AIFFEL
1.탐색적 데이터 분석 EDA 실습
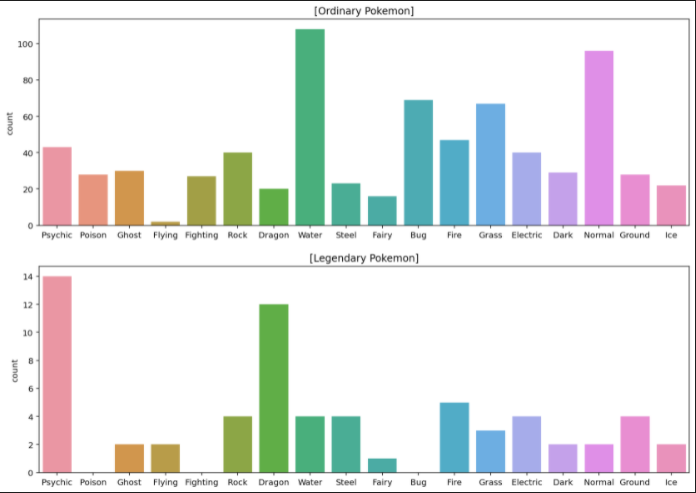
데이터 분석의 두 가지 접근 방법이 있다. 확증적 데이터 분석(CDA, Donfimatory Data Analysis) 가설을 설정한 후, 수집한 데이터로 가설을 평가하고 추정하는 전통적인 분석이다. 관측 형태나 효과의 재현성 평가, 유의성 검증, 신뢰구간 추정 등
2.작사하는 인공지능
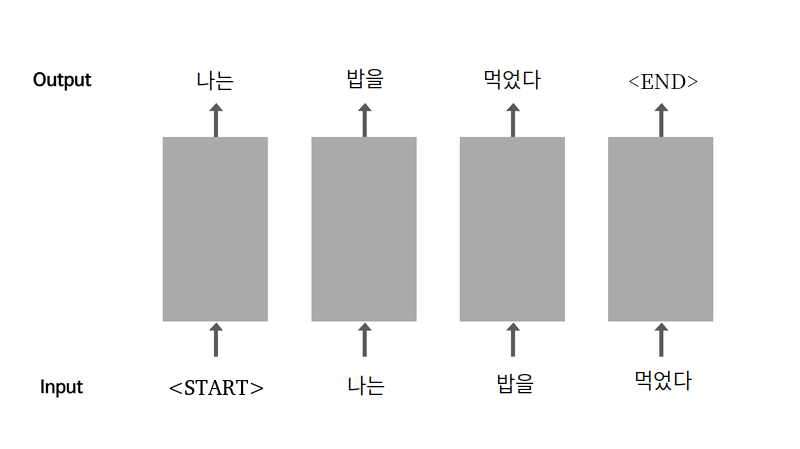
시퀀스는 일련의 연속적인 사건들 또는 사건의 행동 등의 순서라는 뜻을 가지고 있다. 예를 들어 밥을 한다고 치면 쌀을 씻어야 하고 씻은 후 적정량의 물과 함께 압력밥솥에 넣은 후 취사 버튼을 누르면 된다. 만약 알고리즘에 취사버튼을 누르라는 말이 없다면 식사할 때 밥이
3.이미지 분류

개/고양이 이미지 분류기를 만들어 보려고 한다. 분류기를 만들어보는 연습을 하면서 각각의 이론과 코드를 공부해보자.
4.Python Numpy
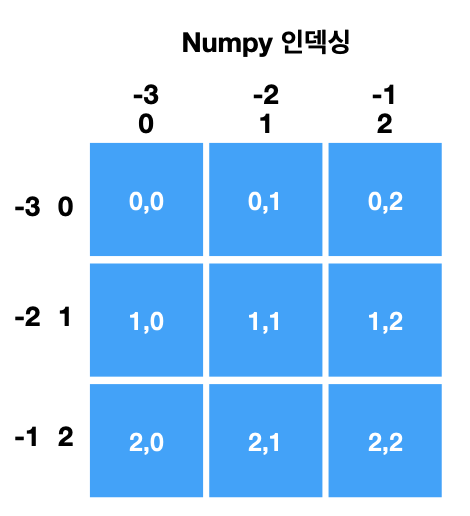
Numpy Numpy는 Numerical Python의 약자, 과학 계산용 고성능 컴퓨팅과 데이터 분석에 필요한 파이썬 패키지 기본 패키지 관리자인 pip에는 없어서 따로 설치해야 한다. conda를 사용한다면 기본적으로 포함 되어 있기도 하므로 conda list
5.인공지능과 가위바위보 하기

간단한 이미지 분류기 이미지를 분류하는 간단한 인공지능을 만들어 볼 예정이다. 이 인공지능은 손으로 쓴 숫자를 인식할 수 있고, 가위바위보 게임을 만들 수도 있다. 숫자는 0~9까지 총 10개의 class만 인식하면 되고, 가위바위보는 총 3개의 class만 구분하면
6.다양한 데이터 전처리
전처가 중요한 이유 모델에 데이터를 넣기 전까지 과정, 데이터 전처리를 알아보려고 한다. "데이터 분석의 8할은 데이터 전처리이다"라는 말이 있다. 왜 데이터 분석에 있어서 전처리는 중요한 것일까?? 전처리에 따라서 데이터 분석의 질이 달라지기 때문이다. 전처리가
7.데이터 시각화(Data Visualization)
시각화는 데이터를 파악하는데 매우 중요한 도구이다. 파이썬은 라이브러리(Pandas, Matplotlib, Seaborn 등)을 이용해 여러가지 그래프를 그려 데이터를 시각화 할 수 있다.이를 통해 데이터셋을 직접 시각화해보며 데이터 분석에 필요한 탐색적 데이터 분석(
8.데이터 시각화(Data Visualization)_02
앞에 데이터 시각화 첫 장에서 데이터 시각화를 하는 방법을 배웠다. 이번에는 자주 사용되는 그래프를 직접 그려보며 연습해보자.
9.데이터 분류_01

이번에 사용할 패키지petal은 꽃잎이고, sepal은 꽃받침이다.위 사진에서 세 가지 붓꽃은 모두 꽃잎과 꽃받침의 크기가 조금씩 다르고, 색깔도 조금씩 다르다이를 머신러닝 기법을 활용해 얼마나 잘 분류하는지 확인해보자.붓꽃 데이터가 예제 데이터로 사용되는 이유는 머신
10.데이터 분류_02
앞에서 연습했던 Iris 품종 분류와 같이 데이터 분류에 대해서 계속 공부해보자 데이터 분류_01 scikit-learn의 예제 데이터를 활용한다 데이터셋 : 사이킷런 toy datasets load_digits : 손글씨 이미지 데이터 (링크) load_wine
11.Python 객체와 클래스
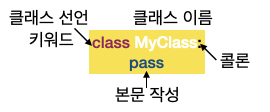
"Python에서 모든 것은 객체(Object)이다. 그리고 대부분 객체는 속성(attributes)과 메서드(methods)를 갖는다." 라는 말이 있다.파이썬에서 bool, 정수, 실수, 문자열, 배열, 딕셔너리, 함수, 모듈, 프로그램 등 모든 것은 객체이다. 참
12.Python Pandas
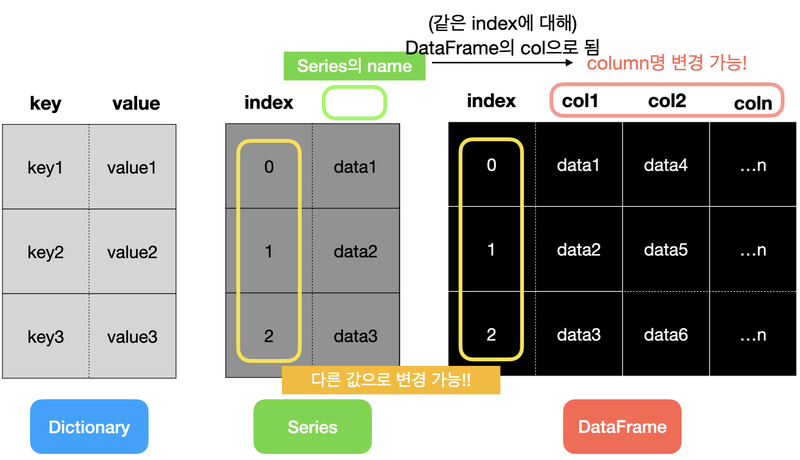
구조화된 데이터가 선행학습이 되어야 한다구조화된 데이터를 키(key)와 값(value)으로만 나타내기에는 너무 제한적이며, 표 형태로 나타내는 것이 시각적으로 편안함을 준다. 구조화된 데이터를 효과적으로 표현하기 위해 pandas라는 파이썬 라이브러리는 Series와
13.AI, 딥러닝, 머신러닝
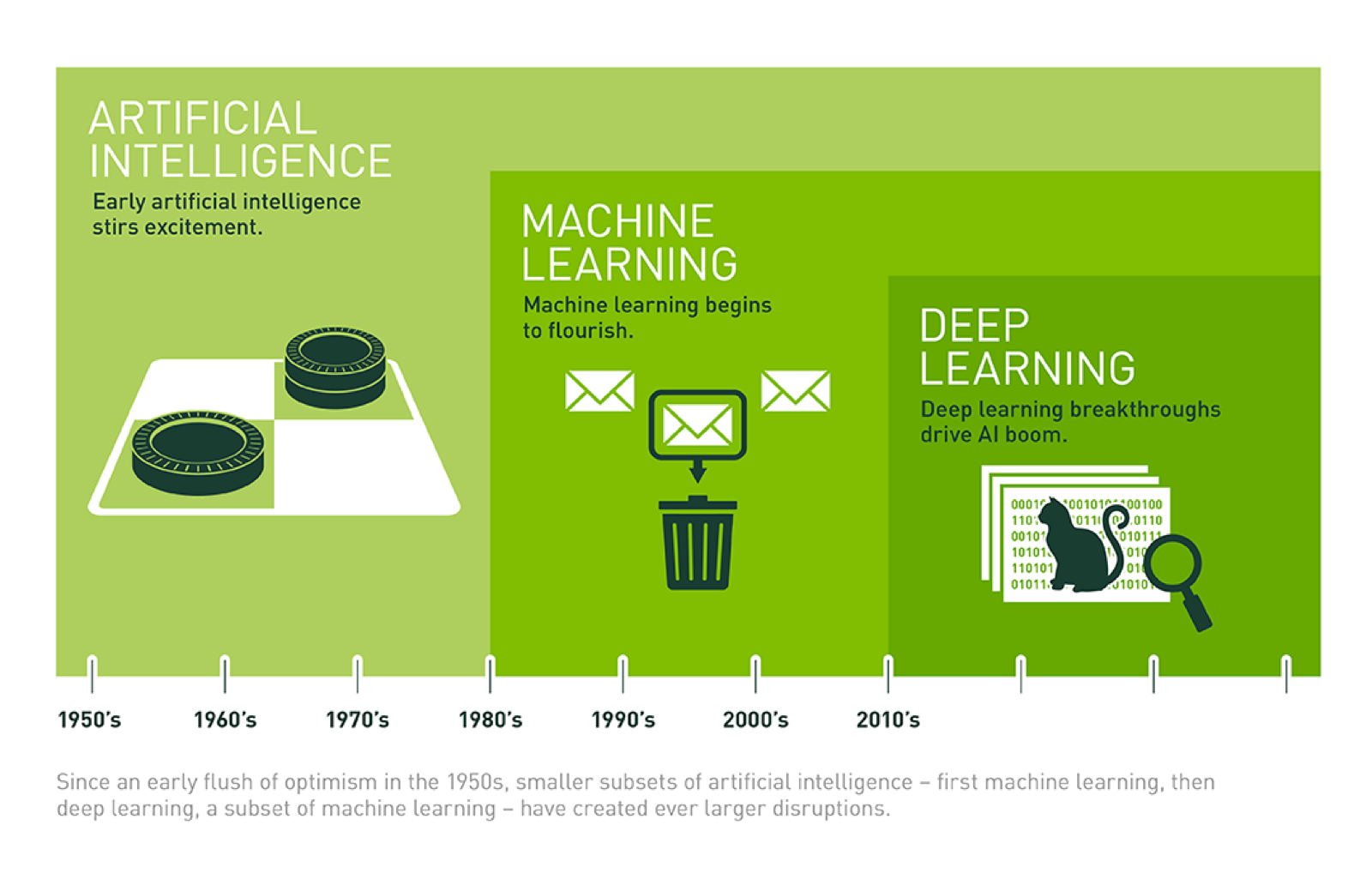
AI하면 가장 먼저 떠오르는 것이 머신러닝, 딥러닝이다. 출처 : https://wendys.tistory.com/136위 그림은 AI 인공지능, 머신러닝, 딥러닝에 대해서 가장 잘 설명해주는 그림이다AI 인공지능안에 머신러닝이 있고 머신러닝 안에 딥러닝이 있
14.회귀(Regression)
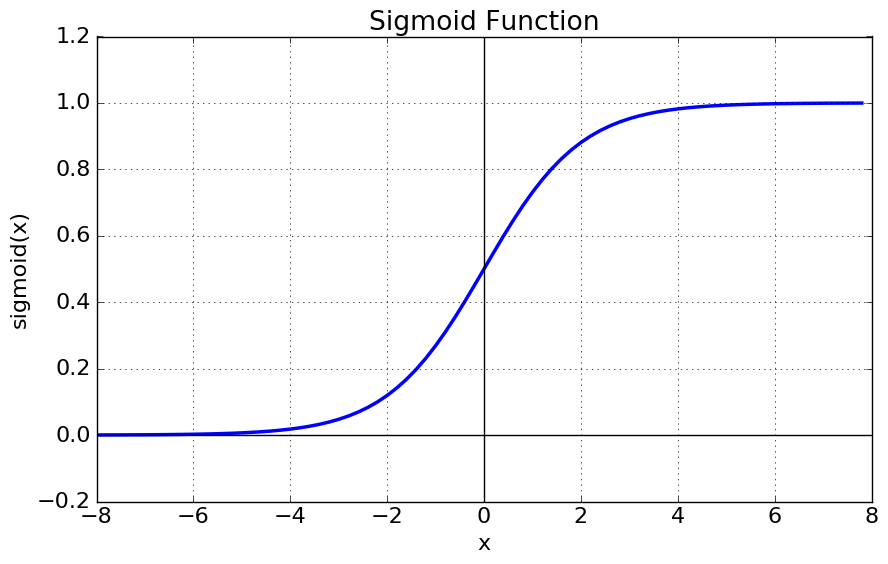
지도학습의 경우 문제가 두 가지 분류(Classification)와 회귀(Regression) 문제로 나뉜다.분류는 입력 데이터의 특성(feature)을 이용해 해당 데이터의 클래스(label)를 추론하는 것회귀는 입력 데이터의 특성(feature)을 통해 연관된 다른
15.텍스트 요약
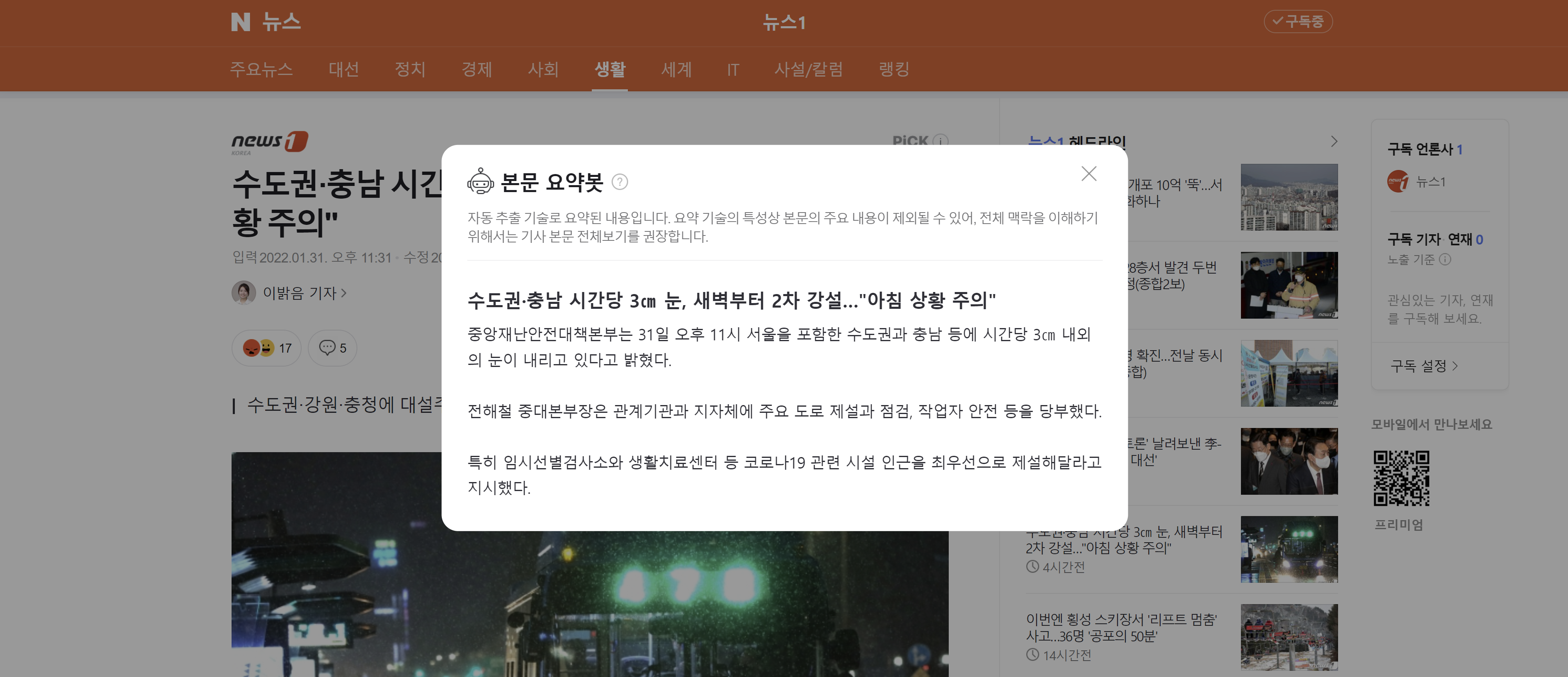
텍스트 요약이란 긴 길이의 문서(Document)를 핵심 주제만으로 구성된 짧은 요약(Summary)로 변환하는 것을 말한다. 예를 들어 뉴스 기사 중에서 핵심 주제를 기사 제목으로 만들어내는 것이다.이때 가장 중요한 것은 요약 할 때, 정보 손실이 최소화되는 것이다.
16.생성 모델링

생성 모델링(Generative Modeling)이라는 새로운 주제에 대해서 알아보려고 한다.일반적으로 이미지, 자연어를 처리하는 모델은 판별 모델링(Discriminative Modeling)이라고 한다. 앞에서 진행했던 가위바위보를 예로 든다면 가위, 바위, 보에
17.Data Augmentation

일반적으로 딥러닝 모델을 학습시키기 위해서는 데이터셋이 필요하다.대표적인 이미지 데이터셋인 이미지넷(ImageNet)은 약 1,400만 장의 이미지를 가지고, CIFAR-10도 6만장의 이미지 데이터를 가지고 있다.문제는 큰 규모의 데이터셋을 만드는 것은 큰 비용이 드