잠깐 CNN을 이야기하기 전에 Fully-connected Layer 에 대해서 이야기를 해보자면
- 일반적인 인공신경망에서는 모든 입력 노드가 모든 출력 노드와 연결되어 있다.
- 이를 fully-connected layer라고 한다.
일반 신경망은 모든 노드가 서로 연결돼 있어서 연산량이 많고, 이미지처럼 큰 데이터에는 비효율적이다.
CNN
- CNN은 이미지 인식에 특화된 구조
- Fully-connected 와 달리
- 필요한 부분만 연결되고 (지역 연결)
- 가중치를 재사용함 (같은 필터를 반복 적용)
- 이 덕분에 연산량이 감소하고, 메모리 사용량도 감소하며 성능은 뛰어나게 된다.
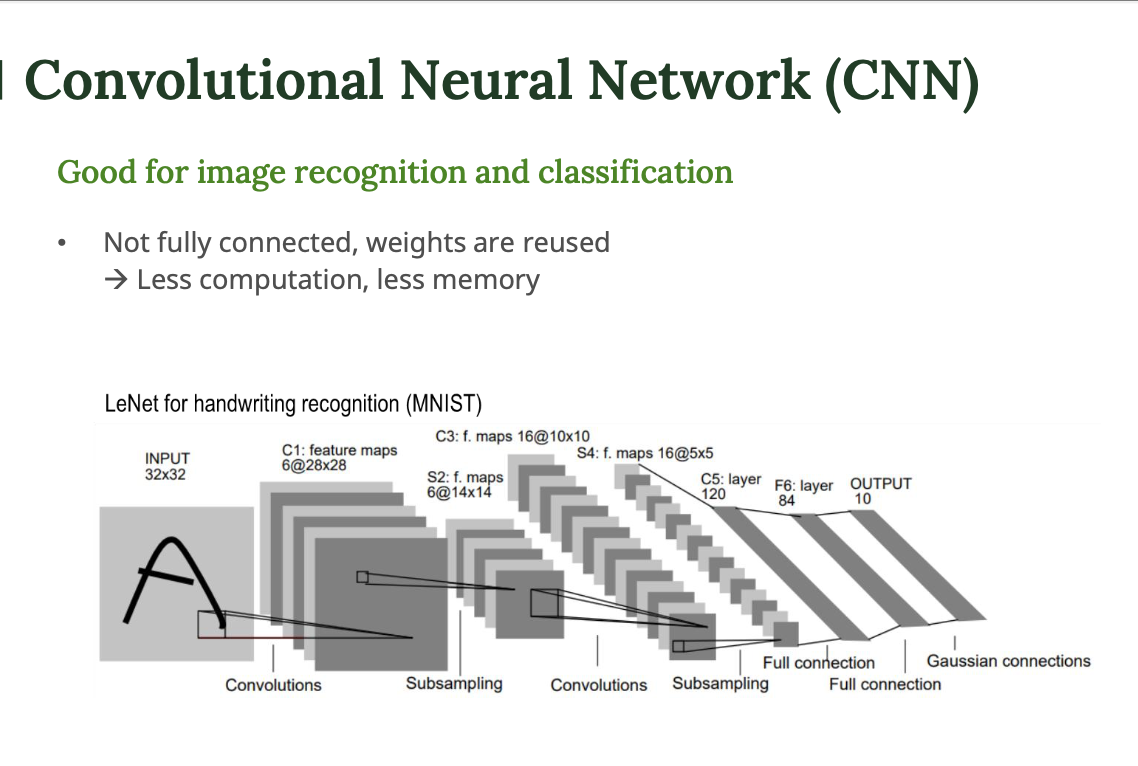
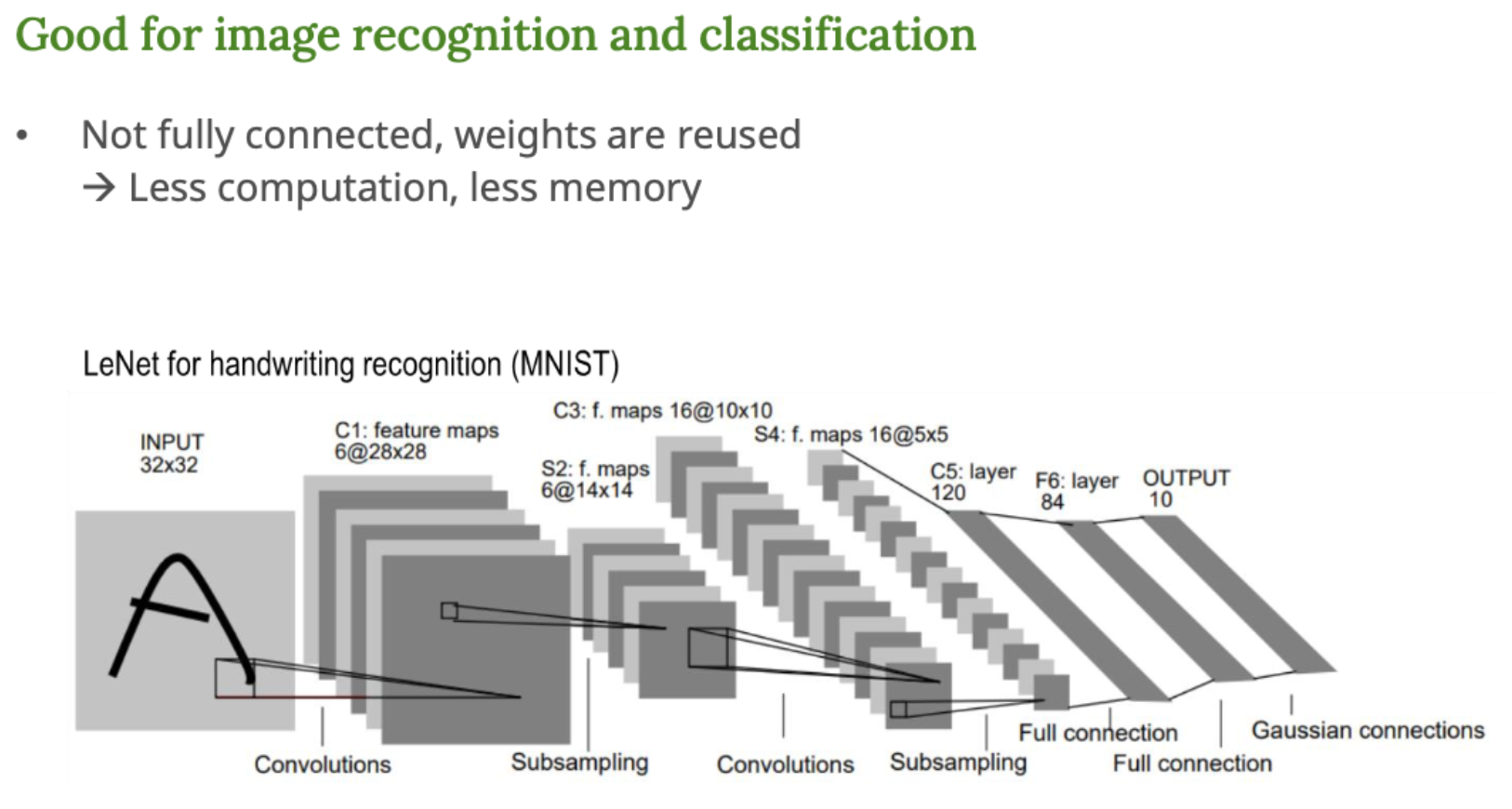
LeNet
- 고전적인 CNN 구조 (MNIST 숫자 인식)
- 구조 : Convolution → Subsampling → Convolution → Subsampling → Fully connected
CNN은 이미지의 공간 구조를 보존하면서, 필터(작은 창)을 이용해 중요한 패턴만 뽑아내는 구조 !
ImageNet 대회
- ImageNet 대회 (ILSVRC) : 전 세계에서 CNN 성능을 겨루는 대회
- 2012년 AlexNet이 처음으로 CNN으로 압도적 성능을 보여줌
- 그 후 CNN 구조는 계속 발전함
- AlexNet → VGG → GoogleNet → ResNet
- 층 수가 많아질 수록 정확도가 향상된다.
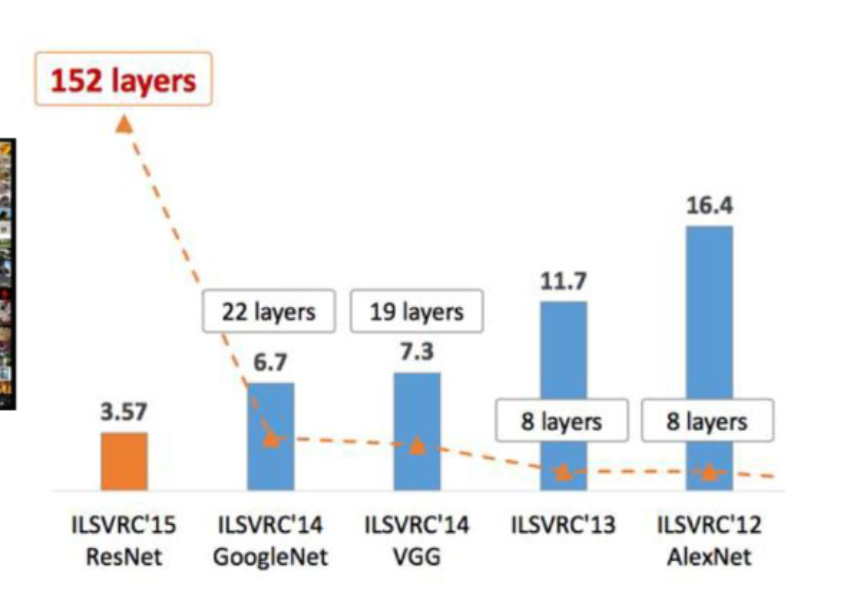
층 수가 많아질 수록 오류율이 낮아진다는 것을 확인할 수 있다.
AlexNet 구조
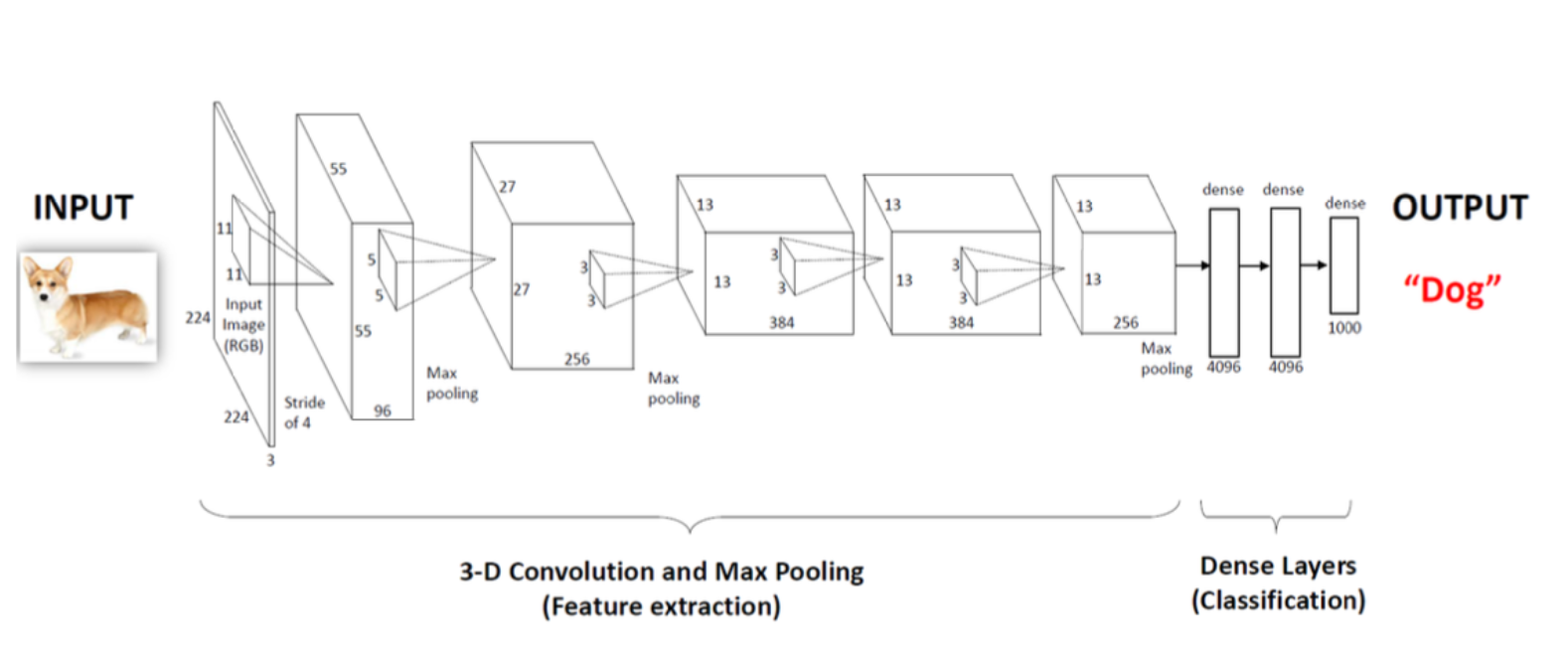
- 입력 : RGB 이미지 (244*244)
1~5단계 : convolution + max pooling
사진에서 특징(귀, 눈, 배경 등)을 추출
- convolution : 필터를 이용해 이미지를 훑으면서 특정 모양이나 패턴을 찾는다. 처음에는 선, 곡선, 밝기 변화 같은 단순한 것들을 감지
- max pooling : 가장 큰 값만 남겨서 정보는 유지하고 크기는 줄이는 역할을 한다. 예를 들어 2*2 를 한다면 제일 큰 값 하나만 뽑게 된다. 사진의 해상도는 줄지만, 중요한 특징만 남기고 효율적으로 처리할 수 있게 된다.
6~8단계 : fully connected layer
추출된 특징을 기반으로 '이건 강아지야!' 라고 판단
AlexNet은 CNN을 본격적으로 실용화시킨 모델이고, 특징 추출 → 판단 구조가 기본 뼈대에 해당한다.
2D Convolution
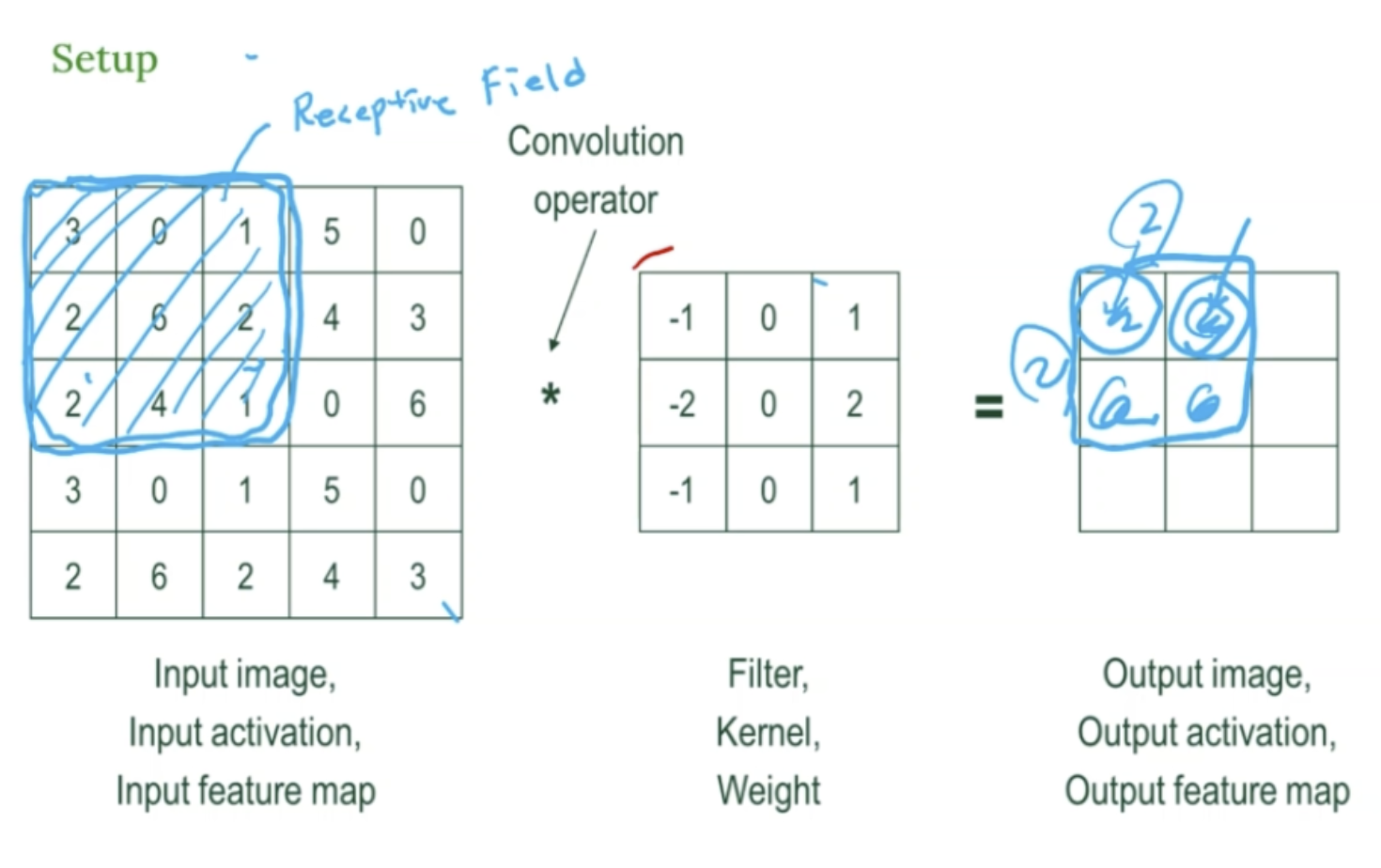
CNN의 핵심 연산인 합성곱 (Convolution) !
- 왼쪽 : 입력 이미지 (숫자로 배열)
- 파란색 네모로 표시된 부분을
수용영역 (Receptive Field)라고 부른다 ! - 신경망의 한 뉴런이 입력 데이터 중 어느 부분을 보고 있는가에 해당하는 영역
- 파란색 네모로 표시된 부분을
- 가운데 : 필터 (=커널, 3*3)
- 오른쪽 : 결과 이미지 (특징 맵)
동작
- 필터를 이미지 위에 올리고, 각 위치의 값들을 곱해서 더함
- 하나의 숫자를 출력한다.
이 과정을 이미지 위를 슬쩍슬쩍 미끄러지듯 반복한다.
→ 그래서 "슬라이딩 윈도우 "
Zero Padding
합성곱 연산에서 경계 정보를 보존하고 출력 크기를 조절하기 위해서 흔히 사용되는 기법이다.
필요성
- 입력과 출력의 크기 일치
- 합성곱 연산을 하면, 출력 이미지가 입력보다 작아지는 경우가 많다.
- 이 때, 입력 테두리에 0을 덧붙이는 방식 (zero padding) 을 사용하면 출력 크기를 입력과 동일하게 유지할 수 있다.
- 경계 정보 손실 방지
- 필터는 가운데를 기준으로 주변 픽셀을 보는데, 가장자리 픽셀은 주변 정보가 부족하다.
- 이를 보완하기 위해 경계에 0을 추가하여 경계에 위치한 정보도 연산 대상이 되도록 만든다.
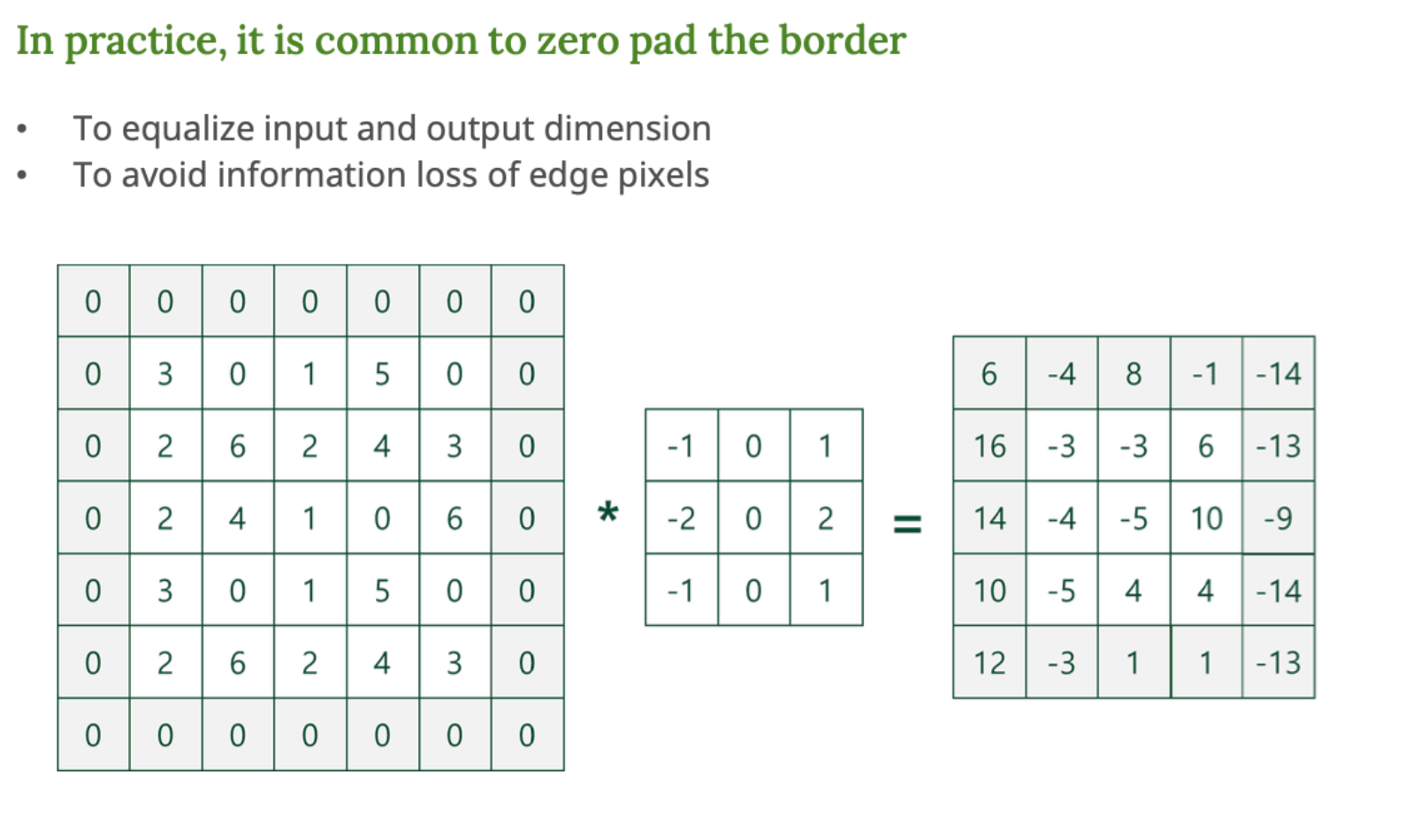
-
왼쪽 이미지 : 패딩 적용
- 원래 입력은 5 * 5 이지만, 위아래 양옆으로 1칸씩 0을 채운다.
- 이로써 필터가 입력의 가장자리를 포함하여 연산할 수 있따.
-
가운데 : 필터 (=커널)
- 3 * 3 필터
- 중심값을 기준으로 주변 8개의 값과 함께 연산
-
오른쪽 : 출력 이미지
- 결과는 5 * 5 크기의 출력 이미지로, 원래 입력 이미지와 동일한 크기를 유지하고 있다.
합성곱
필터를 이미지 위에 스랄이딩하면서 그 안의 특징을 감지하는 연산
- Sliding Window Concept
작은 필터(=창)이 이미지 위를 한 칸씩 옮겨 다니면서 계산
마치 종이 창을 들고 사진 위를 이리저리 움직이며 보는 느낌 - Weighted sum
필터의 각 숫자와 이미지 숫자를 곱해서 모두 더함
결과는 필터가 해당 영역에서 얼마나 잘 맞는지(유사성) 나타내는 점수 - Feature detection 특징 감지
필터의 종류에 따라 : 수평선 감지, 수직선 감지, 모서리 감지 등 가능
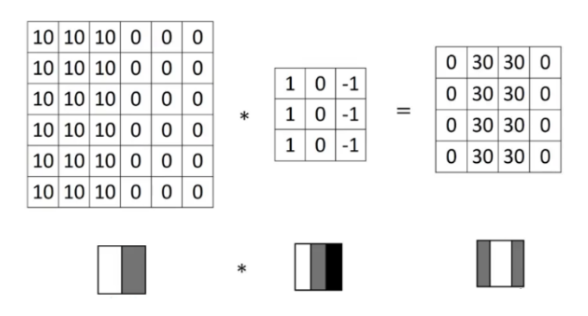
왼쪽 : 입력 이미지
- 밝은 값(10)이 왼쪽에 모여 있는 이미지
가운데 : 필터 (예 : 수직선 감지 필터)
- 이 필터는 수직 방향의 변화(선)을 찾는데 특화됨
결과 : 오른쪽
- 특정 부분에서 수직 변화가 강하면 큰 값 → 특징이 잘 감지됨
예시

첫번째는 사진 예시
- 왼쪽은 원본 이미지 (자전거 + 벽)
- 오른쪽은 특정 필터를 통과한 결과
이미지 속 윤곽, 선, 모서리, 구조가 뚜렷하게 드러남
필터는 단순히 보는게 아니라 '중요한 특징'을 추려내는 역할을 한다.
두번째는 자동차 예시
CNN은 특징을 이렇게 단계적으로 추출한다.
- low-level : 간단한 패턴 (예 : 선, 점, 모서리)
- mid- level : 구조물 (예 : 눈, 창문, 바퀴 등)
- high-level : 전체 형태 (예 : 자동차, 사람, 개 등)
CNN은 점점 더 복잡한 패턴을 인식하면서 이미지를 이해해 나가게 된다.
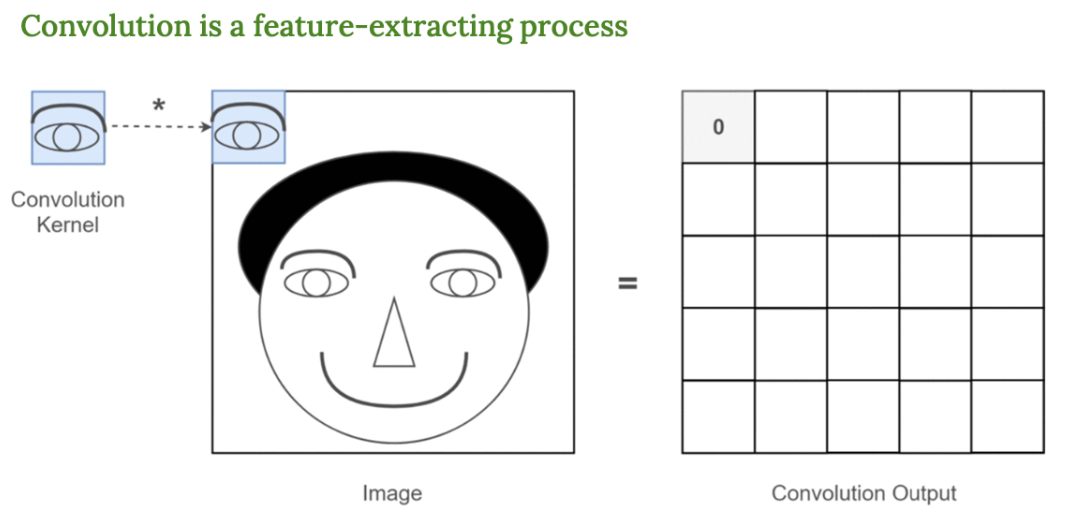
필터 모양이 눈이라면
이미지 전체에서 눈이 어디에 있는지 찾아냄
그리고 결과 이미지에서는 눈이 어디에 있는지 찾아냄 → 눈이 있는 부분만 값이 커지게 됨
CNN은 이렇게 사전 정의된 필터 없이도 스스로 눈,코,입,귀를 학습해서 찾을 수 있다 !
