🏆 학습 목표
- 하이퍼파라미터 탐색 방법에 어떤 것이 있으며 신경망에서 조정할 수 있는 주요 하이퍼파라미터에는 어떤 것이 있는지 설명할 수 있습니다
- Scikit-learn, Keras Tuner등을 사용하여 구축한 신경망에 하이퍼파라미터 탐색 방법을 적용할 수 있습니다.
🤓 지금까지의 내용 복습
-
신경망의 순전파와 역전파 (Note 1-2)
- 신경망의 순전파 (Note 1) - x
- 신경망의 역전파 (Note 2) - , Chain Rule
- 모델 생성과 모델 초기화 (Note 3)
- 경사하강법의 다양성 (Note 2-3)
- 학습 과정에서 알아야 할 Tricks (Note 3)
- 가중치 감소/제한(Weight Decay/Constraint)
- 드롭아웃(Dropout)
- 학습률 계획(Learning Rate Scheduling)
-
그간 다뤄본 데이터
- 손글씨 MNIST
- Fashion MNIST
🔑 Keyword
- Activation Functions(활성화 함수)
- Optimizer(옵티마이저)
- Number of Layers
- Number of Neurons
- Batch Size(배치 사이즈)
- Dropout(드롭아웃)
- Learning Rate(학습률)
- Number of Epochs
하이퍼파라미터 튜닝 : 모델 성능 개선
교차 검증 (Cross-Validation)
colab 실습
### 데이터셋 불러오기 : 보스턴 집값 데이터셋(boston_housing)
from tensorflow.keras.datasets import boston_housing
### 필요한 라이브러리 import
import numpy as np
import pandas as pd
import os
from sklearn.model_selection import KFold, StratifiedKFold
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
### KFold를 통해 학습 데이터셋을 몇 개(k)로 나눌지 결정
kf = KFold(n_splits = 5)
skf = StratifiedKFold(n_splits = 5, random_state = 100, shuffle = True)
"""
KFold : K번마다 K개의 학습데이터 셋을 "일정한 간격으로 나누어" 평가 진행, 학습/검증 데이터 셋 나누어 진행
StratifiedKFold : for 불균형 label 데이터셋, label 데이터 분포도에 따라 학습/검증 데이터 나누기 때문에
split( ) 메서드에 인자로 피처 데이터 세트뿐만 아니라 레이블 데이터 세트도 반드시 넣어줘야한다.
https://2-chae.github.io/category/1.ai/28
"""
### 학습/테스트 데이터 나누기
# numpy.ndarray type -> .iloc 사용 불가
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()
# pandas dataframe 사용
x_train = pd.DataFrame(x_train)
y_train = pd.DataFrame(y_train)
for train_index, val_index in kf.split(np.zeros(x_train.shape[0]),y_train):
training_data = x_train.iloc[train_index, :]
training_data_label = y_train.iloc[train_index]
validation_data = x_train.iloc[val_index, :]
validation_data_label = y_train.iloc[val_index]
### 모델
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# CREATE
model = Sequential()
model.add(Dense(64, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1))
# COMPILE
model.compile(loss='mean_squared_logarithmic_error',
optimizer='adam',
metrics=['accuracy'])
# FIT
model.fit(training_data, training_data_label,
epochs=10,
batch_size=64,
validation_data=(validation_data, validation_data_label),
)
# 확인
print(training_data[:2])
print(training_data.shape)
print(training_data_label[:2])
# COMPILE NEW MODEL
# 다양한 loss로 테스트 : binary_crossentropy, mean_squared_error
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(training_data, training_data_label,
epochs=10,
batch_size=30,
)
# COMPILE NEW MODEL
model.compile(loss='binary_crossentropy', optimizer='adam')
model.fit(x_train, y_train,
epochs=10,
batch_size=30,
validation_data = (validation_data, validation_data_label),
)
results = model.evaluate(x_test, y_test, batch_size=128)
print("test loss, test mse:", results)
### 한 번에 테스트 수행
x_train = pd.DataFrame(x_train)
y_train = pd.DataFrame(y_train)
for train_index, val_index in kf.split(np.zeros(x_train.shape[0])):
training_data = x_train.iloc[train_index, :]
training_data_label = y_train.iloc[train_index]
validation_data = x_train.iloc[val_index, :]
validation_data_label = y_train.iloc[val_index]
# CV
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(training_data, training_data_label,
epochs=10,
batch_size=30,
validation_data = (validation_data, validation_data_label),
)
results = model.evaluate(x_test, y_test, batch_size=128)
print("test loss, test mse:", results)
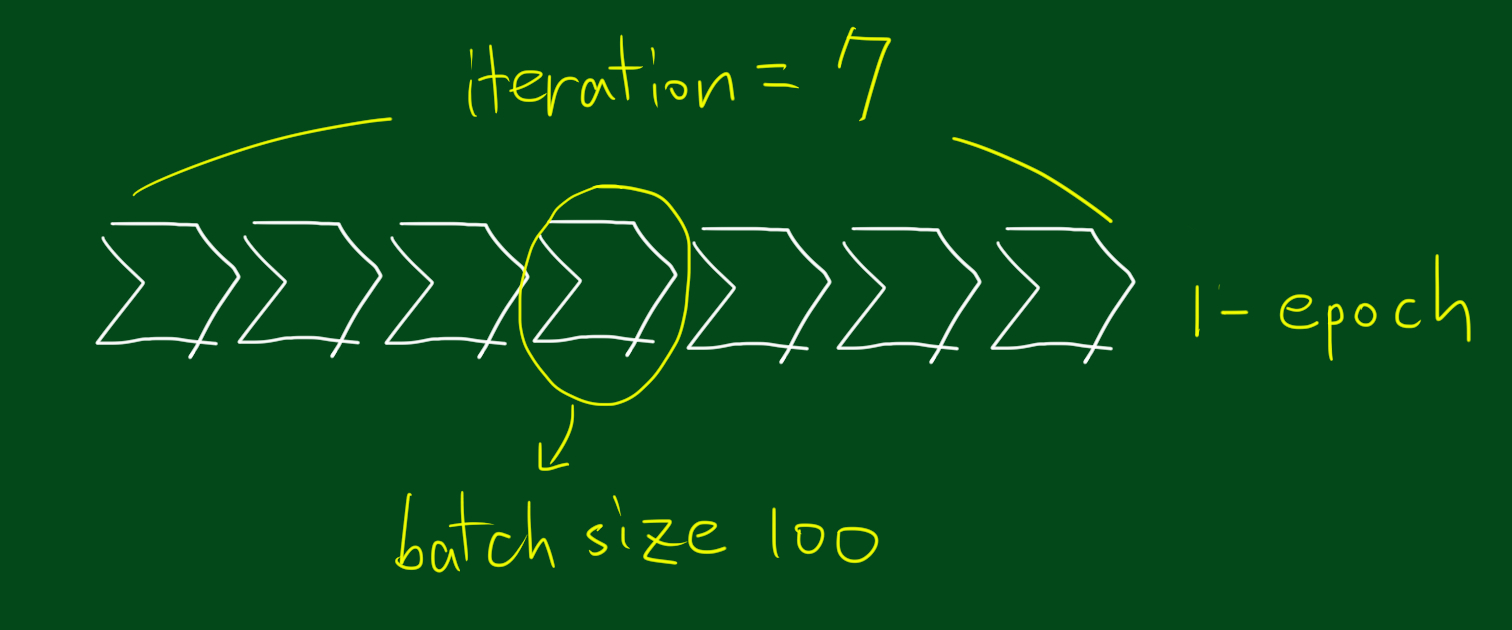
batch_size&epochs# 케라스 모델 학습 model.fit(x, y, batch_size = 32, epochs = 10)
x: 학습 데이터y: 레이블 데이터batch_size
- 몇 개의 관측치(샘플)에 대한 예측을 하고, 레이블 값과 비교를 하여 가중치를 갱신할지 설정하는 파라미터
- 배치사이즈가 클수록 많은 데이터를 저장해두어야 하므로 용량이 커야한다. 반면, 배치사이즈가 작으면 학습은 촘촘하게 되겠지만 계속 레이블과 비교하고, 가중치를 업데이트하는 과정을 거치면서 시간이 오래 걸린다.
epochs
- 전체 데이터셋을 몇 번 반복 학습할지 설정
- 같은 데이터셋이라 할지라도 가중치가 계속해서 업데이트되기 때문에 모델이 추가적으로 학습이 가능
- 오버피팅이 일어날 것 같으면 학습 종료
- https://sevillabk.github.io/1-batch-epoch/
- https://losskatsu.github.io/machine-learning/epoch-batch/#3-epoch%EC%9D%98-%EC%9D%98%EB%AF%B8
입력 데이터 정규화(Normalizing, Scaling) : StandardScaler
신경망은 수치형 데이터를 받게 되면 자체적으로 적절한 가중치를 학습하므로
정규화가 무조건 필요하지는 않지만 정규화를 해주면
학습을 빠르게 해주고, 최적화 과정에서 지역 최적점(Local optimum)에 빠질 위험을 줄여준다.
# 정규화를 위한 함수 호출
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)📚 reference
stackoverflow : Why do we have to normalize the input for an artificial neural network?
keras : 자동 검증(validation)
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 중요한 하이퍼파라미터들
inputs = x_train.shape[1] # 13
epochs = 75 # 전체 데이터셋이 신경망을 75번 통과
batch_size = 10 # 한번에 학습하는 사이즈, 트레이닝 데이터셋 전체를 30개씩(미니배치 1개) 나누어 파라미터를 업데이트
# 모델 생성 방법1
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(inputs,)))
model.add(Dense(64, activation='relu'))
model.add(Dense(1))
# 모델 생성 방법2 (Sequential인 경우)
# model = Sequential(
# [
# Dense(64, activation='relu', input_shape=(inputs,)),
# Dense(64, activation='relu'),
# Dense(1)
# ]
# )
# Compile Model
model.compile(optimizer='adam', loss='mse', metrics=['mse', 'mae'])
# Fit Model
model.fit(x_train, y_train,
validation_data=(x_test,y_test), # validation set
epochs=epochs, # 전체 반복횟수
batch_size=batch_size # 한번에 학습하는 사이즈
)하이퍼파라미터 튜닝 : 신경망
튜닝 방식
1. "Babysitting" 혹은 "Grad Student Descent"
100% 수작업(Manual)으로 파라미터를 수정하는 방법

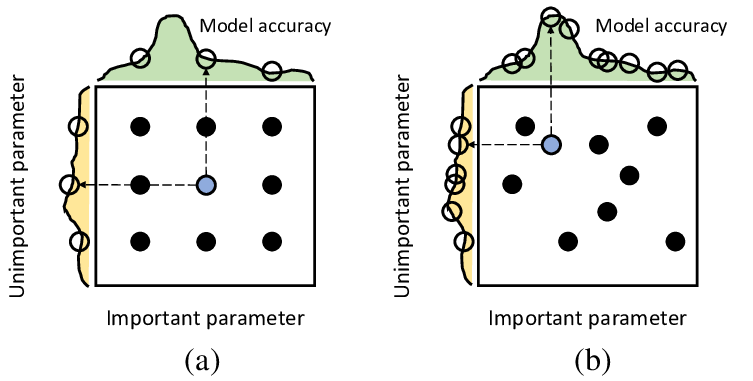
2. Grid Search
- 모든 경우를 테이블로 만든뒤 격자로 탐색하는 방식
- 하이퍼파라미터마다 탐색할 지점을 정해주면 모든 지점에 해당하는 조합을 알아서 수행
- 지정 파라미터 수에 따라 시간이 매우 오래 걸릴 수 있음
- 모델 성능에 보다 직접적인 영향을 주는 하이퍼파라미터 1, 2개가 적합
3. Random Search
- 값을 랜덤하게 넣어보고 그중 우수한 값을 보인 하이퍼 파라미터를 활용해 모델을 생성한다는 것
- 지정된 범위 내에서 무작위로 모델을 돌려본 후 최고 성능의 모델을 반환
- 시도 횟수를 정해줄 수 있어 Grid Search대비 훨씬 적은 횟수로도 학습을 끝마칠 수 있음
- 상대적으로 중요한 하이퍼파라미터에 대해서는 탐색을 더 하고, 덜 중요한 하이퍼파라미터에 대해서는 실험을 덜 하도록 함
- 절대적으로 완벽한 하이퍼파라미터를 찾아주지는 않음
4. Bayesian Methods
- 이전 탐색 결과 정보를 새로운 탐색에 활용하여 효율을 높이는 방법
bayes_opt나hyperopt와 같은 패키지 사용
튜닝 가능한 파라미터
- batch_size(배치 크기)
- training epochs(반복 학습 횟수)
- optimizer(옵티마이저)
- learning rate(학습률)
- activation functions(활성화 함수)
- Regularization(weight decay, dropout 등)
- 은닉층(Hidden layer)의 노드(Node) 수
### 데이터 불러오기
from tensorflow.keras.datasets import boston_housing
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()
### 정규화
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)배치 사이즈(Batch Size)
순전파/역전파를 통해 모델의 가중치를 업데이트 할 때마다,
즉 매 iteration마다 몇 개의 입력 데이터를 볼지 결정하는 하이퍼파라미터
- 일반적으로 ~(~) 사이의 2의 제곱수로 결정 (keras - Default=32)
- 배치 사이즈가 너무 클 경우,
- 한 번에 많은 데이터에 대한 Loss 계산하여 가중치 업데이트 느림
- 주어진 Epoch 안에 충분한 횟수의 iteration 확보 불가
- 파라미터가 굉장히 많은 모델에 큰 배치 사이즈를 적용하게 될 경우 메모리를 초과해버리는 현상(Out-of-Memory) 발생
- 배치 사이즈가 너무 작을 경우,
- 오랜 학습 시간
- 많은 노이즈 발생
- 이미지 처리에서 작은 배치 사이즈()를 잘 설정하면 일반화(Generalization) 성능을 높일 수 있다는 내용의 논문
- 배치 사이즈를 왜 2의 제곱수로 설정하는가 -> Stackoverflow
### 1. 필요한 패키지 import
import numpy
import pandas as pd
from sklearn.model_selection import GridSearchCV
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
### 2. 재현성 위해 랜덤시드 고정
numpy.random.seed(1100)
### 3. 데이터셋을 불러온 후에 Feature & Label로 분리
# 데이터셋을 불러옵니다.
url ="https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
dataset = pd.read_csv(url, header=None).values
# 불러온 데이터셋을 X와 Y로 나눕니다
X = dataset[:,0:8]
Y = dataset[:,8]
### 4. 모델 제작
def create_model():
# 모델 제작
model = Sequential()
model.add(Dense(100, input_dim=8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일링
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
### 5. KerasClassifier로 wrapping
# keras.wrapper를 활용하여 분류기 만들기
model = KerasClassifier(build_fn=create_model, verbose=0)
### 6. GridSearchCV 설정 & 학습
batch_size = [10, 20, 40, 60, 80, 100]
epochs = [30]
param_grid = dict(batch_size=batch_size)
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=1)
grid_result = grid.fit(X, Y) # 데이터셋(X, Y)에 적용
### 7. 최적의 결과를 낸 하이퍼파라미터와 각각의 결과 출력 : grid_result.cv_results_[]
print(f"Best: {grid_result.best_score_} using {grid_result.best_params_}")
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print(f"Means: {mean}, Stdev: {stdev} with: {param}")
옵티마이저(Optimizer)

- "모든 경우에 좋은 옵티마이저란 없다" 따라서 모델에 따라, 데이터셋에 따라 적절한 옵티마이저를 잘 설정해주어야한다.
- 어떤 옵티마이저를 선택하는 지에 따라서 최적의 하이퍼파라미터 값이 달라지므로
옵티마이저를 다르게 해줄 때마다 적절한 학습률(learning rate)과 모멘텀(momentum) 등을 다르게 설정해주는 것이 좋다. - https://sacko.tistory.com/42
Learning Rate(학습률, lr)
옵티마이저(Optimizer)에서 지정해 줄 수 있는 하이퍼파라미터
- Keras 기본 학습률 = 0.001
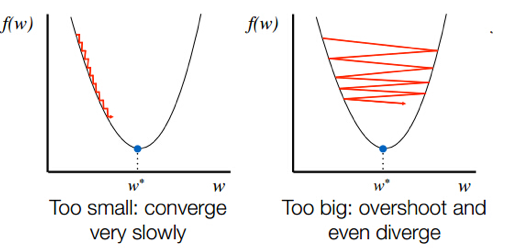
- Too big : 발산하면서 최적값 찾을 수 X
- Too small : 시간이 너무 오래 걸리거나 주어진 iteration 내에서 모델이 수렴하는데 실패
- 학습률을 조정하면 최적값에 도달할 수 있는 iteration의 횟수 역시 변경되므로 Epoch 횟수도 함께 튜닝해주는 것이 좋다
모멘텀(Momentum)
옵티마이저(Optimizer)에 관성을 부여하는 하이퍼파라미터
- 이전 iteration에서 경사 하강을 한 정도를 새로운 iteration에 반영하여
지역 최저점(Local minima)에 빠지지 않을 수 있도록 함

가중치 초기화(Network Weight Initialization)
초기 가중치를 어떻게 설정할 지를 결정
### Keras
init_mode = ['uniform', 'lecun_uniform', 'normal', 'zero', 'glorot_normal', 'glorot_uniform', 'he_normal', 'he_uniform']-
표준편차를 1인 정규분포로 가중치를 초기화(활성화 함수 = sigmoid)할 경우 문제점
 표준편차가 일정한 정규분포로 가중치를 초기화 해 줄 때에는 대부분의 활성화 값이 0과 1에 위치(활성값이 고르지 못함 -> 제대로된 학습 X)
표준편차가 일정한 정규분포로 가중치를 초기화 해 줄 때에는 대부분의 활성화 값이 0과 1에 위치(활성값이 고르지 못함 -> 제대로된 학습 X) -
Xavier 초기화
표준편차가 고정값인 정규분포로 초기화 했을 때의 문제점을 해결하기 위해 등장한 방법
- 이전 층 노드 개 => 현재 층의 가중치를 표준편차가 인 정규분포로 초기화
(케라스에서 Xavier 초기화는 이전 층의 노드가 개이고 현재 층의 노드가 개일 때,
현재 층의 가중치를 표준편차가 인 정규분포로 초기화한다.)
- 이전 층 노드 개 => 현재 층의 가중치를 표준편차가 인 정규분포로 초기화
-
He 초기화(He initialization)
Xavier 초기화의 활성화 함수가 ReLU일 경우 활성값이 고르지 못하여 이를 해결하기 위해 등장
- 이전 층 노드 개 => 현재 층의 가중치를 표준편차가 인 정규분포로 초기화
- He 초기화를 적용하면 그림처럼 층이 지나도 활성값이 고르게 유지되는 것을 확인할 수 있음
c.f. Activation function에 따른 초기값 추천
Sigmoid⇒Xavier 초기화를 사용하는 것이 유리ReLU⇒He 초기화사용하는 것이 유리
(복습)
활성화 함수(Activation Function)
- 은닉층 :
ReLU- 출력층 : 문제에 따라
Sigmoid (이진 분류)나Softmax(다중 분류)적용- 모델에 따라서 은닉층에도
sigmoid나tanh(Hyperbolic tangent) 등의 다른 활성화 함수를 적용할 수 있음
Regularization(weight decay, dropout 등)- 과적합(Overfitting)을 방지하기 위한 Regularization을 적용하는 하이퍼파라미터
- 가중치 감소(Weight decay)를 얼마나 적용할 것인지 혹은
가중치 제한(Weight constraint)의 범위를 어떻게 설정할 것인지에 따라
신경망의 성능이 결정됨- 드롭아웃(Dropout) : 매 iteration마다 임의로 비활성화하고 싶은 뉴런의 비율
은닉층 노드 수- 일반적으로 은닉층의 노드 수를 늘림으로써 모델을 복잡하게 만들어 줄 수록 데이터의 복잡한 패턴을 잘 이해할 수 있지만 노드가 많아지고 층이 깊어질수록 학습 시간이 길어지고 과적합에 대한 위험이 늘어나므로 각 층의 노드 수를 잘 조정하는 것 역시 딥러닝의 성능을 높이기 위한 중요 요소
하이퍼파라미터 튜닝 예제 : Keras Tuner
Keras Tuner
케라스 프레임워크에서 하이퍼파라미터를 튜닝하는 데 도움이 되는 라이브러리
[전체적인 과정 요약]
1. 필요한 패키지 & Keras tunerinstallorimport
2. 데이터셋 불러오기
3. 정규화
4. Model 제작
:함수orKeras Tuner API(HyperModel 클래스의 분류기)
5. 튜너 지정 (Random search, Bayesian, Optimization, Hyperband)
6. Callback 함수 정의
7. 하이퍼파라미터 탐색 :tuner.search()
8. 최적의 하이퍼파라미터 :tuner.get_best_hyperparameters()
9. 최적의 하이퍼파라미터로 모델 구축
:tuner.hypermodel.build(),model.fit
### 1. 필요한 패키지 import
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Dense, Flatten
import IPython
### 2. Keras Tuner 설치 & import
!pip install -U keras-tuner
import kerastuner as kt
### 3. 데이터셋 불러오기
(img_train, label_train), (img_test, label_test) = keras.datasets.fashion_mnist.load_data()
### 4. 정규화(Normalizing)
img_train = img_train.astype('float32') / 255.0
img_test = img_test.astype('float32') / 255.0튜닝 방법 2가지
- 방법1 : 함수 제작 (model_builder)
- 방법2 : Keras Tuner API의 HyperModel 클래스에 있는 분류기 사용 ▶️ 링크
❗️ Keras Tuner 를 더 알아보기 위한 학습 자료
1) Keras Tuner 텐서플로우 블로그
2) Keras Tuner 공식문서
3) HParams 대시보드 in Tensorboard : 하이퍼파라미터 튜닝을 위한 대시보드 만들기
❗️ 심화 학습
이미지 처리를 위한 몇 가지 모델에서는 HyperModel의 하위 클래스인 HyperXception 및 HyperResNet 등을 적용할 수 있다.
### 5. Model 제작
# model builder function
def model_builder(hp):
model = keras.Sequential()
model.add(Flatten(input_shape=(28, 28)))
# 첫 번째 Dense layer에서 노드 수 조정 : 32-512
hp_units = hp.Int('units', min_value = 32, max_value = 512, step = 32)
model.add(Dense(units = hp_units, activation = 'relu'))
model.add(Dense(10, activation='softmax'))
# Optimizer의 학습률(learning rate) 조정 : [0.01, 0.001, 0.0001]
hp_learning_rate = hp.Choice('learning_rate', values = [1e-2, 1e-3, 1e-4])
model.compile(optimizer = keras.optimizers.Adam(learning_rate = hp_learning_rate),
loss = keras.losses.SparseCategoricalCrossentropy(from_logits = True),
metrics = ['accuracy'])
return model
### 6. 하이퍼파라미터 튜닝을 수행할 튜너(Tuner) 지정 : Random Search, Bayesian Optimization, Hyperband 등
"""
Hyperband 사용 시
Model builder function(model_builder), 훈련할 최대 epochs 수(max_epochs) 등을 지정해주어야 한다.
Hyperband는 리소스를 알아서 조절하고 조기 종료(Early-stopping) 기능을 사용하여 높은 성능을 보이는 조합을 신속하게 통합한다는 장점을 가지고 있다.
"""
# Hyperband
tuner = kt.Hyperband(model_builder,
objective = 'val_accuracy',
max_epochs = 10,
factor = 3,
directory = 'my_dir',
project_name = 'intro_to_kt')
# my_dir/intro_to_kr : 하이퍼파라미터 탐색 중에 실행되는 모든 모델에 대한 세부 로그와 체크포인트 저장
# 동일한 모델로 하이퍼파라미터 탐색 다시 실행시, Keras Tuner 기존 로그 참고하여 검색 시작
# 이 동작 비활성화 : 튜너 설정시 'overwrite = True' 로 지정
### 7. Callback 함수 지정 : 하이퍼파라미터 탐색을 실행하기 전에 학습이 끝날 때마다 출력을 지우도록 콜백 함수 정의
class ClearTrainingOutput(tf.keras.callbacks.Callback):
def on_train_end(*args, **kwargs):
IPython.display.clear_output(wait = True)
### 8. 하이퍼파라미터 탐색
tuner.search(img_train, label_train, epochs = 10, validation_data = (img_test, label_test), callbacks = [ClearTrainingOutput()])
# 9. 최적의 하이퍼파라미터를 사용하여 모델 구축 & 데이터 교육
best_hps = tuner.get_best_hyperparameters(num_trials = 1)[0]
print(f"""
하이퍼 파라미터 검색이 완료되었습니다.
최적화된 첫 번째 Dense 노드 수는 {best_hps.get('units')} 입니다.
최적의 학습 속도는 {best_hps.get('learning_rate')} 입니다.
""")
model = tuner.hypermodel.build(best_hps)
model.summary()
model.fit(img_train, label_train, epochs = 10, validation_data = (img_test, label_test))- 하이퍼파라미터 탐색 중에 실행되는 모든 모델에 대한 세부 로그와 체크포인트가 저장 :
my_dir/intro_to_kt경로 - 동일한 모델로 하이퍼파라미터 탐색을 다시 실행할 때, Keras Tuner 기존 로그를 참고하여 검색 시작
- 이 동작을 비활성화하려면 튜너 설정시
overwrite = True로 지정
실험 기록 툴
다양한 하이퍼파라미터를 변경해가면서 장기적으로 실험을 진행하다보면 점점 결과를 관리하기가 어려워진다. Comet.ml, Weights and Biases(wandb) 등은 이러한 문제를 해결하기 위해 등장한 실험 기록 도구로,
- 실험 결과를 원하는 기준대로 언제든지 시각화하여 모델의 성능을 확인 가능하며
- 매 Epoch가 끝날 때마다 데이터가 해당 툴에 보내져 모델이 수렴하고 있는지도 확인 가능하다.
!pip install wandb
import wandb
from wandb.keras import WandbCallback
# group, project 변수를 설정합니다. 반복되는 이름이 많기 때문에 변수로 설정하여 사용하면 편리합니다.
wandb_project = "review"
wandb_group = ""
# !git clone http://github.com/wandb/tutorial
# !cd tutorial; pip install --upgrade -r requirements.txt;
!wandb login (key 입력)
import numpy
import pandas as pd
#from tensorflow import keras
#from tensorflow.python import keras
#from tensorflow.keras.layers import Dense
from sklearn.model_selection import GridSearchCV
wandb.init(project=wandb_project) ## 내가 만든 프로젝트 이름을 넣어주어야 합니다.
#wandb.init(project=wandb_project, entity=wand_group)
# 데이터 및 하이퍼파라미터 설정
X = x_train
y = y_train
inputs = X.shape[1]
wandb.config.epochs = 50
wandb.config.batch_size = 10
# 모델을 구축합니다
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(inputs,)))
model.add(Dense(64, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1))
# 모델을 컴파일 합니다
model.compile(optimizer='adam', loss='mse', metrics=['mse', 'mae'])
# 모델을 학습합니다
model.fit(X, y,
validation_split=0.3,
epochs=wandb.config.epochs,
batch_size=wandb.config.batch_size,
callbacks=[WandbCallback()]
)
wandb.init(project=wandb_project) ## 내가 만든 프로젝트 이름을 넣어주어야 합니다.
# 데이터 및 하이퍼파라미터 설정
from tensorflow.keras import datasets
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
wandb.config.epochs = 10
wandb.config.batch_size = 64
# 모델을 구축합니다
model = Sequential() ## 과제시에는 이 모델을 Tre-trained model로 대체하면 됩니다.
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D((2,2)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D((2,2)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.summary()
# 모델학습방식을 정의함
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델 학습시키기
model.fit(train_images, train_labels,
validation_data=(test_images, test_labels),
epochs=wandb.config.epochs,
batch_size=wandb.config.batch_size,
callbacks=[WandbCallback()]
)
# 성능이 마음에 안들경우 추가 학습
wandb.config.epochs = 20
wandb.config.batch_size = 512
model.fit(train_images, train_labels,
validation_data=(test_images, test_labels),
epochs=wandb.config.epochs,
batch_size=wandb.config.batch_size,
callbacks=[WandbCallback()]
)
!ls wandb/
🧐 Review
-
Keyword
- Activation Functions(활성화 함수)
- Optimizer(옵티마이저)
- Number of Layers
- Number of Neurons
- Batch Size(배치 사이즈)
- Dropout(드롭아웃)
- Learning Rate(학습률)
- Number of Epochs
- and many more
-
Scikit-learn과Keras Tuner를 통한 신경망 하이퍼파라미터 조정 방법 적용


차원수에 맞춰 써야함
input_dim=3 # shape를 더 편하게 쓰기위함, 괄호 생략하고 숫자만 기입(1차원만)
input_shape=(feature수,) # 2차원
input_shape(32,32)-> flatten ->input_shape(1024,)
dense 1차원 밖에 되지 않아서 flatten 사용해서 1차원으로 전환
num_params
= connections between layers + biases in every layer
= (i×h + h×o) + (h+o)
예) hidden layer 5개 노드 / Output layer 3개 노드
이 사이의 params 갯수 = 3*5 + 3(bias)
GridSearch
- 조건의 모든 조합
- 조건과 범위에 따라 매우 오래 걸리고 OOM이 발생할 수도 있으므로 적절한 범위를 정해야함
Random Search
- random 조합
Random > Grid
가중치 초기화
- 가중치 학습시킬 때 시작점
- kernel_initializer -> layer 단위로 설정(각 층마다의 가중치 조절)
- 맨 처음에 진행
- 출발점 설정(산의 어느 지점에서 내려올지)
- 잘 설정하지 않으면 학습이 잘 안이뤄짐 -> loss
최저점, 최저값 - 가중치를 다 0으로 설정하게 되면, x * 0 -> 0 이므로 학습이 전혀 이루어지지 않으므로 X
학습률
- 학습(가중치 업데이트)할 때 얼마나 변화할건지
- 학습률이 너무 작으면, local minima에서 탈출하지 못하고 global minima를 못 찾을 수 있다.
- 학습률이 너무 크면, 발산할수도 있고 지나칠 수도 있다.
optimizer
- 최저점을 찾아가는 방법
- gradient descent가 local minima에 빠져 나오지 못하는 점 보완
- 방향 :
- 거리 :
- momentum : 이전 가중치 업데이트 가속도, 관성 달려가는 방향으로 얼마나 달려갈지, 하이퍼파라미터로 관성의 정도 결정(global minimum을 넘어가지 않을 정도)
Gradient Descent
- 방향 : 기울기 반대방향
- 거리 : 학습률*기울기(편미분값)
- 가중치 한 번 : 전체 학습 데이터(다 공부하고 한발짝 움직임) 사용 -> 시간이 너무 오래걸림
SGD
- 가중치 한 번 : random하게 1개 뽑아서 사용, batch_size=1 -> 이상치처럼 너무 왔다갔다 거림(노이즈가 너무 심함)
Mini-batch GD
- 배치 사이즈, 1번 학습 시 그 배치 데이터 > 가중치 업데이트
adam = momentum + rmsprop
