Learning Rate Scheduling
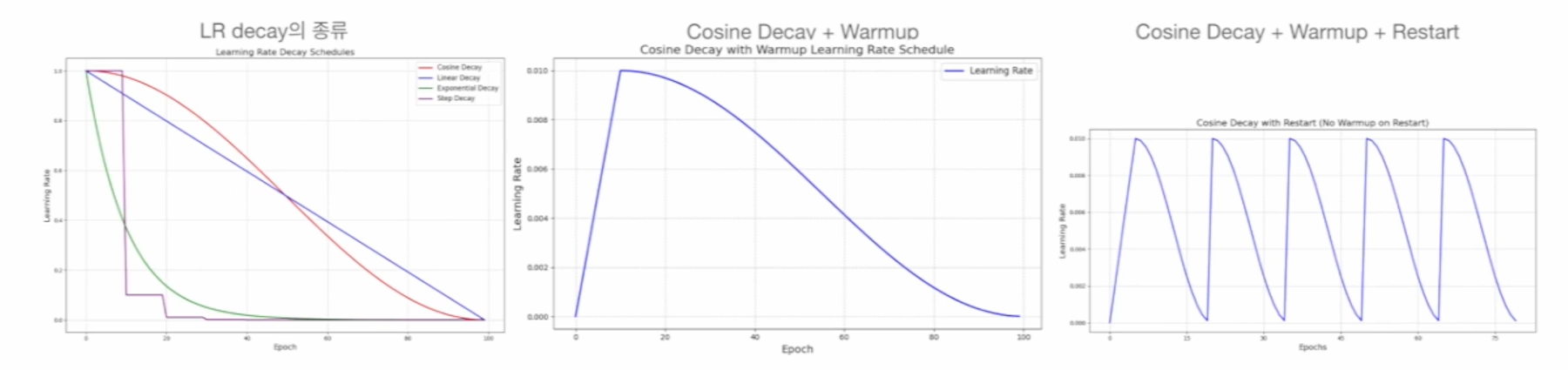
Decay: 모델의 학습이 진행될수록 learning rate (lr)를 작게 함- Cosine decay, Linear decay, Exponential decay, Step decay etc
Warmup: 초기 학습 안정성을 위해 lr을 작은 값부터 시작해 서서히 증가시키는 것Restart: Local minimum에서 벗어나기 위해 decay된 lr을 다시 크게 함
Hyperparameter
파라미터(모수)가 아니면서 모델 성능에 영향을 미치는 모든 변수 → batch_size, epochs, lr(α), weight_decay(λ), beta_1(β1), beta_2(β2), epsilon(ϵ), hidden layer의 개수, 각 hidden layer별 뉴런 개수, 모델, activation function, loss(cost) function, Initializer, Optimizer, LR Schedular의 종류
- 반복적인 실험을 통해 최적의 하이퍼 파라미터를 찾는 것이 모델 성능을 위해 필수적임

적당히 공부한 거 정리하는 곳