이전의 수업들에선 단어 단위로 입력을 생각했다. 자연어 처리 분야에서 흔히 토큰이라고 부르는 것은 가장 작은 의미의 단위로 영어에선 띄어쓰기 단위로, 한국어에선 형태소 단위로 자르고, 정규화하여 만들어진다. 하지만 언어의 가장 작은 의미의 단위가 실제로 단어 하나일까? 하나씩 살펴보자.
0. Linguastic Things
0-1. 음소(Phoneme)
사람의 입은 사실 무척 다양한 소리를 낼 수 있다. 우리가 음성을 문자로 옮길 때, 하나의 문자에 하나의 소리를 할당해놓기 때문에, 정해진 글자들만 표현 할 수 있다고 생각하지만, 혀와 입술의 모양은 자유롭기 때문에 무한한 표현이 가능하다. 예를 들어, "나"와 "너"라는 단어 사이에는 무언가 애매한 발음을 무척 많이 연속적으로 낼 수 있다.
하지만 인지심리학자들이 연구해보니, 사람은 범주적 지각(categorical perception)을 한다고 한다. 연속적인 자연 세계를 일정한 구분을 통해 범주로 이해한다는 것이다. 가령 뚱뚱한 체형, 보통 체형, 마른 체형 이렇게 세개의 범주로 체형을 분류해서 생각하거나, 덥다, 시원하다, 춥다 등으로 기온을 분류해서 인식한다.
이는 언어에서도 마찬가지여서 연속적인 소리들을 범주로 나누어 인식한다. 그래서 우리는 "나"와 "너"로만 소리를 인식하고 있는 것이다. 그리고 이처럼 사람들이 나눈 소리의 최소 단위를 음소(phoneme)라고 한다. 언어는 음소의 결합으로 이루어져 있으며, 음소의 변화는 다른 단어와 의미를 가지는 것이 된다. "나"와 "너"는 모음 음소가 바뀌어 다른 뜻을 가진 단어가 되었다.
0-2. 형태소(morphology)
하지만 음소는 그 자체로 의미를 가지지 못한다. 단순히 인간이 지각하는 최소 단위의 소리일 뿐이다. 의미를 가지는 언어적 최소 형태는 형태소이다. 즉, 모델에 단어를 통채로 넣을 수도 있지만, 형태소를 입력값으로 하여 훈련시킬 수도 있다.
예를 들어 unfortunately라는 단어가 있다고 하자. 이 단어를 형태소로 분리해보면 un + fortune + ate + ly로 분해할 수 있을 것이다. 실제로 전통적인 자연어 방법론에서는 이렇게 단어를 분리해서 사용하고자 하는 노력들이 있었다고 한다. 그리고 Manning 교수님 역시 형태소로 단어를 분리하여 입력값으로 사용하고자 연구를 했다고 한다.
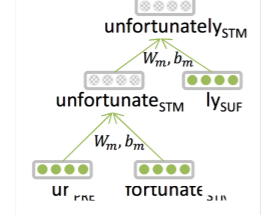
교수님이 당시 생각했던 방법은 위와 같이 트리 구조로 모델을 쌓는 것이었다. 하지만 이렇게 하려면 너무 시스템이 복잡해진다.
실제로 광범위하게 사용되는 것은 문자 단위 n-gram이다. 모델은 단어의 어디부터 어디까지가 하나의 형태소인지 확실히 알지 못한다(기존에 개발된 모듈로도 처리가 되지 않는 단어들이 있으니까?). 또한, 우리가 알지 못하는 의미적 관계가 있을 수도 있다. 이를 문자 단위로 n-gram하여 임베딩하는 것이다. 예를 들어 hello라는 단어가 있으면 3-gram 을 통해 처리하면 다음과 같이 잘라질 수 있다.
[#he, hel, ell, llo, lo#]
0-3. 왜 subword로 내려가야 하나?
그럼 왜 단어를 그대로 쓰기보다 더 분해하려고 하는지 정리해보자.
- 단어는 사전에 계속 추가되어야 한다.
독일어에서 합성어가 하나의 단어로 쓰인다. 영어에서 life insurance company employee 이렇게 띄어쓰기로 구분되어 있는 여러 단어로 이루어진 의미가 독일어에선 Lebensversicherungsgesellschaftsangestellter처럼 하나의 긴 단어로 표현된다. 이를 그대로 쓴다면, 기존에 있던 단어로 만든 합성어가 새로운 단어로 등록되어야 할 것이다. - 번역 시 음절 등의 단위로 고려되어야 한다.
christopher라는 단어를 한국어로 번역한다면, 단어로는 알 수 없다. 고유명사의 경우에 대응하는 한국 단어가 없기 때문이다. 그래서 단어를 3-gram 등으로 나누어 ch => 크, ri => 리 등의 과정을 통해 크리스토퍼로 그럴듯하게 번역될 수 있을 것이다. - 인간은 인터넷에서 괴이하게 언어를 사용한다.
인터넷은 신조어의 어머니이다. 정말 하루에도 수없이 많은 신조어들이 수많은 커뮤니티와 사람들 사이에서 만들어진다. 또한 의도적인 오타를 통해 의미를 전달하기도 한다. 이런 것들을 모두 보캡에 추가하여 대응할 수 없다. hellooooooooooooo라는 단어는 hello이다. 하지만 단어 단위로 보면, 절대 알 수 없게 된다. - 어떤 언어는 띄어쓰기가 없다.
중국어, 일본어, 아랍어 등에선 의미단위로 띄어쓰지 않는다. 이건 한국어도 해당하는 부분인데, 중국어와 일본어는 띄어쓰기가 아예 없어서, 공백으로 단어를 구분하는 것이 거의 불가능하고(전처리를 많이 하면 되기는 할 것이다), 아랍어는 의미에 따라 갑자기 단어들이 붙어서 여러 단어가 하나의 띄어쓰기 안에 묶여있게 된다. 한국어만 해도 하나의 어절 안에 여러 형태소가 섞여있게 된다(특히 문장을 마무리하는 서술어 부분). 이는 단어 단위로는 파악이 힘들고, 형태소 단위로 내려가야한다.
0-4. character-level models
그래서 우리는 subword 기반, 혹은 character-level 모델을 해볼 것이다. 이를 통해 우리가 얻을 수 있는 것은 다음과 같다.
- 모르는 단어에 대해서도 임베딩을 만들 수 있다.
- 비슷한 철자를 가진 단어들을 비슷한 임베딩 벡터로 위치시킬 수 있다.
- OOV 문제를 해결할 수 있다.
사실 subword, 형태소 기반의 모델링은 납득이 가는 모델링이다. 의미가 그렇게 구성되니까 말이다. 하지만 n-gram, 심하면 1-gram의 character level의 모델링은 좀 극단적이지 않나 싶다. 교수님도 그렇게 생각했고, 그래서 잘 되지 않을 거라고 생각했다는데, 웬걸 성능이 꽤 나온다고 한다.
하지만 character-level 모델링 시 기억해 두어야 할 점이 있다. 인간의 언어로서 문자는 전처리나 모델링이 쉽다는 강점이 있지만, 실제 "언어"라는 대상과 어느 정도 괴리가 있다는 것이다.
- 가장 이상적인 상황 : 언어의 소리와 문자가 1대1 대응일때(ex. 스페인어: 읽는대로 발음이 난다.)
- 문자의 소리가 단어마다 매우 달라질 때(ex. 영어: 단어 어원에 따라 발음이 달라진다.)
- 문자를 조합해서 문자를 만들때(ex. 한국어: 음절과 character가 일치하지 않게 된다.)
- 표의문자일때(ex. 중국어)
- 표음과 표의문자의 조합일 떄(ex. 일본어)
이를 고려하면서 이후 과정을 살펴보자.
1. Purely character-level models
그래서 워드 단위의 토크나이징 대신에 완전히 문자 단위의 토크나이징을 통한 모델링이 시작되었다. 초창기의 시도들은 NN 베이스든 전통적 방법론의 베이스든 성능이 그리 좋지 못했다고 한다. 그러다가 점차 성능을 확보할 수 있다는 논문이 나오게 되었다. 실제로, Manning 교수님이 진행한 논문에서도 비슷한 모습이다. 영어-체코어 번역 태스크인데, 단어 기반 모델과 문자 기반 모델의 성능(BLEU)가 거의 비슷하게 나오는 모습을 보여준다.

하지만 문자단위 모델링은 한 문장의 입력값이 약 7배 늘어난다. 또한, 문자 하나의 정보량이 많지 않다보니 BPTT도 길게 전해져야 해서 무려 600 시점의 역전파를 통해 위와 같은 성능을 달성했다고 한다. 긴 시점과 긴 BPTT는 결국 연산량의 증가를 의미하고, 이는 모델이 무려 3주간 학습하는 아주 오랜 학습시간을 필요로하게 된다는 단점이 있다.

하지만 장점 역시 분명하다. 위의 결과를 보면 11-year-old라는 단어는 사실 거의 무조건 oov 문제를 야기한다. 11이 숫자이기 때문인데, 이 때문에 단어단위 모델은 UNK 토큰을 뱉어내거나 원문을 그대로 가져왔다. 하지만 문자기반 모델의 경우 이를 정확히 번역해내는 모습을 보이고 있다. 또한 사람 이름인 Shani Bart의 경우에도 고유 명사이기 때문에 단어기반 모델에서는 제대로 번역을 하지 못하지만 문자기반 모델에서는 그 발음을 제대로 살려서 번역해냈다고 한다.
문자기반 모델이 가지는 특징을 좀 더 살펴보자.
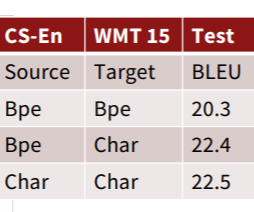
위 표는 Jason Lee가 제시한 CNN과 BiGRU를 결합한 모델의 성능표이다. 여기서 디코더에 문자기반모델을 사용할 경우에 얻는 성능 향상이 상당했지만, 인코더에선 성능 향상이 그렇게 보이지 않는 것을 알 수 있다.
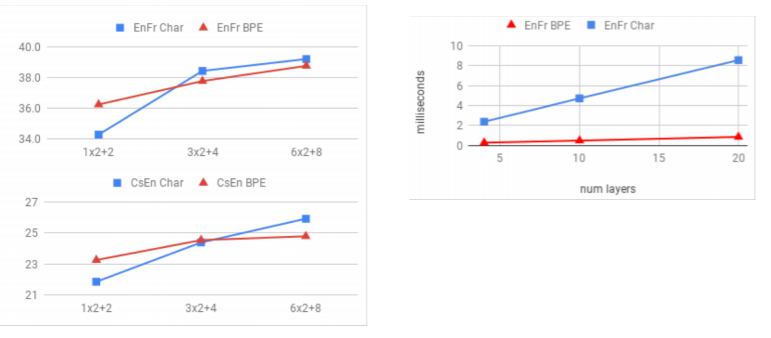
또한 Cherry와 구글 연구진들의 논문에서는 모델의 크기가 커질수록 문자기반 모델의 성능이 훨씬 좋은 것을 알 수 있는데, 언어에 따라서도 양상이 다른 것을 볼 수 있다. 언어의 형태적 특징(morphologic)이 중요한 체코어의 경우에는 문자기반모델이 얻는 성능향상이 크지만, 영어는 형태적 특징이 비교적 덜 중요해서 얻는 성능 향상이 크지 않은 모습이다. 이에 비해 문자기반 모델은 당연하게도 단어기반 모델에 비해 복잡도에서 상당한 손실을 보게 되는 것을 오른쪽 표에서 확인할 수 있다.
2. Sub-word Models
문자단위 모델은 너무 작은 단위를 기준으로 하고 있는 것 아닐까? 하나의 문자가 가지는 의미는 너무 적은데, 이를 위해 증가하는 연산량은 너무 크다. 여기서 중간 점을 찾은 두가지 트렌드가 있다. 하나씩 살펴보도록 하자.
2-1. Byte Pair Encoding
바이트란 컴퓨터에서 정보를 표시하는 가장 작은 단위이다. 8개의 비트가 하나의 바이트로 간주된다. BPE는 여기서 시작한다. 사실 BPE는 자연어나 NN과 관련이 있는 방법론은 아니었다고 한다. 본래는 압축 알고리즘의 일종으로 자주 등장하는 연속된 바이트 쌍을 딕셔너리에 저장하고 압축하는 알고리즘으로 발상 자체는 단순하다.
자연어에서는 바이트를 n-gram 문자로 간주하고 생각할 수 있다. n개의 문자가 연속해서 등장하면 하나의 단위로 간주하고 인코딩하는 것이다. 하지만 동아시아 문자들(중국어, 한국어, 일본어) 등은 문자의 수가 너무 많다. 한국어는 조합해서 한글자를 만들기 때문일 것이고, 일본어나 중국어는 한자의 사용으로 BPE를 적용하더라도 보캡의 크기가 2만이 넘어가게 된다고 합니다. 2만이라는 크기 역시 너무 크다고 생각했는지, 연구자들은 동아시아 언어 등에 대해 아예 바이트 단위로 더 내려서 인코딩하기도 한다고 합니다.
2-1-1. How to?
어떻게 BPE가 이루어지는지 살펴보도록 하자.

우선 편의를 위해 위와 같이 단어 단위의 딕셔너리와 문자 단위의 보캡이 있다고 생각하자.
여기서 가장 많이 등장하는 n-gram을 찾아보자(n=2). "es"가 9회로 가장 자주 등장하게 된다. 이를 보캡에 추가하고 딕셔너리에서 하나로 합치게 된다.

그러면 보캡은 늘어나고, 딕셔너리는 줄어들게 된다.
위의 딕셔너리에서 가장 많이 반복되는 것은 "est"이다. 이를 다시 합하여 보캡에 추가한다.

이 과정을 계속 반복하는 것이다. 즉, 가장 빈도수가 높은 n-gram을 찾아 하나의 토큰으로 보캡에 추가하는 과정을 반복한다. 종료 시점은 연구자가 보캡의 크기가 어느정도까지 괜찮을지 임의로 정하는 식으로 이루어지게 된다고 한다. 이를 통해 단어가 쪼개져서 입력값으로 활용될 수 있으면서, 문자 단위보다 많은 정보를 담을 수 있게 된다. 또한, 그 과정이 자동적으로 이루어져서 더이상 문자 단위 혹은 단어 단위의 모델링을 할 필요가 사라지게 된다. 이 방법은 2016년에 SOTA를 기록하고, 2018년에도 각광을 받았다고 한다.
2-1-2. Google and Some else
구글 기계 번역 시스템에선 두가지 버전이 있다고 한다.
이 두 방법 모두 단순히 가장 빈도수가 높은 n-gram을 합치기 보다 합쳐서 언어 모델의 펄픅렉시티를 낮추는 n-gram을 찾는 탐욕 알고리즘을 이용한다고 한다.
- 첫번째 방법은 wordpiece model이다. 이 방법은 우리가 지금까지 이야기했던 것처럼 단어 내부를 쪼개는 방식으로 이루어진다.
- 두번째 방법은 Sentencepiece model이다. 이 방법은 전체 텍스트에서 BPE를 수행한다. 띄어쓰기는 "_"로 치환되어 인코딩되고, 이후에 다시 띄어쓰기로 변환된다고 한다.
BERT 모델은 또 다른 방법을 사용하는데, at, the, fairfax, 1910s와 같이 자주 등장하는 단어들은 하나의 단어로 보캡에 넣고, 다른 단어들은 워드 피스를 이용해 쪼개게 된다. 이때 ##라는 심볼이 사용되는데, 이는 해당 페어가 단어의 시작이 아니라는 의미를 가진다고 한다. 물론 이는 보캡의 크기를 키우기는 하지만, 그래도 전체 단어를 보캡으로 가지는 것보다는 작은 크기를 유지할 수 있다.
2-2. Character-Aware Nerual Language Models
여러 모델이 언급되었지만 중요하게 언급되는 모델을 중심으로 이야기해보자. 해당 논문은 Yoon Kim의 2015년 발표된 논문으로 CNN과 LSTM을 모두 활용하여 문자 기반 언어 모델을 제시하고 있다.
2-2-1. Model Architecture
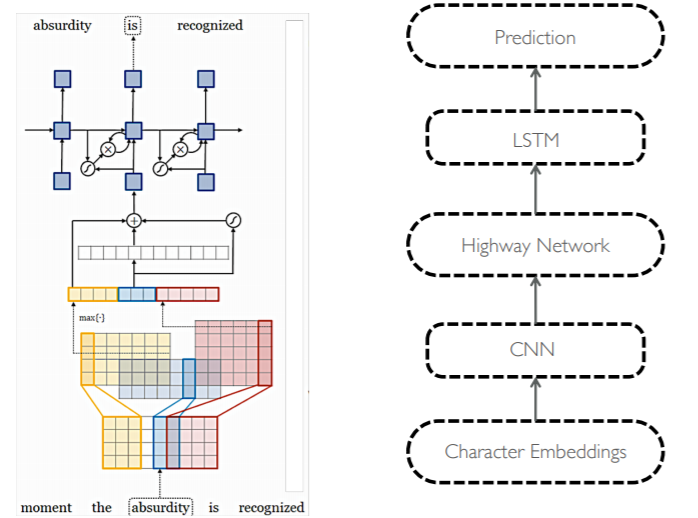
전체 모델 구조는 위와 같다. 위의 예시는 absurdity라는 단어의 입력을 받아서 is라는 출력값을 내보내야 하는 상황이다. 이때, 이전과 다르게 문자 임베딩을 입력값으로 하여 CNN과 Highway Network, LSTM을 통과하여 최종 출력을 보이고 있다. 즉, 언어 모델 자체는 LSTM을 통해 구현하고, LSTM의 매 시점 입력값을 해당 시점의 단어를 문자로 쪼개어 CNN과 Highway Network로 만들어내고 있는 것이다.
2-2-2. Convolutional Layer
우선 Convolutional Layer를 자연어에서 사용하듯이 각각의 문자에 해당하는 임베딩 벡터를 붙여서 2차원 데이터가 해당 단어의 character embeddings가 된다. 그리고 이를 1d Conv를 통해 여러 크기의 필터가 지나가면서 feature map을 만든다. 이를 다시 max pooling over time을 통해 feature representation을 생성하게 된다. 이때, max pooling over time은 결국 해당 단어의 의미를 잘 표현하는 특징만 모으는 과정이라고 할 수 있다.
2-2-3. Highway Network
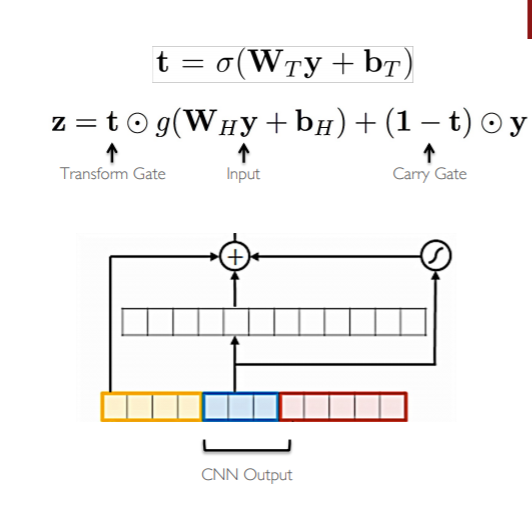
하이웨이 네트워크는 resnet과 비슷한 개념이다. 이미지를 LSTM과 같이 게이트로 통제하면서 정보를 잘 전달하기위해 개발된 모델이다. 위의 이미지에서 보듯이, 기존의 이미지와 비선형 변환된 이미지가 Transform gate를 통해 합쳐지는 모습을 하고 있다. 이를 통해 좀 더 문자 단위 feature representation을 잘 표현하고자 하는 것 같다.
2-2-4. LSTM
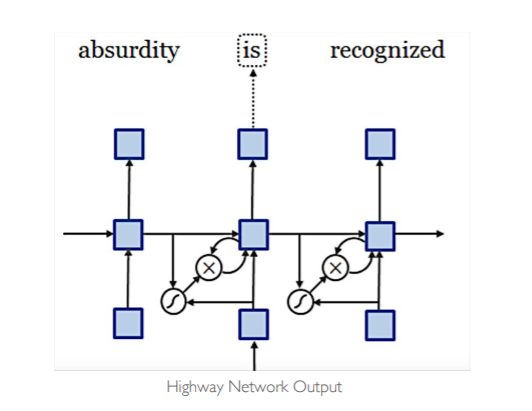
이후 Highway Network를 통과한 최종 벡터를 LSTM의 입력값으로 사용한다. 이때, 단순 소프트 맥스를 사용하기보다 Hierarchial Softmax를 통해 계산량을 줄인다. 이는 나중에 따로 다뤄보도록 하자.
2-2-5. Results
사실 위의 모델 구조는 특별할 것은 없다. 수업에서도 그냥 지나갔다. 이전에 다 다룬 내용이기 때문에 대충 설명하더라도 이해하는데 무리는 없었을 것이다. 이 모델은 그 결과에서 좀 더 이야기할 부분이 많다.
- 더 작은 모델로 좋은 성능을 낼 수 있다.
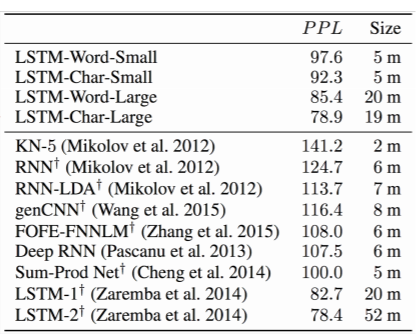
위의 표에서 보듯이, 문자기반 모델은 LSTM-2와 비슷한 성능을 보이면서도 모델의 크기는 1/3 정도이다.

그것보다 신기했던 부분이 바로 위에 부분이다. 첫 줄은 단어기반 LSTM 모델이고, 가운제 줄은 하이웨이넷을 통과하기전, 문자기반 Conv+MaxPooling을 했을 때, 마지막 줄은 하이웨이넷을 통과한 벡터와 각 실제 단어 벡터의 유사도를 측정한 결과이다. 이때 단어기반 모델은 사실 비슷한 단어들을 잘 잡아내지 못하는 반면, 문자기반 모델은 잘잡아내고 있다. 또한, 하이웨이 넷을 통과하기 전에는 단어의 철자나 형태적으로 유사한 단어들을 잡아내고 있고, 하이웨이 넷을 통과한 벡터에선 의미적인 부분을 잘 잡아내는 모습이다. 아마 하이웨이 넷이 실제 단어들의 공간으로 맵핑해주는 역할을 하는 것으로 보인다.
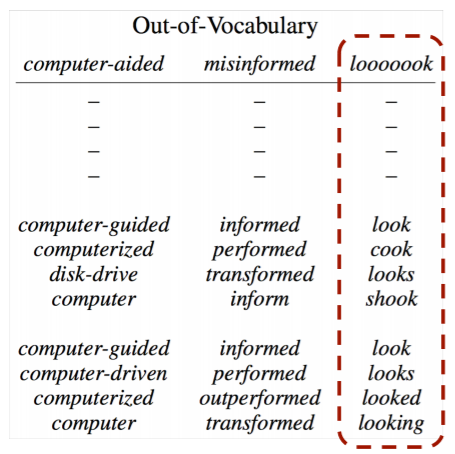
이러한 결과는 OOV의 경우에도 마찬가지인데, 단어기반 모델은 OOV에 대처하지 못하는 반면에, 문자기반 모델은 잘 대처하는 모습을 볼 수 있다. 또한 대처하는 것을 넘어서 실제로 유사한 단어들이 하이웨이넷을 통과한 결과에 나오는 것이 보인다.
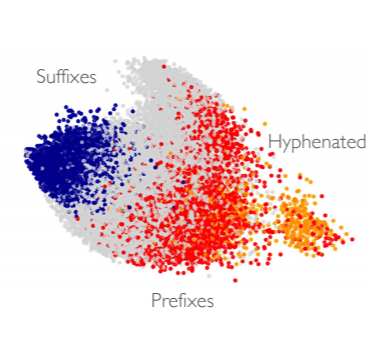
심지어 이는 2d로 벡터를 시각화 한 결과에서도 보이는데, 접미사와 접두사, 하이픈 등의 유사한 subword들이 비슷한 공간에 맵핑되어 있는 모습을 볼 수 있다.
2-3. Hybrid NMT
하지만 문자 기반만 사용하게 되면 연산이 많이 필요하게 된다. 대부분의 경우 단어 기반 모델링으로 충분하고 필요할 때만 문자 기반 모델을 활용하는 것이 Hybrid NMT이다.
2-3-1. Model Architecture
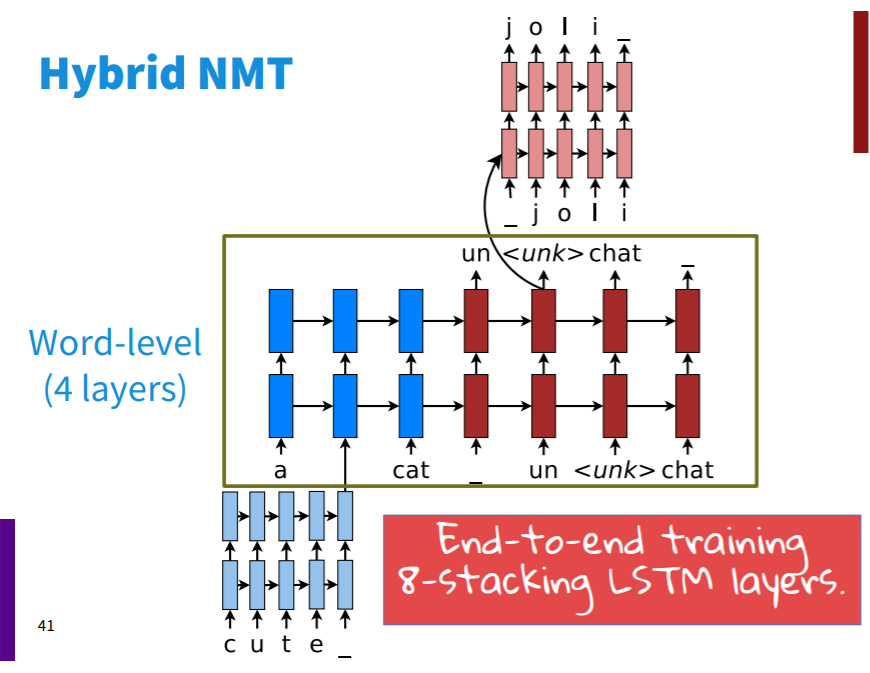
Hybrid NMT의 구조는 위와 같다. 약 12000개의 보캡을 가지고 있는 모델로, UNK 토큰의 경우 문자 기반 LSTM을 통해 처리한다.
구체적으로 이야기해보면, 보캡에 없는 단어가 인코딩에 사용되면 해당 단어를 문자 단위 LSTM으로 입력하여 임베딩 벡터를 얻는다. 그리고 이를 입력값으로 활용한다. 디코딩에서 UNK 토큰이 발생할 경우, hidden state를 문자 기반 LSTM의 0 시점 hideen state로 사용하여 보캡에 없는 단어를 생성하게 된다. 이를 통해 당시 SOTA를 달성했다고 한다.
3. Chars for Word Embeddings(FastText)
이러한 문자 단위의 방법론을 word2vec에 적용해보자는 것이 fasttext의 개념이다. 만약 wisdom이라는 단어가 있고, 이를 임베딩할 때, 3-gram이라고 한다면, <wis, isd, sod, dom, om>, 이렇게 6개의 subword를 만들 수 있다. 그리고 이들을 이용해 기존의 word2vec 알고리즘을 돌리고, 6개의 벡터를 합하면 wisdom에 대한 임베딩 벡터를 구할 수 있게 된다.
