End-to-End Classification Example
1단계 : 데이터셋 만들기
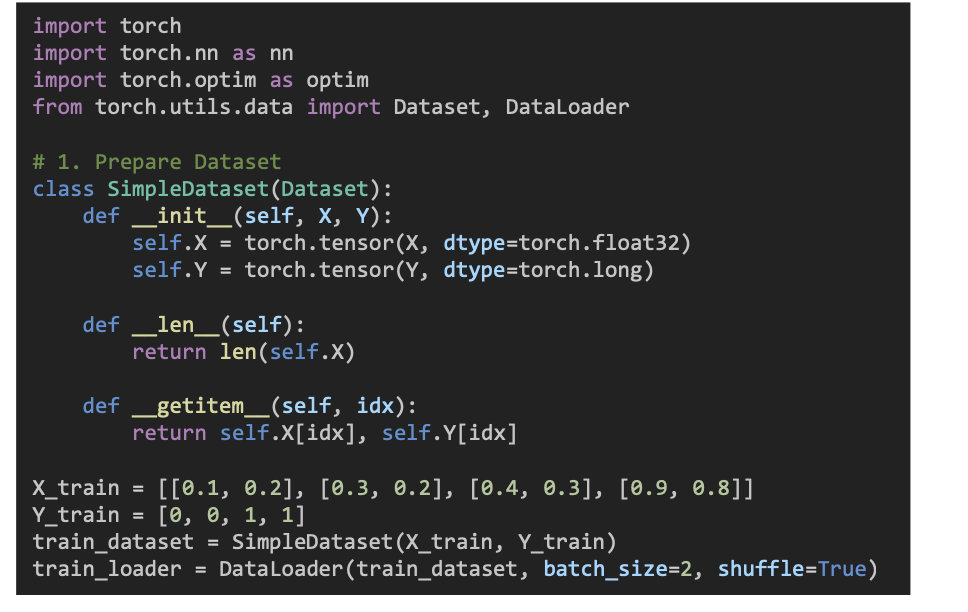
- X : 입력 데이터 (예 : 키, 몸무게)
- Y : 정답 클래스 (예 : 0 = 남자, 1 = 여자)
- 둘을 PyTorch가 처리할 수 있게 Tensor로 변환
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)
- 데이터를 2개씩 나눠서(batch) 학습하고,
- 순서도 섞어서 (shuffle) 학습 효과를 높이려는 설정
2단계 : 모델 만들기
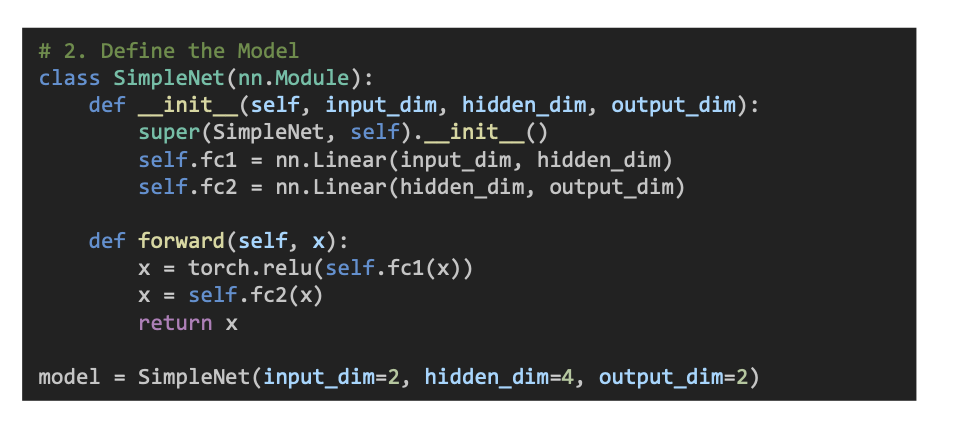
- fc1 : 첫 번째 레이어 (입력 → 은닉층)
- fc2 : 두 번째 레이어 (은닉층 → 출력층)
input_dim =2 이면 입력 특징이 2개 (예 : x1 = 키, x2 = 몸무게)
- forward() : 입력이 들어왔을 때, 예측값을 어떻게 계산할지 정의함
- ReLU 는 은닉층에서만 사용
3단계 : 손실함수와 옵티마이저 정의

CrossEntropyLoss : 분류 모델에서 예측값과 정답의 차이(=손실) 을 계산 Adam : 가중치를 얼마나 어떻게 바꿀지 결정해주는 학습 알고리즘 model.parameters() : 학습 대상인 모델의 가중치들
4단계 : 학습 루프
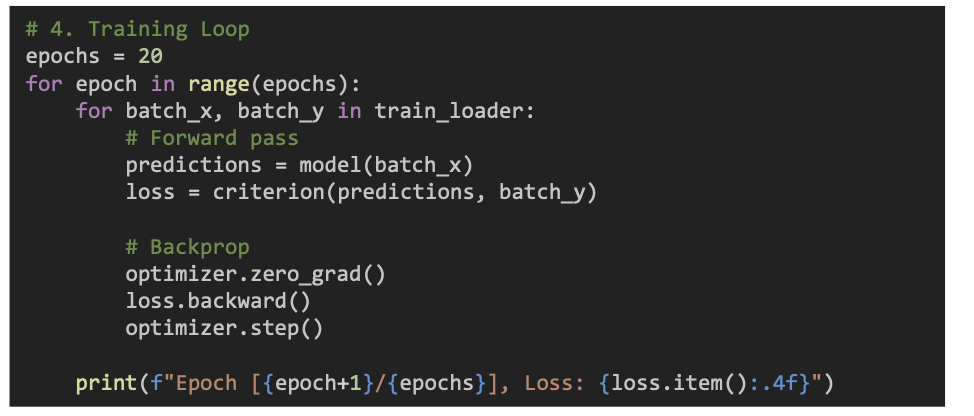
- 1번 반복 = 1 epoch
- 모델은 데이터를 보고 예측하고, 틀렸다면 가중치를 조금씩 수정
5단계 : 예측해보기 (모델 평가)

eval() 은 학습 중에 쓰던 기능들(dropout 등)을 꺼서 정확한 예측이 가능하게 함 - 예측 결과는 [0.2, 0.8] 처럼 나옴 → argmax로 가장 큰 값을 가지는 클래스 선택 (예 : 1번 클래스)
