최근 투빅스 컨퍼런스에서 "비영어권 사용자를 위한 글을 정갈하게 다듬어주기"(내맘대로붙여본이름, 정식이름은아직정해지지않았다.) 프로젝트가 시작되었다. 전체적인 플로우는 아래 그림과 같이 이루어질텐데, 나는 그 중에서도 unpaired data를 이용해서 non-native speaker의 글을 native speaker의 글로 바꿔주는 모델을 찾아보는 역할을 맞았다. 찾다보니 익숙한 트랜스포머 계열 모델을 활용한 논문이 있었고, 성능도 나쁘지 않은 것 같아 이 논문으로 진행하게 되었다. 전반적인 내용이 unpaired data를 이용한 NLG와 맞물려 있는 것 같아서 기록으로 남겨보고자 한다.
0. Abstract
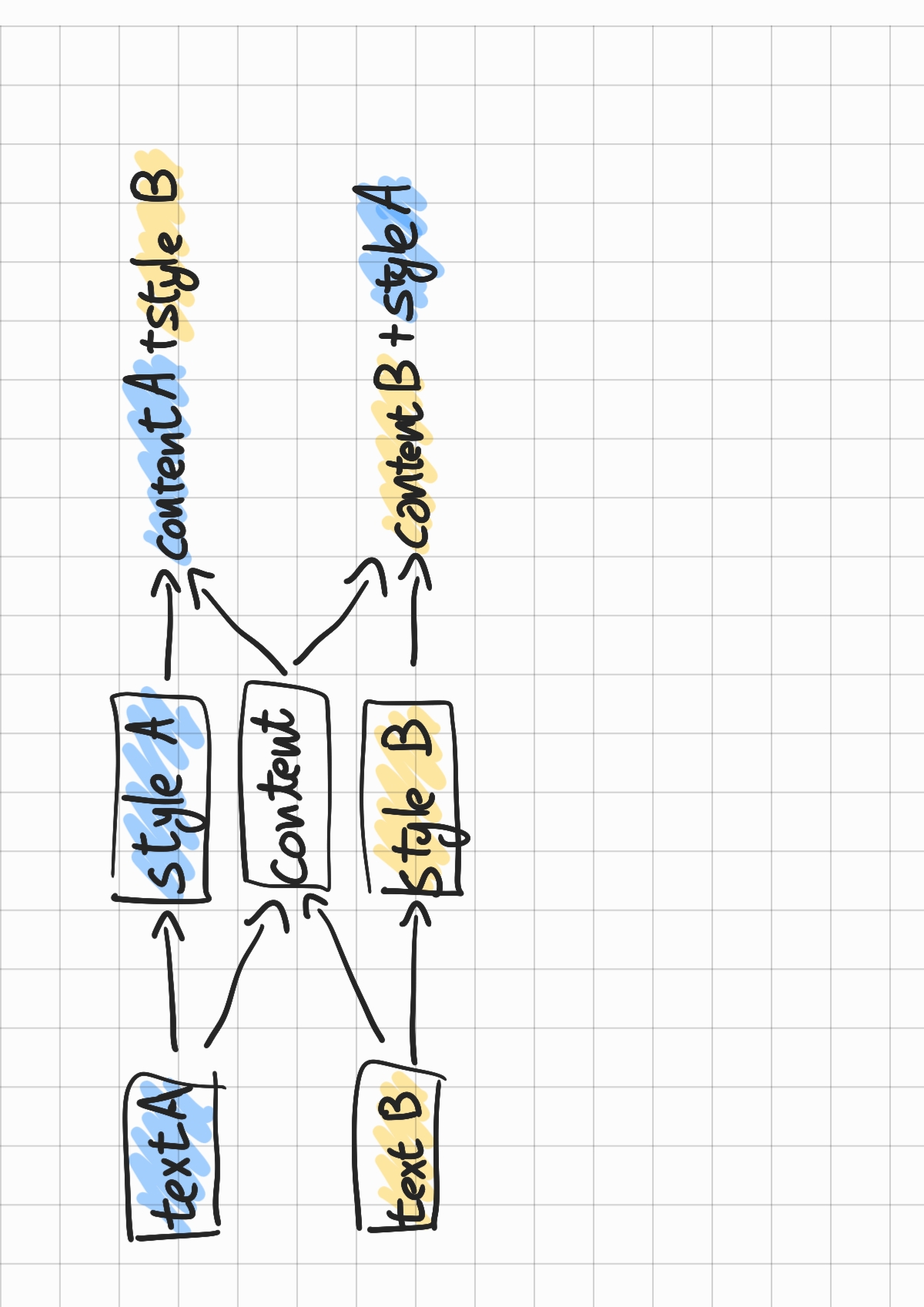
시작하기에 앞서 텍스트 분야에서 style transfer에 대해 조금 이야기를 할 필요가 있을 것 같다. 텍스트 분야에서 style transfer란 아래 그림과 같이 텍스트를 스타일과 콘텐츠로 분리하고 본래의 스타일과 다른 스타일로 해당 콘텐츠는 유지한 채 텍스트를 생성하는 태스크이다.
여기서 스타일은 태스크마다 다르지만 보통 긍, 부정 혹은 공식, 비공식적 언어 스타일을 의미하고, 콘텐츠는 스타일과 독립적인 텍스트의 내용을 의미한다.
요새 넷플릭스에서 코민스키 메소드라는 드라마를 보는데 진짜 웃기더라 ㅋㅋㅋㅋ
긍부정 style transfer라면 위와 같은 텍스트에서 스타일은 "긍정"이 되고, 콘텐츠는 넷플릭스에서 코민스키 메소드라는 드라마를 봤다는 내용이 될 것이다(이렇게 문자로 구별할 수 있는 것은 아니다.). 위 문장에서 스타일과 콘텐츠는 각각 오토인코더 등을 통해 벡터 표현된다. 그럼 콘텐츠 벡터와 다른 텍스트에서 구한 부정 스타일 벡터를 디코더에 통과시키면 다음과 같은 텍스트가 만들어진다.
요새 넷플릭스에서 코민스키 메소드라는 드라마를 보는데, 너무 노잼이야...
몇가지 논문을 보니, 단어를 1대1로 치환하는 방법도 있고, 문장을 통채로 새로 생성하는 방법도 있다. 해당 논문은 문장을 통채로 새로 생성하는 방법을 취하고 있다.
하지만 문장에서 콘텐츠와 스타일 두 벡터를 뽑아내는 과정이 쉽지 않고, RNN류의 모델들은 장기의존성 문제로 인해 제대로 태스크를 수행하는데 어려움을 겪고 있다. 이 논문에선 그래서 트랜스포머 기반의 모델(정확히는 BERT-LARGE)을 이용하여 이 문제를 해결하고 있다.
1. Introduction
2017년 이후부터 style tranfer 문제를 NN을 통해 해결하고자 하는 움직임이 있었다고 한다. 보통 인코더-디코더 구조를 취하게 되는데, 인코더는 텍스트를 스타일과 독립적인 벡터(style independent latent representation)를 생성하게 된다. 그리고 디코더는 동일한 콘텐츠 벡터를 스타일 변수와 함께 이용하여 다른 스타일로 생성하게 된다. 이러한 방법론들은 텍스트를 별개의 스타일과 콘텐츠로 잠재 공간에 맵핑하느냐가 중요하다. 결국 콘텐츠에서 최대한 스타일과 관련된 정보를 제거해야 다른 스타일로 쉽게 이전될 수 있기 때문이다.
하지만 실제 세계에선 paired data가 드물어서 adversarial loss를 사용하게 되는데, 이는 스타일 정보를 잠재 공간에 표현하는데 어려움을 겪는다. 물론 이렇게 스타일과 컨텐츠로 분리하는 것은 훨씬 해석력을 높이지만, 해당 저자는 다음과 같은 문제점들을 지적하고 있다.
- 텍스트에서 스타일을 분리해내는 것은 쉽지 않다. 또한, 모델이 얼마나 잘 분리해내는지 판단하는 것 역시 어렵다. 기존의 논문들에서 콘텐츠 벡터만으로 스타일 정보를 복원해낼 수 있었다고 한다.
- 콘텐츠와 스타일의 분리가 꼭 필요하지 않다. 좋은 디코더는 기존의 스타일 가지고 있는 텍스트 벡터에 다른 스타일을 "덮어씌울" 수 있다고 한다.
- 벡터의 차원은 한정되어 있는데, 이 안에 텍스트의 의미적 정보(sementic information)을 충분히 담아내기 어렵다. 특히 긴 문장의 경우에 더 어려워진다. NMT에서도 잠재 벡터에서 다시 원문장을 복원하는 것이 힘들다고 한다.
- 텍스트를 스타일과 콘텐츠로 분리하는 과정에서 텍스트를 고정된 크기의 벡터 사이즈로 인코딩하는데, 사실 이렇게 되면 어텐션 매커니즘이 제대로 정보를 보존하기 힘들다고 한다.
- RNN류 모델들은 장기의존성 문제로 긴 텍스트에서 정보를 제대로 보존하지도 못한다.
이 논문에서는 이 대신에 트랜스포머 모델을 사용하는데, 그 이유에 대해 다음과 같이 설명하고 있다.
트랜스포머는 인코더에서도 self-attention을 통해 어텐션 메커니즘을 구현하고 인코더와 디코더 간에도 어텐션 메커니즘이 구현되어있어서, 고정된 벡터로 모든 정보를 담는 RNN에 비해 정보를 잘 보존한 채로 문장을 생성할 수 있다.
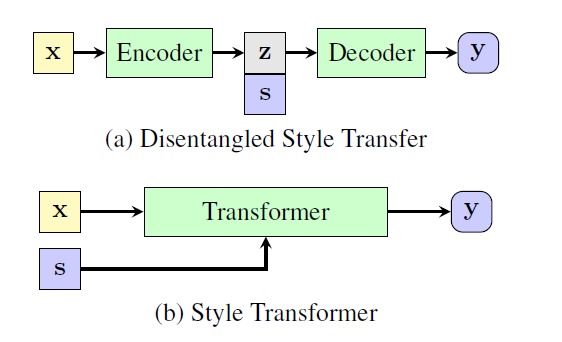
기존의 RNN류 모델들은 위와 같이 인코더를 통해 latent representation을 만들고, 거기에 style variables를 추가하여 디코더에 통과시켰지만, 해당 논문에서는 기존의 텍스트와 style variables를 그냥 트랜스포머에 집어넣고 있다.
Contributions
- 텍스트에서 벡터를 뽑아내지 않기 때문에, 어텐션 메커니즘을 적용하여 성능을 올릴 수 있었다.
- 트랜스포머 모델을 style transfer task에 처음 적용한 논문이다.
- 두가지 데이터셋에 대해 좋은 성능을 보이고 있고, 콘텐츠를 보존하는 부분에서는 최고의 성능을 보이고 있다.
2. Related Work
이전까지의 연구를 두 종류로 정리하고 있다.
- 인코더-디코더 구조 혹은 오토 인코더 구조를 통해 latent representation을 이용하는 모델
이 방법의 경우 모델의 해석가능성을 높이고, 직접 조작할 수 있다는 장점이 있지만, 고정된 latent representation의 벡터 사이즈로 인해 텍스트의 정보를 제대로 보존하지 못한다. - 번역 태스크 혹은 cycled reinforcement 구조를 이용하는 모델. 이 경우 unpaired data를 이용할 수 있지만, 이 역시 어텐션 메ㅌ커니즘을 제대로 이용하지 못해 장기의존성 문제를 해결하지 못했다. 특히 NLG에서 어텐션 메커니즘이 장기의존성을 해결하고 정보를 보존하는 장점이 있다는 것을 고려하면 아쉬운 부분이다.
그래서 이 논문에선 어텐션 메커니즘을 활용한 트랜스포머 모델을 통해 latent represenation을 사용할 필요를 제거했다.
3. Style Transformer
3.1 Problem Formalization
특징을 공유하는 문장의 모임을 라고 하자. 그리고 이 공통된 특징을 우리는 이제 스타일이라고 부를 것이다. 만약 K개의 스타일이 있다고 가정한다면 데이터셋은 로 구성된다.
그렇다면 다음과 같은 데이터셋과 스타일 노테이션으로 정리할 수 있다.
목표는 다음과 같다.
주어진 텍스트 데이터 와 원하는 스타일 을 이용해 새로운 텍스트 를 생성하는 것. 이때 은 스타일과 기존의 의 정보들은 최대한 보존해야 한다.
3.2 Model Overview
위의 목표에서 모델을 삽입하면 다음과 같다.
즉, 본래의 텍스트 x와 원하는 스타일 변수 를 입력으로 하여 을 출력하도록 하는 함수 를 구하고자 하는 것이다. 이때 함수를 일종의 맵핑으로 볼 수 있다.
하지만 문제가 있다.
parallel data가 없다.
이를 본 논문에서는 판별자(discriminator)와 세가지 손실 함수를 이용해 해결한다.
3.3 Style Trnasformer Network
기본적으로 트랜스포머는 다음과 같은 입력값과 내부 모델을 취하고 있다.
input :
Transformer Enc =
sequence of continous representation =
Transformer Dec =
output sentence =
여기서 를 생성하는 방식은 기존의 seq2seq처럼 autoregressive한 조건부 확률이다.
각각의 시점마다 최종 토큰을 선택하는 방식은 소프트맥스 함수를 이용한다.
여기서 는 디코더 단을 통과한 벡터이다.
그런데 style transfer는 스타일을 변환하기 위해 style control variable인 s가 필요하다. 이를 이용해 식을 약간 변형하면 다음과 같다.
3.4 Discriminator Network
이 논문은 parallel data를 사용하지 않기 때문에 를 지도학습을 통해 학습시킬 수 없다. 대신 우리는 에 대해선 학습시킬 수 있다. 와 s는 동일한 데이터셋인 에서 나왔기 때문이다. 이는 모델에게 를 이용해 다시 를 생성하도록 하는 reconstruction을 통해 가능하다.
만약 다른 스타일을 생성하도록 모델을 학습시키고 싶다면 다음과 같은 두 과정을 통해 가능하다. 다시한번 말하지만 논문에서 만들고 싶은 모델은 콘텐츠는 유지하되 스타일은 바꾸는 것이다. 이 논문에선 두가지 판별자를 정의하고 각각 실험하고 있다. 이를 유념해서 보자.
- preservation of content
스타일을 변경하여 생성된 문장 에서 다시 본래의 문장 를 생성하도록 학습시킨다. 즉,
이렇게 다시 x를 생성하도록 한다.
- style controlling
판별자(discriminator)를 학습시켜, 모델이 생성된 문장에서 스타일을 잘 변형할 수 있도록 한다.
Conditional Discriminator
Conditional GANs와 비슷하게 문장과 스타일이 일치하는지 판별하는 판별자를 만들게 된다. 즉, 아래와 같은 입력값을 가지는 함수가 된다.
판별자 학습시에는 다음과 같은 경우에 positive 판별을 하게 된다.
- 본래의 문장 와 스타일 일 경우 :
- reconstruct한 문장 와 스타일 일 경우 :
판별자 학습시에는 다음과 같은 경우에 negative 판별을 내리게 된다.
- 본래의 문장 를 스타일 변형 시킨 문장 과 본래의 스타일 일 경우 :
즉, 판별자는 입력된 문장과 스타일이 일치하는지 판별하게 된다.
생성 모델 학습시에는 판별자가 를 positive로 판단하도록 학습하게 된다.
Multi-Class Discriminator
만약 학습하고자 하는 스타일이 다수라면 어떻게 판별자를 구성해야 할까? 이때는 판별자의 입력값으로 문장 만 들어가게 된다. 이때 판별자는 다중 분류 태스크를 수행하게 되며 클래스 개수는 K+1개를 가지게 된다. K개는 각각의 스타일이고, 마지막 하나는 즉, 생성 모델에 의해 생성된 문장이다.
다시 말해 multi-class discriminator는 입력된 문장이 K개의 스타일 중 하나인지 혹은 임의로 생성된 문장인지 판별하게 된다.
판별자 학습 시에는 다음과 같은 같이 레이블링한 데이터를 사용하게 된다.
- 기존의 문장 : 해당 스타일로 레이블
- reconstruct된 문장 : 로 레이블
- 스타일 변형한 문장 : 마지막 클래스로 레이블
생성 모델 학습시에는 스타일 변형한 문장 가 로 레이블되도록 학습하게 한다.
3.5 Learning Algorithm
unparallel data를 이용하다 보니 하나의 손실함수로 학습이 이뤄지지 않는다. 단계별로 살펴보면 다음과 같다.
3.5.1 Discriminator Learning
결국 판별자를 활용한 학습은 판별자에게 본래 있던 데이터인지 생성된 데이터인지 잘 판별하도록 만들고자 한다. 이러한 판별자를 속일만큼 그럴듯하게 데이터를 생성해야 하는 것이다. 좋은 생성 모델을 위해선 그래서 좋은 판별자가 필요하다.
그래서 각 판별자의 손실함수는 다음과 같이 정의될 수 있을 것이다.
conditional discriminator
multi-class discriminator
두 판별자는 다른 데이터셋을 학습하기 때문에, 학습 과정이 조금 달라지게 된다. 전체적인 판별자 학습 알고리즘은 다음과 같다.

3.5.2 Style Transformer Learning
생성 모델의 학습엔 생성 모델 본인이 생성한 문장과 판별자가 사용된다. 총 3가지 손실함수를 이용해 학습이 진행되게 된다.
Self Reconstruction
self reconstruction은 본래의 문장과 본래의 스타일로 문장을 생성했을 때, 본래의 문장이 나오도록 학습한다. 식은 다음과 같이 negative log liklihood를 이용한다.
Cycle Reconstruction
생성 모델이 입력 문장 의 정보를 보전할 수 있도록 cycle reconstruction이 사용된다. 이는 를 다른 스타일의 문장 으로 변형한 후 다시 본래의 스타일로 돌렸을 때, 본래의 문장과 유사하도록 학습시키는 것이다. 식은 다음과 같다.
self reconstruction과 cycle reconstruction은 생성 모델 자체에서 손실함수를 구한다.
Style Controlling
위의 두 식만 이용해 모델을 학습하게 되면, 생성모델은 입력 문장과 동일한 문장을 출력하도록 학습되게 된다. 하지만 우리가 원하는 것은 생성 모델이 스타일을 변형할 수 있어야 한다. 그래서 style controlling loss를 사용한다.
이 손실함수에선 다른 스타일로 변형된 문장 를 판별자에 넣었을 때, 변형에 사용한 스타일 로 판별하도록 한다. 식은 다음과 같다.
conditional discriminator
multi-class discriminator
이렇게 손실함수 정의가 모두 끝났다. 전체적인 손실함수 계산 알고리즘은 다음과 같다.

3.5.3 Summarization
GAN류 모델의 학습과정처럼 STyle Transformer의 학습 역시 판별자와 생성자가 번갈아가면서 학습하게 된다. 구체적으로 우선 판별자 번 먼저 파라미터를 업데이트하고, 다음 번 생성자가 업데이트하는 식으로 이루어진다. 전체적인 알고리즘은 다음과 같다.

하지만 여기서 문제가 생기는데, 이미지와 달리 텍스트는 결국 이산데이터이다. 즉, 이산확률분포를 가지기 때문에, 직접 생성한 데이터에서 역전파 시킬 수 없다. 그래서 보통은 강화학습을 이용하거나 생성된 문장의 소프트맥스를 Gumbel-Softmax로 변형하여 역전파 시키게 된다.
하지만 논문 저자에 따르면 두 방법 모두 잘 수렴하지 못했다고 한다. 그래서 논문에서는 생성모델에서 각 시점마다 생성하는 소프트맥스 분포를 sotf하게 생성된 문장이라고 여기고 이를 다시 다음 시점의 입력값으로 사용했습니다.
이러한 디코딩 방식을 continuous decoing이라고 했습니다. 다음 시점에 분포가 입력될때는, 이 분포와 각 토큰을 가중합 평균(weighted average) 임베딩 벡터로 사용하였습니다.
4. Experiment
4.1 Datasets
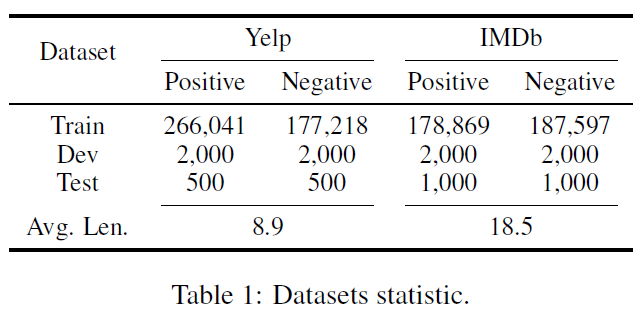
논문에서는 긍부정 데이터셋으로 유명한 Yelp Review Dataset과 IMDB Movie Review Dataset을 이용했습니다. 이때 기존에 있는 데이터셋을 그냥 가져오기 보다 몇가지 작업을 통해 데이터의 극성(polarity)을 높였습니다.
- Bert를 파인튜닝하여 정확도 0.95짜리 긍부정 분류기 모델을 만들었습니다.
- 각각의 리뷰를 문장 단위로 나누었습니다.
- 각 문장을 1의 Bert에 통과시켜 confidence가 0.9를 넘지 못하는 경우 버렸습니다.
- 마지막으로 흔치않은 단어가 등장하는 문장은 삭제하였습니다.
그 결과 다음과 같은 최종 학습 데이터셋이 만들어졌습니다.
4.2 Evaluation
CS224N 강의에서 봤듯이, 생성 모델의 성능 평가는 매우 어렵습니다. 그래서 평가하고자 하는 요소를 세분화하고 각각의 요소에 집중한 지표들을 사용합니다.
이 논문에선 모델이 생성한 문장이 자연스럽고(fluent), 콘텐츠가 완벽히 담겨 있으며, 원하는 스타일로 이루어져 있어야 한다고 정의했습니다. (A goal transferred sentece shold be a fluent, content-complete one with target style.)
4.2.1 Automatic Evaluation
그래서 이를 세가지 세부 요소로 나누고, 지표를 세웠습니다.
- Style control - 두 데이터로 학습한 두가지 감성 분류기를 통한 정확도
- Content preservation - BLEU 스코어, 콘텐츠라는 것을 원문의 단어들이라고 생각했습니다(self-BLEU). 이때 reference를 이용할 수 있으면 이를 이용한 BLEU 스코어도 따로 계산했습니다(ref-BLEU).
- Fluency - perplexity by 5-gram KenLM
4.2.2 Human Evaluation
non parallel data로 학습했기 때문에 이미 불완전한 평가 지표들이 더욱 불완전할 수 밖에 없습니다. 그래서 사람에의한 평가도 시행했다고 합니다. 각각 50문장씩 100문장을 뽑고, 원문과 3개의 변환된 문장을 사람에게 제시한 후 다음 질문들을 통해 평가했다고 합니다.
- style control : Which sentence has the most opposite sentiment toward the source sentece?
- content preservation : Which sentence retains most content from the source sentence?
- fluency : Which sentence is the most fluent one?
4.3 Training Detail
Style Transformer
- 4 Layer/ 4 Attention-head Transformer Enc, Dec
- 256 dimensions of hidden, embedding, positional encoding size
- 256 hidden units for representing different style : 스타일을 인코더에 넣기 위해 256차원을 사용했고, 이때는 positional encoding은 적용하지 않았다고 합니다.
Discriminator
- cls token for input and output
General
- random word dropout for the input sentence when self constrution
- temperature parameter to the softmax layer
4.4 Experimental Result
당연하게도 지표에서도 꽤 준수한 성능을 보이고 있습니다.
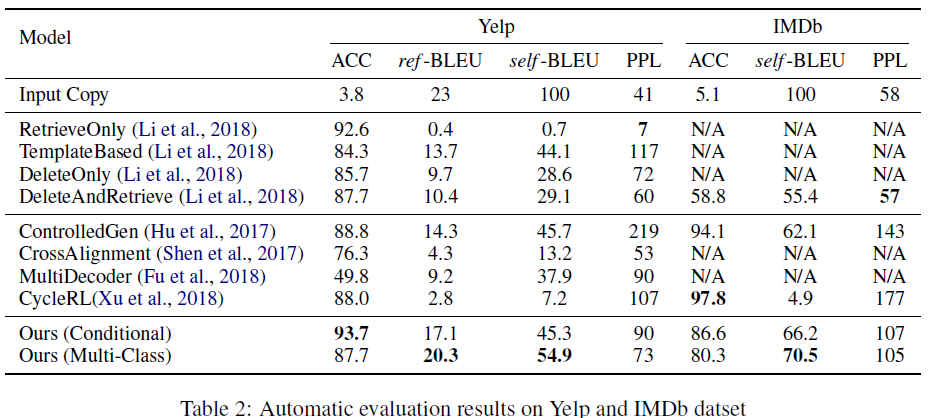
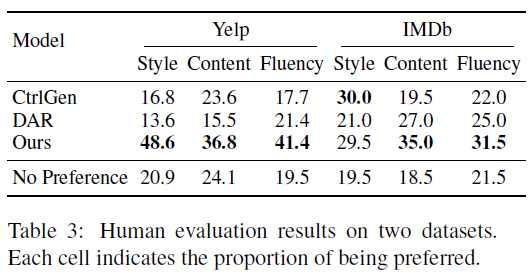
더 강조할 점은 사람 평가에서 다른 모델에 비해 무척 좋은 성능을 거뒀다는 것입니다. 특히 YELP 데이터에서 성능차이가 큰데, 두 데이터셋의 문장길이의 차이 때문인지, 학습 데이터 수의 차이 때문인지, 원인이 궁금합니다.
4.5 Ablation Study
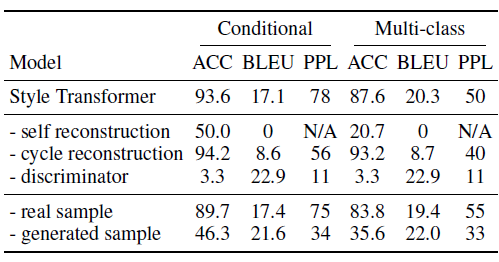
self construction loss를 제거했을 때
이때는 모델이 입력문장에 상관없이 하나의 단어만 내뱉었다고 합니다. self construction loss가 LM으로서 트랜스포머가 기능하도록 만들지 않았나 추측해봅니다.
cycle reconstruction loss를 제거했을 때
cycle reconstruction loss를 제거하여도 모델은 학습을 했습니다. 꽤 준수한 성능을 보인 것 같습니다. 모델의 accuracy가 올라가기도 했습니다. 하지만 BLEU가 많이 떨어진 모습을 보이고 있습니다. 이는 본래 이 손실함수에서 의도했던 것처럼 cycle reconstruction loss를 통해 모델이 본래의 정보를 좀 더 잘 저장할 수 있게 학습하는 것 같습니다.
discriminator loss를 제거했을 때
학습이 거의 안되는 모습입니다. 스타일 변화없이 입력 문장을 곧장 뱉기 시작했다고 합니다. 이 역시 이 손실함수가 제 역할을 다하고 있다는 것을 의미합니다.
각각의 손실함수의 역할을 다시 정리하면서 리뷰를 마치도록 하겠습니다.
- self construction loss - 그럴듯한 문장을 생성
- cycle reconstruction loss - 원문의 정보를 저장
- discriminator loss - 문장 생성 시 스타일을 변형
