자료구조란?
- 데이터를 원하는 규칙 또는 목적에 맞게 저장하기 위한 구조
** 자료구조가 중요한 이유 - 메모리를 효율적으로 사용하면서 데이터를 빠르고 안정적으로 처리하기 위함
Array
- 한 가지 자료형만 담을 수 있다.(primitive, object타입 모두 가능)
- Random Access가 가능하다 -> 시간 복잡도 O(1)
- 크기가 불변하다. -> 컴파일 시간에 stack에 할당된다.
- 다차원이 가능하다.
- 삽입, 삭제 시 많은 비용이 든다.
Array를 사용하면 좋을 데이터
- 순차적인 데이터
- 수정, 삭제가 적은 데이터
- 인덱스를 활용하여 빠르게 값을 찾을 수 있는 데이터
- 주식 관련 데이터
- 데이터의 수정, 삭제가 없고 오로지 append만 존재하기 때문
- 주식 관련 데이터
Array vs ArrayList
- ArrayList는
- 수정, 삭제가 가능하다.
- 사이즈가 동적이다.
- Object타입만 저장 가능하다.
- generic을 활용하여 type-safe를 보장한다.
- Array보다 느리다
- capacity를 활용하여 크기를 동적으로 변환시킬 수 있다.
- 런타임시간에 heap에 할당된다.
- 공통점 : 중복되는 요소 저장 가능. index로 요소를 꺼내올 수 있다.
List 종류
- 순차적으로 데이터가 저장. 중복 데이터 저장 가능.
- ArrayList
- Thread-safe지원X
- 삽입, 삭제 시 시간 많이 걸림(순차적으로 옮기는 방법 사용)
- 따라서 stack에 적합
- capacity가 모두 찰 시 capacity * 1/2만큼 증가
- random access 가능
- LinkedList
- 각 데이터마다 다음 데이터의 주소값을 저장
- 따라서 삽입/삭제가 용이 -> Queue에 적합
- sequential access 가능
- vector
- Thread-safe한 키워드 제공
- synchronized 키워드 사용- 성능 저하
- 한번에 한 스레드만 접근 가능
- capacity가 100% 증가
- Thread-safe한 키워드 제공
Hash 알고리즘
- 배열과 연결 리스트로 구성되어 있다.
- 저장할 key를 hash function에 넣어서 나온 index에 연결리스트로 저장한다.
Set 종류
-
데이터 중복 저장 허용X, 순서 보장X
-
hashcode와 equals를 사용하여 데이터를 비교한다.
- 먼저 hashcode를 이용하여 비교 -> 왜냐하면 hashcode는 Integer인데 반해 value는 String일 수도 있는데, Integer의 비교시간이 훨씬 빠르기 때문이다.- equals를 이용하기에 주소값이 다른 String도 비교 가능하다.
-
내부적으로는 hashmap을 이용한다.
- hashmap은 key값이 중복허용이 안되기 때문. value는 dummy값으로 채운다.
-
HashSet
- 기본적인 set. 순서 보장이 안됨
-
LinkedHashSet
- 순서 보장이 되는 set. 성능이 느리다.
-
TreeSet
- 들어온 대로 정렬을 지원해준다.
- 조회, 검색 성능이 빠르다. -> O(logn)의 시간복잡도
- 중복 저장X, 순서 보장X
- 데이터의 추가/삭제 시간이 오래걸린다.
Map의 종류
- 키는 중복X, value는 중복 허용
- 동일한 키일 경우 value는 덮어씌워짐
- HashTable
- thread-safe
- 성능 저하
- 키, value null 허용X
- HashMap
- 키, value null 허용
- 순서 보장X
- LinkedHashMap
- 순서 보장 O
- LinkedList형태로 저장
- ConcurrentHashMap
- 자원마다 락을 따로 걸기 때문에 병렬적 처리가 가능하다.
- HashTable의 Thread-safe와 HashMap의 조합
- 블록 단위로 synchronized
- 노드가 존재하지 않을 때
- CAS 알고리즘으로 현재 쓰레드의 값과 메인 메모리의 값을 확인한 뒤 삽입
- 노드가 이미 존재할 때
- synchronized 키워드로 한 스레드만 접근 가능하도록 설정
해시충돌 시 해결방법
- 오픈 어드레싱 방법
- Linear Probing : 충돌 발생 시 n칸 옆을 검사
- Quadratic Probing : 충돌 발생 시 n제곱 칸 옆을 검사
- 이중 해쉬
- 1차 해쉬
- 키를 근거로 저장위치를 결정- 2차 해쉬
- 충돌발생 시 어디에 저장할 지 결정
장점 : 추가저장공간 필요X
단점 : 해시함수의 성능에 따라 테이블의 성능이 달라진다.
- 2차 해쉬
- 세퍼레이트 체이닝
- Separate Chaining
- 데이터 8개 전까지는 linkedList / 이후부터는 tree로 변경된다.
graph 구현 두가지
- arrayList 1차원 배열 [인접그래프]
- 메모리 효율적
- 희소 그래프에 사용하기 좋다.
- dfs
- 2차원 배열
- 쉽다
- 인덱스로 바로 접근이 가능하다.
- 밀집 그래프에 사용하기 좋다.
- 시간복잡도가 크다
이진트리
- 자식은 최대 2개 트리
이진탐색트리
- 정렬이 된 트리
- 왼쪽은 작은 값, 오른쪽은 큰 값
- O(logn) / 최악 : O(N)
stack 과 queue의 공통점 차이점
- 공통점
- ArrayList, LinkedList로 구현 가능
- 차이점
- stack: 선입후출
- queue: 선입선출
B- tree/ B+ Tree
- B-tree
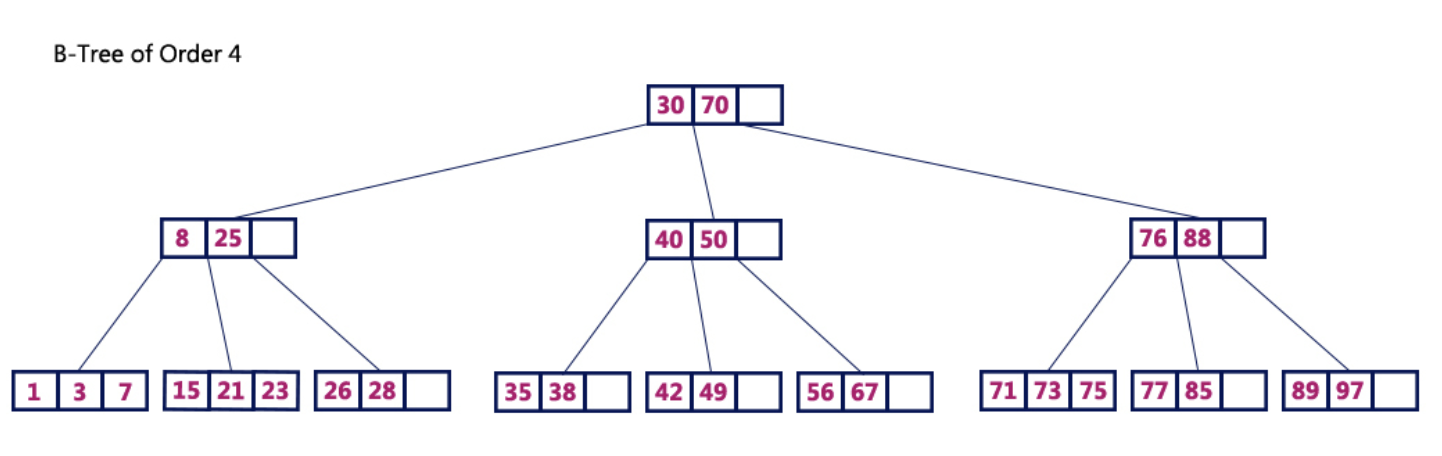
- 균형 트리
- 데이터가 정렬된 상태로 유지되어있다.
- 한 노드 당 자식 노드가 2개 이상 가능하다.
- 모든 노드에 키/데이터가 다 존재 - b+tree
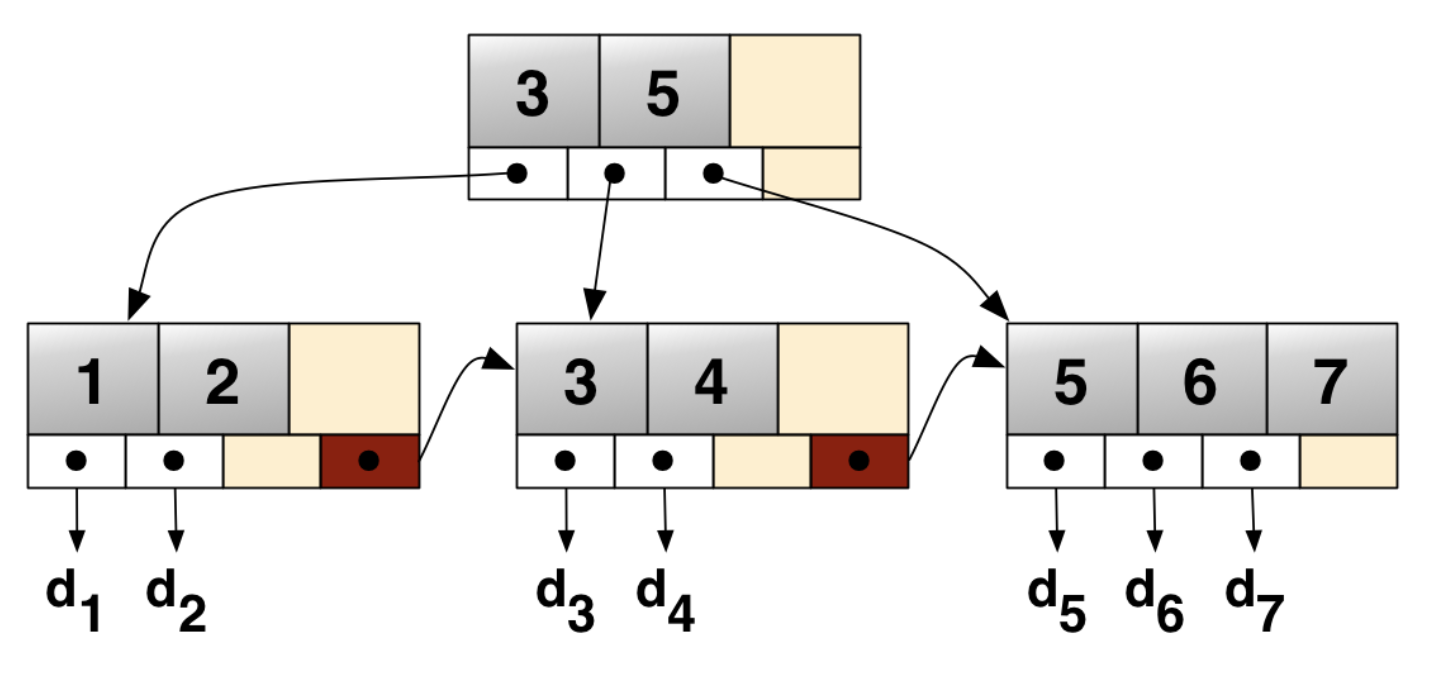
- 균형 트리
- 인덱스에 사용한다.
- 리프노드에만 key,data를 저장하며 다른 노드에는 key만 저장된다.
- 리프노드끼리 linked List로 연결되어있다.
- 장점
- 더 많은 key 수용 가능. data를 저장하지 않기 때문에
- 삽입 삭제는 O(logn)이 걸린다.
-
Reference
https://velog.io/@alsgus92/ConcurrentHashMap%EC%9D%98-Thread-safe-%EC%9B%90%EB%A6%AC
https://zorba91.tistory.com/293
https://tecoble.techcourse.co.kr/post/2020-07-29-equals-and-hashCode/

Backend Developer