구조화된 데이터가 선행학습이 되어야 한다
pandas
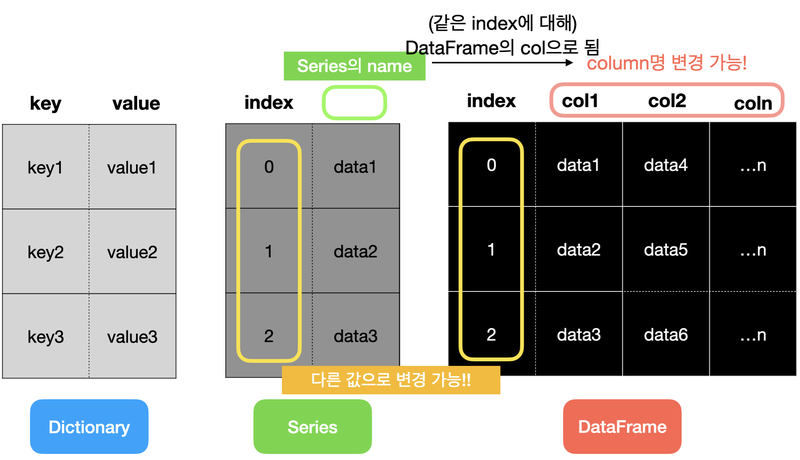
구조화된 데이터를 키(key)와 값(value)으로만 나타내기에는 너무 제한적이며, 표 형태로 나타내는 것이 시각적으로 편안함을 준다. 구조화된 데이터를 효과적으로 표현하기 위해 pandas라는 파이썬 라이브러리는 Series와 DataFrame이라는 자료 구조를 제공한다. 이 데이터 타입을 활용하면 구조화된 데이터를 더 쉽게 다룰 수 있다.
pandas의 특징
- Numpy 기반에서 개발되어 Numpy를 사용하는 애플리케이션에서 쉽게 사용 가능
- 축의 이름에 따라 데이터를 정렬할 수 있는 자료 구조
- 다양한 방식으로 인덱싱(indexing)하여 데이터를 다룰 수 있는 기능
- 통합된 시계열 기능과 시계열 데이터와 비시계열 데이터를 함께 다룰 수 있는 통합 자료 구조
- 누락된 데이터 처리 기능
- 데이터베이스처럼 데이터를 합치고 관계 연산을 수행하는 기능
pandas는 Numpy와 동일하게 pip를 이용하여 설치할 수 있고, 보통 Numpy를 설치할 때 같이 설치된다.
만약 없다면 $ pip install pandas를 사용
Series
구조화 데이터를 표현하는 데 중요한 개념인 Series의 인덱스(index)와 Name에 대해 알아본다.
pandas에는 다양한 기능 들이 있는데, 다른 기능은 pandas 공식 문서를 참고해 연습한다.(pandas 공식 문서 번역 블로그)
Series는 일련의 객체를 담을 수 있는, 1차원 배열과 비슷한 자료 구조로 배열 형태인 리스트, 튜플, 딕셔너리를 통해서 만들거나 Numpy 자료형(정수형, 실수형 등)으로 만들 수 있다.
ser이라는 Series객체를 만든다
import pandas as pd
ser = pd.Series(['a','b','c',3])
serSeries의 인덱스
pandas의 Series에는 index와 value가 있다. 위에서 보면 index는 순서를 나타낸 숫자(range)이고, value는 배열로 표현된 실제 데이터 값이다.
Series 객체의 values를 호출하면 array형태로 반환되고, index를 호출하면 RangeIndex(정수형 인덱스)가 반환된다.
ser.index
ser.valuesSeries가 구조화된 데이터를 표현할 수 있는 이유는 인덱스에 다른 값을 넣을 수 있기 때문이다. Series객체를 만들 때 인자로 넣어주거나 '='와 같은 할당 연산자(Assignment Operators)를 이용해서 인덱스의 값을 지정할 수 있다.
인덱스 설정
- Series의 인자로 넣어 주는 법
ser2 = pd.Series(['a','b','c', 3], index=['i','j','k','h'])
ser2- 할당 연산자 : 인덱스 값이 바뀐다
ser2.index = ['Jhon', 'Steve', 'Jack', "Bob"]
ser2인덱스 조회(ser2.index)하면 조금 전의 RangeIndex가 아닌 Index타입의 객체가 표시된다.
Series에서 인덱스는 기본적으로 정수 형태로 설정되고, 사용자가 원하면 값을 할당할 수 있다.
파이썬 딕셔너리 타입의 데이터를 Series 객체로 손쉽게 나타낼 수 있다.
Country_PhoneNumber = {'Korea': 82, 'America': 1, 'Swiss': 41, 'Italy': 39, 'Japan': 81, 'China': 86, 'Rusia': 7}
ser3 = pd.Series(Country_PhoneNumber)
ser3Series의 Name
Series 객체와 Series 인덱스는 모두 name속성이 있다. 이 속성은 pandas의 DataFrame에서 매우 중요하다
ser3.name = "Country_PhoneNumber"
ser3.index.name = "Country_Name"
ser3Series 객체의 name속성을 이용해서 Series 객체의 이름을 설정하고, Series 인덱스의 name 속성을 이용해 인덱스의 이름을 설정
DataFrame
DataFrame은 표(table)와 같은 자료 구조
Series는 한 개의 인덱스 컬럼과 값 컬럼, 딕셔너리는 키 컬럼과 값 컬럼 같이 2개의 컬럼만 존재하는데, DataFrame은 여러 개의 컬럼을 나타낼 수 있다. 그래서 csv파일이나 excel파일을 DataFrame으로 변환하는 경우가 많다.
Series와 DataFrame 비교
- Series으로 변환
data = {'Region' : ['Korea', 'America', 'Chaina', 'Canada', 'Italy'],
'Sales' : [300, 200, 500, 150, 50],
'Amount' : [90, 80, 100, 30, 10],
'Employee' : [20, 10, 30, 5, 3]
}
s = pd.Series(data)
s- DataFrame으로 변환
d = pd.DataFrame(data)
dSeries는 기본적으로 인덱스 외 한 개의 값 칼럼만을 가질 수 있고 그 칼럼의 데이터가 많더라도 배열 형태로 표현된다.
반면 DataFrame은 인덱스 칼럼 외에도 여러개의 칼럼을 가질 수 있다. 따라서 Index와 Column Index도 설정할 수 있다.
d.columns
d.index
d.index=['one','two','three','four','five']
d.columns = ['a','b','c','d']
dSeries의 name은 DataFrame의 Column명이다
구조화된 데이터의 표현법
pandas EDA
데이터 분석에 있어서 첫 번째 단계는 데이터를 쭉 훑어보는 것이다.
전문용어로는 EDA(Exploratory Data Analysis), 우리말로는 '데이터 탐색'이다.
pandas 라이브러리는 수학 메서드와 통계 메서드를 기본적으로 가지고 있다. 통계 데이터를 활용해서 데이터의 대푯값과 분산을 구하는 것은 EDA의 기본이라고 할 수 있다.
간단한 EDA를 이탈리아 코로나 바이러스 현황 데이터를 가지고 연습한다.
데이터셋 - COVID19
CSV 파일 읽기
import pandas as pd
import os
csv_path = "covid19_italy_region.csv"
data = pd.read_csv(csv_path)
type(data)csv 파일을 DataFrame 객체로 읽는다. type을 확인하면 자료형은 DataFrame으로 나온다.
head(), tail()
먼저 데이터를 출력해본다
datahead()와 tail()을 사용해서 출력해본다.
data.head()
data.tail()head()는 첫 5개 행을 보여주고, tail()은 마지막 5개 행을 보여준다.
정수 인자를 넣어 출력할 행의 개수를 조정할 수 있다.
data.head(3)
data.tail(7)columns
데이터셋의 서브구조를이루는 항목엔 어떤게 있는지 확인하기 위해 columns를 이용해 데이터셋에 존재하는 컬럼명을 확인해 보자
data.columns총 17개의 컬럼이 나온다
info
info()는 각 컬럼별로 Null 값과 자료형을 보여주는 메서드
data.info()describe
기본 통계 데이터(평균, 표준편차 등)을 pandas에서 손쉽게 보고 싶으면 describe()을 사용하면 된다. describe()은 각 컬럼별로 기본 통계 데이터를 보여주는 메서드로 개수(count), 평균(mean), 표준편차(std), 최솟값(min), 최댓값(max), 4분위 수(25%, 50%, 75%)를 보여준다.
data.describe()isnull().sum()
데이터를 분석할 때, 결측값(Missing value)확인은 정말 중요하다.
pandas에서 missing데이터를 isnull()로 확인하고, sum()을 이용해 missing 데이터 개수의 총 합을 구할 수 있다.
data.isnull().sum()EDA - 통계
pandas는 기본 수학 메서드와 통계 메서드를 가지고 있다. 이는 describe()을 통해 기본 통계 기능을 확인할 수 있었다. 이번엔 pandas에서 제공하는 풍부한 통계 기능을 활용해서 데이터를 더 자세히 탐색해 보자
value_counts()
범주형 데이터로 기재되는 컬럼에 대해서는 value_counts() 메서드를 사용해 각 범주(Case 또는 Category)별로 값이 몇 개 있는지 구할 수 있다.
코로나 데이터에서 범주형 데이터가 사용되는 컬럼에는 Country, RegionCode, RegionName이 있다.
data['RegionName'].value_counts()
data['Country'].value_counts()value_counts().sum()
sum() 메서드를 추가해 컬럼별 통계 수치의 합을 구할 수 있다.
data['RegionName'].value_counts().sum()
data['Country'].value_counts().sum()sum()
sum()을 컬럼에 단독으로 적용해서 해당 컬럼 값의 총합을 구할 수 있다.
sum() 메서드로 총 감염자, 전체 검사자 수, 사망자 수, 회복자 수의 합을 각각 구해본다.
print("총 감염자", data['TotalPositiveCases'].sum())
print("전체 검사자 수", data['TestsPerformed'].sum())
print("사망자 수", data['Deaths'].sum())
print("회복자 수", data['Recovered'].sum())DataFrame 전체에서 각 컬럼별로 합을 구하고 싶다면
data.sum()corr()
상관관계는 2개의 매개변수가 필요하다. 두 컬럼 내 데이터가 얼마만큼의 상관관계가 있는지를 나타내는 것이기 때문에. 예를 들어 폐암과 사망률의 상관관계는 폐암에 걸린 사람 중 사망자를 조사하면 되고, 반대로 사망률과 폐암의 상관관계는 사망자 중 폐암에 걸린 사람의 데이터를 확인하면 된다.
그러나 data.corr()을 통해 모든 컬럼이 다른 컬럼 사이에 가지는 상관관계를 일목요연하게 확인할 수 있다.
상관관계 분석은 EDA에서 가장 중요한 단계라고 할 수 있다. 이 과정을 걸쳐 불필요한 컬럼을 분석에서 제외한다.
print(data['TestsPerformed'].corr(data['TotalPositiveCases']))
print(data['TestsPerfromed'].corr(data['Deaths']))
print(data['TotalPositiveCases'].corr(data['Deanths']))
data.corr()위 작업을 통해 Country, Date, SNo, HospitalizedPatients, RegionCode, Longitude, Latitude 등의 컬럼을 삭제하기로 했다. 이때 drop() 메서드를 사용
data.drop(['Latitude', 'Longitude', 'Country', 'Date', 'HospitalizedPatients', 'IntensiveCarePatients', 'TotalHospitalizedPatients','HomeConfinement','RegionCode','SNo'], axis=1, inplace=True)
data.corr()pandas 통계 관련 메서드
count(): NA를 제외한 수를 반환한다describe(): 요약 통계를 계산한다.min(), max(): 최소, 최댓값을 계산한다.sum(): 합을 계산mean(): 평균을 계산median(): 중앙값을 계산var(): 분산을 계산std(): 표준편차를 계산argmin(),argmax(): 최소, 최댓값을 가지고 있는 값을 반환idxmin(),idxmax(): 최소, 최댓값을 가지고 있는 인덱스를 반환cumsum(): 누적 합을 계산한다.pct_change(): 퍼센트 변화율을 계산한다.
