Summary
복잡한 task/modality-specific customization 없이 multimodal pretraining을 위한 단일화된 패러다임을 제안한다. OFA는 unified multimodal pretrained model인데, 많은 modality와 task를 간단한 seq2seq학습으로 unify한다. OFA는 pre-training하고 task instruction으로 fine-tuning하여 별도의 task-specific한 layer를 필요로 하지 않는다. 이를 통해 많은 multimodal task에서 SOTA를 차지하게 된다.
인간처럼 다양한 modality를 한번에 학습하여 다양한 task를 해결하는 인공지능 모델을 만드는 것은 AI의 주된 목표이지만, 어렵다. transformer의 발전으로 pre-train, fine-tuning은 많은 성공을 이뤘고, few/zero-shot model또한 성공적인 결과를 얻게 되었다.
다양한 modality를 가진 task를 해결하는데 있어 모델에 더 나은 일반화 성능을 가지게 하기 위해서는 세 가지 properties가 필요하다.
- Task-Agnostic: task-representation을 하나로 만드는 것 (task가 무엇인지 몰라도 모델이 쉽게 여러 task를 해결할 수 있는 능력)
- Modality-Agnostic: input, output을 하나로 만드는 것 (input, output이 어떤 modality인지 몰라도 모델이 쉽게 이를 처리할 수 있는 능력)
- Task Comprehensiveness: 일반화 능력을 좀더 robust하게 만들기 위해 충분한 task variety를 가지는 것
세 가지 properties를 만족하면서 좋은 성능을 내는 것은 어렵다. 이러한 이유로 현재의 language, multimodal model들은 1. fine-tuning을 위한 추가적인 layer를 만들어 학습을 진행하거나, 2. 아예 task에 맞는 모델을 따로 만들거나, 3. 각각의 modality에 맞는 디자인으로 모델을 구성하던가 하는 방식을 따르고 있다.
이러한 문제를 해결하기 위해 multimodal pretraining omni-model OFA (One For All)를 제안한다. 이는 모델의 아키텍쳐, modality, task 모두를 하나로 합쳤고 위의 세가지 properties를 모두 지원한다. task-agnositc을 위해 직접 만든 instruction을 통해 unified seq2seq abstraction안에서 pretraining, finetuning을 진행한다. modality agnostic을 위해 transformer구조를 사용하였고, 이는 모든 task에서 공통적으로 사용되는 multimodal vocabulary안에서 다양한 modality정보를 사용할 수 있게끔 했다. task comprehensiveness의 경우, uni-modal, cross-modal task를 pre-training하므로써, 달성할 수 있었다.
Method
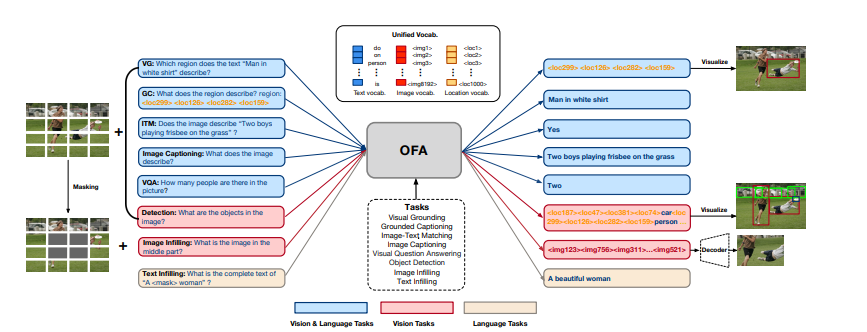
I/O & Architecture
multimodal pretraining은 transformer model을 image-text corpus로 pretrain한다. 이를 위해 data를 전처리해서 visual, linguistic information이 모두 transformer에서 처리될 수 있도록 하는 것이 필요하다. 많은 cost가 드는 object detector를 사용해서 얻은 region feature대신 ViT에서 사용하는 것 처럼 image를 patch로 나눠서 feature를 뽑아낸다. liguistic information의 경우, GPT, BART에서 사용되는 것과 같이 BPE를 통해 feature를 얻는다.
다양한 modality를 가지는 데이터를 task-specific하지 않게 하기 위해, 같은 공간에 표현하는 것이 중요하다. 본 논문에서는 이를 위해, text, image, object를 이산화하고, 하나의 output vocabulary에 넣는다.
아키텍쳐는 encoder-decoder transformer로 이루어져있다.
Tasks & Modalities
task와 modalities를 하나로 합치기 위해서 본 논문은 seq2seq learning paradigm을 제안한다. 이는 pretraining task, downstream task, generation이 모두 합쳐진 seq2seq generation task이다. multimodal, unimodal data 모두에 수행할 수 있으며, 모델의 성능을 높였다. cross-modal representation learning에는 5가지가 있다.
- visual grounding: 이미지의 일부분을 제거하고 text가 주어졌을 때 그 일부의 이미지를 생성하는 task
- grounded captioning: 이미지의 일부분이 주어졌을 때 그것을 잘 설명하는 caption을 생성하는 task
- image-text matching: image-text pair가 서로 일치하는 지 판별하는 task 이때 모델은 discriminator로 학습된다.
- image captioning: 주어진 image를 잘 설명하는 caption data를 생성하는 task
- visual question answering: image와 그것에 대한 질문이 주어졌을 때 답을 생성하는 task
uni-modal representation learning을 위해, 2개의 vision, 1개의 language task를 수행했다.
image infilling, object detection으로 학습했다. 요즘들어 vision분야에서도 masked image modeling이 효과적인 pretraining task로 떠올랐다. image infilling은 image의 중간을 뚫어두고, text로 “이미지 중간에 있는 부분은 무엇인가?”로 질문해서 답을 내는 task. 여기에 덧붙여서 object detection도 적용했다.
text의 경우 text infilling으로 학습했다. (아마 masked language modeling 비슷한 것이 아닐까 추측)
Results
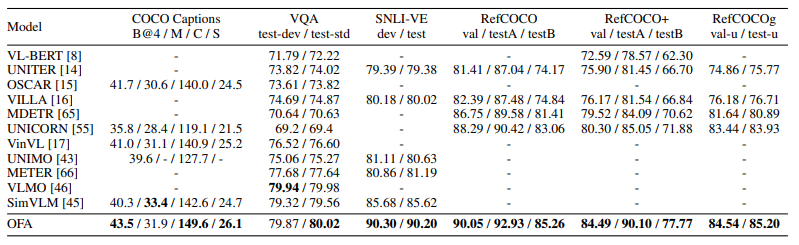
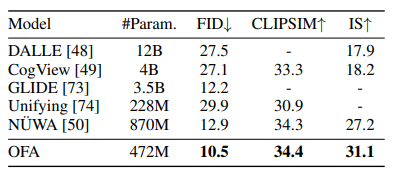
많은 down-stream task에서 SOTA를 차지하였다.
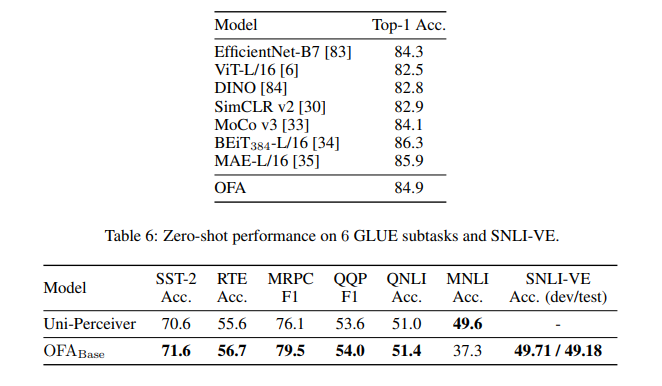
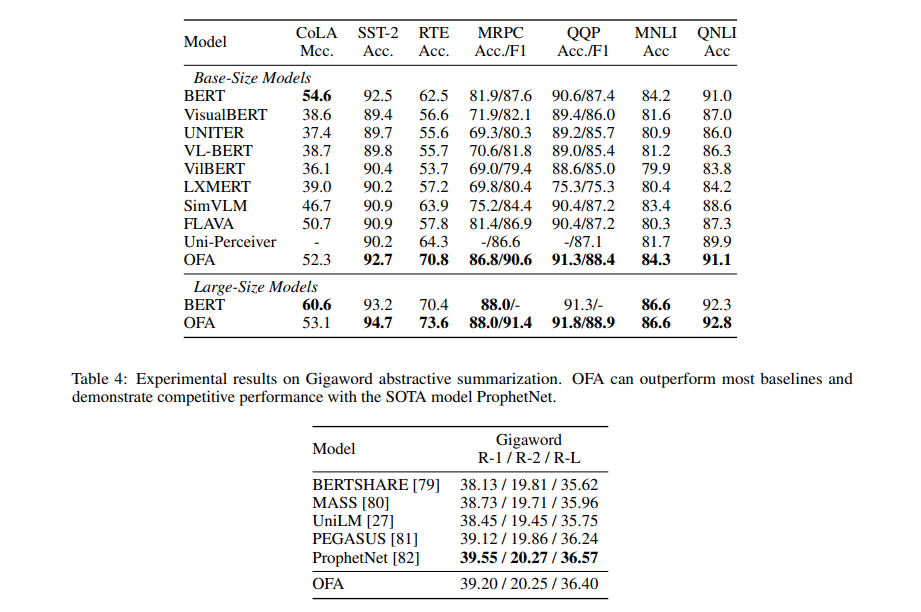
심지어 unimodal task의 경우에도, 이것만을 처리하는 specific model보다 성능이 더 잘 나온 경우를 볼 수 있다.
unseen task, out-of-domain에도 잘 적응하는 것을 볼 수 있다.
uni-modal pretraining은 cross, uni-modal task 모두에 영향을 미쳤는데, natural language pretraining은 language의 문맥 표현을 더 잘 학습할 수 있도록 하였지만, image classification task에는 부정적인 영향을 미치게 했다. 심지어 text-to-image generation task에도 안좋은 영향을 미쳤다는 것이 밝혀졌다. image infilling의 경우에는 image classification, text-to-image generation 모두에 좋은 결과를 내게 했다. 의도적으로 손상을 입힌 이미지를 채우는 학습은 decoder의 image 생성 능력을 향상시키는데 도움을 준다는 것을 알 수 있다. 하지만 image infilling은 image captioning, VQA의 성능을 낮춘다. 두 task모두 높은 text generation capability를 요구하는데, decoder가 image generation 능력을 학습하는 것은 당연하게도 위 task들의 성능을 낮추게 된다.
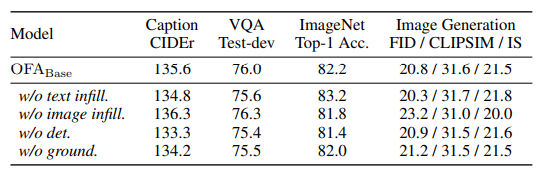
이전에도 multimodal pretraining task들로 학습한 multimodal model이 있었지만, 본 논문에서는 추가적으로 detection, visual grounding, grounded captioning을 수행했다. 이 task들은 multimodal task의 성능을 높이는데 중요한 역할을 했는데, 이들의 공통점은 region을 예측하는 것이다. 하지만, region information은 text-to-image task의 성능을 높이는데는 거의 기여를 하지 않았는데, 이러한 task는 text-region alignment information이 그다지 필요로 하지 않기 때문이다. 놀랍게도 detection은 visual understanding에서의 성능을 높이는데 기여했다. 이것은 image의 region information또한 image를 이해하는데 필요한 요소라는 것을 보여준다. 특히 이미지에 복잡한 object가 존재할 경우에는 더더욱.
Conclusion & Comments
본 논문은 다양한 task, modalities에 일관적으로 좋은 성능을 보이는 OFA를 제안한다. OFA는 모델의 아키텍쳐, task, modalities에서 unification을 이뤄냈다. 특히 몇몇 multimodal task에서는 SOTA를 차지하기도 하였다. 심지어는 unimodal에서도 specific model을 제치고 좋은 성능을 보이기도 했다. 이러한 점에서 본 모델이 vision, language 모두를 이해하고 있다고 봐도 될것이다.
개인적으로 논문이 조금 불친절 하고 아 아무튼 성능 잘나왔어요 하는 느낌. 물론 region feature의 중요성을 새로운 pretraining task를 제안하여 증명하였고, 실제로도 SOTA를 차지한 점은 놀랍다고 생각한다. 실제로 논문 부록을 보면 정말 와 이게 가능한가 싶을 정도로 신기하다.. 심지어 그렇게 많은 데이터를 가지고 학습한 것도 아니라서 진짜 뭔가 이상할 정도?
