1. Language Modeling
언어 모델링(번역이 맞는지 모르겠다)는 다음에 올 단어를 맞추는 모델을 구축하는 것을 말한다.
the students opened their ___
위와 같은 문장이 주어졌을 때, 사람은 당연히 books, laptops, exams, minds 등이 문맥 상 올 수 있다는 것을 안다. 하지만 이를 모델링하는 것은 쉬운 일이 아니다. 즉, 언어 모델링은 해당 언어에서 문맥에 맞는 단어로 무엇이 등장해야 하는지 맞추는 태스크라고 할 수 있다. 이를 좀 더 분명하게 수학적으로 작성하면 다음과 같다.
위에서 는 t 시점에 등장한 단어 x이다. 즉, t 시점까지 단어들이 주어졌을 때, t+1 시점의 단어 분포를 하는 것이다. 이때, x는 당연히 보캡, V 안에 있어야 한다. 즉, 우리가 예측할 단어도 모델이 전혀 모르는 단어가 아니라, 보캡의 단어 중 하나인 것이다. 이는 보캡 사이즈 만큼의 레이블이 있는 분류 태스크라고 볼 수 있다.
위 식이 조건부 확률이라는 점을 생각해보면, 다음과 같은 식 역시 유도할 수 있다.
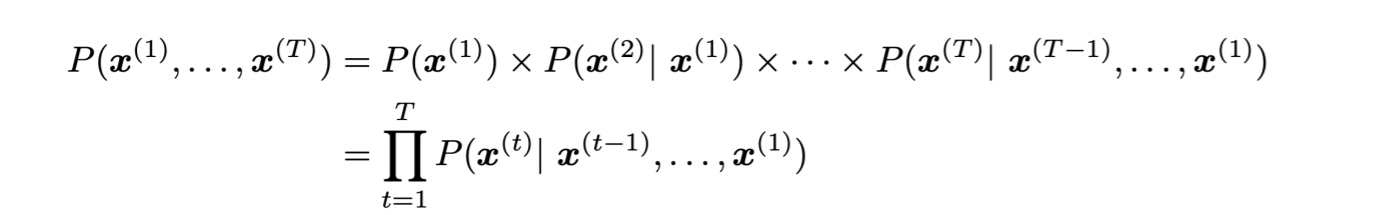
2. N-Gram Language Model
2-1. N-Gram
그렇다면 LM은 어떻게 구축할 수 있을까? 딥러닝이 본격적으로 주목받기 전에 사용되던 모델부터 살펴보도록 하자.
가장 먼저 살펴볼 모델은 n-gram 모델인데, 여기서 n-gram이란 n개의 연속된 단어를 의미한다. 좀 더 나아가서 n-gram 모델은, n 개의 단어가 관련이 있다고 본다. 즉, n번째 단어로 무엇이 등장할 지 계산하기 위해서는 이전 n-1개의 단어가 필요하다는 것이다.
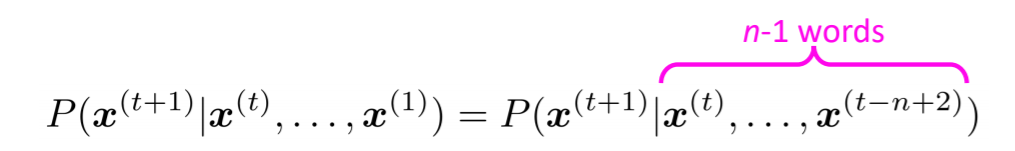
즉, 100번째 단어를 예측할 때, 첫번째 단어부터 고려할 필요가 없어진다. 단순히 94번째 단어부터 고려하면 되는 것이다(n=7).
하지만 그렇다고 해도 여전히 이상한 것은 있다. 문장을 입력받아서 어떻게 확률을 계산할 수 있을까? 가장 원시적이면서 아직도 많이 쓰이는 빈도수를 계산하면 된다. 이를 이용하면 위의 식은 다음과 같이 될 것이다.
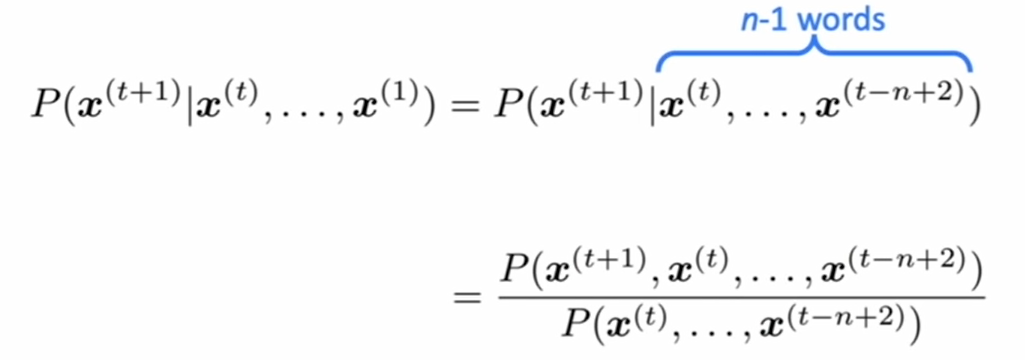

2-1-1. N-gram Problem
하지만 여기엔 문제가 있다. n-gram 안에 문맥에 핵심적인 정보가 없을 경우, 제대로 예측되지 않는다.
as the proctor started the clock, the students opened their ___
위와 같은 문장에서 3-gram을 할 경우 students, opened, their를 이용해 다음 단어를 예측하게 된다. 하지만 여기서 중요한 단어는 proctor, clock, students 등이다. 즉, n이 너무 작아서 제대로 예측할 수 없게 되는 것이다.
2-1-2. Sparcity problem
그렇다고 n을 무작정 키울 수는 없다. 희소성 문제가 발생하기 때문이다. n-gram의 식은 분자가 각 단어 조합이 등장한 빈도수이고, 분모가 n-1까지의 단어 조합이 등장한 빈도수이다. 하지만, n이 커지게 되면, 대부분의 단어 조합은 한번도 등장한 적이 없어지고, 이로인해 분자 부분에서 대부분의 단어는 0이 된다. 하지만, train 데이터에 한번도 등장하지 않은 단어 조합이, test에는 발생할 수 있다. 위 예시에서 the students opened their closet도 가능하지 않은가? 이를 보완하기 위해 beta를 추가하여 확률을 보정해주는 smoothing을 사용하기도 한다. (피샛하면서 자주 사용했던 그 smoothing이 맞다.)
더 심각한 문제도 있다. 만약 분모 부분이 0이라면, 애초에 확률을 계산할 수 없다. 분자가 0이면 그냥 그 단어의 등장확률이 0이라고 생각하면 되지만, 이 경우엔 그냥 분포가 아예 나오지 않는 것이다. 이를 해결하는 방법으론, 해당 조합의 첫번째 단어를 제외하고 n-1 gram이라 생각하고 확률을 계산하는 것이다. 사실 마음에 드는 방법론은 아니다. 더욱 정보를 줄여서 예측하는 것인데, 잘 될리가 없을 것 같다.
제일 문제는,,, 문맥을 더 반영하자고 n을 늘리는 순간 단어 조합은 더 희귀해지고 sparcity problem은 더 심각해진다는 것이다.
2-1-3. Storage problem
또다른 문제점으론 모델의 크기에 있다. n-gram 모델은 모든 n개의 단어 조합의 빈도수를 계산하고 저장해야 한다. 당연히 n이 커질수록 모델의 크기는 커지는데, LM이 상당히 큰 데이터를 이용하고, n 역시 어느 수준 이상으로 커야 작동한다는 점은, 모델이 저장해야 하는 조합의 수가 비대하게 만든다.
today the price of gold per ton , while production of shoe
lasts and shoe industry , the bank intervened just after it
considered and rejected an imf demand to rebuild depleted
european stocks , sept 30 end primary 76 cts a share .
위 문장은 3-gram LM을 통해 만들어진 문장이다. 얼핏 보기엔 제법 문장의 구성을 갖추고 있다. 하지만 자세히 살펴보면 전체 맥락이 없다. 금과 신발 산업, 은행과 imf 이야기가 나오지만, 전체 문장이 전하고자 하는 맥락은 없다. 이는 당연히 3-gram 이기 때문이다. 앞의 두 단어를 이용해 다음 단어를 예측하다보니, 이전의 문맥을 제대로 파악할 수 없다.
그렇다고 n을 키우자니, 모델은 커지고, 오히려 확률이 제대로 계산되지 않아 적절한 단어를 예측하지 못할 여지가 있다. 즉, 이 모델의 한계는 명확한 것이다.
3. Neural Language Model
앞서 LM의 입력값은 연속된 단어이고, 예측값은 다음에 나올 단어인 점이라고 했다. 이를 이용해 인공신경망 LM을 만들 수 있지 않을까? 이전 강의에서 NER 모델을 만든 과정을 조금 바꾸면 된다.
3-1. Fixed-window Neural Language Model
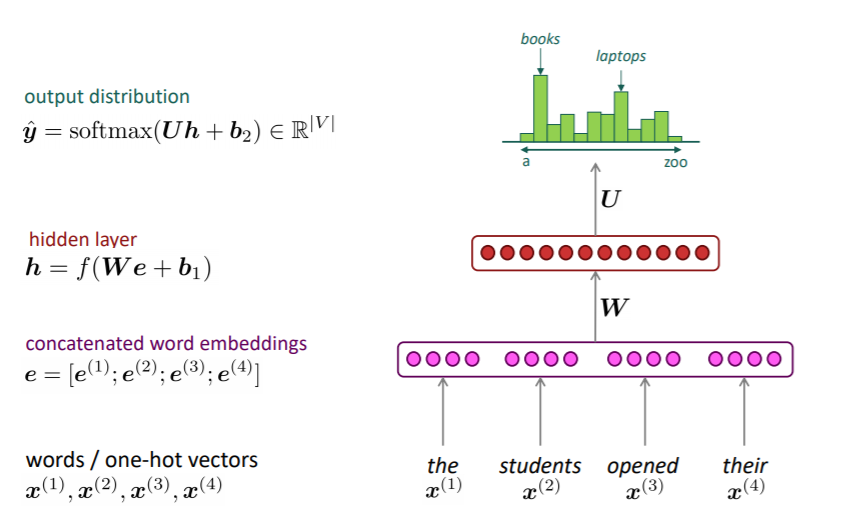
전체 모델의 구조는 다음과 같다.
1. n에 해당하는 단어들의 one hot vector를 입력값으로 받는다.
2. 이를 임베딩 행렬에 look up하여 해당 단어들의 임베딩 벡터를 얻는다.
3. 임베딩 벡터들을 순서대로 concat한다.
4. 이를 hidden layer에 통과시킨다.
5. 최종적으로 softmax 등의 함수를 이용하여, 보캡의 각 단어에 대한 확률값을 얻는다.
3-1-1. No Sparcity problem
이 모델이 n-gram 모델에 비해 가지는 첫번째 이점은 더이상 sparcity에 대해 고민할 필요가 없다는 것이다. 단어의 임베딩 벡터를 이용하기 때문에 dense한 입력값을 가지게 되고, 각 단어의 조합이 없더라도 임베딩 벡터는 가지게 되므로 계산에 문제가 없다.
3-1-2. No need to store all observed n-grams
비슷한 이점이다. 더이상 모든 조합을 저장할 필요가 없다. 임베딩 벡터는 각 단어마다 개별적으로 존재하기 때문에, 조합이 있었던, 없었던, 조합이 적던, 많던간에 관계없이 모델은 작동하게 된다.
3-1-3. Window is small
윈도우가 작다. 밑에서도 계속 서술하겠지만, 모델의 윈도우는 너무 커질 수 없기 때문에 작을 수 밖에 없다.
3-1-4. Weight Matrix W is too big
FFNN 모델을 기반으로 하기 때문에, W가 커질수록 연산량은 기하급수적으로 커진다. 하지만 n을 키울수록, 즉 윈도우를 키울수록 W는 덩달아 커져야 하고, 이는 모델이 무거워지게 한다. 이로인해 N을 충분히 키울 수 없다.
3-1-5. No symmetry in the input context
같은 단어가 n-gram 내에서 다른 위치에 있을 경우, 다른 weight와 곱해지게 된다. 그래프로 보면 input 노드가 다르기 때문이고, 행렬 개념에선 다른 weight column과 곱해지기 때문이다. i eat a apple이라는 문장에서 i eat 일때와 eat a 일떄의 eat이라는 단어의 의미는 달라지지 않는다. 하지만 모델 내에선 다르게 처리되버리는 것이다. 사실 word vector들을 두번째 차원으로 concat해서 2차원 행렬로 만든 이후 cnn을 이용하면 해결되지 않을까 싶다. cnn은 ffnn보다 가볍기 때문에 더욱 n을 키울 수 있고, 위치에 관계없이 똑같은 filter가 통과하기 때문이다. 하지만 강의에선 이 문제들이 결국 fixed window에서 온다고 이야기하고 있다. 아마 이 부분이 rnn의 등장배경이 될 것이다.
4. RNN
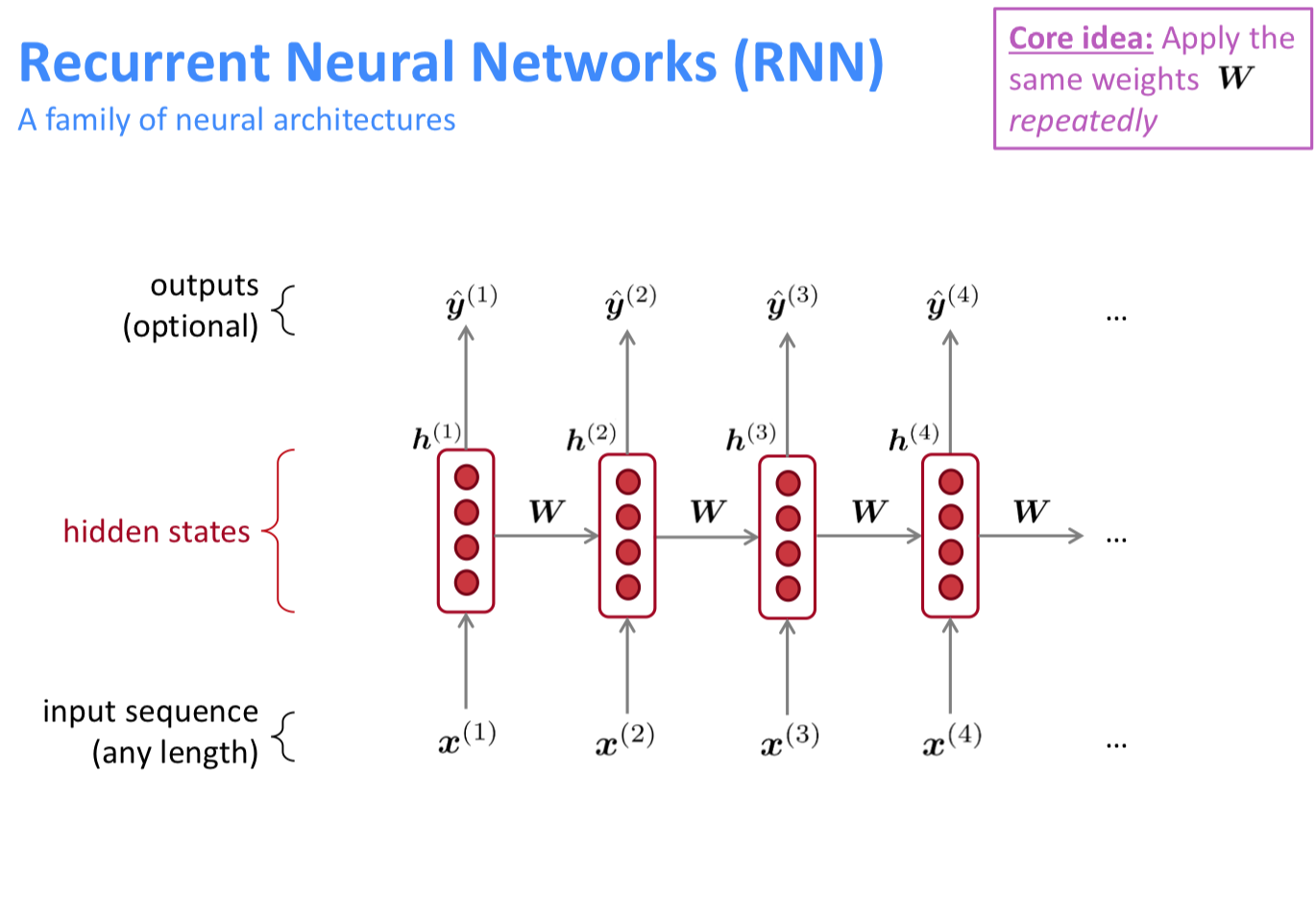
그래서 등장한 RNN이다. RNN의 목적은 결국, input의 time step에 구애받지 않고 모델링하자이다. 이론적으로 사실 input의 길이가 얼마이든 상관없이 inference가 가능하니 맞는 말인 것 같다. 이를 가능케 하는 것은 모든 시점의 W 행렬이 동일한 행렬이기 때문이다. 100번째 타임 스텝에 사용되는 W와 첫번째 시점에 사용되는 W는 동일한 값이다.
특히 태스크에 따라 출력값의 개수를 조절할 수 있다. 우리는 현재 LM을 하고 있기 때문에 주어진 단어들 이후에 나타날 단어 하나만 예측하면 된다. 그래서 마지막 시점의 hidden state만 뽑아서 사용할 것이다.
4-1. Advantages
- 입력값의 길이가 유동적일 수 있다.
- (이론적으론) 이전 시점의 정보들이 이번 시점의 정보를 처리하는데 이용된다.
- input의 길이가 길어진다고 모델의 크기가 커지지는 않는다.
- 동일 토큰이 다른 시점에 들어오더라도 동일하게 처리된다. 왜냐하면 모든 시점의 W는 동일하기 때문이다.
4-2. Disadvantages
- 분산처리가 불가능하다. 이전 시점의 정보를 처리해야 이번 시점을 처리할 수 있기 때문이다.
- 시점이 길어지면 오래된 시점의 정보를 이번 시점에 활용할 수가 없다. 이 부분에 대해선 많은 이야기가 나오고 이후 모델들에 대한 이야기이기 때문에 나중에 더 이야기가 나온다.
4-3. Training RNN
4-3-1. Grandient Descent Method
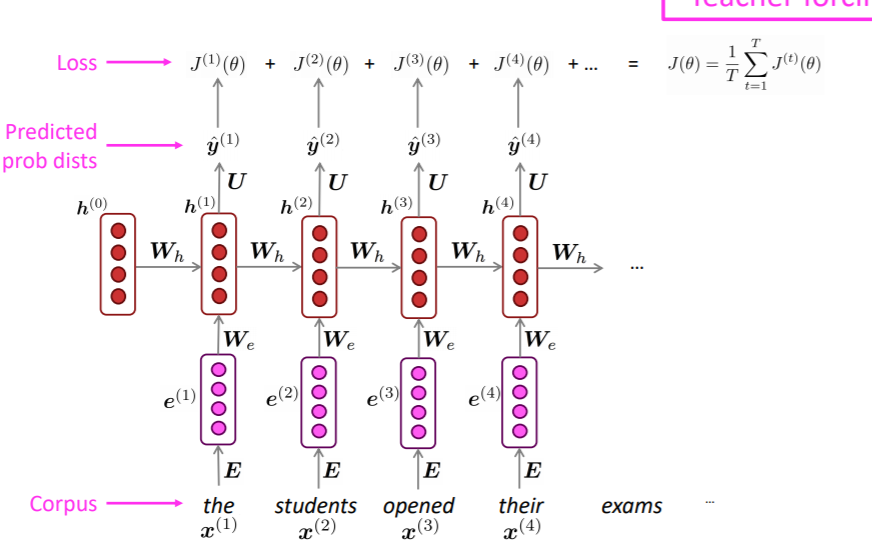
- 준비물 : big corpus
- Feed forward into RNN-LM : 각 토큰을 예측하도록 훈련시킨다. 즉, 하나의 input sentence가 있다면, 이전에 들어온 토큰들로 매 시점마다 다음 토큰을 예측하게 하는 것이다.
- 매 시점 Cross Entropy를 손실함수로 계산한다.
- 2에서 계산한 손실함수의 값을 평균내어 최종 손실함수로 사용한다.
하지만 이런 식으로 모델을 학습시키면, 계산량이 엄청나다. 매 시점마다 계산하려다 보니 정말 어마어마해질 것이다. 이게 우리가 일반적으로 하는 학습 방법하고 다른 것은, 이 예시는 단순 GD라는 점이다. 즉, 모든 corpus 내 단어를 한번에 처리해버린다. 즉, 모든 corpus 내 단어마다 순전파를 시키고, 손실함수를 계산하고, 이를 업데이트해야 1 epoch이 끝난다. 말도 안되게 계산량이 클 수 밖에 없을 것이다.
(참고로 이와 같은 학습 방법을 teaching force라고 하며 번역 태스크에서 사용된다)
4-3-2. Stochastic Gradient Descent.
SGD 방식은 다음과 같다.
0. 준비물 : big corpus
1. corpus를 문장 단위 혹은 단락 단위로 나눈다(각 문서가 하나의 batch가 된다.).
2. 배치 별로 각 타임스텝 별 손실함수를 계산한다.
3. 배치 별로 역전파를 수행한다.
하지만 여기서 문제가 있다. RNN은 이전에 배운 FFNN과 다르게 W가 시점마다 공유된다. 이를 어떻게 업데이트해야 할까?
4-4. Backpropagation Through Time.
그래서 BPTT가 등장한다. 처음 배울 때는 잘 이해가 가지 않았는데, 역시 이해가 안가면 반복해서 봐야한다...
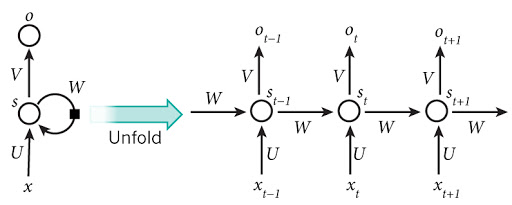
위와 같이 RNN 모듈을 unfold해서 생각해보자. 각 타임스테마다 손실함수가 계산 될 것이다.
그리고 t 시점의 손실함수를 역전파 시켜보자.
우선 hidden state에서 최종 예측값으로 내보내는 weight들은 이전의 미분 계산과 다르지 않다.
하지만 W를 업데이트 시키려면 문제가 발생한다. 각 시점마다 역전파 되는 값이 달라지게 되는데, 이를 동일한 W에 어떻게 해야할까?
모든 W를 다른 행렬이라 생각하고 식을 써보면 다음과 같다.
하지만 모두 같은 손실함수에서 나온 미분을 바탕으로 똑같은 행렬을 미분해야 한다.
이때 다변수 함수 미분을 이용해보자.
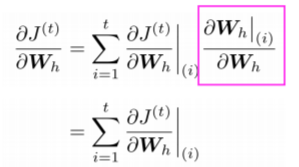
다변수 함수 미분을 이용할 경우, 각 시점마다의 W의 t시점의 손실함수에 대한 미분은 위의 식과 같아진다. 여기서 t 시점에서 각 시점으로 그래디언트가 흐르기 위해 체인룰이 사용되는데, 는 자연스레 1이 되기 때문에, 각 시점의 W에 대한 t 시점의 손실함수에 대한 체인룰 미분을 더해주기만 하면 된다.
4-5. Generation of RNN
그렇다면 RNN이 만든 문장은 어떤 모습일까?

위 문장은 해리포터를 학습한 RNN이 만들어낸 문장이다. 꽤 해리포터 책 속에 있을 것 같은 구절을 만들어낸 것을 알 수 있다. 이전의 n-gram 모델보다 좀 더 말이 될 것 같은 모습이다. 하지만 완벽하게 말이 되는 문장을 만들어내지는 못했다.
이유는 rnn이 실제로는 과거 정보를 긴 시간동안 담고 있지 못하기 때문이다. 시그모이드를 연속적으로 사용하여 초기 시점의 역전파가 제대로 이루어지지 않기도 하다. 이 부분은 해당 강의엔 없는 것으로 봐서 아마 다음 강의에서 다룰 것 같다.
5. Perplexity
LM의 성능을 하지만 얼마나 사람같이 문장을 만들어내는지로 평가할 순 없다. 그래서 perplexity라는 개념을 이용한다.
6. Why Language Modeling?
그렇다면 왜 언어 모델링을 하는 것일까? 분류 모델을 만들어도 되고, 다른 여타 태스크를 이용할 수도 있을텐데 말이다.
1. Benchmark Task
언어 모델링은 다음에 올 그럴듯한 단어를 예측하는 태스크이기 때문이다. 이 태스크는 매우 어렵고, 해당 언어에 대한 상당한 이해가 바탕이 되어야 수행이 가능한 태스크이다. 이로인해 언어 모델링은 benchmark task로 사용된다.
- Overall Task
언어 모델링은 speech recognition, grammar correction, summarization 등 다양한 태스크에서 사용될 수 있기 때문이다.
7. Various Tasks
강의 후반엔 다양한 태스크에 대한 이야기가 나왔다. 태스크가 어떠한 것인지 소개하는 수준이라 따로 담지 않지만, sentence encoding과 관련하여 재밌는 이야기가 있었다.
감성분석 태스크에서 보통 마지막 시점의 hidden state를 이용하여 감성분석을 하게 된다. 그리고 이를 sentence encoding과 연결지어 생각해보면, 마지막 hidden state를 해당 문장을 encoding한 결과라고 생각한다고 볼 수 있을 것이다. 즉, 해당 문장이 긍정인지 부정인지 판단하기 위해 필요한 정보가 마지막 hidden state에 담겨 있다고 보는 것이다.
하지만 좀 더 나은 방법이 있다. 매 시점의 hidden state를 뽑고, 이 hidden state들의 element wise mean이나 max를 encoding 결과로 사용하는 것이다. 이를 통해 해당 문장을 대표하는 행렬이나 벡터를 얻을 수 잇게 된다.
이를 좀더 생각해보면 RNN은 인코더로 사용할 수 있다는 결론이 나온다. 인코딩이란 정보를 압축하여 일정한 벡터 등의 형태로 나타내는 것인데, rnn은 연속된 문장을 압축할 수 있으니 충분한 인코더로 사용이 가능하다. 그리고 이 아이디어가 QA나 번역 태스크로 이어지는 것 같다.
