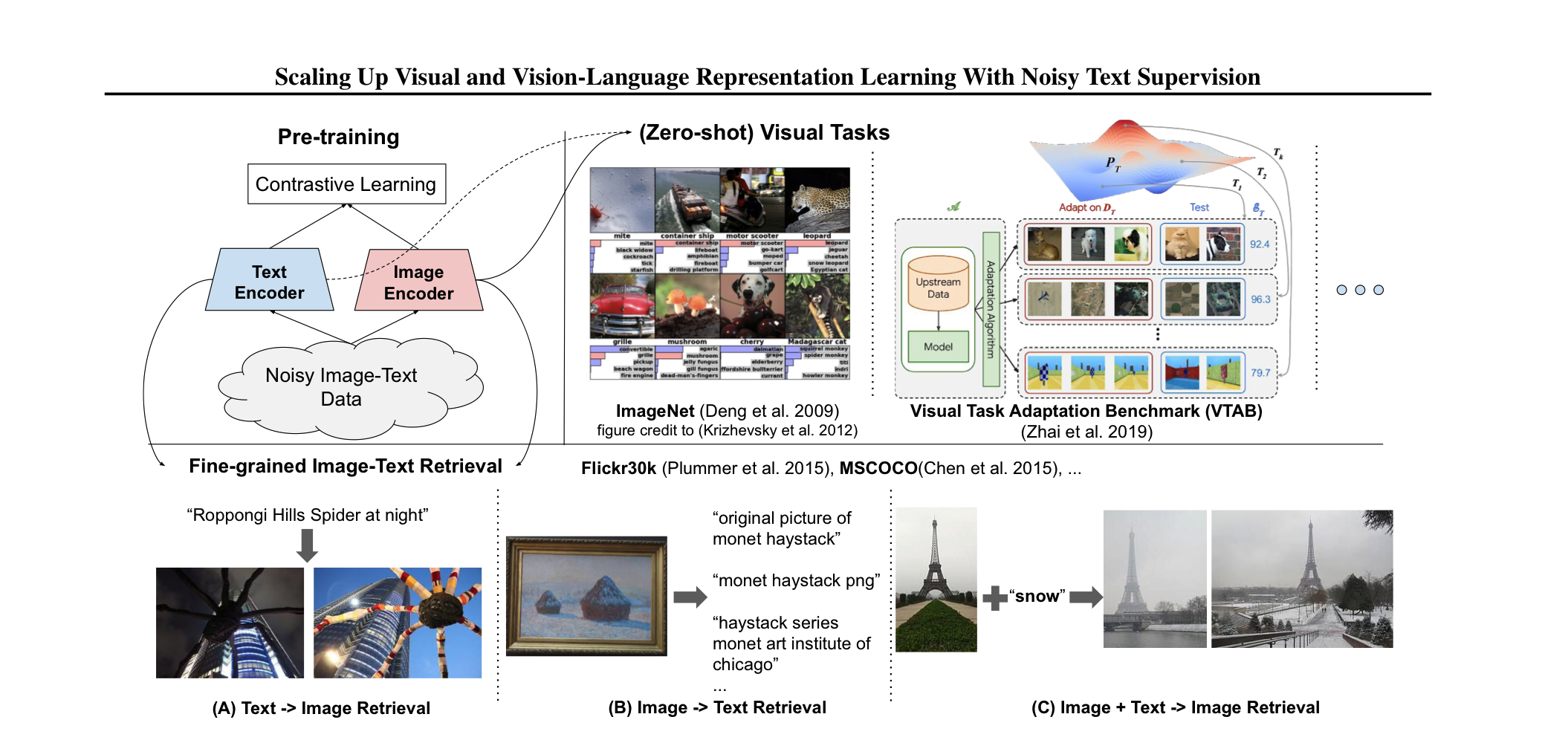
Summary
pre-trained model에는 많은 데이터를 필요로 한다. 이 과정에서, costly한 annotation 과정이 필요한데, 이는 필연적으로 학습에 사용되는 데이터셋의 크기를 줄인다. 본 논문에서는 별도의 후처리 없이 noisy한 1billion image alt-text pair로 모델을 학습하여, down-stream task에서 좋은 성능을 내는 것을 보여준다. 모델은 image-text pair로부터 feature를 얻는 두개의 encoder로 이뤄져 있고, contrastive loss를 사용하여 학습을 진행한다. 심지어, ALIGN은 ImageNet, VTAB과 같은 zero-shot image classification task에서도 복잡한 cross-modality를 가지는 모델들에 비해 좋은 성능을 보인다.
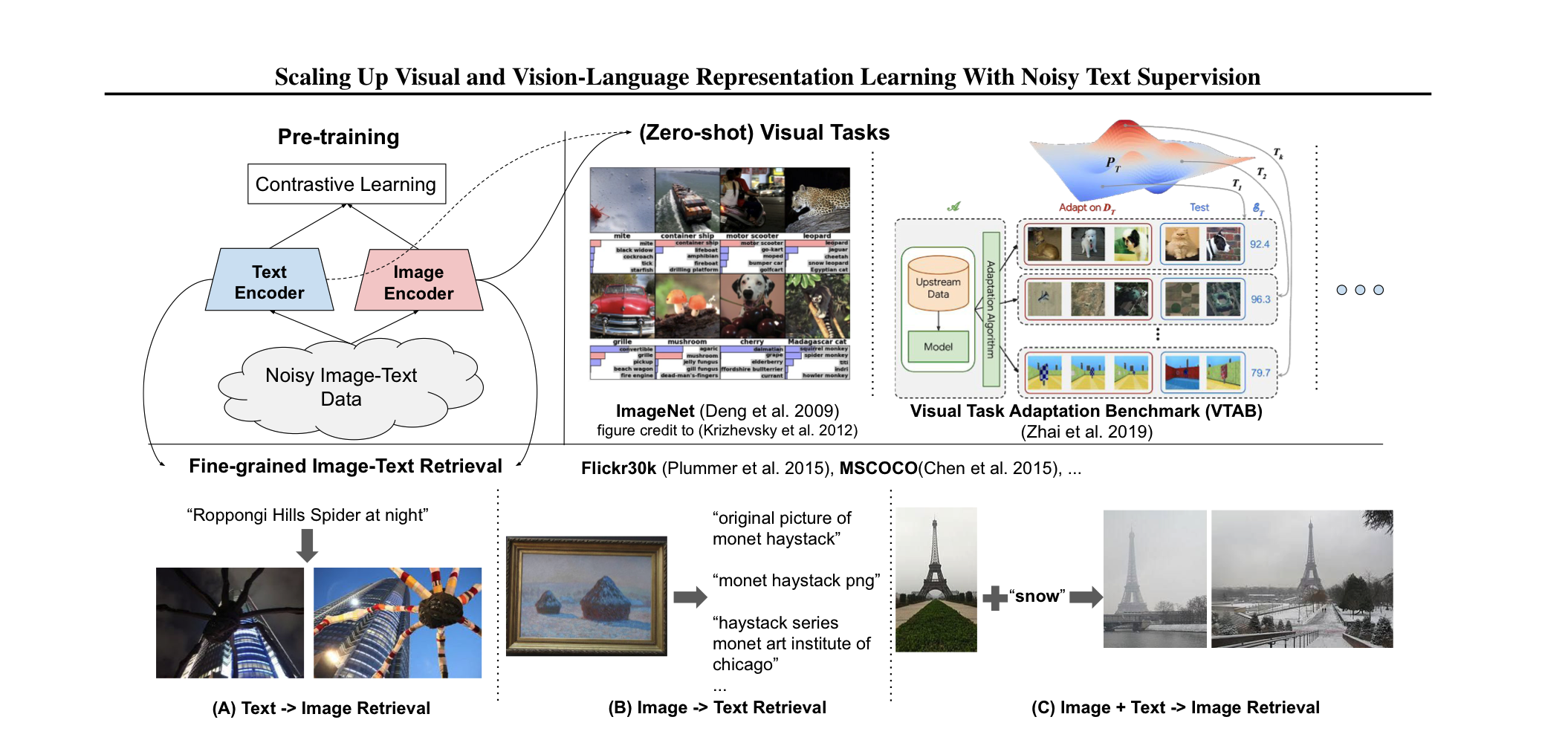
CLIP과 굉장히 비슷한 느낌을 받았는데, 가장 큰 차이점은 training data에 있다. ALIGN같은 경우, raw alt-text data의 natural distribution을 가지는 image-text pairs를 사용하고, CLIP같은 경우, English Wikipedia에서 높은 빈도로 등장하는 visual concept를 사용한다. 전문가의 지식 없이 학습될 수 있는 visual, vision-language feature가 더 강력하다고 주장한다.
Dataset
본 논문의 핵심이 이 dataset인데, dataset을 scale up해서 모델의 성능을 높였다. 본 논문에서는 dataset의 크기를 키우기 위해, Conceptual Captions dataset에서 사용한 후처리를 크게 적용하지 않았다. 결과적으로 훨씬 더 크고 noisy한 dataset이 만들어졌다.

잘 보면, jpg와 같이 text data가 제대로 걸러지지 않음을 확인할 수 있다.
그래도 아예 거르지 않으면 문제가 될 수 있기 때문에 최소한의 필터링을 거쳤는데, Image-based filtering과 Text-based filtering을 사용했다.
Image-based filtering
성적인 이미지를 제거하고 짧은 변의 길이가 200pixel보다 크고, 비율이 3보다 작은 이미지만 살렸다. 그 외에 자주 중복되는 이미지를 제거했다.
Text-based filtering
위의 사진에서 볼 수 있는 raw text를 제거했는데, jpg, 224x224와 같이 쓸모 없는 내용을 필터링했다.
Pre-training
image encoder로는 EfficientNet을, text encoder로는 BERT를 사용했다. BERT에서 나오는 CLS token embedding를 fc layer로 통과시킨 vector와, EfficientNet을 통과하고 global pooling을 거쳐 나온 vector를 구한다. 이때, 두 모델은 scratch로 구현된다.
Experiments
Image-Text Matching & Retrieval과 Visual Classification에 전이 학습하여 성능을 평가했다.
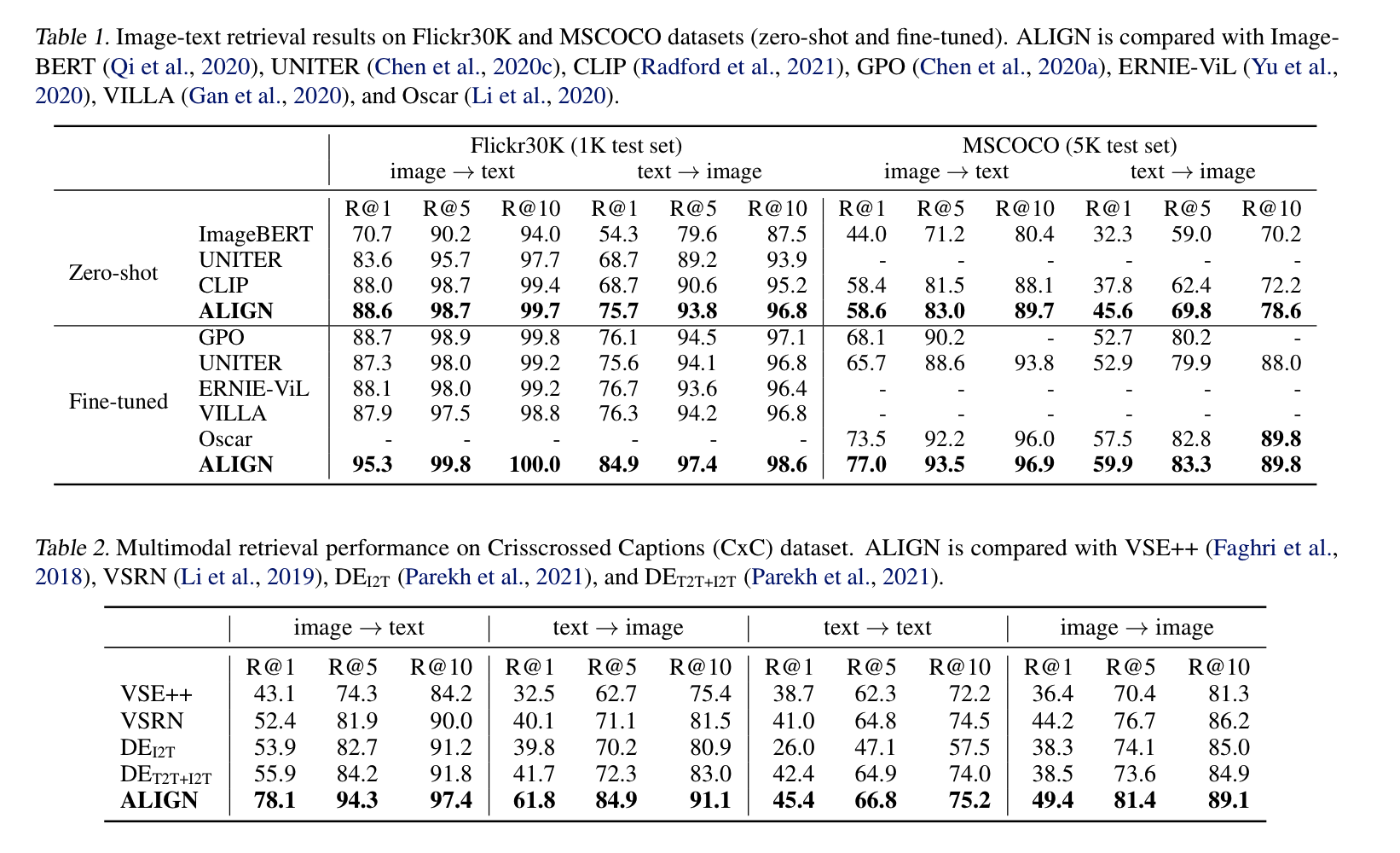

보이는 것과 같이 많은 task에서 SOTA를 차지하였다.
Ablation Study
encoder의 capacity에 따른 성능 비교
- vision task의 경우 image encoder의 capacity가 클 수록 성능이 잘 나왔다.
- vision-language task의 경우 image/text encoder의 capacity가 모두 중요했다.
embedding dimension
- embedding dimension이 클 수록 성능이 잘 나왔다.
pre-training datasets
- dataset을 다르게 하면서 성능을 비교했다.
- 전체 ALIGN dataset / 10%만 random하게 뽑았을 때 / Conceptual Captions (3M)
- 당연히 전체 ALIGN dataset을 사용하는 경우가 더 좋은 성능을 내었고, 심지어 10%만 뽑은 것도 Conceptual Captions보다는 좋은 성능을 내었다.
- 단, ALIGN을 Conceptual Captions의 크기(3M) 만큼 뽑았을 때는 성능이 썩 좋지 않았는데, ALIGN dataset이 그만큼 noisy하기 때문이다.
Analysis of Learned Embeddings
CLIP과 비슷하게 정말 다양한, 거대한 규모의 image로 학습을 하다보니 다양한 분포의 이미지도 처리할 수 있는데, 예를 들면 미술 작품이라던지, 구두라던지 imagenet 기반의 image의 분포를 따르지 않는 실제 세상의 이미지들을 잘 처리하는 모습을 보인다.
Multilingual ALIGN Model
ALIGN이 가지는 또 하나의 장점은, noisy한 web text에 거의 filtering을 하지 않은 data로 학습을 하다보니, 특정 언어에 기반해서 filtering을 하지는 않았다는 것. 이 말은 즉, 모델을 multilingual하게 확장할 수 있다는 말과 같다. Flickr30k의 비영어권 버전인 Multi30k로 학습을 진행한 결과, 기존 SOTA 모델에 비해 월등한 성능 향상을 보였다.
Conclusion & Comments
large-scale noisy image-text data로 학습한 ALIGN모델을 보였다. zero-shot, multilingual등 일반화 성능을 높일 수 있었던 좋은 방법론 이지만, data에 대한 filtering을 거의 거치지 않고서 critical한 bias가 충분히 제거되었는지는 의문점이 남는다. 또한 TPU 1024개로 학습을 진행하였는데, scratch로 학습을 진행하다보니 발생한 문제(?)라고 생각한다. 학습에 너무 많은 cost가 소모된다는 점은 조금 아쉬운 부분.
