이번 수업에선 컴퓨터 공학이나 수학에 대한 이야기보단, 인간이 언어를 사용하는 방식에 대해 주로 다루게 된다. 사실 언어마다 구조가 다르기 때문에, 한국어와 영어는 전처리 방식도 다르고, 분석 방식도 달라지게 되는데, 본 강의는 영어를 기준으로 하고 있다.
1. Prase Structure Grammer (Context free grammers)
the large cat in a crate
이라는 문장이 있다고 해보자. 사실 문장은 아니다. 영어로 noun phrase(NP)라고 하는 것이다. 이를 뜯어보면 "the large cat"이라는 NP가 또 있고, "in a crate"이라고 하는 Prepositional Phrase(PP)가 있다. NP는 determiner + (adjective) + noun의 꼴이고, PP는 preposition + NP의 꼴이다. 이를 응용하면 the cat by the large crate on th large table by the door와 같은 NP + PP + PP 식의 순환형 구조가 가능하다는 것을 알 수 있다.
talk to my daughter라는 문장은 Verb + Preposition + NP의 구조이다. 이를 더 크게 보면 Verbal Phrase(VP)와 NP의 합이라는 것을 알 수 있다. 이러한 형태는 사실 문맥에 상관없이 유지되는 형태이다. 즉, 어떤 문장, 어떤 구절이든 앞뒤 상관 없이 파악이 가능하다.
2. Dependecy Structure
사실 대부분의 문장은 위와 같이 이루어져 있지 않다. 각각의 요소들이 서로 얽혀있다.

위 문장은 from space라는 PP가 scientist에 의존하는 형태이다. 하지만 whale에 의존하는 것으로 보면, 과학자들이 우주에 있는 고래들을 셌다 라고 해석할 수도 있다. 이처럼 언어는 각각의 요소가 어디에 의존하는지 제대로 파악하지 못한다면 의미를 제대로 파악할 수 없다. 이를 제대로 파악하기 위해서는 표준화된 방법을 통해 관계를 표현해야 한다.
3. Universal Dependencies treebanks
이를 구현한 것이 universal dependencies treebanks이다.

위 그림처럼 각 단어의 관계를 화살표와 역할을 써놓아서 완성했다.
treebank는 학자들이 일일히 구축해 놓아야 한다. 문장마다 분석하여 수작업으로 만들어지는데 대체 왜 이런 수고를 할까?
-
구조화된 데이터를 구축할 수 있다. 모두 동일한 문법으로 문장을 분석해 놓기 때문에, 정형데이터처럼 머신러닝에 사용할 여지가 있다고 한다.
-
의미를 분명하게 볼 수 있다. 자연어 문장은 매우 모호하게 형성되어 있다. 하지만 treebank를 보면 아주 확실한 구조와 의미를 알 수 있고, 이를 통해 계산이 가능해진다.
4. Greedy transition-based parsing
그렇다면 어떻게 이런 상호 의존적 구조의 언어를 분석(parse)할 수 있을까? 강의에선 greedy transition-based parsing이라는 방법론을 소개하고 있다.
4-1. Arc-standard transition-based parser
I ate fish 라는 문장이 있다고 하자.
시작은 다음과 같다.
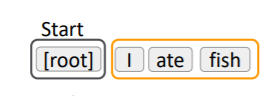
검은색 박스는 stack, 즉 현재 처리할 데이터가 놓인 곳이고, 주황색 박스는 buffer 즉, 아직 처리되지 않은 내용을 저장하는 곳이다. 첫 단계는 당연히 아직 분석이 시작되지 않았으므로 root만 stack에 있게 된다. 이때는 root만 stack에 있으므로 분석할 내용이 없고, 이로 인해 취할 수 있는 행동은 shift 밖에 없다.
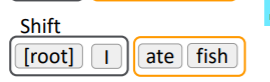
한번의 shift 결과 I가 stack이다. 하지만 여전히 처리할 데이터가 root와 I밖에 없으므로 한번 더 shift 하게 된다.

이제 stack 안에 I와 ate를 비교할 수 있다. 이 때 I가 ate에 의존하고 있으므로 I를 지우고 I가 ate에 의존한다고 표현하면 된다.

그 결과 stack은 위와 같이 바뀌게 된다. 이 과정을 문장이 모두 처리 될 때까지 반복하면, buffer는 비게 되고 stack엔 root와 단어 하나만 남게 된다. 남은 단어는 당연하게도 root에 의존하므로 남은 단어마저 지우면 root만 stack에 남아 모든 분석이 종료되게 된다.
위 과정을 동적 프로그래밍을 통해 구현하면 세가지 동작이 존재한다.
- shift : stack에 buffer에 있던 데이터를 가져와서 추가하는 과정이다. stack에 단어가 하나만 있을 경우 수행하게 된다.
- left arc : stack에 있는 두 단어 중 왼쪽에 있는 단어, 즉, 위에서 두번째 stack이 stack 최상단의 단어에 의존할 경우 왼쪽에 있는 단어를 지우는 과정이다. 이를 통해 의존 관계를 파악하게 된다.
- right arc : stack에 있는 두 단어 중 오른쪽에 있는 단어, 즉, stack 최상단의 단어가 stack의 위에서 두번째 단어에 의존할 경우 오른쪽에 있는 단어를 지우는 과정이다. 이를 통해 의존 관계를 파악하게 된다.
문제는 각 상황에서 위 두가지 행동 중 어떤 행동을 해야할지 사람이 매번 결정해야 한다는 것이다. 시간도 오래 걸리고, rule-based로 풀기에도 쉽지 않은 문제다.
4-2. MaltParser
이때 Nivre는 머신러닝을 통해 위 과정을 예측하고자 했다. 현재 stack에서 위 두 동작 중 어느 것을 취해야 할 지 예측하고, 다시 shift하고 다시 예측하고... 이 과정을 반복하는 것이다. 실제로 Nivre는 머신러닝이 높은 정확도를 가지는 것을 보였다고 한다. 머신러닝을 사용할 경우 장점은 동적 프로그래밍이 2차 식 이상의 복잡도를 가질 때, 머신러닝은 선형적 복잡도를 가진다는 점이다. 모든 상황에서 거의 동일한 시간 복잡도를 가지고, 그 과정을 전체 단어에 대해 반복하면 그만이기 때문이다.
그렇다면 머신러닝의 입력값은 무엇이었을까? 단순무식할 수도 있지만, one hot encoding vector였다. 각 단어와 품사 태깅을 포함하여 one hot encoding하고 이를 입력값으로 사용했다. 그러면 100만에서 1000만 길이의 벡터가 필요했다고 하니 정말 엄청 sparse하게 되고, 엄청 비효율적일 수밖에 없다. (성능이 비교적 좋지 않기도 할 것이다.)
4-3. Evaluation of Dependency Parsing
위에서 머신러닝을 이용한 파싱이 꽤 높은 정확도를 보였다고 했다. 그렇다면 어떻게 성능을 측정할 수 있는 것일까? 사실 단순한데... 사람이 의존구조를 직접 작성하고, 이를 머신러닝이 작성한 것과 비교하는 것이다.
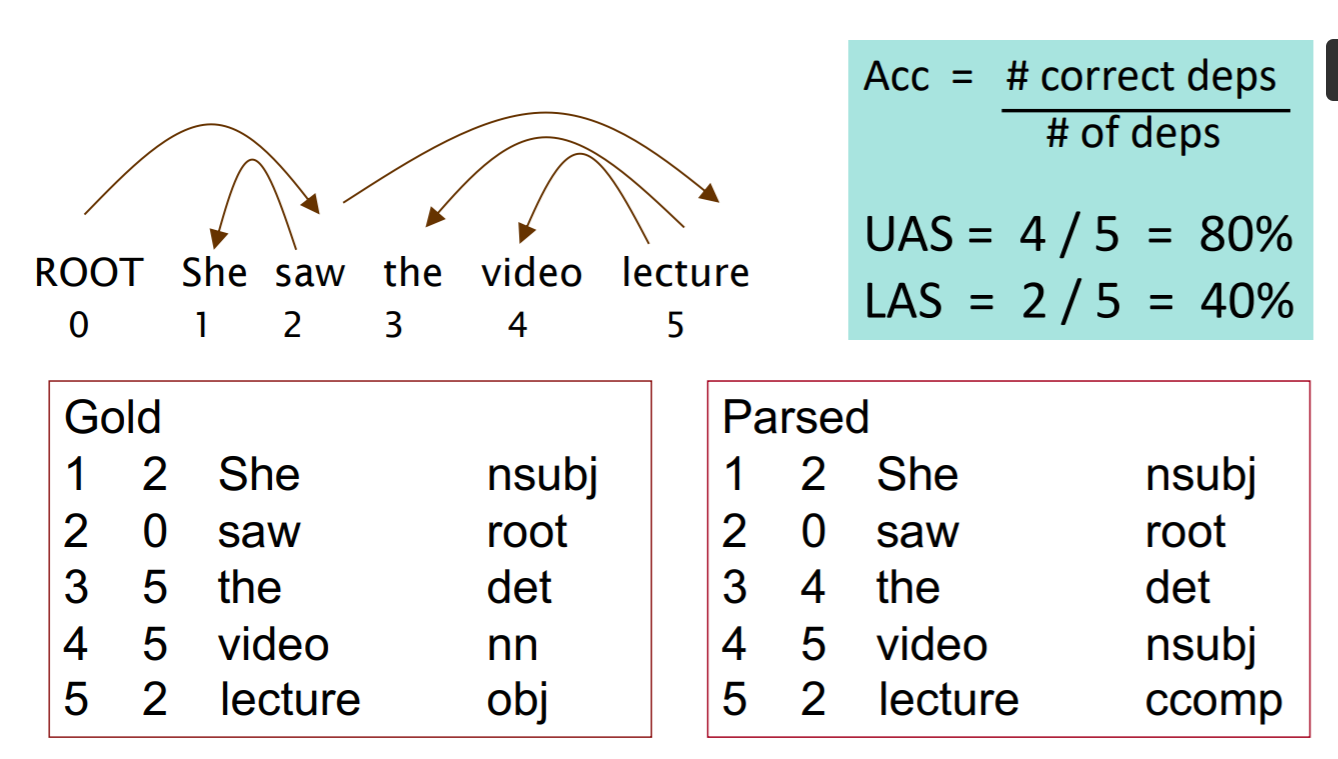
위에서 Gold는 사람이 만든 구조이다. 이때, 각 단어 왼쪽의 숫자는 각 단어가 의존하고 있는 단어의 인덱스이다. 그리고, Parsed는 모델이 예측한 인덱스이다. 이를 기준으로 정확도를 측정하면 80%가 나오게 된다.그리고, 각 품사를 얼마나 잘 예측했는지도 볼 수 있는데 이때는 20%의 성능이 나오게 된다.
4-4. Features
위에서 언급한 변수에 대해 조금 더 자세히 살펴보자. 위와 같이 one hot encoding의 형태로 벡터를 구성하게 되면 어떤 문제가 발생할까?
- 매우 sparse하다. 모든 단어와 품사의 조합이 하나의 feature가 되면서 무척 크고 sparse한 벡터를 입력값으로 사용한다.
- incomplete한 변수이다. configuration이 완벽하지 않다.
- computation power 낭비가 심하다. 계산의 95%가 변수들을 처리하는데 사용된다. 사실 3번 역시 1번과 연관이 있는 것 같다.
이를 해결하고자 NN을 사용한 시도가 있었는데, 교수님과 지도학생이 수행한 연구인 것 같다.
5. A neural dependency parser
굳이 성능 비교표를 첨부하지 않겠지만, 결론은 매우 좋았다! 이다. 기존의 parser들 보다 빠르고, 정확했다. 그리고 부가적으로 얻은 것들이 있었는데, 이것이 사실 핵심인 것 같다.
5-1. Distributed Representation
여기선 word embedding과 함께, POS(Part of Speech)와 Dependency Label도 임베딩하였다. 이를 통해 각 단어의 의미를 품사와 의존 구조에 따라 또 다르게 볼 수 있게 된 것이다. 이때 Dependecy Label은 모델이 이전에 예측한 의존 구조를 사용했다.
입력 벡터와 전체 모델을 시각화 하면 다음과 같다.
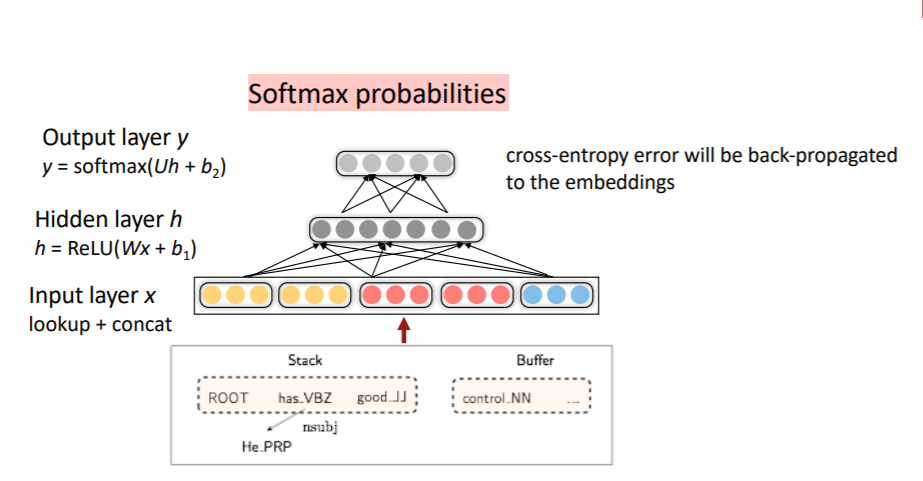
노란 색이 단어 벡터이고, 빨간색이 POS 벡터, 파란색이 Dependency Label이다. 현재 has만 he에 parsing된 상태이기 때문에, 하나만 벡터로 표현된 것을 볼 수 있다.
