0. Representations of a word
지금까지 배운 내용을 정리해보자면, 2011년 이전까진 NN을 이용한 자연어 처리 기법들은 사실 각광을 받지 못했다. Feature Engineering을 통한 모델들보다 성능이 좋지 못했고, 그럼에도 학습에 오랜 시간이 걸렸기 때문이다.
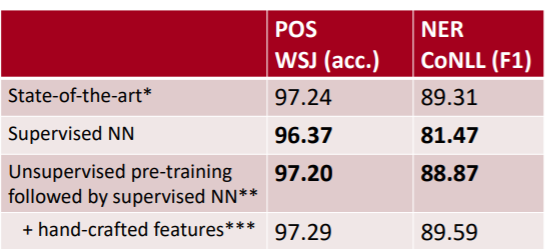
위 표는 NN을 이용한 모델들과 Feature Engineering을 통한 모델을 비교한 표이다. 위에서 볼 수 있듯이 기존에는 Feature Engineering이 월등히 성능이 좋았다. 그러다가 로이터 통신과 위키피디아에서 약 13만 단어를 가지고 와서 100개의 노드를 가지는 NN으로 7주 동안 학습을 시키자, Feature Engineering과 비슷한 성능을 보이기 시작했다. 그래, NN도 성능을 낼 수 있구나! 하는 확신을 어느 정도 가질 수 있게 되었다.
그리고 나서 Word2Vec, Glove와 같은 임베딩들이 등장했다. 대량의 코퍼스를 통한 무척 많은 단어에 대한 워드 임베딩들은 학습 시간을 무척 단축시킬 뿐만 아니라, 랜덤하게 시작한 임베딩 벡터들보다 성능이 나았다. 그래, 사전 학습된 임베딩들을 활용하면 시간도 단축할 수 있구나! 하는 것도 알았다.
사전 학습된 임베딩들이 가지는 장점은 또 있다. UNK 토큰, 즉 OOV 발생 시 사전 학습된 임베딩을 활용하면 어느정도 해결할 수 있었다. 위에서 말했듯이 사전학습된 임베딩은 훨씬 큰 보캡을 가지고 있기 때문에 가능한 일이었다.
또한, UNK 토큰 등장시 문자 단위 모델링을 한다든가, UNK 토큰 대신 랜덤 벡터를 주고, 사전에 추가하는 방법들이 등장하여 OOV 문제도 해결이 가능해보였다.
하지만 사전학습된 임베딩들은 두가지 문제가 있었다.
- 하나의 단어에 대해 고정된 하나의 임베딩을 가지게 된다.
스타라는 단어는 영화나 드라마 산업에서 사용될 때와 천문학계에서 사용될 때, 전혀 다른 의미를 가지게 된다. 하지만 스타라는 단어가 가질 수 있는 임베딩 벡터는 단 하나이다. 이는 결국 전혀 다른 두 단어가 하나의 임베딩 벡터로 표현되어야 한다. - 문맥적 정황이 전혀 고려되지 못한다.
단어 벡터들은 모두 문맥이라는 것이 없다. 어떠한 상황이든 똑같은 벡터가 사용될 뿐이다. 하지만 때와 장소에 따라서 동일한 의미의 단어라도 다른 단어들이 사용된다. 임베딩 벡터를 통해서는 이러한 문제를 해결할 수 없다.
하지만 이전에 배웠던 모델들을 생각해보면, 어느정도 이러한 점을 해결했다고 이야기할 수 있다.
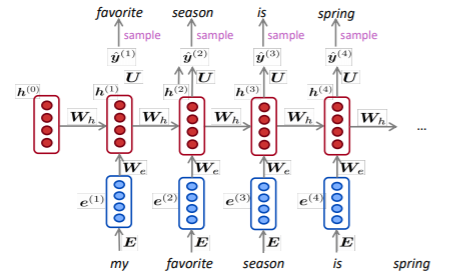
위 모델은 LSTM의 언어모델인데, 각 시점의 hidden state들은 결국 맥락 정보가 담긴 벡터들이 된다. 다시 말하면, 각 시점의 hideen state들은 해당 시점의 단어 정보 + 이전 시점들의 맥락 정보를 담고 있는 게 아닐까? 그러면, 이 벡터를 사용하면 해결되지 않을까??
1. TagLM
TagLM의 메인 아이디어는 다음과 같다.
입력값으로 단어의 임베딩과 맥락적 임베딩까지 함께 사용하자.
이전에도 말했듯이 임베딩 벡터들은 맥락적 정보들이 없다는게 문제였다. 이는 특정 도메인의 태스크에서 도메인에서 사용되는 맥락이 중요한 단어들에게는 중요한 문제일 수 있다. 이를 이용해 TagLM은 비지도 학습으로 각 단어의 맥락정보를 반영했다.
1-1. Model Architecture
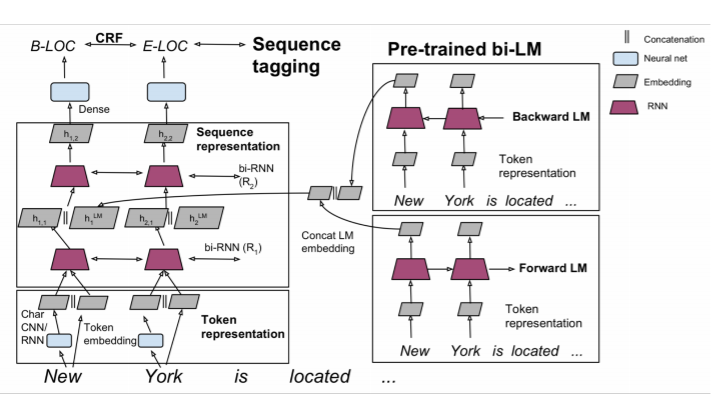
TagLM의 모델 구조는 위와 같다. 우선 BiLSTM으로 LM 모델을 구성한다. 여기에 해당 도메인의 대량의 데이터를 학습시킨다. 이를 통해 각 단어의 hidden state는 그 도메인의 맥락에 맞는 의미를 가지게 될 것이다. 양방향 hidden state를 concat하여 활용하는 것이다.
또한 CNN을 활용해 문자 단위 임베딩을 만들고, 본래의 임베딩 벡터 역시 concat하여 일반적인 입력값으로 활용한다. 일반적인 입력값은 BiRNN을 통해 처리되고, hidden state들이 다음 레이어로 들어가게 된다. 다음 레이어는 이전 레이어에서 온 hidden state들과 LM의 concatenate한 벡터를 다시 concatenate하여 BiRNN의 입력값으로 활용한다. 그래서 최종적인 NER 태스크를 수행하게 되는 것이다.
이때, LM 파트는 사전학습되어 사용되어, 실제 NER 태스크를 하는 모델 학습이나 inference 시에는 프리즈되어 학습되지 않게 된다.
모델 구조가 복잡하지는 않다. 하지만 그 아이디어가 기존의 단어 임베딩이 가지는 문제점을 해결하려고 했다는 점이 중요할 것이다.

그 결과 TagLM은 CoNLL 태스크에서 SOTA 모델을 달성하게 된다.
1-2. Conclusion
- 지도학습을 통한 LM 모델의 학습은 전혀 도움이 되지 않는다.
- 양방향 모델이 단일 방향의 모델보다 훨씬 좋다.
- 큰 데이터로 큰 LM 모델을 만들어 활용하는 것은 확실히 도움이 된다.
2. ELMo(Embeddings from Language Models)

그래서 문맥을 임베딩하는 과정을 일반화하고자 ELMo가 등장했다. ELMo는 결국 TagLM에서 LM 모델이 문맥을 임베딩했듯이, 여러 태스크에서 사용하도록 임베딩 벡터를 만드는 모델이다. 즉, 이 모델을 통해 feature extraction을 하는 것이 목적이라고 할 수 있다.
2-1. Model Architecture
ELMo의 구조는 다음과 같은 요소를 사용한다.
- 2층의 BiLSTM
- 문자단위 CNN을 사용
이때 2048개의 n-gram 필터와 2층의 highway layer를 이용한다. 이때 highway layer를 통과한 벡터는 4096차원이므로 너무 크기 때문에 NN을 이용해 512차원으로 맵핑해준다.
-Residual Connection
전체 구조는 위와 같다. 다시 설명하자면,

우선 단어의 문자단위 CNN을 통해 임베딩 벡터를 생성한다. 위에서 언급한 바와 같이 4096차원 벡터를 NN 구조를 통해 512차원으로 맵핑한 벡터를 출력한다.
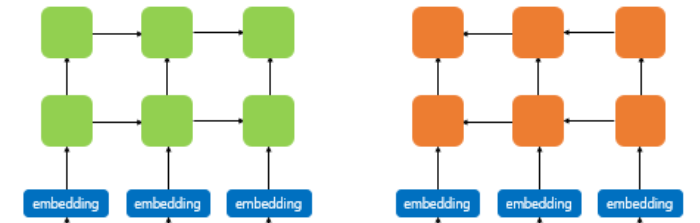
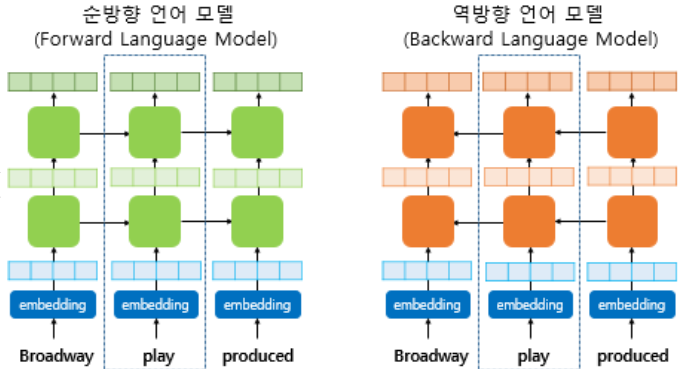
이후 이 값을 2층의 BiLSTM을 통해 LM 태스크를 수행한다. 이때 첫번째 LSTM층의 출력값은 CNN 임베딩과 Residual Connection으로 연결되어 있다. 이때, 두 방향의 LSTM은 서로 공유되지 않는다.
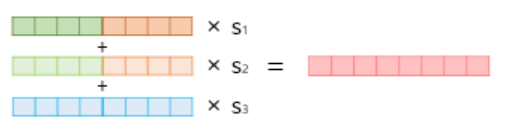
그리고 각 레이어의 hidden state를 모두 가져와서 임의의 weight와 곱하고 더한다.
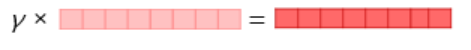
마지막으로 전체 벡터의 스케일을 결정하는 파라미터를 곱해서 최종 임베딩 벡터를 뽑게 된다.
ELMo의 저자는 입력층에 가까운 레이어일수록 문법적 정보를, 위로 올라갈수록 문맥적 정보를 가지고 있다고 한다. 즉, Feature가 레이어를 거치면서 점차 가공되어가는 것이다. ELMo는 하고자하는 태스크가 해당 정보들 가운데 어떤 정보를 중요하게 여기는지 모르기 때문에 s를 곱해서 결정하고, ELMo로 만든 임베딩 벡터가 유용한 정도 역시 알 수 없기 때문에 를 통해 결정하는 것이다. s와 모두 태스크에서 학습되게 된다.
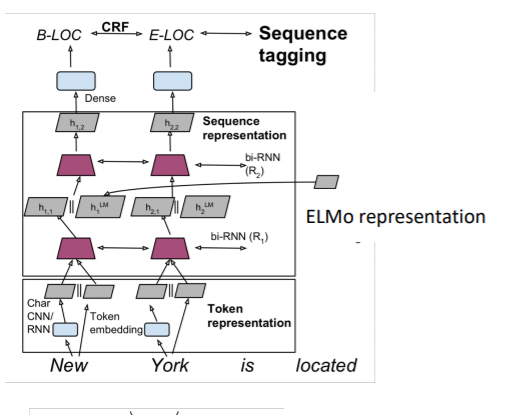
그리고 최종적으로 이렇게 만들어진 벡터는 기타 다른 태스크에 concatenate하는 식으로 사용되게 된다. 위의 그림도 앞에서 언급한 TagLM에서 ELMo를 사용한 경우를 보여주고 있다. 매우 간단한 모습이다.
2-2. Result

그 결과 ELMo는 NER에서 SOTA를 달성할 수 있었다. 하지만 이보다 ELMo를 더 중요하게 만든 것은, ELMo는 매우 간단하게 다른 태스크에도 활용할 수 있다는 점이었다.
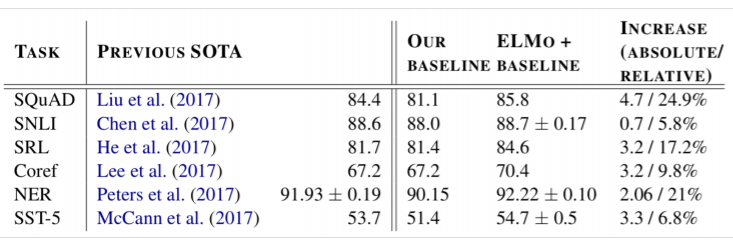
많은 태스크에 ELMo를 적용한 결과 적게는 0.7%p에서 많게는 4.7%p에 이르기까지 엄청난 성능 향상을 거뒀다. 단순히 ELMo를 적용해서 성능이 이렇게 오른다는 것은 매우 놀라운 일일 수밖에 없다.
2-3. Layers
위에서 언급했듯이 ELMo의 레이어들은 각각 다른 역할을 한다. 아래층은 문법적 요소, Tag of Speech, NER를 잡아내고, 상위층은 문맥적 요소를 잡아낸다. 이것이 각각의 태스크마다 유용한 정도는 다를 것이다. NER 태스크를 한다면 하위 레이어의 정보가 더 유용하고, 감성 분석 태스크에선 상위 정보가 더 유용할 것이다. ELMo에선 그래서 가중치를 이용해 이 레이어들의 정보를 가져오게 되는 것이다. 그래서 레이어를 추가하면 더 좋은 성능을 보일 수도 있을 것이라고 강의에선 이야기한다.
3. ULMfit
여기서 또다른 접근법이 등장한다. ELMo와 비슷하지만 조금 다르다. ULMfit은 대량의 데이터로 학습된 LM을 이용해 각각의 도메인에 대한 fine tuning을 통한 다른 태스크로의 전이학습을 이야기하고 있다.
3-1. fine-tuning & transfer learning
전체 과정은 아래와 같다.
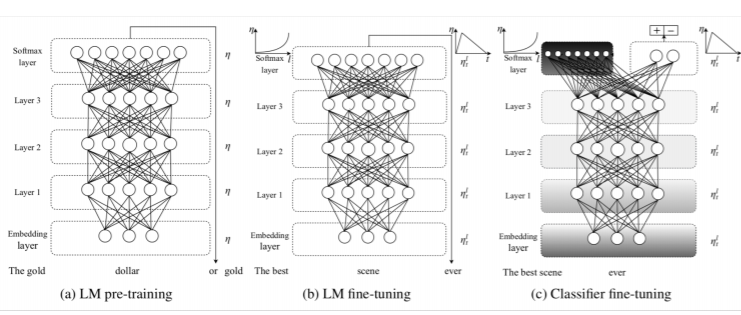
우선 ULMfit에서 큰 데이터를 바탕으로 LM 모델을 학습시킨다. 이후 해당 도메인의 데이터로 이미 대량의 데이터로 학습된 ULMfit을 그대로 가져와 LM으로 fine-tuning을 한다. 이후, 해당 태스크에 맞게 가장 마지막 레이어를 고치고, 목적함수를 설정하여 transfer하면 된다. 이를 통해 ULMfit은 이후에 등장하게 될 트랜스포머 등에서 자주 사용되는 사전학습이나, fine-tuning, 전이 학습의 개념들이 사용되었다. 즉, 모델을 그대로 가져와서 상위 레이어 몇개만 수정하고 목적함수만 바꿔주면 어느정도의 성능을 확보할 수 있는 모델을 우리는 이제 가지게 된 것이다.
3-2. Result
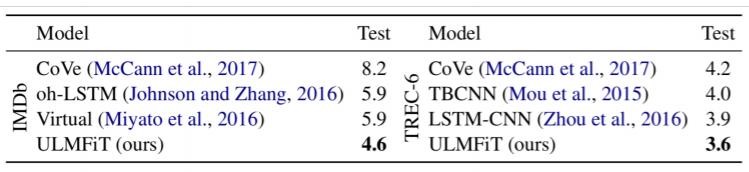
실제로 ULMfit은 다양한 태스크에서 SOTA를 보였다고 한다. 하지만 더 중요한 것은 따로 있다.
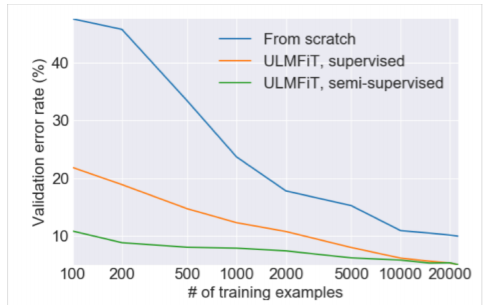
위 그래프에서 가로축은 학습에 사용된 데이터의 수이다. 그리고 가장 위의 선은 처음부터 학습한 모델이고, 가운데 선은 지도 학습만 이루어진 ULMfit, 가장 아래 선은 비지도학습으로 LM까지 이루어진 ULMfit이다. 위에서 보이듯이 데이터가 적을수록 사전학습과 전이학습의 효과가 매우 크게 나타나고 있다. 결국 데이터가 적고 큰 모델을 한번에 학습시킬 여건이 되지 않는 상황에서도 이미 사전학습된 모델을 활용하여 성능을 확보할 수 있다는 것이다.
3-3. After that
즉, 요약해보자면, 엄청 엄청 거대한 Language Model을 만들면, 여기저기 활용할 곳이 엄청 많다는 이야기다. 즉, 태스크마다 따로 모델을 만들지 말고, 그냥 큰 모델 하나 만들어서 그거 튜닝해서 쓰면 되는거다. 여기서, 대기업들이 나서기 시작한다.
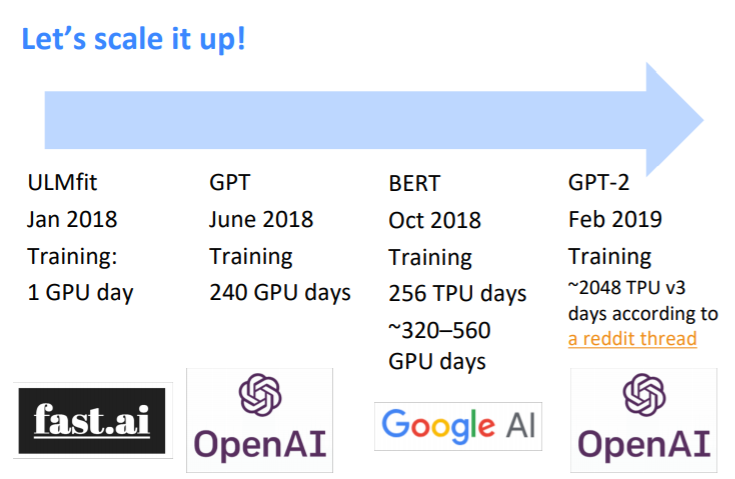
ULMfit은 고작 1 GPU day만한 연산으로 학습이 이루어졌다. 이후에 GPT나 BERT, GPT-2의 경우엔 점점 커져서, 2048 TPU v3 day가 걸리게 된다. 정말 말도 안되게 큰 사이즈다. 이를 통해 GPT-2는 어느 정도의 성과를 거두게 된다. 인간과 비슷하게 말하는 듯한 느낌을 주는(일부러 장황하게 썼다. 얘도 어쨋든 언어를 이해한다든가 인간과 자유롭게 대화가 되지는 않는다.) 모델이 된 것이다.
4. Transformer(LSTM is dead, Long Live Transformer)
사실 위의 세 모델은 트랜스포머의 변형 모델들이다. 즉, LSTM과 CNN으로는 아무리 대용량 서버로 학습시켜도 저런 성능이 나오지는 않는다. 트랜스포머에 대해 이제 살펴봐야 할 동기가 생길 것이다.
트랜스포머 이전의 상황은 다음과 같았다.
- RNN류의 모델들은 장기적인 정보를 전달하는데 여전히 어려움을 겪고 있었다.
- 어텐션 메커니즘이 해당문제를 해결해주었다.
- 하지만 여전히 RNN류 모델들은 병렬처리가 불가능했다.
여기서 트랜스포머는 다음과 같은 결론에 도달한다.
RNN이 병렬처리가 안돼서 학습이 힘들면, 어텐션만 가져오고 RNN 구조는 버려보자!
그렇다. 트랜스포머를 제시한 논문 제목도 Attention is All You Need 이다. 어텐션만으로 전체 모델을 꾸리는 것이다. 이를 통해 병렬 처리가 가능해지고, 대형 모델의 구성이 가능해졌다.
4-1. Tricks
4-1-1. Dot Product Attention
트랜스포머의 어텐션은 간단한 내적 어텐션이지만 조금 다른 부분이 있다.
복잡해 보이는 위 식이 바로 트랜스포머의 어텐션 기본식이다. 기본적으로 내적 어텐션이지만, 가중치를 구하는 벡터와 실제 가져오는 정보의 벡터가 다르다. 가중치는 Query와 Key를 이용하고 정보는 Value를 이용하게 된다. 자세한 사항은 나중에 보도록 하자.
하지만 단순 내적의 경우에는 스케일링이 전혀 되지 않는다는 것이 문제다. 벡터들의 차원이 커질수록 내적값들은 커지는 경향을 가지게 된다. 이는 소프트맥스 함수에서 특정 값들이 지나치게 커지게 만들고, 그래디언트가 매우 작아지게 만들어서 학습에 방해가 된다. 이를 방지하기 위해서 트랜스포머에서는 Query와 Key의 벡터들을 내적할 때, 스케일링한다. 식은 다음과 같다.
여기서 는 벡터의 차원 수이다.
4-1-2. Multi-head Attetion
이렇게 self attention을 구현하면 하나의 레이어가 어텐션 sub layer가 만들어진 것이다. 하지만 우리는 트랜스포머를 깊고 복잡한 모델로 만들고자 한다. 그래서 어텐션을 여러개 묶을 방법을 찾으려고 한다. 하나의 어텐션보다 여러 개의 어텐션을 묶는 것이 더 복잡한 모델이 될 수 있기 때문이다. 이를 통해 여러 어텐션들이 다른 방면에서 동일한 문장을 보도록 만들 수 있다. 어떤 어텐션은 단순히 조사를 집중적으로 보고, 다른 레이어는 주술 관계를 집중적으로 보는 식으로 만들 수 있다. 식은 다음과 같다.
이를 그림으로 표현하면 아래와 같다.
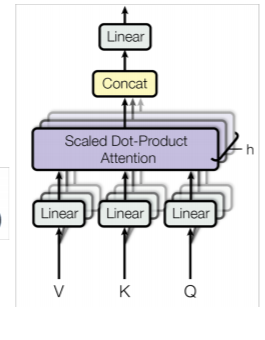
즉, Q, K, V를 선형 변환를 통해 차원을 축소시키고, 이를 동일한 구조의 h개의 attention에 넣는다. 그리고 그 결과를 concatenate하여 최종 출력을 내는 것이다.
4-1-3. Sublayers & LayerNorm
MultiHead Attention 하나는 위와 같이 구성되는데, 이번에는 수직적으로 모델을 복잡하게 만들고자 한다. 즉, MultiHead Attention을 더 쌓아서 층을 늘려보고자 하는 것이다.
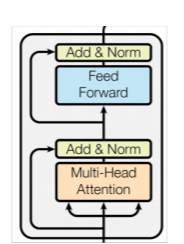
이때 Residual Connection과 LayerNorm이 사용된다. 입력값으로 들어온 임베딩 벡터는 Q, K, V로 나누어져 MultiHead Attention을 통과하고, Residual Connection을 통해 합치고, Layer Norm을 거친 이후 다시 Residual Connection이 있는, NN층을 통과한다. 이때 Layer Norm은 BatchNorm과 비슷한데 조금 다르다. LayerNorm은 한 레이어 내의 출력값을 평균 0, 분산 1로 스케일링하는 것이다. 배치 단위의 계산이 아니다. 위와 같은 블록은 sublayer라고 부르며 이 레이어를 반복적으로 쌓아 인코더를 만들게 된다. 논문에선 6층을 쌓았다.
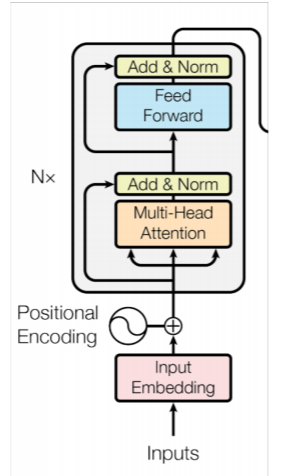
4-1-4. Positional Encoding
RNN류의 모델은 입력값을 시점에 따라 순차적으로 입력되어 sequential한 데이터의 특징을 살렸다. 하지만 현재까지 설명으론 트랜스포머는 시점에 대한 정보가 전혀 없다. 어순과 관계없이 단어들을 넣어도 모델은 인지하지 못하게 된다. 모델에 시점에 대한 정보를 넣는 것은 sin과 cos함수를 통해 주기적인 정보를 만들어서 더하는 방법을 통해 이루어진다.
4-1-4. Encoding Result
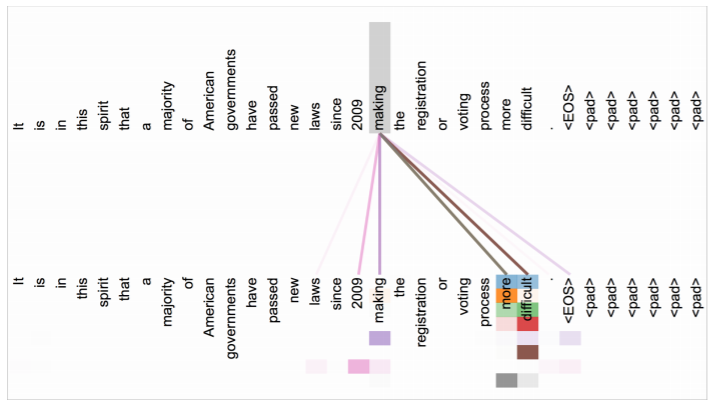
위의 그림은 5번째 sublayer의 모습이다. query가 making 일때, 어떠한 단어들에 어텐션을 두는지 보여주는 것인데, making이 이용되는 단어들에 집중하는 모습을 보여준다. 즉, making more difficult라는 구문을 잡아내는 모습이다.

위에서는 its가 의미하는 본래 명사와 its가 수식하는 명사를 정확히 집어내는 모습이다. its는 law를 의미하고 apllication을 수식하는데, 이를 강한 어텐션을 통해 잡아내고 있다.
4-2. Decoder
교수님은 디코더를 다음 수업으로 남기신 듯하다. 다음 시간을 좀 더 자세히 다뤄보자.
5. BERT

버트는 트랜스포머에서 인코더를 떼어와서 문장의 representation을 만들고자 하는 모델이다. 그래서 이름도 Bidirectional Encoder Representations from Transformers이다.
버트가 제시한 문제는 다음과 같았다.
문장 이해, NLU는 결국 LM을 통해 이루어진다. 그런데. LM은 다음 단어를 예측하는 태스크를 통해 학습하기 때문에, 이전 시점의 정보만 가지고 학습하게 된다. 하지만 실제 문장 이해는 양방향의 정보를 가지고 이루어진다.
- 다음 단어를 예측하는 태스크는 양방향 모델로 만들 수 없다. 다음 단어에 대한 정보가 이미 출력 전에 흘러와서 반영되어 버리기 때문이다.
- 트랜스포머의 양방향 인코더는 단어들이 스스로 문장 내의 다른 단어를 보기 때문에 적절하지 않을까?
5-1. Train
5-1-1. Masking
버트는 그래서 학습을 바꿨다. 다음 단어가 아니라 중간에 단어를 맞추도록 말이다.
The man went to the store to buy a gallon of milk
위와 같은 문장이 있을 때,
The man went to the [MASK] to buy a [MASK] of milk
와 같이 단어를 마스킹해서 비어버리면 모델은 문장을 이해해서 이를 맞출 수 있지 않을까? 이때, 너무 많은 단어를 비어버리면, 문장의 정보가 부족해서 제대로 맞출 수 없고, 너무 적게 비어버리면, 모델 학습이 너무 오래걸리는 일종의 trade off 관계가 있었다. 이를 15%로 고정하여 사용했다고 한다.
물론 ELMo도 BiLSTM을 사용한다. 하지만 처리 과정에서 두 방향의 정보는 개별적으로 처리된다. GPT-1의 경우엔 아예 사용하지 않는다. 버트는 그래서 아래와 같은 모델 구조를 가지게 되었다.
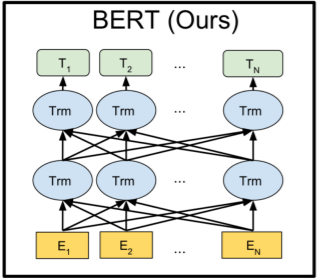
5-1-2. Next Sentence Prediction
버트는 학습에서 두가지 태스크를 한다고 한다. 하나는 마스킹이었고, 다른 하나는 다음 문장 예측이다. 이를 통해 학습이 더 잘된다고 하는데, 자세한 내용은 논문을 봐야 알 수 있을 것 같다.

대략적인 내용은 다음과 같다. 두 문장을 입력값으로 해서, 두 문장이 연속된 문장인지 아닌지 판단하는 것이다. 즉, 이진분류 문제인 것이다. 이를 통해 문장 간의 관계를 학습할 수 있다고 한다.
5-2. Input
이렇게 복잡한 태스크를 하다보니 입력값도 좀 다양하다.
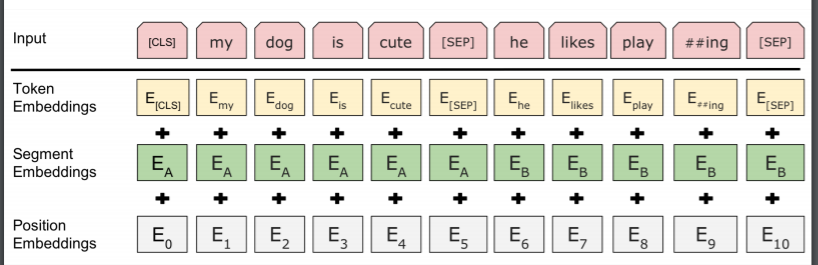
위와 같은데, 기존의 토큰 임베딩이 첫번째 줄, 트랜스포머의 positional embedding이 마지막 줄이다. 두번째 줄은 문장 구별을 위해 들어간 임베딩이다.
5-3. fine tuning & Result
ULMfit처럼 버트도 fine tuning을 통해 다양한 태스크를 수행할 수 있다고 한다. 이때 마지막 레이어와 목적함수를 바꿔주기만 하면 된다.
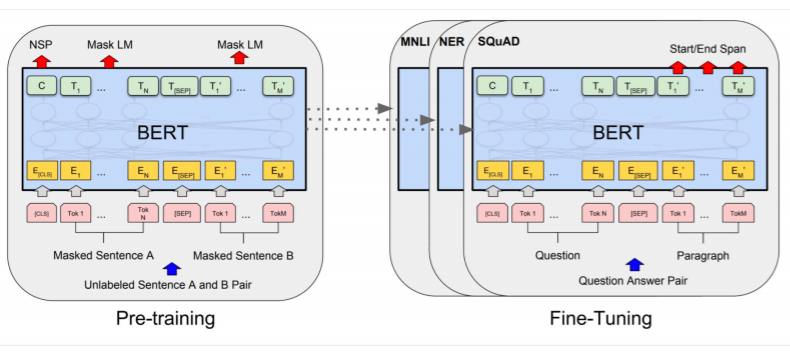
역시 그래서 버트는 결국 모든 태스크에서 SOTA를 달성했다.
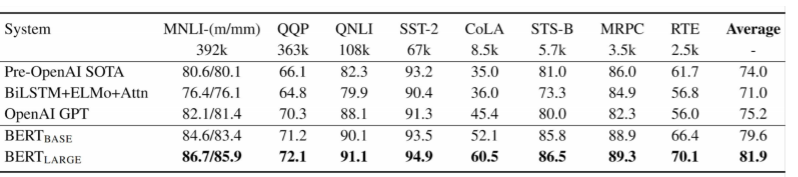
특히 모델의 크기를 키우자 성능이 더 향상되는 모습을 보였다고 한다.
결국 2019년 겨울 당시의 강의 상황에 한정해서 이야기해보자면, NLP도 vision분야처럼 거대 모델을 개발하여 fine tuning하는 길로 접어들고 있다고 교수님은 이야기한다. 지금의 상황이 어떤지는 잘 모르겠다. 며칠 전에 네이버에서도 한국어판 GPT-3 모델을 발표하고, OPEN AI에서도 GPT-4의 크기를 더 키워서 준비하고 있다는 이야기가 들린다. 자연어 처리 연구가 결국 거대 모델을 개발하고, 이를 활용하는 방안으로 계속 나아가는 것 같다. 그렇다면 대학원에서 연구자로서 할 수 있는 부분이 뭐가 있을지 고민이 된다. 난 기업에 가고 싶지 않다. 아직은 그래도 무언가 "연구"라 할만한 내가 하고 싶은 분야를 고르고, 내가 생각한 모델 구조와 학습 방법들을 고민하고 싶다. 하지만 대학원에서 충분히 그것이 가능할지 이제는 걱정해야 하는 것인가 하는 고민이 들기도 한다. 그래도 가야지!
