sklearn.pipeline
- 데이터 전처리와 모델 학습을 하나의 워크플로우로 결합하고
- 하이퍼 파라미터 튜닝을 더 간편하게 수행할 수 있음 (
set_params사용)
✔️ 예시
ⅰ. 데이터 전처리(StandardScaler())와 모델 형성을 파이프라인으로 묶기
from sklearn.pipeline import Pipeline from sklearn.tree import DecisionTreeClassifier from sklearn.preprocessing import StandardScaler estimators = [('scaler', StandardScaler()), ('clf', DecisionTreeClassifier())] pipe = Pipeline(estimators) print(pipe.steps)
결과)
[('scaler', StandardScaler()), ('clf', DecisionTreeClassifier())]ⅱ. 파이프라인에서 set_params를 통한 모델 파라미터 설정
pipe.set_params(clf__max_depth=2) pipe.set_params(clf__random_state=2024)
ⅲ. 파이프라인을 이용한 모델 훈련 및 모델 정확도 산출
from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13, stratify=y) pipe.fit(X_train, y_train) y_pred_tr = pipe.predict(X_train) y_pred_test = pipe.predict(X_test) print('Train ACC : ', accuracy_score(y_train, y_pred_tr)) print('Test ACC : ', accuracy_score(y_test, y_pred_test))
결과)
Train ACC : 0.9657494708485664
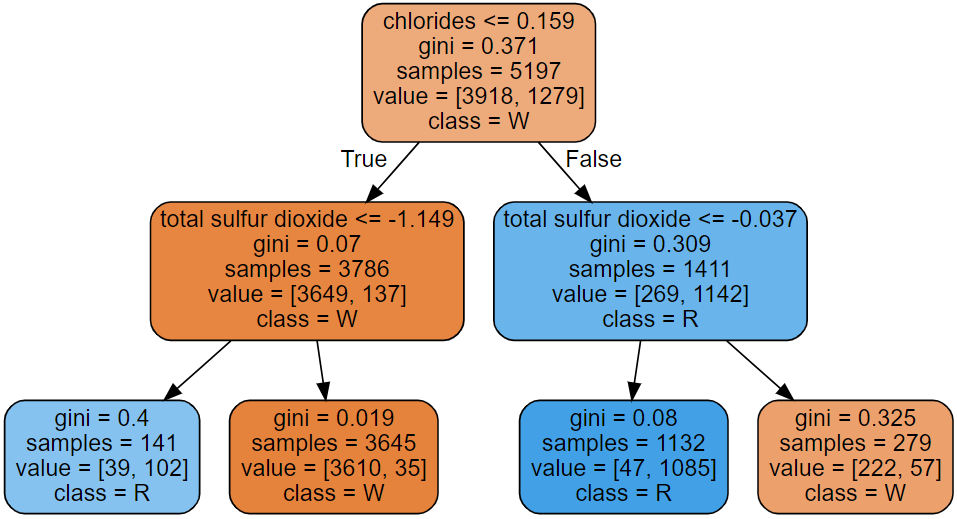
Test ACC : 0.9576923076923077ⅳ. 모델 구조 시각화
from graphviz import Source
from sklearn.tree import export_graphviz
>
Source(export_graphviz(pipe['clf'], feature_names=X.columns,
class_names=['W', 'R'],
rounded=True, filled=True))결과)

적당히 공부한 거 정리하는 곳