
토요지식회 오픈
매주 오프라인 정기 모임에서는 과제 리뷰를 하기 전, 토요지식회 시간을 갖는다.
발제 내용 말고도 AI 관련해서 자신이 시도한 것이나 배운 것들을 공유하는 시간인데 이번에는 두 분이 나오셔서 각각 MCP와 트랜스포머의 파라미터 수를 직접 계산하는 것에 대해 발표했다.
MCP 관련 발표가 흥미로웠는데, 발표자 분은 클로드 데스크탑에 MCP 환경을 구축해서 리서치, 블로그 글 작성, 일정 관리까지 활용하고 있었다.
오~ 매우 흥미로워... 나도 시도해보고 싶긴한데 지금 회사 + 방통대 중간고사 기간 + 부트캠프 과제 쓰리콤보로 부트캠프가 끝나야 시도를 해볼 수 있을 것 같다 하하ㅜㅠ
3주차 과제 회고
이번 과제는 MNLI 태스크를 BERT-base, distilBERT, 그리고 사전학습 하지 않은 Transformer에 각각 학습시켜서 정확도와 커브를 비교 분석해보았다.
- *Multi-genre natural language inference(MNLI) : 두 문장이 주어졌을 때 논리적으로 연결이 되어 있는지, 서로 모순되는지, 아니면 아예 무관한지 분류하는 문제다.
MNLI 데이터 셋의 구성요소는 아래와 같다.
- premise (전제)
- hypothesis (가설)
- labels ✅ label의 종류
- 함의(Entailment): 전제가 가설을 지 지하는 경우. -> 0
- 중립(Neutral): 전제가 가설에 대해 중립적이거나 관련이 없는 경우. -> 1
- 모순(Contradiction): 전제가 가설과 모순되는 경우. -> 2
결과를 말하자면 distilBert와 Bert-base의 정확도 차이는 크지 않았고 오히려 distilBert가 약 5%차이로 더 좋은 성능을 내줬다.
BERT-base
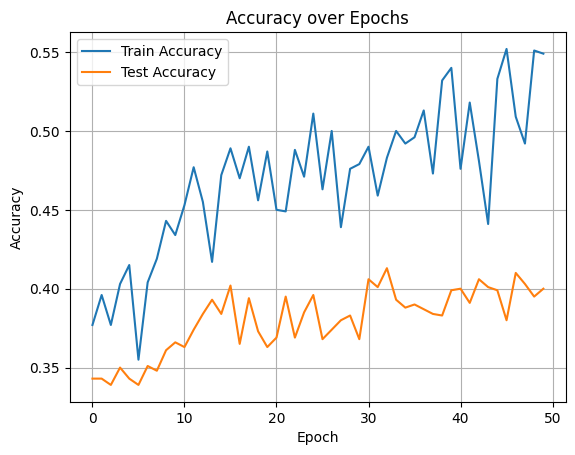
DistilBert
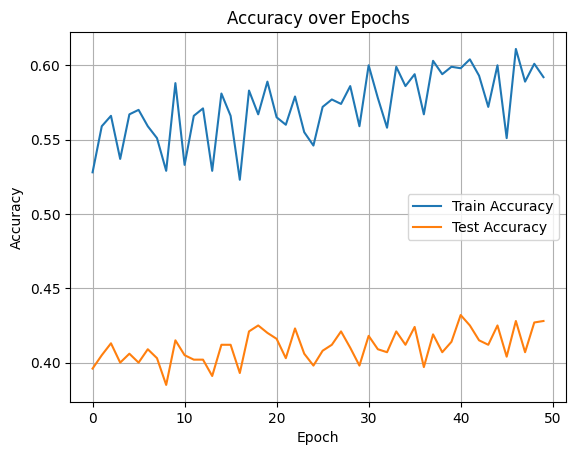
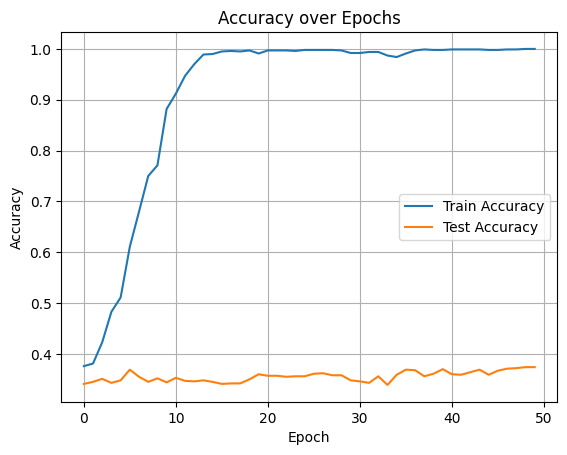
사전학습하지 않은 트랜스포머에서는 freeze하지 않고 전체학습을 시켰는데, 그래서 학습용 데이터셋에 대한 정확도가 거의 1에 가까웠다.
자세한 내용은 아래의 깃헙에서 볼 수 있다.
https://github.com/sosososoyoen/hh_plus_ai_3/tree/main/work/week3/%EC%8B%AC%ED%99%94
아쉬웠던 점은, BERT에서는 freeze를 한 상태에서 학습을 시켰는데, 트랜스포머에서는 전체 학습을 시켜버렸다는 것이다.
그리고 다른 학생분들이 한 것을 보았는데 다른 학생분들은 pandas를 이용해 데이터 샘플이나 데이터 분석을 체계적으로 하여 깔끔하게 보고서를 썼는데
아 .. 이런 방법도 있구나! 하는 생각이 들었다.
같은 태스크를 비슷한 방식으로 해결했는데도, 테스트를 어떻게 하느냐에 따라서 보고서의 퀄리티가 달라지는 것 같다.
AI는 개발이 아니라 통계와 분석에 가깝다는 말을 들은 적이 있었는데 그 말이 맞는 것 같다.
비록 부족한 과제였지만, 그래도 Best Practice로 선정되어서 기쁘긴하다.
부트캠프 티어(게임 티어와 비슷)도 이번 과제들로 한 단계 승급해서 기분이 좋다ㅎㅎ
Transfer Learning(전이 학습)
- 사전 학습 모델(Pre-trained 모델) : 이미 충분한 데이터로 학습한 모델
- 파인 튜닝 : 사전 학습 모델로 자연어 처리 문제를 푸는 모델을 학습하는 것
Pre-training
- Supervised pre-training : 입력값과 정답값이 나뉘어져 있는 자연어 처리 문제에 대해서 모델을 학습하는 방식
학습 데이터가 정답을 가지고 있음.
감정 분석(긍정/부정), 스펨 메일 분류 - Unsupervised pre-training : 주어진 입력값으로부터 가상의 label(정답)값을 생성해서 그것을 맞추는 방향으로 학습하는 방식
데이터에 정답이 없음
모델이 스스로 데이터의 패턴, 구조, 관계를 학습함
단어 임베딩, 텍스트 카테고리 분석
문장에서 단어 하나를 마스킹하고 이것을 맞추는 방식(MLM)도 포함
파인튜닝의 학습 방식
- 모든 파라미터를 포함하여 전체 모델 학습
* 마지막 classification 레이어를 태스크에 맞게 다시 정의하고, 나머지 부분은 사전 학습 모델의 파라미터들로 초기화 함 - 특정 레이어를 freeze하여 학습 (많이 사용!)
* 일반적으로 classification 레이어를 제외한 파라미터들을 고정함
왜 특정 레이어를 freeze해서 학습하는 걸까?
- 모든 파라미터를 학습 시키는 방식에는 메모리 이슈가 발생함
최신 언어 모델들은 파라미터의 개수가 수억, 수십억 개라 이 모든 파라미터를 학습시키면 메모리 사용량이 증가한다.
학습 시에는 각 파라미터에 대한 경사(gradient)와 파라미터의 현재 상태를 메모리에 저장 => 메모리 사용량 증가 - 오버피팅 이슈
* 파라미터가 많은 상황에서 적은 데이터로 학습을 하면, 데이터를 전부 다 외워버려서 예측을 잘 못하게 됨
BERT
- 트랜스포머 인코더를 사용한 모델
- 이전의 Left-to-Right (Autoregressive)한 방식이 아닌 Bidirectional한 방법으로 모델 학습을 시도한다.
* left-to-Right 방식은 시퀀스 투 시퀀스를 생각하면 될 것 같다. - unsupervised 방식으로 사전 학습 모델을 학습시키는 방식
- 입력값은 자연어로 하고 label이 필요 없기 때문에 위키나 인터넷에서 구한 텍스트를 그대로 입력값으로 사용할 수 있다.
- MLM, NSP 방식으로 사전 학습을 진행한다.
Masked Language Model (MLM)
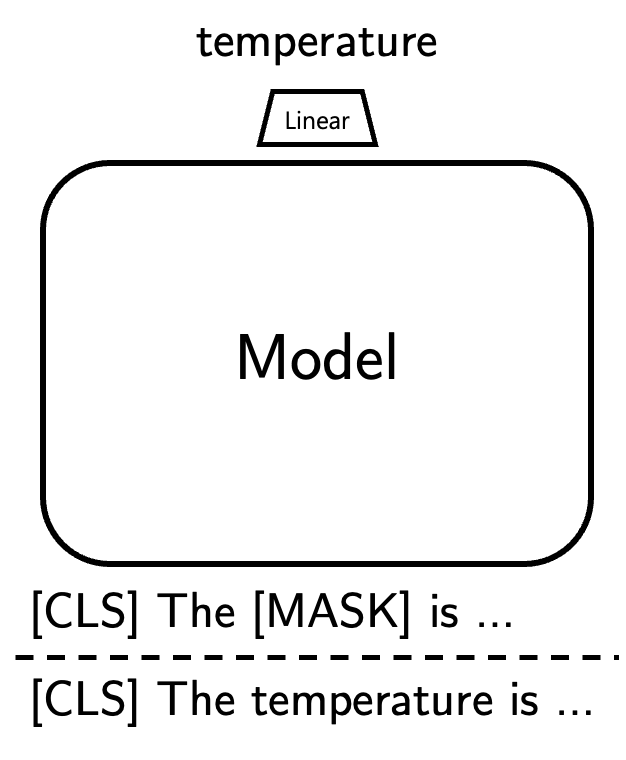
- BERT에서 사용하는 학습 방식
- 문장의 일부분을 지웠을 때(=마스킹 했을 때), 문장의 나머지 부분을 보고 마스킹된 단어를 맞추는 식으로 학습하는 것.
- 특정 토큰 마스크 : 학습 단계에서 랜덤하게 토큰들을
[MASK]라는 스페셜 토큰으로 바꿈 - 마스크한 토큰 예측
Next sentence prediction (NSP)
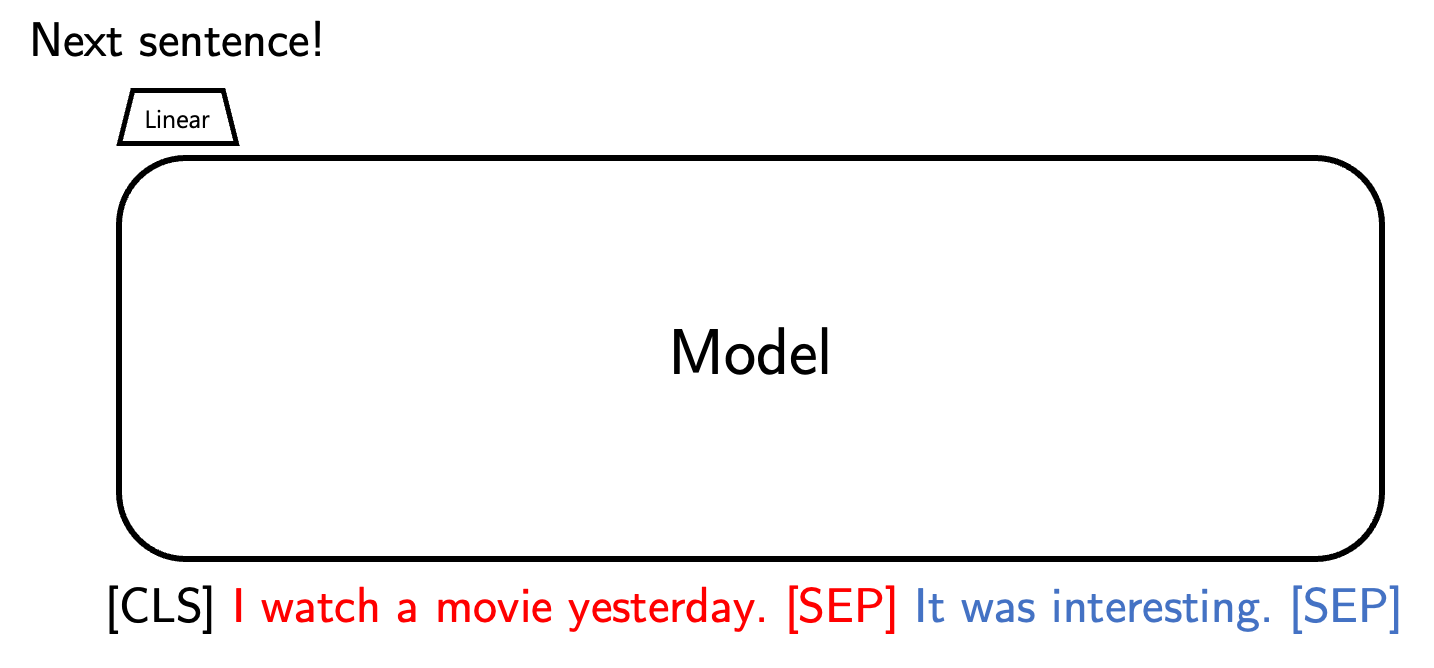
- BERT에서 사용하는 학습 방식
- 입력값이 두 문장으로 이루어져있을 때, 두 문장이 실제로 이어진 문장인지, 아니면 별개의 문장인지 맞추는 식으로 학습한다.
DistilBERT
- Knowledge distillation(지식 증류)라는 방식을 통해 BERT와 비슷한 성능을 내지만 빠르고 가볍게 경량화를 시킨 모델
Knowledge distillation(지식 증류)의 과정
- 선생, 학생 모델 선정
- 선생 모델 : 성능이 좋은 사전학습 모델
- 학생 모델 : 우리가 학습시키고자 하는 소형 모델
- soft label 생성
- 선생 모델을 통해 soft label를 생성함
- 예를 들어 MLM 에서 마스킹 된 단어에 대해 선생 모델이 예측한 값을 label로 삼는다.
- 이 때 soft label은 argmax를 하기 전 값을 의미함!
- 학생 모델 학습 : 생성한 soft label을 가지고 학생 모델을 학습시킨다.
GPT
- Generative(생성하는) Pre-trained(사전 학습된) Transformer(트랜스포머)
- 방대한 양의 텍스트 데이터셋에서 자연어의 패턴을 학습한 후, 텍스트를 이해하고 생성한다.
- BERT와 비슷한 방식으로 사전 학습을 진행한 모델
* 기본적인 아이디어는 BERT의 MLM과 비슷하지만 조금 다른 next token prediction이라는 방식으로 학습한다.
next token prediction
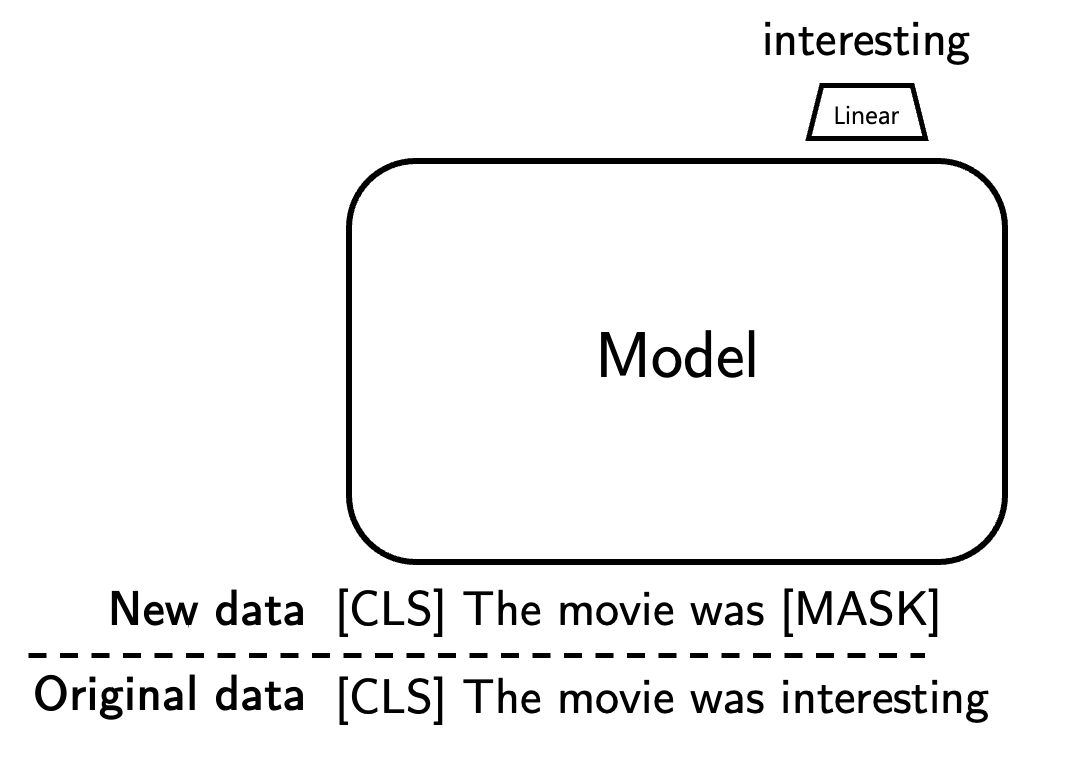
- 기존의 MLM은 문장 중간의 토큰을 마스킹하고, 이를 맞추는 방식
- 이것은 문장의 마지막 토큰을 마스킹하고 맞추는, 앞의 문장만 보고 예측하는 방식
- 이 방식은 랜덤한 마스킹이 필요 없고, 문장 전체를 가지고 학습할 수 있다.
BERT와의 차이점 - Text generative model
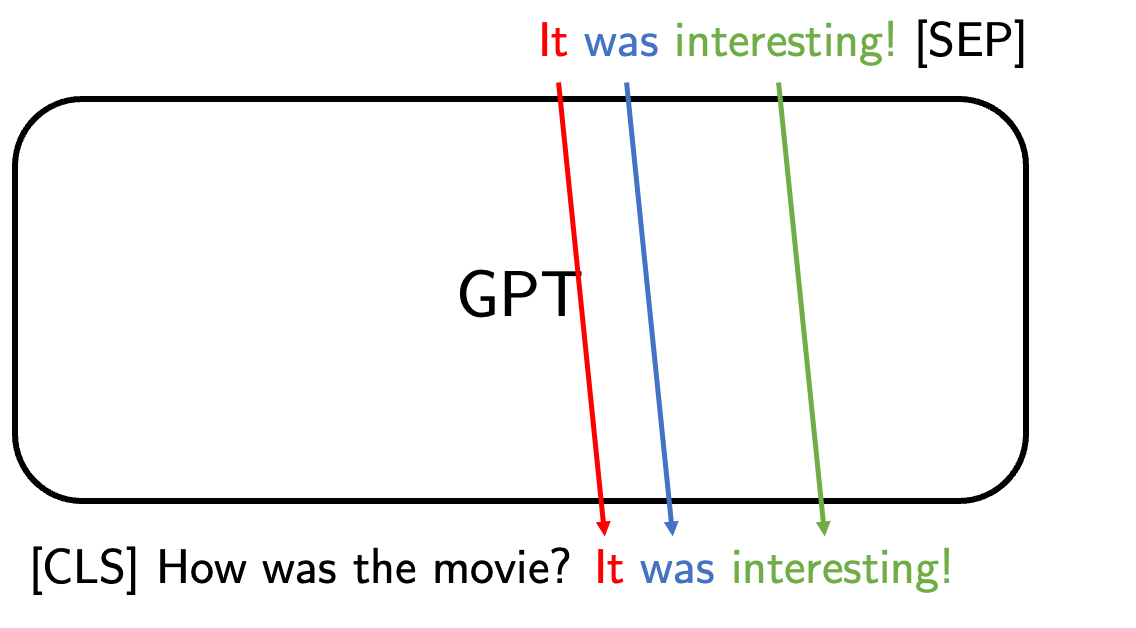
GPT가 예측값을 출력하는 과정은 아래와 같다.
1. 주어진 문장을 보고 토큰 생성
GPT에 문장을 입력하면, next token prediction과 같은 방식으로 문장 다음의 토큰을 생성함
2. 생성한 토큰을 주어진 문장에 concat한다.
위에서 생성된 토큰을 주어진 문장에 붙인다. 그리고 이것을 다시 GPT에 입력하여 토큰을 생성한다. 이 과정을 반복하여 문장을 얻는다.
3. 스페셜 토큰이 나올 때까지 생성
* BERT의 [SEP] , GPT의 <|endoftext|> 와 같은 문장의 끝을 의미하는 토큰이 나올 때까지 반복
시퀀스 투 시퀀스 모델의 디코더가 텍스트를 생성하는 방식과 동일하다.
BERT는 마스킹된 토큰을 예측할 때 모든 문장을 토대로 예측하기 때문에 text를 생성할 수 없다.
반면, GPT는 마스킹 토큰 이전에 나온 토큰들을 가지고 예측하기 때문에 text 생성에 활용할 수 있다.
Large Language Model (LLM)
- GPT 모델의 파라미터 수와 300B의 토큰을 학습시켜 내보인 모델
- 기계 번역, 질의 응답, 수학 연산에 있는 자연어 처리 문제들에 대해서 파인튜닝을 하지 않아도 괜찮은 정답을 내놓는 수준까지 오게 되었다.
- few-shot-learning이라는, 문제의 예시를 먼저 보여주고 주어진 문제를 풀게하는 방식으로도 태스크를 잘 해결할 수 있다.
🌟🌟 BERT와 LLM의 모델 선택 기준
BERT 사용이 적합한 경우
- 입력이 짧고
- 분류, 추천, 의도 분석 등 비교적 단순한 task일 때
- 고성능 GPU가 부족할 때
- 특정 도메인에 대해 이미 훈련된 언어 모델을 그대로 활용하고 싶을 때
- 단점 : 자연어를 입력했을 때, 구조적인 한계로 새로운 텍스트 생성(요약, 번역 등)에 약함
LLM 사용 적합한 경우
- 요약, 생성, 검색 증강, 수학 문제 풀기 등 다양한 언어 추론이 필요한 경우
- 멀티모달 데이터(이미지 + 텍스트 등) 기반 추천 기능
🌟BERT vs GPT 계열 모델 성격 비교
| 항목 | BERT | GPT/LLM |
|---|---|---|
| 방향성 | 양방향 | 단방향(left to right) |
| 구조 | 인코더 | 디코더 |
| 주요 용도 | 분류, 임베딩 추출 | 생성, 요약, 생성기반 QA |
| 파라미터 크기 | 작음(0.1B~1B) | 큼(7B ~ 1000B) |
#항해99 #항해플러스 #AI #AI개발자 #항해플러스AI후기 #LLM #트랜스포머 #NLP
