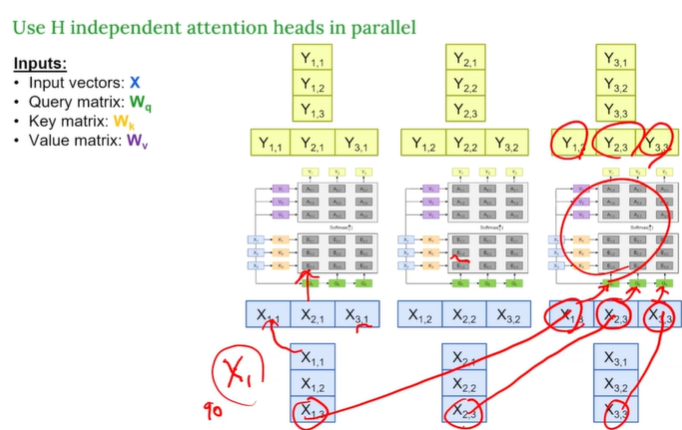
- 입력 X를 각 각 다른 Projection으로 변환
- 각 Head에서 독립적으로 Attention 수행
- 모든 Head의 결과를 Concat(연결) → Linear Projection
여러 Head의 결과를 하나로 연결해서 projection을 해서 최종 Output Y를 얻어 마지막에 결과를 받는다.