Big-O Notation, Time Complexity, and Algorithm

알고리즘
어떠한 문제를 해결하기 위해,
정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것,
계산을 실행하기 위한 단계적 절차
Algorithm
-
어떤 목적을 달성하거나, 결과물을 만들기 위해, 거쳐야하는 일련의 과정들을 의미한다.
-
그 과정은 다양하며, 여러가지 상황에 따라, 알고리즘은 모두 다르다.
-
시간복잡도가 가장 낮은 알고리즘을 선택하여 사용한다.
-
알고리즘을 평가하는 기준에는 수행시간과 메모리 사용량이 있다.
-
수행시간에 해당하는 것이 시간복잡도이고, 메모리 사용량에 해당하는 것이 공간복잡도이다.
Time Complexity
문제를 해결하는데 걸리는 시간과 입력의 함수 관계
간단하게 정의하면, 알고리즘의 성능을 설명하는 것이다.
알고리즘이 문제를 해결하기 위한, 시간 및 연산의 횟수를 말한다.
cf ) 저장 기술의 발달로, 현재는 시간복잡도를 우선 고려하는 경우가 많다.
Time Complexity, Space Complexity
시간 복잡도란 내가 짠 코드의 실행 시간(Execution Time)을 예측해 얼마나 효율적인 코드인가를 나타내는 개념이다. 실행 시간은 연산(Operation)에 비례해 길어진다.
공간 복잡도는 코드가 얼마나 메모리 공간을 효율적으로 사용하는지에 대한 개념이다. 정적 배열이나 해시 테이블 처럼 공간을 미리 확보하는 자료구조에 자주 등장하는 개념이다.
일단 코드의 동작 유무가 우선 순위이지만, 중급 이상 개발자로 나아가기 위해서는 동작은 물론이고 효율도 중시해야하기 때문에 이러한 시공간 복잡도를 계산하여 효율적인 코드인지 파악하는 연습을 해야한다.
Asymptotic Notation (점근 표기법)
연산 횟수의 기준은 5가지가 있다.
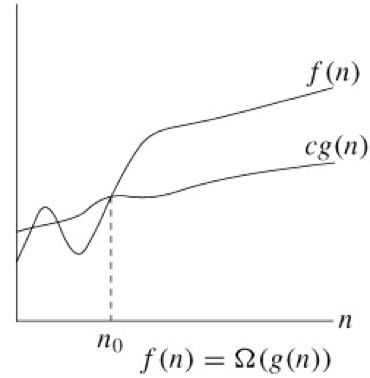
최선의 경우 ➡ 빅오메가(Ω) 표기법
빅-오메가라고 읽으며 점근적 하한선을 의미한다. (Asymptotic lower bound)
해당 알고리즘이 아무리 빨라도 기존 비교하는 함수와 같거나 혹은 좋지 않다는 뜻.
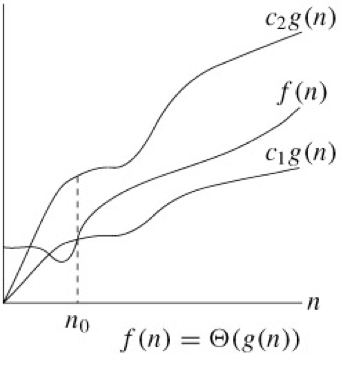
최악의 경우 ➡ 세타(Θ) 표기법
빅-세타라고 부르는 말로서 점근적 상한과 하한의 교집합을 의미한다. (Asymptotic tighter bound) 해당 알고리즘이 아무리 나쁘거나 좋더라도 기존의 비교하는 함수의 범위 안에 존재한다는 뜻이다.
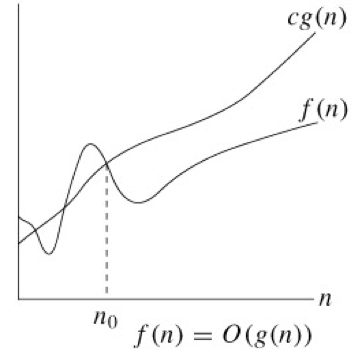
평균적인 경우 ➡ 빅오(O) 표기법
빅-오라고 부르며 점근적 상한선을 의미함. (Asymptotic upper bound). 즉 해당 알고리즘이 아무리 나빠도 기존 비교하는 함수와 같거나 혹은 좋다는 뜻. Big O 표기법이 알고리즘의 속도 및 공간 복잡도에서 대부분 객관적 지표로서 활용되는 표기법이다.
4. 소문자 (o) 표기법
5. 소문자 오메가(ω) 표기법
최악의 경우로 알고리즘의 성능을 파악한다.
최선과 최악이 아닌, 평균적인 경우가 가장 이상적일 것이라 생각되지만, 알고리즘이 복잡해질수록, 평균적인 경우를 구하기 어려워지기 때문이다.
Big O Notation
빅오(Big-O)는 시공간 복잡도를 수학적으로 표시하는 대표적인 방법이다. 단, 코드의 실제 러닝 타임을 표시하는 것이 아니며, 인풋 데이터 증가율에 따른 알고리즘의 성능을 (논리적으로) 예측하기 위해 사용한다. 빅오 표기법에는 다음 2가지 규칙이 있다.
가장 높은 차수만 남긴다.
O(n² + n) -> O(n²)계수 및 상수는 과감하게 버린다.
O(2n + 3) -> O(n) O(3N) ➡ O(N) O(N² +2) ➡ O(N²)
Time Complexity by Big-O Notation
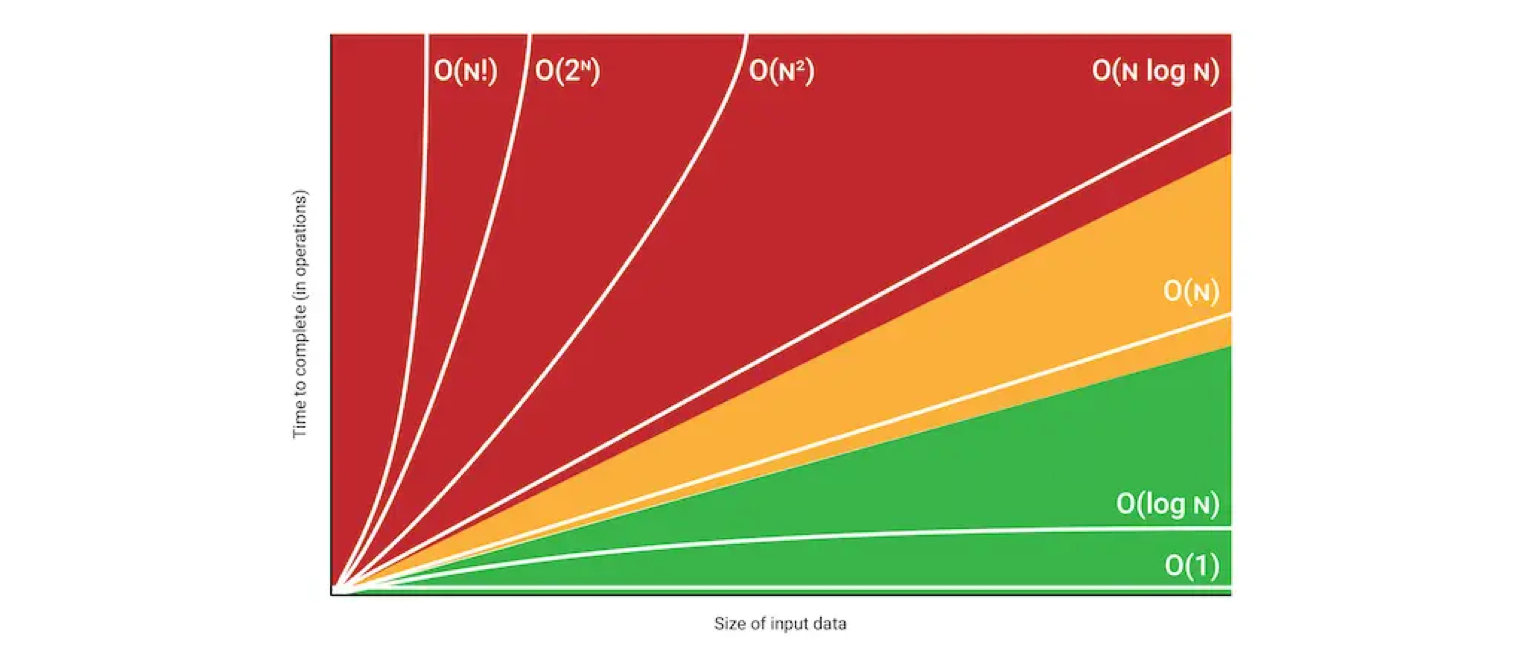
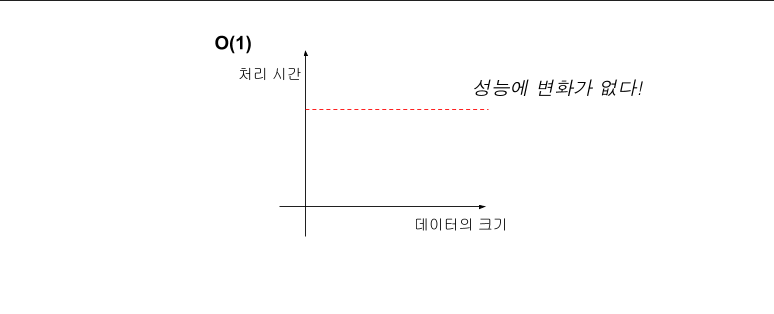
- O(1) (Constant)
입력 데이터의 크기에 상관없이 언제나 일정한 시간이 걸리는 알고리즘을 나타낸다. 데이터가 얼마나 증가하든 성능에 영향을 거의 미치지 않는다.스택에서 데이터를 넣고 빼고 할 경우 해당 시간이 소요. 데이터가 많아도 항상 같은 시간이 소요되는 경우
- O(log₂ n) (Logarithmic)
입력 데이터의 크기가 커질 수록 처리 시간이 로그(log: 지수 함수의 역함수) 만큼 짧아지는 알고리즘이다. 예를 들어 데이터가 10배가 되면, 처리 시간은 2배가 된다.이진 탐색이 대표적이며, 재귀가 순기능으로 이루어지는 경우도 해당된다.
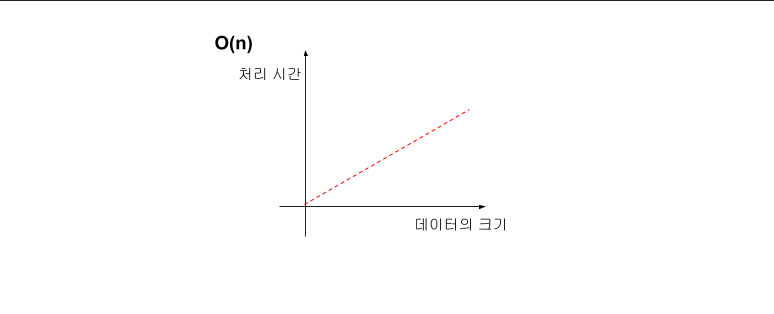
- O(n) (Linear)
입력 데이터의 크기에 비례해 처리 시간이 증가하는 알고리즘이다. 예를 들어 데이터가 10배가 되면, 처리 시간도 10배가 된다.선형 탐색 알고리즘이 대표적이다.
- 하나의 루프를 사용하여 단일 요소 집합을 반복하는 경우 : O(n)
- 절반 이상을 반복하는 경우 : O(n/2) ➡ O(n)
-
O(n log₂ n) (Linear-Logarithmic)
데이터가 많아질수록 처리시간이 로그(log) 배 만큼 더 늘어나는 알고리즘이다. 예를 들어 데이터가 10배가 되면, 처리 시간은 약 20배가 된다. 선형 시간보다는 약간 느리다정렬 알고리즘 Merge sort, Quick sort의 평균 시간 복잡도이다.
-
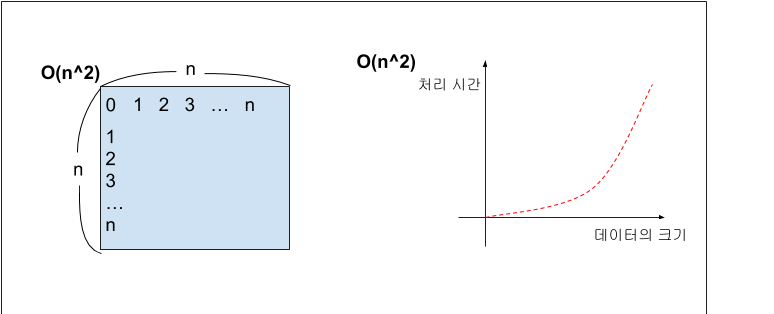
O(n²) (Quadratic)
데이터가 많아질수록 처리시간이 급수적으로 늘어나는 알고리즘이다. 예를 들어 데이터가 10배가 되면, 처리 시간은 최대 100배가 된다.
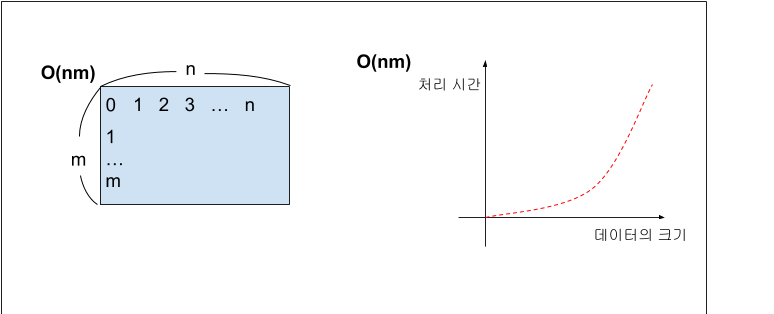
이중 루프(n² matrix)가 대표적이다. 단, m이 n보다 작을 때는 반드시 O(nm)로 표시하는것이 바람직하다.이중 루프문, 삽입 정렬, 선택 정렬, 버블 정렬 등이 이에 해당
두 개의 다른 루프를 사용하여 각각 반복하는 경우 : O(n∗m) ➡ O(n²)
- O(2ⁿ) (Exponential)
데이터량이 많아질수록 처리시간이 기하급수적으로 늘어나는 알고리즘이다.대표적으로 피보나치 수열이 있으며, 재귀가 역기능을 할 경우도 해당된다.
다음의 글을 참고하였습니다.
