Transformer
- 기존 RNN, LSTM의 한계를 극복함
- 병렬 처리 가능 → 속도 개선
- 긴 문맥 의존성 처리 가능 → 문장 길이가 길어도 성능 유지
- 기계 번역 (Machine Translation) 분야에서 SOTA (최신 최고 성능)을 달성
대표 Transformer 기반 모델들
-
BERT (Bidirectional Encoder Representations from Transformers)
-
GPT (Generative Pre-trained Transformer)
Transformer Model Architecture
1. Encoder
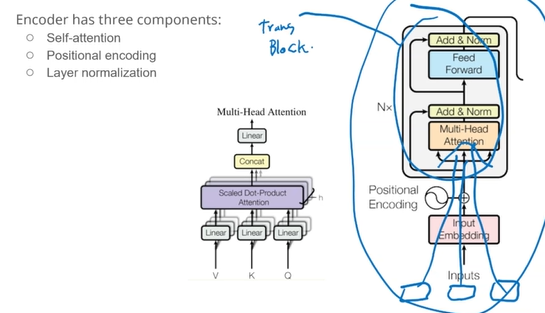
- 순차적인 RNN/CNN 없이 Attention + Feed Forward 만으로 구성됨
- 완전 병렬 처리 가능
- Encoder Block은
N_layer만큼 Stack 됨 - 입력 단어 → 임베딩 + 위치정보 → 여러 Encoder Block → 문맥 벡터 생성
하이퍼파라미터 (Hyperparameters)
d_model: 단어 벡터 차원N_layers: Encoder 블록 층 수N_heads: Multi-Head Attention의 헤드 수
d_ff: Feed Forward Layer의 내부 차원 수
Encoder Block 구성 요소
- Multi-Head Self Attention
입력 문장 안의 단어들끼리 서로 어던 관계가 있는지 파악 - Add & layer Normalization
원래 입력 + Attention 결과를 더하고 정규화 - Feed Forward Layer
각 단어 벡터를 더 복잡하게 바꿔주는 완전 연결 신경망 - Add & layer Normalization
FFN의 결과도 원래 입력과 더해서 정규화해줌
→ 위 구성 전체를 하나의 Transformer Block이라 하고, 이를 N번 쌓음
Self-Attention (=Scaled Dot-Product Attention)
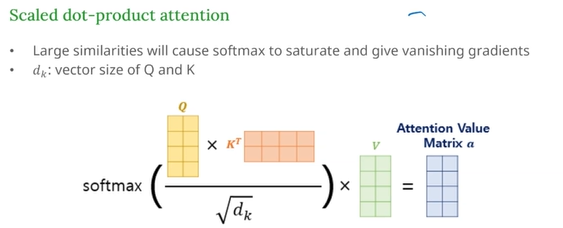
동작 설명
- Q, K, V 는 모두 입력에서 만들어짐
- Q와 K의 내적으로 유사도 점수 계산
- 루트로 나누어서 안정화
- Softmax로 확률화 → 각 단어가 다른 단어에 얼만큼 집중할지
- 그 가중치로 V를 가중합 → 새로운 표현 벡터 생성
Multi-Head Attention
- 여러 개의 self-attention head를 병렬으로 실행
- 각 head에는 Q, K, V를 따로 학습함
→ 다양한 관점에서 문맥 파악 - 마지막에 head 결과를 Concat → Linear Layer 통합
Positional Encoding
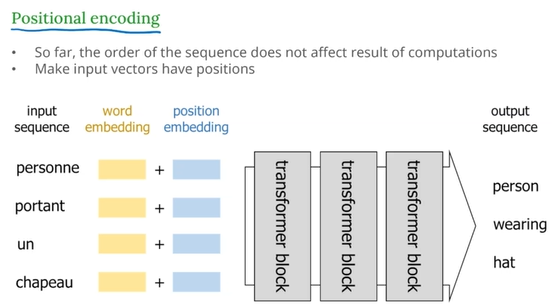
Transformer 는 단어 순서를 모름
구조상 RNN 처럼 순서에 따라서 처리하지 않아, 단어들을 벡터로 바꾸기만 하면 이 단어가 문장에서 몇 번째에 있었는지 알 수 없다.
→ 위치 정보를 직접 더해줌
Word Embedding + Position Embedding 을 합쳐서 입력으로 사용
- word embedding : 단어 자체를 임베딩한 벡터
- position embedding : 해당 단어가 문장에서 몇 번째인지에 대한 위치 정보 벡터
Layer Normalization
- 입력 벡터의 평균과 표준편차를 맞춰주는 정규화 과정
- 네트워크가 깊어지면 값이 흐트러지기 쉬움 → 이를 안정화 함.
- 위치 : Add & Norm 구조에서 Sublayer 뒤에 항상 적용됨
2. Decoder
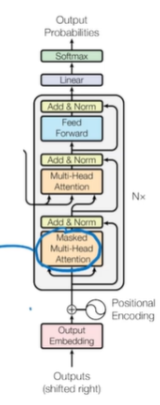
역할
- Encoder가 만들어낸 문맥 벡터를 바탕으로
- 하나씩 단어를 생성해나가는 단계
구성 요소
-
Output Embedding + Positional Encoding
Decoder도 마찬가지로 단어를 벡터로 변환하고, 순서를 인식할 수 있도록 위치 정보 추가 -
Masked Multi-Head Self-Attention
Decoder 내부에서 이전 단어들을 참고해서 다음 단어를 예측
Masked: 미래 단어는 보면 안되니깐 마스크를 씌움
- Multi-Head Cross Attention (또는 Encoder-Decoder Attention)
Encoder가 만든 문맥 벡터를 받아서 지금까지 생성된 출력과 얼마나 관련 있는지 Attention으로 판단
-
Feed Forward Layer
인코더와 동일한 방식의 FFN 사용 -
Output Layer
최종적으로 각 단어에 대한 확률 분포를 출력
확률이 가장 높은 단어를 선택해서 출력에 추가
Masked Self-Attention Layer
미래 단어를 보지 못하게 가려서 단어를 하나씩 순서대로 예측하도록 만든 Self-Attention
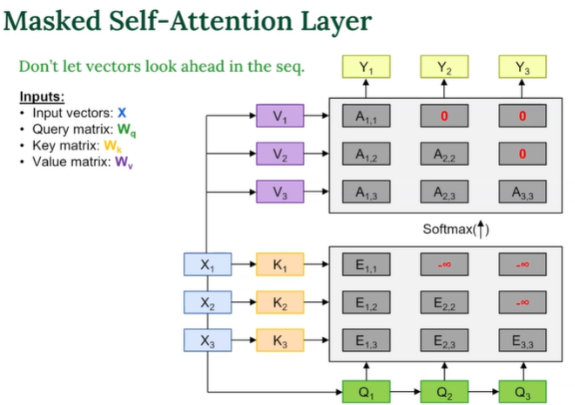
- Encoder의 Self-Attention은 입력 전체를 동시에 본다.
- 하지만 Decoder는 예측 중이기 때문에 아직 생성되지 않은 미래 단어를 보면 안됨
그래서 미래 위치는 무조건 -∞로 설정해서 Softmax 후 0이 되게 함
