Transformer Models
Scaling Up Transformers - 트랜스포머의 확장
트랜스포머 (Transformer)는 자연어 처리 (NLP)의 혁신을 이끈 모델이다. 점 점 더 깊고(레이어 수 증가), 넓고 (너비 증가), 똑똑해지며 (파라미터 증가) 이와 함께 학습 비용도 급격히 증가하고 있다.
| 모델 | 레이어 수 | 너비(Width) | 헤드 수 | 파라미터 수 | 학습 데이터량 | 학습 비용/시간 |
|---|---|---|---|---|---|---|
| Transformer-Base | 12 | 512 | 8 | 65M | - | 8x P100 (12시간) |
| Transformer-Large | 12 | 1024 | 16 | 213M | - | 8x P100 (3.5일) |
| BERT-Base | 12 | 768 | 12 | 110M | 13GB | - |
| BERT-Large | 24 | 1024 | 16 | 340M | 13GB | - |
| GPT-2 | 48 | 1600 | ? | 1.5B | 40GB | - |
| GPT-3 | 96 | 12,288 | 96 | 175B | 694GB | 약 $4.6 million |
| GPT-4 | ? | ? | ? | ? | ? | 약 $100 million |
Language Model 이란 ?
Language Model (언어모델)은 주어진 단어 시퀀스가 있을 때, 다음에 올 단어를 예측하는 모델이다.
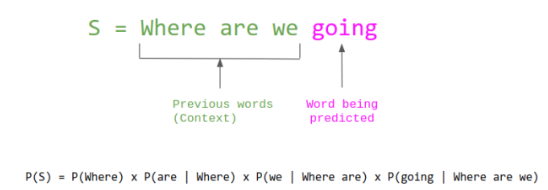
위에 사진과 같이,
예를 들어, 문장 Where are we going 이 있다고 할 때, 모델은 마지막 단어 'going' 을 예측하기 위해 앞의 문맥인 "Where are we" 를 사용한다.
전체 문장의 확률은 각 단어가 문맥 속에서 등장할 확률의 곱으로 계산된다.
Pre-training 과 Fine-Tuning
트랜스포머 모델은 단순히 처음부터 특정 작업을 학습하지 않는다. Transfer Learning (전이학습) 개념을 바탕으로 다음과 같은 2단계로 학습된다.
1. Pre-Training (사전 학습)
- 엄청나게 많은 텍스트 데이터를 활용해, 자기지도학습 (Self-supervised learning) 방식으로 언어의 패턴을 학습한다.
- 예시 : BookCorpus (8억 단어), Wikipedia (25억 단어)
- 목적 : '문장 구조, 어휘, 의미' 에 대한 일반적인 이해 능력을 기른다.
2. Fine-Tuning (미세 조정)
- 사전 학습된 모델을 가져와 특정 작업에 맞게 추가학습을 진행한다.
- 예 : 스팸 분류, 감정 분석, 질문 응답, 요약 등
- 지도학습 (Supervised learning) 방식으로 진행된다.
BERT
Bidirectional Encoder Representations from Transformers
BERT 는 2018년 Google AI에서 발표한 사전학습 (pretrained) 기반 언어 모델이다. 기존 트랜스포머 모델 중 Encoder 부분만 사용하여, 문장의 의미를 양방향으로 잘 파악할 수 있도록 설계되었다.
특징
- bidirectional : 왼쪽 문맥 + 오른쪽 문맥을 모두 참고하여 단어의 의미를 이해한다.
- encoder only : 트랜스포머 구조 중 encoder만 사용 (생성 불가)
- pretraining + fine-tuning : 대량의 텍스트로 먼저 학습 + 실제 task에 맞게 조금 더 학습
BERT의 입력 표현 (Input Representation)
BERT는 단어를 입력으로 받을 때, 아래와 같이 3가지 정보를 더해 사용한다.
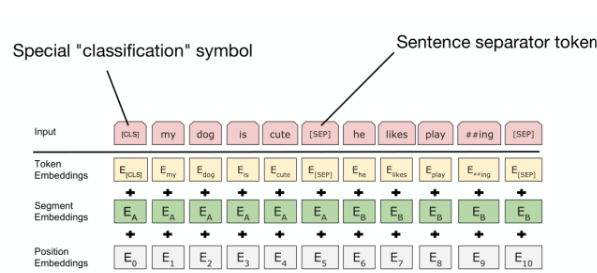
- Token Embedding : 단어 자체를 벡터로 표현
- Segment Embedding : 문장 A, 문장 B 구분
- Position Embedding : 단어의 순서 정보 반영
BERT의 Pretraining Task
1. Masked Language Modeling (MLM)
문장의 일부 단어를 가려놓고, 해당 단어를 맞히는 훈련
"A quick brown [MASK] jumps over the lazy dog"
전체 단어 중 15%만 선택
- 80%는 [MASK] 로
- 10%는 랜덤 단어로
- 10%는 그대로 유지
→ 다양한 상황에 잘 대응하도록 유도한다 !!
2. Next Sentence Prediction (NSP)
두 문장을 넣었을 때, 두 번째 문장이 실제 다음 문장인지 아닌지를 분류하는 작업
| 예시 | Label |
|---|---|
| "[CLS] the man went to [MASK] store [SEP] he bought milk [SEP]" | IsNext |
| "[CLS] the man went to the store [SEP] penguin are flightless [SEP]" | NotNext |
BERT의 Fine-Tuning
BERT는 사전 학습 후, 다양한 작업에 쉽게 활용된다. 보통은 BERT의 본체는 고정(frozen) 시켜두고, 출력층 (classifier) 만 교체하여 task에 맞게 학습한다.
예 : spam 분류, 감정 분석, 개체명 인식, 질문 응답, 문장 분류 등
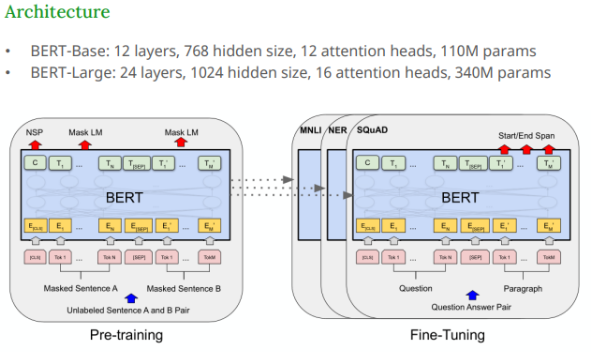
BERT가 할 수 없는 것 : 텍스트 생성 (BERT는 디코더가 없어서 문장을 만들어내지 못함)
GPT (Generative Pretrained Transformer)
GPT는 OpenAI가 만든 텍스트 생성에 특화된 모델로, BERT와 달리 Decoder만 사용하는 구조
특징
- Decoder-only 구조 (Encoder 없음)
- Autoregressive Language Modeling : 이전 단어들을 기반으로 다음 단어를 예측
- Masked Self-Attention 사용 : 미래 단어를 보지 않도록 제한
GPT 구조
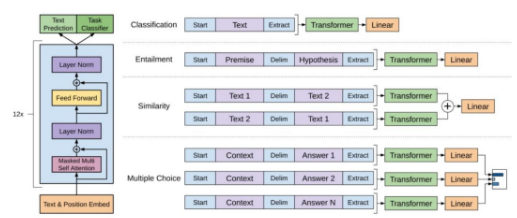
- Masked Multi-Head Self Attention
- 입력 토큰 중 이전 단어들만 참조
- 텍스트 생성 시 미래 정보 보지 않도록 막음
- Layer Norm (정규화) : 학습 안정성 향상
- Feed Forward : 비선형 변환으로 표현력 향상
다양한 Downstream tasks
오른쪽에는 Decoder 구조를 활용해 처리할 수 있는 여러 NLP 테스크 예시가 나와 있다.
| Task 유형 | 예시 입력 구조 | 설명 |
|---|---|---|
| Classification (분류) | Start Text Extract | 예: 스팸/비스팸, 감정 분류 등 |
| Entailment (문장 관계 판단) | Start Premise Delim Hypothesis Extract | Premise(전제)와 Hypothesis(가설) 간의 관계 (예: SNLI 데이터셋) |
| Similarity (유사도 판단) | Start Text1 Delim Text2 Extract | 두 문장의 의미 유사도 측정 |
| Multiple Choice (객관식 문제) | Start Context Delim AnswerN Extract | 주어진 문맥(Context)에 가장 적절한 정답 선택 (예: SAT 유형 문제) |
GPT-2
본격적인 생성 모델의 시작
- GPT-2는 다수의 Decoder 블록으로 구성된 모델
- 입력된 문장을 바탕으로 다음 단어를 예측하여 텍스트 생성
GPT-3
GPT-3는 GPT-2보다 훨씬 크고 강력한 모델이다. 학습량과 구조가 엄청난 만큼, 적은 예시만으로도 task를 수행하는 few-shot learning이 뛰어나다.
| 항목 | 수치 |
|---|---|
| Decoder 블록 수 | 96개 (GPT-2의 2배) |
| Context size | 2,048 (2배) |
| Embedding 크기 | 12,288 (8배 이상) |
| 파라미터 수 | 175B (GPT-2의 117배 이상!) |
GPT-4
GPT-4에 대해서는 정확한 구조 정보가 공개되지 않았다. 하지만, 다음과 같은 점은 명확하다.
- GPT-3보다 훨씬 크고 정교함
- 더 깊은 층, 더 넓은 임베딩, 더 많은 학습 데이터
- 일부 연구자들은 hidden size가 1024~2048임을 밝히기도 함
