LLM (Large Language Models)
LLM은 매우 큰 규모의 파라미터와 데이터를 기반으로 훈련된 Autoregressive Transformer 모델을 의미한다. 보통 GPT 계열처럼 Decoder-only 구조를 따르며, 다음 단어를 예측하는 방식으로 작동한다.
- Autoregressive 모델 : 순차적으로 다음 단어 예측
- Emergent Abilitlies (자발적 능력) : 특정 규모 이상이 되면 나타나는 고급 능력
- Zero-shot reasonging
- 도구 사용 (tool use)
- 멀티모달 추론 (multimodal grounding)
이런 능력은 단순히 모델이 커지기만 하면 생기는 것이 아니라, Token 수, 파라미터 수, 연산 예산이 임계값을 넘을 때 나타난다.
LLM 규모 기준
- 파라미터 수 : 보통 10B ~ 1T 이상
- 학습 토큰 수 : 약 10의 13승 tokens 이상
- 모두 decoder-only 기반 구조
token count : 얼마나 많은 토큰 (문자열 단위)를 학습했는가
parameter count : 모델 내부의 학습 가능한 가중치 수
compute budget : 학습이 들어간 전체 연산 자원
Bigger = Better ?
하나의 모델로 다양한 작업을 수행 가능하다. 즉, 모델이 커질수록 범용적 언어 이해 및 생성 능력이 강해진다 !
💡Emergent Capabilities 돌발능력
모델이 특정 임계 크기를 넘어서면 갑자기 새로운 능력이 자발적으로 등장한다. 작은 모델에서는 전혀 보이지 않던 능력이, 어느 순간 급격하게 향상된다.
다음 사진에서도 알 수 있듯, Emergent 능력은 모델 크기에 따라 폭발적으로 증가한다. 그래프에 따르면, 모델 FLOPs(훈련 연산량)이 커질수록 정확도가 급상승하는 지점이 있다.
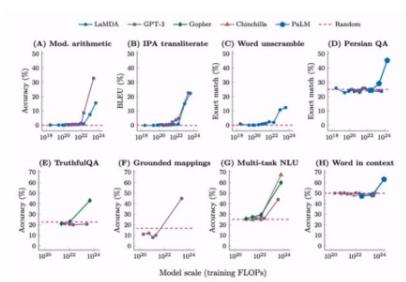
예시
| Task 유형 | 임계 크기 | 정확도 향상 | 의미 |
|---|---|---|---|
| 다단계 산술 연산 | 30~50B 파라미터 | 30% → 85% | 상징적 추론 가능 |
| CoT 수학 문제 | 100B + CoT 프롬프트 | <10% → 60% | 추론 능력 노출 |
| 코드 생성 | 30~70B | 거의 0% → 50%↑ | 실제 프로그래밍 대응 가능 |
| 저자원 언어 번역 | >65B, >1T tokens | BLEU 점수 +10 | 포괄적 언어 포용성 |
1. In-context learning
훈련 없이 입력 안에서 패턴만 보고 문제를 해결한다.
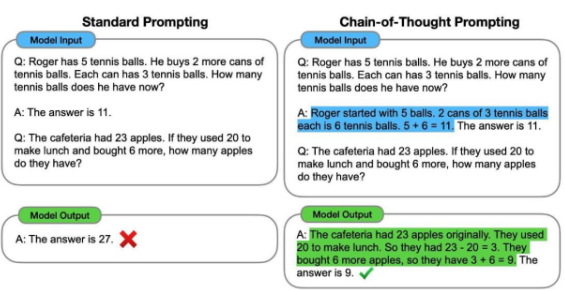
2. Chain of Thought (CoT) Prompting
모델에게 정답만 요구하지 않고 풀이 과정을 단계적으로 보여주면 모델도 유사한 방식으로 복잡한 문제를 더 잘 해결할 수 있게 된다.
LLM Scaling Laws
대규모 언어 모델은 어떻게 키워야 효과적일까 ?
Validation loss는 파라미터 수, 데이터량, 계산량에 대해 파워 법칙(power law)를 따름.
→ 즉, 모델의 크기나 학습 데이터가 늘어날 수록 성능 향상은 예측 가능한 방식으로 증가한다 !!
모델 크기나 데이터 양이 증가할 수록 손실은 서서히 감소한다. 그러나, 지수적으로 효율은 떨어진다.

Kaplan Law (2020)
고정된 연산량을 기준으로 할 때, 파라미터 수와 데이터 양은 다음과 같은 비율로 분배해야 최적화 가능하다.
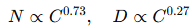
해석 : 모델 크기 > 데이터 양 이 더 중요하다는 의미 !
- GPT-3 기준 : 175B 파라미터, 300B 토큰 → 대량 2-6개의 토큰을 파라미터 하나 당 학습시키는 것이 적절하다고 제안
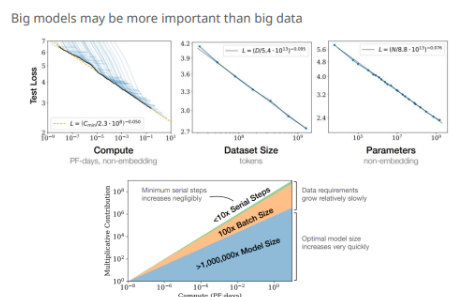
위 그래프를 보면, 'compute, dataset, parameters' 모두 loss를 일정한 법칙으로 줄인다.
데이터보다는 모델 크기가 훨씬 민감하게 성능에 영향을 미친다.
Chinchilla Law (2022)
Kaplan과 달리, 데이터 양 부족이 문제라는 주장을 한다.
→ 결론 : 계산 자원이 같다면, 모델을 줄이고 데이터를 늘리는 게 더 낫다.
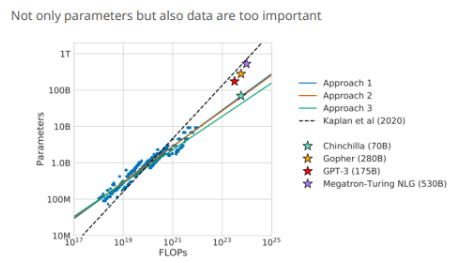
위 그래프를 참고해보면 같은 연산량일 때, 더 작은 모델 + 더 많은 데이터가 더 좋다는 것을 볼 수 있다.
Practical Recipe
- Compute 예산 설정
- 데이터 양 확보 → Chinchilla 비율 적용해서 파라미터 수 N 선택
- 작은 프로토타입으로 γ, δ 추정
- learning rate 조정
- 검증에서는 약 0.3% 의 FLOPs 할당
- γ와 β만 알면 Validation Loss ±5% 오차로 예측 가능
Sampling
LLM의 출력은 왜 항상 똑같지 않을까 ?
Deterministic vs. Stochastic
- 기존 딥러닝 모델은 deterministic : 동일 입력에 항상 동일한 출력
- 그런, LLM 은 stochastic : 같은 질문에도 매번 다른 결과가 나올 수 있음
왜냐하면, 모델은 다음 단어를 확률 분포로 예측하고, 그 중 하나를 선택해서 출력하기 때문이다.
확률 분포 기반 토큰 선택
LLM은 입력 문맥을 처리한 후, 각 시점마다 단어(토큰)에 대한 softmax 확률 분포를 생성한다.

- 𝑉 : 전체 어휘 집합
- 모델은 가장 높은 확률의 단어를 선택할 수도, 확률적으로 다른 단어를 고를 수도 있음
이 분포를 어떻게 설정하느냐에 따라 결과는 크게 달라진다. 유창성, 다양성, 반복성, 사실성, 독성까지 !!
샘플링 기법 : Stochastic Decoding Tricks
1. Temperature T
확률 분포를 조정하는 스케일링 파라미터
- T < 1 : 보수적 (정확한 답 중심)
- T > 1 : 창의적, 예측 불가능한 응답
2. Top-k 샘플링
확률이 높은 k개 토큰만 남기고, 나머지는 버림
- 초고확률 외 이상치 방지 : k = 20 - 200
- 단점 : yes/no 같이 결정적인 상황에는 부적절할 수 있음
3. Top-p (Nulcleus Sampling)
누적 확률이 p이상이 되는 최소 토큰 집합에서 샘플링
- 장점 : 엔트로피(불확실성)에 적응 가능, 더 유연하고 자연스러움
- 단점 : 낮은 확률 단어 포함 위험이 있음
실전 조합
대부분의 실제 사용 사례에서 다음과 같은 조합을 사용한다.
Temperature = 0.7, Top-p : 0.9
Trainging LLM
대규모 언어 모델은 어떻게 훈련될까 ? 오늘날의 LLM은 단순히 하나의 학습으로 끝나지 않는다. 3단계에 걸쳐 훈련되며, 각각의 단계는 서로 다른 목적을 가지고 있다.
1. Pre-Training
두뇌 만들기
- 대량의 웹 기반 텍스트로 self-supervised learning 수행 (자기 지도 학습)
- 주요 목적 : 언어의 구조와 지식 습득
- 수 주 ~ 수 개월이 소요되는 대규모 cross-entropy 최적화
- 스케일링 법칙 기반으로 학습 종료 시점 (early stopping) 판단
사용 데이터
- 1~20T tokens
- Next-token prediction
- 컨텍스트 길이 : 16k ~ 32k
- cosine learning rate decay
→ 이 단계에서 만들어진 모델은 흔히 말하는 base model 이다.
2. SFT (Supervised Fine-Tuning/Instruction Tuning)
말 잘 듣는 모델로 바꾸는 단계
- 사람이 작성한 고품질 instruction-response 데이터를 이용한 감독학습
- 목적 : 명령을 이해하고 따를 줄 아는 능력을 부여
- 학습률은 pre-trained 대비 약 10배 낮게 설정한다.
데이터
- 50K ~ 5M 개의 instruction-response 쌍
→ 이 과정을 통해 모델은 '단순한 텍스트 예측기' 에서 질문에 답할 줄 아는 조력자로 발전
3. Alignment by Preference Optimization
사람이 선호하는 방향으로 모델을 정렬하는 단계
- 기존의 SFT 모델은 명령은 잘 따르지만, 여전히 비논리적이거나 유해한 응답을 할 수 있다.
- 이 단계를 통해 친절하고, 안전하며, 정교하게 추론 가능한 모델로 발전시킨다.
방법
- 사람의 피드백 (선호도) 를 보상 함수로 사용하여 강화학습을 수행한다.
- 보상이 높은 응답의 확률은 높이고, 낮은 응답의 확률은 줄이도록 학습한다.
🤝RLHF
앞서 말한, 인간 피드백을 바탕으로 LLM이 바람직한 출력을 생성하도록 강화학습을 적용하는 방식이다.
기본 아이디어
좋은 응답에는 보상을, 나쁜 응답에는 벌을 !
LLM 출력 s에 대해 사람이 부여한 보상 R(s)에 따라 모델의 출력 확률을 조절한다.
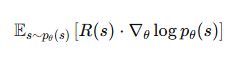
다음 식에서
- R이 크면 : 그 출력을 더 자주 만들도록 확률을 증가
- R이 작으면 : 덜 자주 나오게 확률을 감소시킴
인간의 선호는 어떻게 모델링할까 ?
문제 1
사람의 피드백은 비싸다. (비용 문제)
해결책
사람 대신 LLM 판사 (Reward Model)을 학습
- 사람의 평가 데이터를 활용해, 사람 선호를 예측하는 별도 모델을 학습
- 그 다음부터는 사람이 직접 평가하지 않아도, 이 모델을 통해 보상을 예측할 수 있다.
이 방식은 RLAIF (Reinforcement Learning from AI Feedback)이라고 불리기도 함.
문제 2
사람 평가가 부정확하거나 일관되지 않다.
해결책
절대 평점 대신, 쌍(pairwise) 비교를 요청한다.
- 사람에게 '이 둘 중 뭐가 더 나아 ?' 하고 묻는 것이 '이 응답은 몇 점이야 ?' 보다 신뢰도가 높다.

