Summary
transformer 기반의 multimodal encoder는 model이 visual, text tokens을 함께 학습하도록 한다. visual, word tokens들이 unaligned되어있기 때문에 multimodal encoder가 image-text interaction을 학습하는 것이 어렵다. 본 논문에서는 image-text representation을 합치기 전에 align하기 위한 contrastive loss를 소개한다. (ALBEF) 어떠한 bbox annotation, high-resolution image도 필요로 하지 않는다.
또한 momentum distillation을 소개한다. 이는 momentum model에 의해 생성된 pseudo-targets으로부터 self-training하는 것이다. ALBEF에 대해 이론적인 분석을 제공하는데, 서로 다른 task를 수행한다는 것은 image-text pair에 대해 서로 다른 view를 생성하는 것으로 해석될 수 있다.
기존의 VLP 모델들은 region-based image features를 추출하는데, 사전 학습된 object dector model을 사용 하곤했다. 또한 masked-language model, image-text matching으로 학습을 진행했다.
그러나 몇 가지 한계점이 존재하는데,
- image feature와 word token을 한 space에 위치시켜서, 하나의 공간에서 그들의 상호작용을 학습하기가 어렵다.
- object detector는 annotation-expensive, compute-expensive하다.
- 널리 사용되는 dataset은 web에서 가져온 것이라 noisy하고 모델이 이를 통해 학습하게 되면 noisy text에 overfit하여 일반화 성능을 떨어뜨릴 가능성이 있다.
본 논문은 detector없이 image와 text를 따로 encoding하고 multimodal encoder로 image-text feature를 cross-modal attention를 통해 학습하는 새로운 VLP model ALBEF를 소개한다. 본 논문에서는 ITC loss를 사용해서 unimodal encoders를 학습하는데, 다음과 같은 목적을 가지고 있다.
- image-text feature를 align하여 multimodal encoder가 cross-modal learning을 더 쉽게 하도록 만들어 준다.
- unimodal encoder가 image-text feature의 semantic meaning을 더 잘 이해할 수 있도록 한다.
- image-text를 embedding하기 위해 low space를 학습하는데, 이는 image-text matching object가 더 정보가 담겨져 있는(덜 noisy한) sample을 찾도록 도와준다.
Momentum Distillation (MoD)
MoD는 noisy supervision조건에서 학습을 개선시키기 위한 간단한 방법이다. 이것은 모델이 larger uncurated web dataset에 영향을 미치도록 한다. momentum model은 pseudo-targets을 생성하여 추가적인 지도학습을 가능하게 한다. MoD를 사용하면 web annotation과 다르게 reasonable한 data의 경우 모델이 penalize하지 않는다.
또한 본 논문에서는 ALBEF에 대한 이론적 정의 또한 제공한다. ITC, ITM은 image-text pair의 서로 다른 관점에 대한 lower bound 정보를 제공한다. 이러한 관점에서 MoD는 새로운 view를 만들어 내는 것으로 해석될 수 있다. ALBEF는 변하지 않는 vision-language representation을 학습한다.
Method
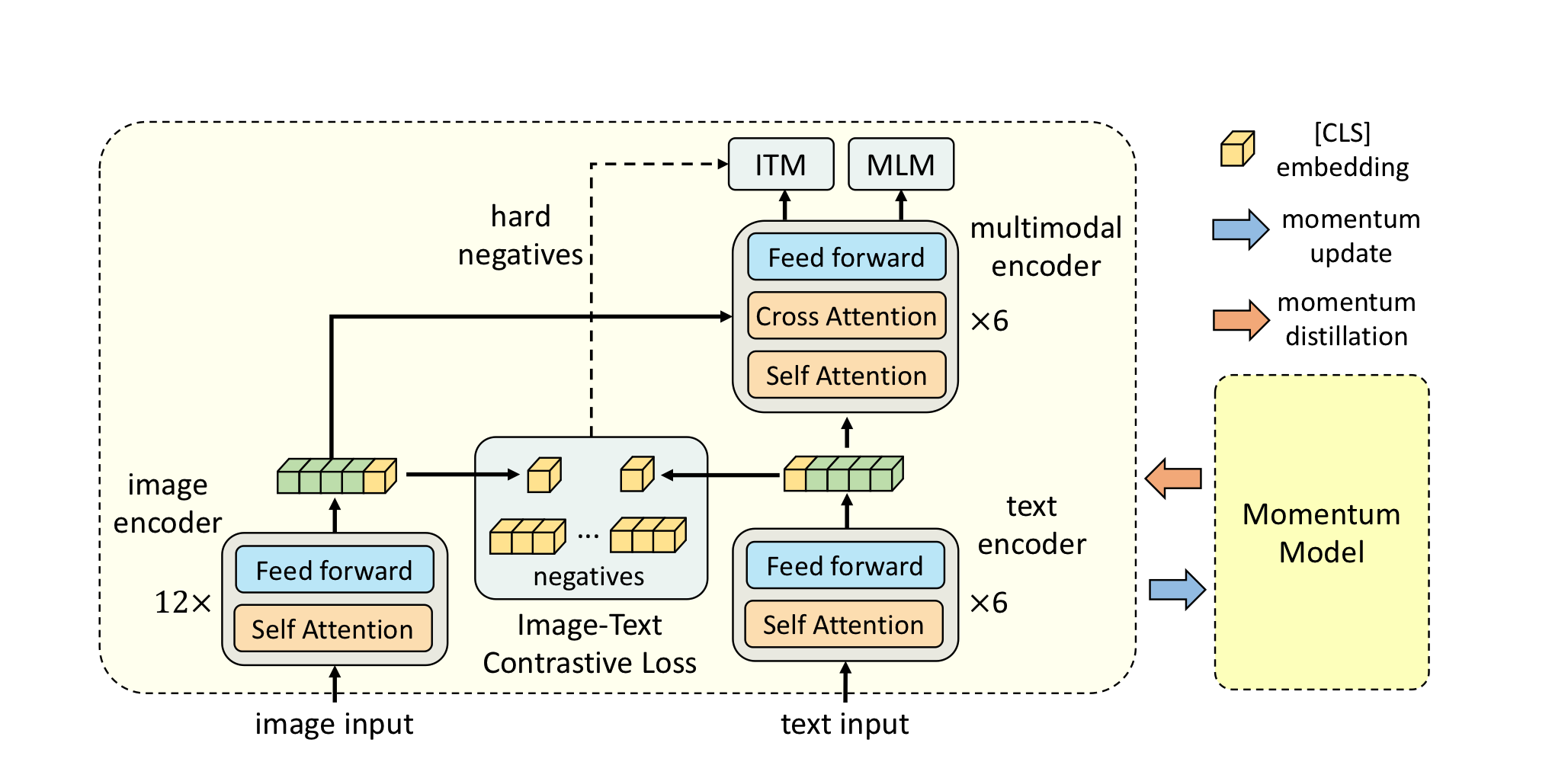
ALBEF는 image encoder, text encoder, multimodal encoder 3개로 이루어져있는데, 각각 ViT-B/16, BERT_base, BERT_base로 초기화한 multimodal encoder를 사용한다.
pre-training objective로 ITC, MLM, ITM을 사용한다.
ITC
더 나은 unimodal representation을 학습하고 한다. parallel image-text pair가 더 높은 similarity score를 가지도록 한다. 이는 image, text features의 cls token을 mapping하고 dot-product를 통해서 구해진다.
Conclusion & Comments
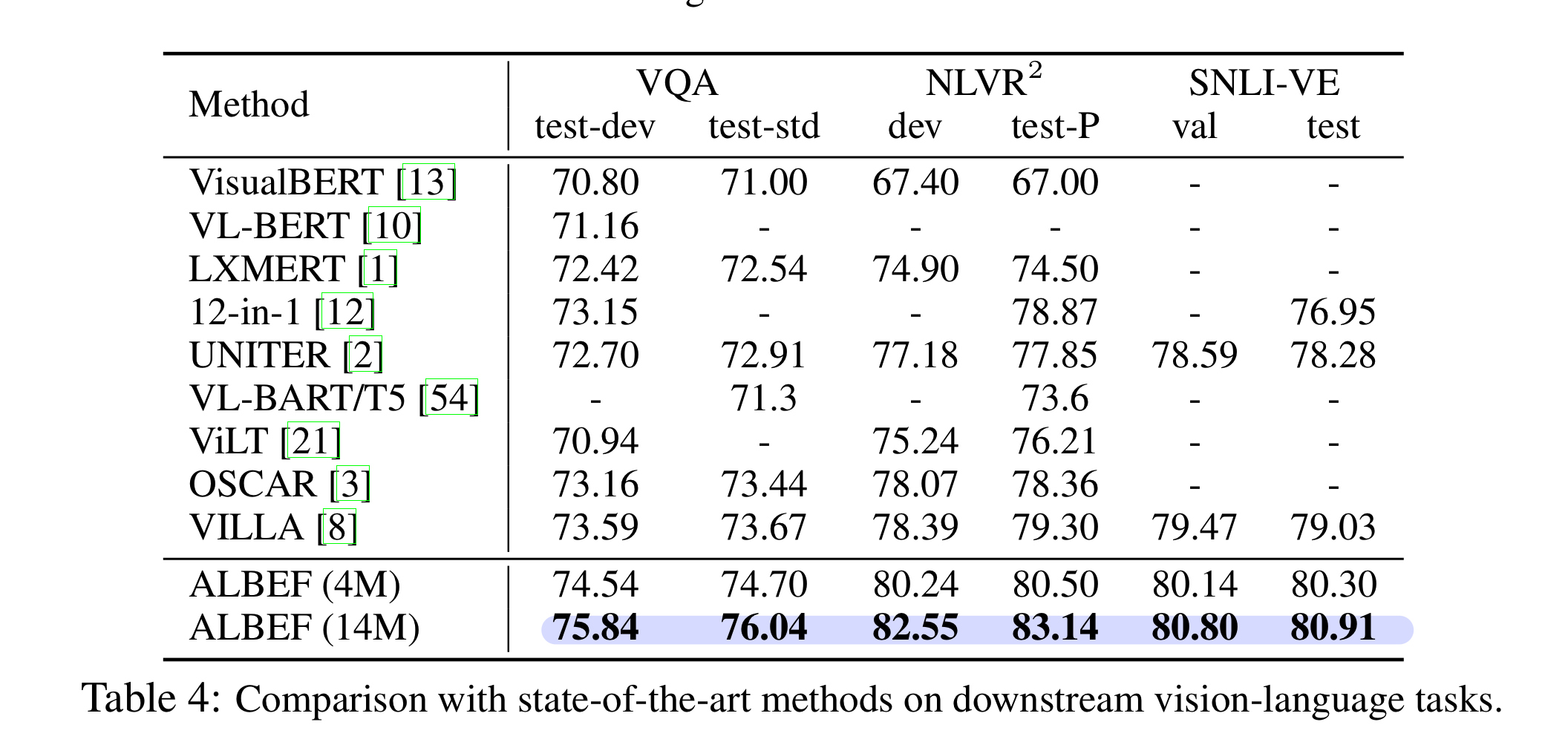
ALBEF는 multimodal encoder에 image, text feature를 합치기 전에, 두 representation을 align하여 둘 사이의 차이를 좁히도록 먼저 학습하면서 다양한 V-L down stream task에서 SOTA를 차지하였다. 또한 이론적으로, 실험적으로 ITC, MoD의 효과를 입증했다. 또한 web data를 사용해 pretraining을 한 만큼 많은 bias, noise가 섞여 있을 가능성이 높기 때문에, 실제 application에 적용할 때는 각별한 주의가 필요하다고 밝혔다.
ITC를 적극적으로 활용하여 좋은 성능을 낸 논문, 앞으로 object detector를 사용하는 연구는 조금씩 사라지는 추세? 인 것 같다.
