드디어 4주차부터 본격적으로 허깅페이스의 Trainer을 사용한다.
이번 주차부터 실습 위주라서 앞으로는 내가 진행한 과제를 위주로 WIL를 작성할 것 같다.
기본 과제 맛보기 : HuggingFace로 MNLI 문제 해결하기
지난주 과제로 파이토치로 BERT 모델을 학습시켜서 MNLI 문제를 해결했었는데 이 코드를 그대로 허깅페이스 라이브러리로 옮기는 것이 이번 주의 기본 과제였다.
자세한 코드는 아래에서 확인할 수 있다.
https://github.com/sosososoyoen/hh_plus_ai_3/blob/main/work/week4/%EA%B8%B0%EB%B3%B8/MNLI_HF_transformer.ipynb
Multi-genre natural language inference(MNLI)란?
- 두 문장이 주어졌을 때 논리적으로 연결이 되어 있는지, 서로 모순되는지, 아니면 아예 무관한지 분류하는 문제!
- MNLI 데이터 셋의 구성요소
- 모델 학습에 필요한 '전제, 가설, 라벨' 형태로 가공한다.
- premise (전제) hypothesis (가설) labels (라벨)
- ✅ 라벨의 종류
- *함의(Entailment): 전제가 가설을 지 지하는 경우. -> 0
- *중립(Neutral): 전제가 가설에 대해 중립적이거나 관련이 없는 경우. -> 1
- *모순(Contradiction): 전제가 가설과 모순되는 경우. -> 2
저번 주에 다른 수강생 분들이 과제를 진행한 것을 보니까, 데이터를 멋드러지게 dataframe으로 출력해서 체크를 하시길래... 이번 과제에서는 나도 데이터를 잘 정리하고 시각화 하는 것에 중점을 맞추었다.
데이터 전처리에 따른 학습 모델 평가 비교
토크나이저를 활용하여 전제와 가설 문장들을 연결해서 학습시켰을 경우
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
# 전처리 함수 정의
def preprocess_function(examples):
return tokenizer( examples["premise"], examples["hypothesis"],
truncation=True, padding="longest", )- BERT 계열의 토크나이저는 문장쌍까지만 구조적으로 구분 가능 => premise, hypothesis 문장 따로 전달
tokenizer(
text = "문장1", # 또는
text_pair = "문장2", # 문장쌍일 때
truncation = True, # 너무 길면 자름
padding = "longest", # 가장 긴 입력의 길이에 맞춰서 패딩 토큰을 자동으로 채워줌
max_length = 128, # 최대 길이
return_tensors = "pt" # torch 텐서로 반환 (선택)
)[CLS] premise [SEP] hypothesis [SEP]구조를 사용하기로 함- token_type_ids(문장을 구분해주는 인덱스)을 통해 모델이 문장을 쉽게 분리할 수 있도록 처리
[7365/7365 21:08, Epoch 3/3]
| Epoch | Training Loss | Validation Loss | Accuracy | F1 |
|---|---|---|---|---|
| 1 | 0.866200 | 0.868188 | 0.603328 | 0.594561 |
| 2 | 0.796400 | 0.844906 | 0.624222 | 0.624192 |
| 3 | 0.732300 | 0.867255 | 0.623738 | 0.623072 |
Out[54]:
TrainOutput(global_step=7365, training_loss=0.7982978111210115, metrics={'train_runtime': 1268.5338, 'train_samples_per_second': 742.97, 'train_steps_per_second': 5.806, 'total_flos': 130220993318850.0, 'train_loss': 0.7982978111210115, 'epoch': 3.0})
스페셜 토큰 없이 전제와 가설을 이어서 한 문장으로 만들어서 학습 시켰을 경우
def preprocess_function(data):
text = []
for i in range(len(data['premise'])):
text.append(data['premise'][i] + data['hypothesis'][i])
return tokenizer(text, truncation=True)| Epoch | Training Loss | Validation Loss | Accuracy | F1 |
|---|---|---|---|---|
| 1 | 0.932600 | 0.958541 | 0.527903 | 0.530360 |
| 2 | 0.899600 | 0.951936 | 0.532397 | 0.533510 |
| 3 | 0.852900 | 0.969038 | 0.533938 | 0.534887 |
TrainOutput(global_step=7365, training_loss=0.8950229787211473, metrics={'train_runtime': 354.5992, 'train_samples_per_second': 2657.882, 'train_steps_per_second': 20.77, 'total_flos': 39329901033570.0, 'train_loss': 0.8950229787211473, 'epoch': 3.0}
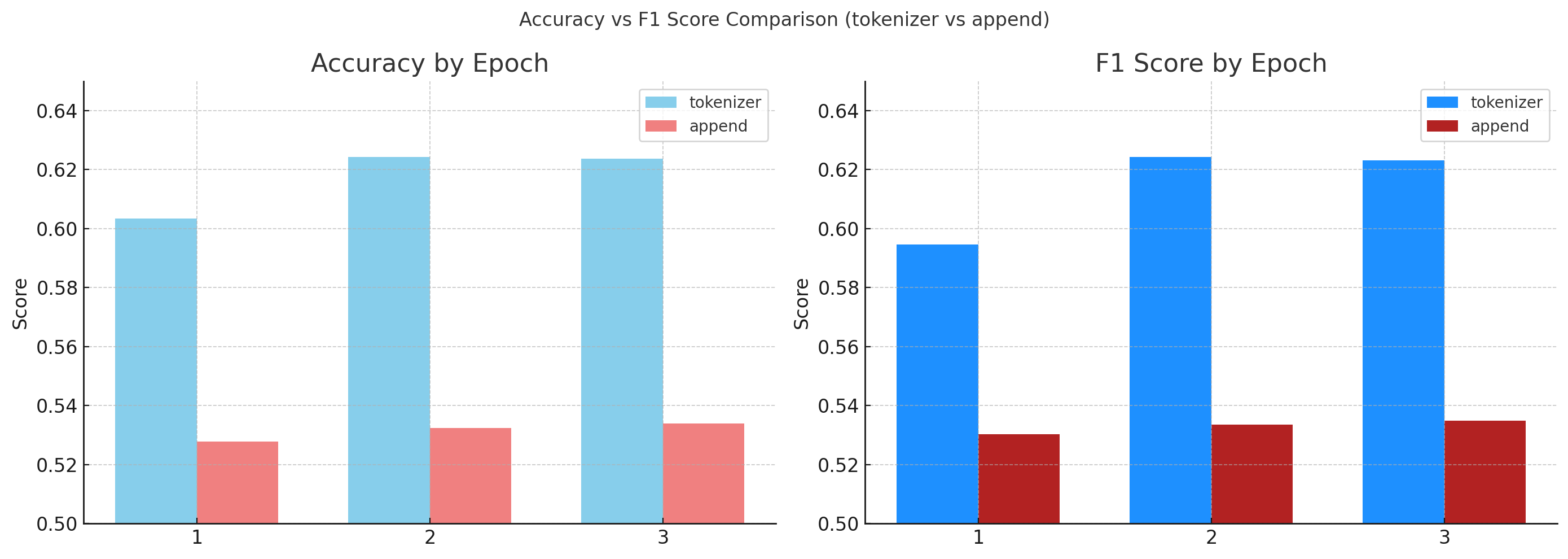
정확도가 약 10% 정도 상승한 것을 확인할 수 있었다.
이렇게 된 이유에는 BERT의 구조 때문인데,
BERT 자체가 문장 중간에 [SEP]토큰을 경계로 두고, self-attention으로 문장을 분석하고 학습하기 때문이다.
과제 Q&A 섹션
매주 평일 저녁, 그 주 발제를 맡으신 코치님이 직접 Q&A 세션을 진행하신다.
지금까지 시간이 맞지 않아서 4주차에 드디어 첫 참석을 하게 되었다.
세션 시작 전 구글폼으로 익명 질문을 받는데, 익명이니 사소한 질문들도 부담 없이 물어볼 수 있었다ㅋㅋㅋ
코치님이 질문 하나하나 열심히 답해주셔서 좋았음.
코치님이 마지막에 조언을 해주셨다.
✨ 좋은 AI 개발의 근본 = 끊임 없는 비교 실험을 통한 모델 개선 + 비용 절감! ✨
그래서 나도 곧 있을 개인 프로젝트에 랭체인과 RAG를 적극 활용하여서 가성비 있는 AI 서비스를구축해보고자 한다.
아래에 내가 한 질문들과 답변을 정리해보았다.
**질문 1.
기본 과제에서 Trainer 사용해서 학습하면 wandb 로그인하라고 뜨는데, 혹시 실무에서는 wandb가 필수일까요?
A.
네 wandb나 mlflow같은 실험 관리 도구는 실무에서 거의 필수다 싶을 정도로 매우 유용한 실험 도구입니다.
모델 하나의 학습 양상 뿐만 아니라 여러 설정 값(hyperparameter)에 따른 모델들의 성능도 직관적으로 확인할 수 있고, 수 백 개의 실험 중 가장 좋은 세팅을 찾아내는 데도 유용합니다.
**질문 2.
허깅페이스의 evaluate에서 f1는 뭘 평가하는 것일까요?
- f1 score는 recall(민감도)과 precision(정밀도) 의 조화 평균 값입니다.
- 문제 예시: 환자 정보를 보고 암인지 아닌지 분류하는 문제
- 모델: 암이면 1, 아니면 0을 출력 전체 환자 1000명, 암 환자 100명
recall: 모델이 예측한 실제 암 환자 수 / 전체 암 환자 recall이 60%다 = 실제 암 환자 100명 중에 60명은 예측했다. recall을 100%로 만드는 방법? 모든 환자를 암 환자라고 예측하면 됩니다.
precision: 모델이 예측한 실제 암 환자 수 / 모델이 암이라고 예측한 환자 수 recall을 100%면? precision의 분모가 1000, 분자가 100, -> 10% -> recall(민감도)이 증가하면, precision은 감소하는 경향이 있음. 이 두 개를 조화롭게 보면서 모델의 성능을 판단하기 위해 -> 이걸 조화 평균을 해서 f-1 score라는 게 만들어짐
추가 질문!
정확도보다 f1이 더 신뢰 가는 평가 기준일까요?
A.
- 정확도=accuracy=실제 라벨값과 예측한 라벨값의 일치도
- 근데 문제는 데이터가 불균형하면 정확도가 의마가 없음
- 전체 환자 1000명, 암 환자 10명 모델이 모든 환자를 암이 아니라고 예측 -> 정확도 99% (1000명 중에 990명은 맞혔으니까)
- 이러한 단점을 보완하기 위해 정밀도, 민감도, 특이도 등 다양한 지표 사용 Confusion Matrix 개념을 완벽히 이해하면, 데이터 분석/모델 평가에 있어 새로운 시각을 얻을 수 있습니다.
* -> 여기서 더 나아가면, AUROC, AUPRC
**질문 3.
BERT를 학습시켰는데 이후에 데이터셋의 label 값들이 잘못되었다는 것을 알게 되었다면, 어떻게 해야 하나요?
A.
- Manual re-labeling: 직접 확인 후 수정
- 첫 모델 학습 후, 모델이 잘 틀리는 데이터들만 모아서 분석
- 라벨이 1인데, 모델 예측이 0.01 이런 경우 -> 데이터를 직접 보면서 라벨이 실제로 잘못된건지 확인
* -> 하나하나 전부 볼 수는 없으니, 이러한 데이터들의 특성, 통계적인 경향성을 분석해서, 모델의 학습이 잘못된 건지, 데이터가 이상한 건지 판단이 필요 - re-labeling 하거나, 학습/평가에서 제외 시켜야 함
- 애매한 경우라면 soft-labeling
질문4.
만일 프롬프트의 길이가 너무 길어지는 경우에는 어떻게 해야하나요?
A.
- 너무 길다면 프롬프트를 chunking 후 각 청크를 langchain의 load_summarize_chain과 같은 함수를 활용해서 요약할 수 있습니다.
- 코드 예시:
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
)
chunks = splitter.split_text(very_long_document)
# 각 Chunk 요약
from langchain.chains.summarize import load_summarize_chain
chain = load_summarize_chain(llm, chain_type="map_reduce")
summary = chain.run(chunks)
prompt = PromptTemplate(
input_variables=["summary"],
template="""
다음은 보고서의 요약입니다:
{summary}
이 요약을 바탕으로 독자가 궁금해할 수 있는 질문 5개를 생성하세요.
"""
)
llm_chain = LLMChain(llm=llm, prompt=prompt)
questions = llm_chain.run(summary)
**질문 5.
만약에 챗봇서비스를 만드는데 정답이 분명하지않다, 라고 하면 어떻게 성능을 평가할 수 있을까요?? 예를들면 상담을 해주거나, 추천을 해주는 경우에요!
A.
- 기존에 동일한 서비스를 하고 있는데, 이걸 LLM으로 대체하는 경우는 상담만족도/구매내역 같은 데이터가 있기 때문에, 이걸로 학습/평가 같은게 가능 (새로운 데이터가 입력되더라도, 기존 데이터에 비슷한 데이터 찾아서(retrieval) 라벨링 가능)
- 우리가 새로운 서비를 만들 때 -> chatGPT 4o generation, labeling -Human Feedback으로 보상 설정 (추천결과에 대해 유저가 직접 scoring)
- 프로젝트 시작하는 시점에서 가장 중요한것
* 내 LLM 모델의 성능을 평가하는 지표 설정 (어떻게 평가해야 하나?)
마치며
4주차는 3주차에 비해 과제에 좀 더 집중할 수 있어서, 데이터 전처리에 대해 고민도 해보고, 데이터 분석하는 방식에 대해 많이 고민해보았다. (이 글에서는 데이터 분석에 대한 내용은 없지만 추후에 다른 포스트로 올릴 예정임)
5주차부터는 본격적으로 LLM 서비스 프로젝트를 위한 초읽기에 들어갈텐데, 부디 무사히 잘 완성할 수 있길 바란다ㅎㅎ
#항해99 #항해플러스 #AI #AI개발자 #항해플러스AI후기 #LLM
