Summary
Vision-Language Pre-training은 많은 V-L task을 발전시켰다. 최근 V-L 모델들은 웹상에 존재하는 noisy하고 거대한 데이터로 학습을 진행하였는데, 이것은 suboptimal하다. 본 논문은 nosiy web data를 caption을 bootstrapping하는 방식으로 효과적으로 개선을 이룬 BLIP을 소개한다. BLIP은 captioner + filter로 이루어져있는데, captioner는 caption을 합성하고, filter는 그것에서 noise를 줄이는 역할을 한다. BLIP은 많은 V-L task에서 SOTA를 차지하고, video-language task에 zero-shot으로 적용하여 좋은 성능을 얻을 수 있었다.
현재 존재하는 모델들은 두 가지 주요한 한계점을 지니고 있다.
- model의 관점: 대부분의 모델들은 encoder-based이거나 encoder-decoder based인데, encoder-based model은 generation에 약하고, encoder-decoder model은 image-text retrieval에 약하다.
- data의 관점: 최근의 SOTA model은 web에서 수집한 image-text pair로 pre-train하는데, 이것이 가져다 주는 이득에도 불구하고 filtering 되지 않은 noisy한 data는 상당한 문제점을 지닌다 (bias issue)
결과적으로 이러한 문제점들을 해결하고자 BLIP을 제안한다. BLIP은 다음과 같은 장점을 지닌다.
- Multimodal mixture of Encoder-Decoder (MED): 세 가지 loss function으로 학습을 진행한다. 1) image-text contrastive learning 2) image-text matching 3) image-conditioned language modeling
- CapFilt: noisy image-text pair에서 noise를 줄인 새로운 dataset
즉, captioner와 filter가 caption을 bootstrappingg하면서 성능을 높였고, 더욱 다양한 caption을 사용하면서 이득을 볼 수 있었다. 또한 BLIP은 다양한 V-L task에서 SOTA를 차지하였다. (zero-shot video-text task를 포함)
Method
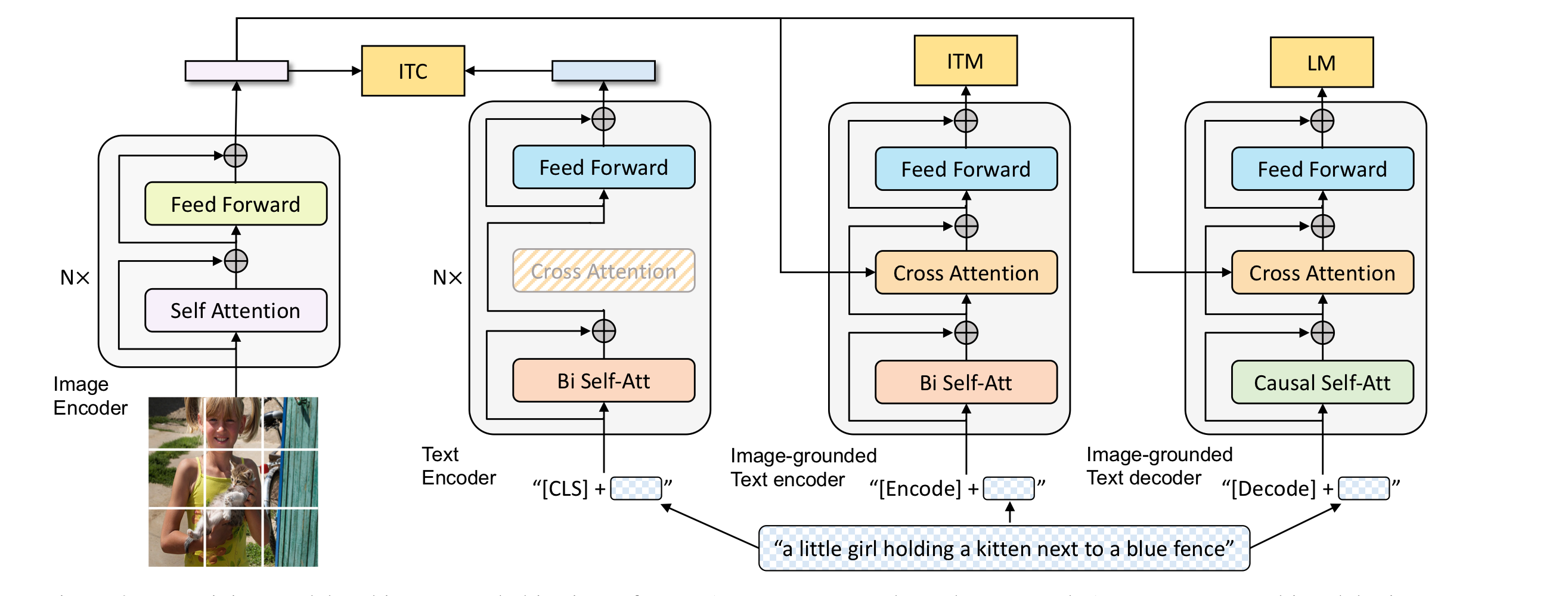
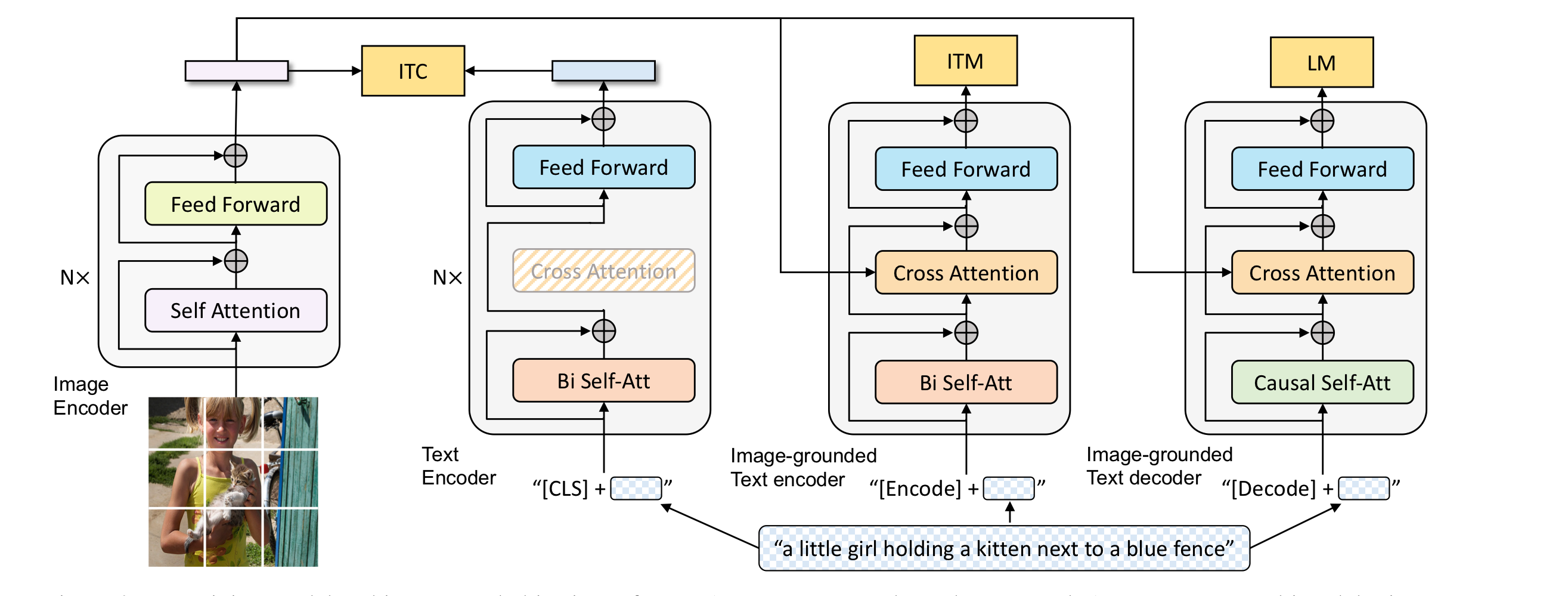
image feature extraction하는데 있어서, 최근에는 object detector를 사용하는 것보다, ViT를 사용하는 것이 더 좋은 성능을 보인다는것을 확인하고 본 논문도 ViT를 사용하였다. 본 논문은 세 가지 기능 중 하나를 수행할 수 있는 MED를 소개한다.
Model Architecture
- Unimodal encoder: image와 text를 독립적으로 encoding하는 것, text는 BERT로 image는 ViT로 encoding. CLS token이 text를 요약한 정보를 담고 있다.
- Image-grounded text encoder: visual information이 주입된다. encode token은 image-text pair의 multimodal representation을 나타낸다
- Image-grounded text decoder: bi-self attention을 제거하고 casual self-attention을 추가하였다. decode token은 문장의 시작을 알리는 용도로 사용된다.
Pre-training object
Pre-training object는 다음과 같다
- Image-Text Contrastive Loss (ITC): unimodal encoder에 사용된다. 이것의 목적은 visual, text transformer의 feature space를 align하도록 하는 것이다. 그래서 image-text pair가 서로 유사한 것 끼리는 더 가깝게, 아닌것은 더 멀게 학습되도록 한다. vision-language를 이해하는 것에 효과적이다.
- Image-Text Matching Loss (ITM): 개인적으로 ITC와 헷갈렸는데, image-grounded text encoder를 activate하고, image-text multimodal representation을 잘 포착하도록 학습한다. 일종의 binary classification으로 사용되며, image와 text가 match하는지 아닌지만, 결정한다.
- Language Modeling Loss (LM): image-grounded text decoder에 사용되며, image가 주어졌을때, textual description을 잘 생성해내는 것을 목표로 한다. MLM Loss와 비교했을 때, VLP에서 좀 더 많이 사용된다. visual information을 caption으로 바꾸는 일반화 성능을 향상시킨다.
text encoder와 decoder는 self-attention layer를 제외하고 모든 파라미터를 공유하는데, 이는 효율적인 학습을 가능하게 한다.
CapFilt
image에 caption을 annotate하는데 많은 비용이 발생하기 때문에, 높은 퀄리티의 human-annotated image-text pair data는 그 수가 제한적이다. 최근의 많은 연구들에서는 web에서 수집한 larger noisy data를 이용해 학습을 진행한다. 하지만, 이런 data들은 caption이 정확하게 image를 설명하지 않는 경우가 많아서 V-L model의 학습에 suboptimal하게 사용된다.
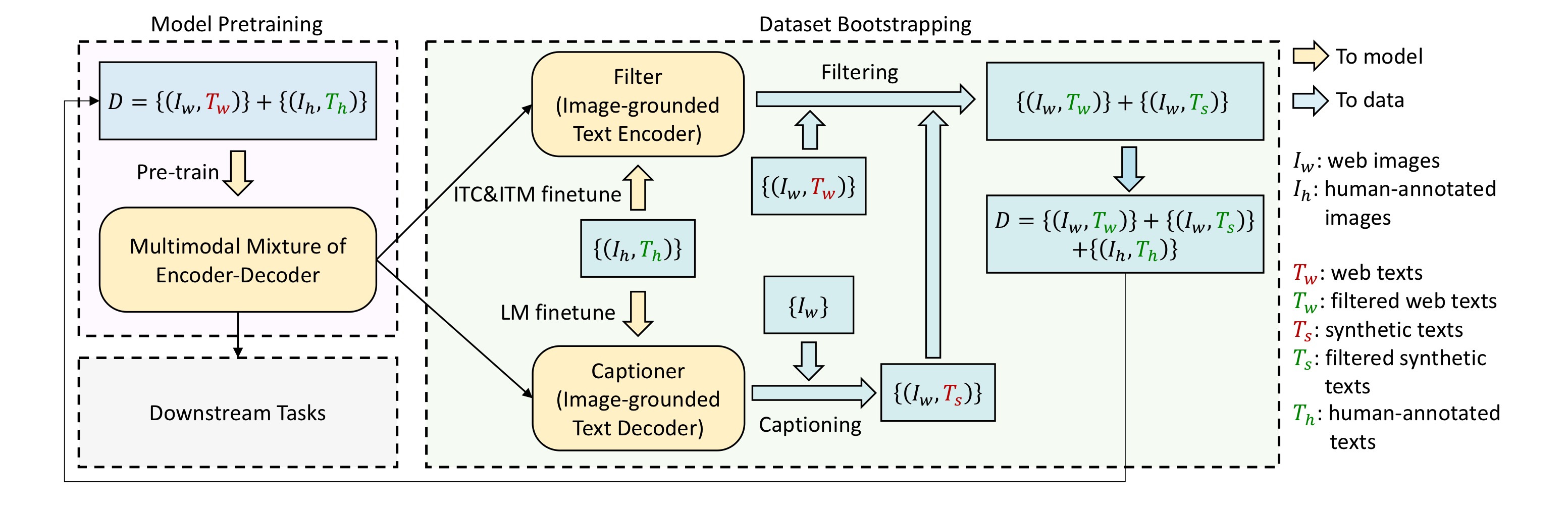
CapFilt는 text corpus의 질을 향상시키는 새로운 방법론이다. captioner는 web image가 주어지면, caption을 생성하고, filter는 noisy한 image-text pair를 제거한다. captioner, filter는 모두 MED로 initialized된다. 특히 captioner는 LM으로 학습하는데, caption을 실제로 생성해야하는 부분이기 때문이다. filter는 ITM으로 학습되는데, captioner를 통해 만들어진 caption이 실제로 image를 잘 설명하는지, 즉 noisy하지 않는지 판단할 수 있어야 하기 때문이다. 이때, captioner가 만든 caption, 원래 image에 있던 caption모두가 filtering과정을 거치고 합쳐져서 data로 사용된다.
CapFilt는 오직 14M의 data를 사용하고도 성능을 향상시킨 것을 확인할 수 있었고, data나 visual backbone을 더욱 늘리면서 성능을 향상시킬 수 있었다.
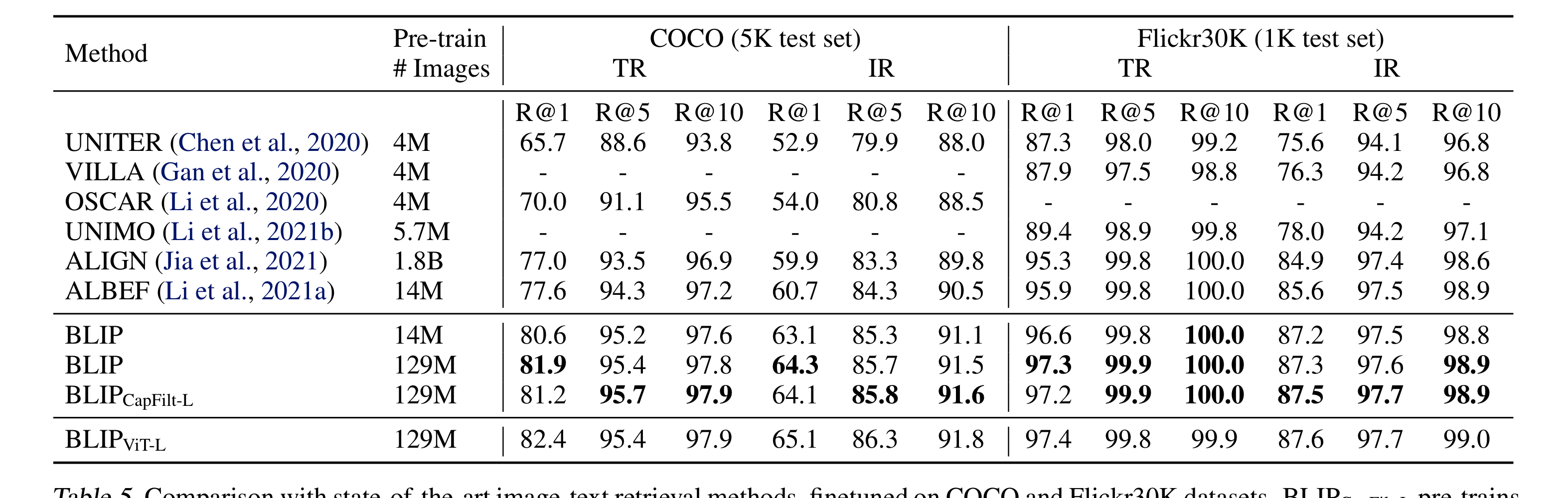
이 외에도 다양한 비교 실험을 진행했다.
- Diversity is Key for Synthetic Captions: caption을 생성할 때 nucleus sampling을 사용하는 것이 가장 좋은 성능을 내었다. nucleus sampling이란, 다음 단어를 생성할 때, 누적 확률이 top-p가 될 때까지의 단어만을 sampling하는 것을 의미한다.
- CapFilt의 장점은 더 오래 학습하는 것에서 오지 않는다. bootstrapped dataset으로 학습하게 되면 같은 수의 epoch를 반복하더라도 더 오랜 시간이 걸리게 되는데, 이로 인해 성능이 좋아진 것이 아니냐는 의견에 대해 본 논문은 web text를 모사해서 같은 시간으로 학습을 해본 결과, 성능이 향상되지 않았다는 것을 보여주었다.
- 새로운 모델은 bootstrapped dataset으로 학습되어야만 한다. pre-trained된 모델을 계속 학습하는 것이 이득을 가져다주지는 않았다.
Conclusion & Comments
MED, CapFilt를 사용해서 web text에 대해 noise를 제거하여 더 적은 데이터 셋으로 학습하여 많은 V-L task에서 SOTA를 차지한, BLIP을 소개했다. 개인적으로 더 적은 데이터 셋을 사용했다는 점, web text의 quality를 개선하여 성능을 높였다는 점에서 VirTex가 생각났던 논문이었다.
